Deviner la langue d’un texte (correction)¶
Calcul d’un score pour détecter la langue d’un texte. Ce notebook aborde les dictionnaires, les fichiers et les graphiques (correction).
[34]:
%matplotlib inline
Q1 : lire un fichier¶
[35]:
def read_file(filename):
with open(filename, "r", encoding="utf-8") as f:
return f.read()
Les problèmes d”encoding sont toujours délicats. Un encoding définit la façon dont une séquence d’octets représente une chaîne de caractères. Il y a 256 valeurs possible d’octets et la langue chinoise contient beaucoup plus de caractères. Il faut donc utiliser plusieurs octets pour représenter un caractère un peu comme le Morse qui n’utilise que deux symboles pour représenter 26 lettres. Quand on ne connaît pas l’encoding, on utilise un module chardet et la fonction detect.
[58]:
import chardet
def read_file_enc(filename):
with open(filename, "rb") as f:
b = f.read()
res = chardet.detect(b)
enc = res["encoding"]
return res, b.decode(enc)
On teste la fonction avec un petit fichier qu’on crée pour l’occasion.
[59]:
with open("texte.txt", "w", encoding="utf-8") as f:
f.write("""Un corbeau sur un arbre perché tenait en son bec un fromage.
Maître Renard, par l'odeur alléché, Lui tint à peu près ce langage :""")
[60]:
lu = read_file("texte.txt")
print(lu)
Un corbeau sur un arbre perché tenait en son bec un fromage.
Maître Renard, par l'odeur alléché, Lui tint à peu près ce langage :
[61]:
enc, lu = read_file_enc("texte.txt")
print(lu)
Un corbeau sur un arbre perché tenait en son bec un fromage.
Maître Renard, par l'odeur alléché, Lui tint à peu près ce langage :
Visiblement, ce n’est pas toujours évident mais suffisant pour ce qu’on veut en faire à savoir des statistiques. Les problèmes avec la langue latine devraient être statistiquement négligeables pour ce que nous souhaitons en faire.
[62]:
enc
[62]:
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
Q2 : histogramme¶
[41]:
def histogram(texte):
d = {}
for c in texte:
d[c] = d.get(c, 0) + 1
return d
[42]:
histogram(lu)
[42]:
{'U': 1,
'n': 9,
' ': 23,
'c': 5,
'o': 4,
'r': 11,
'b': 3,
'e': 13,
'a': 10,
'u': 7,
's': 3,
'p': 4,
'h': 2,
'é': 3,
't': 5,
'i': 3,
'f': 1,
'm': 1,
'g': 3,
'.': 1,
'\n': 1,
'M': 1,
'î': 1,
'R': 1,
'd': 2,
',': 2,
'l': 4,
"'": 1,
'L': 1,
'à': 1,
'è': 1,
':': 1}
Le module collections propose un objet Counter qui implémente ce calcul.
[43]:
from collections import Counter
def histogram2(texte):
return Counter(texte)
histogram2(lu)
[43]:
Counter({' ': 23,
'e': 13,
'r': 11,
'a': 10,
'n': 9,
'u': 7,
'c': 5,
't': 5,
'o': 4,
'p': 4,
'l': 4,
'b': 3,
's': 3,
'é': 3,
'i': 3,
'g': 3,
'h': 2,
'd': 2,
',': 2,
'U': 1,
'f': 1,
'm': 1,
'.': 1,
'\n': 1,
'M': 1,
'î': 1,
'R': 1,
"'": 1,
'L': 1,
'à': 1,
'è': 1,
':': 1})
Comme pour beaucoup de fonctions faisant partie des extensions du langage Python, elle est plus rapide que la version que nous pourrions implémenter.
[44]:
%timeit histogram(lu)
11.8 µs ± 407 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
[45]:
%timeit histogram2(lu)
5.37 µs ± 45.4 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Q3 : normalisation¶
[46]:
def normalize(hist):
s = sum(hist.values())
if s == 0:
return {}
else:
return {k: v / s for k, v in hist.items()}
normalize(histogram2(lu))
[46]:
{'U': 0.007751937984496124,
'n': 0.06976744186046512,
' ': 0.17829457364341086,
'c': 0.03875968992248062,
'o': 0.031007751937984496,
'r': 0.08527131782945736,
'b': 0.023255813953488372,
'e': 0.10077519379844961,
'a': 0.07751937984496124,
'u': 0.05426356589147287,
's': 0.023255813953488372,
'p': 0.031007751937984496,
'h': 0.015503875968992248,
'é': 0.023255813953488372,
't': 0.03875968992248062,
'i': 0.023255813953488372,
'f': 0.007751937984496124,
'm': 0.007751937984496124,
'g': 0.023255813953488372,
'.': 0.007751937984496124,
'\n': 0.007751937984496124,
'M': 0.007751937984496124,
'î': 0.007751937984496124,
'R': 0.007751937984496124,
'd': 0.015503875968992248,
',': 0.015503875968992248,
'l': 0.031007751937984496,
"'": 0.007751937984496124,
'L': 0.007751937984496124,
'à': 0.007751937984496124,
'è': 0.007751937984496124,
':': 0.007751937984496124}
Q4 : calcul¶
On essaye avec la fréquence de la lettre H. (données : articles.zip)
[48]:
from teachpyx.tools.data_helper import download_and_unzip
url = "https://github.com/sdpython/teachpyx/raw/main/_data/articles.zip"
texts = download_and_unzip(url)
h = {text: normalize(histogram2(read_file_enc(text)[1])).get("h", 0) for text in texts}
h
[48]:
{'afp1.txt': 0.0067247820672478205,
'afp2.txt': 0.007575757575757576,
'arthur_charpentier1.txt': 0.007012142979305627,
'arthur_charpentier2.txt': 0.02588801926550271,
'arthur_charpentier3.txt': 0.004853022739877981,
'blog1.txt': 0.010752688172043012,
'blog2.txt': 0.007556675062972292,
'blog3.txt': 0.010554089709762533,
'blogny1.txt': 0.029830508474576273,
'elpais1.txt': 0.01349112426035503,
'elpais2.txt': 0.005625270445694505,
'elpais3.txt': 0.005441436539246361,
'elpais4.txt': 0.00224408769204212,
'elpais5.txt': 0.009715025906735751,
'elpais6.txt': 0.0051919661155895615,
'elpais7.txt': 0.005625270445694505,
'inconnu1.txt': 0,
'inconnu2.txt': 0.00016849199663016007,
'lemonde1.txt': 0.010804020100502512,
'lemonde10.txt': 0.007139797229758675,
'lemonde11.txt': 0.0021551724137931034,
'lemonde2.txt': 0.0055272108843537416,
'lemonde3.txt': 0.0014691478942213516,
'lemonde4.txt': 0.004875076173065204,
'lemonde5.txt': 0.0044822949350067235,
'lemonde6.txt': 0.007034547444114429,
'lemonde7.txt': 0.0020463847203274215,
'lemonde8.txt': 0.0034299968818210166,
'lemonde9.txt': 0.008162299639202697,
'lequipe1.txt': 0.00572041473006793,
'lequipe2.txt': 0.005029013539651838,
'nytimes1.txt': 0.030130034887408817,
'nytimes2.txt': 0.031933508311461065,
'nytimes3.txt': 0.02547634339541854,
'nytimes4.txt': 0.03934426229508197,
'nytimes5.txt': 0.035542582417582416,
'nytimes6.txt': 0.030610255410411385,
'nytimes7.txt': 0.04194094414143314,
'nytimes8.txt': 0.03151779230210603,
'nytimes9.txt': 0.03840526700804682}
On regarde les valeurs obtenus pour les articles du monde et du new-york time.
[50]:
import matplotlib.pyplot as plt
lemonde = list(sorted(v for k, v in h.items() if "lemonde" in k))
ny = list(sorted(v for k, v in h.items() if "times" in k))
plt.plot(lemonde, label="lemonde")
plt.plot(ny, label="times")
plt.legend();
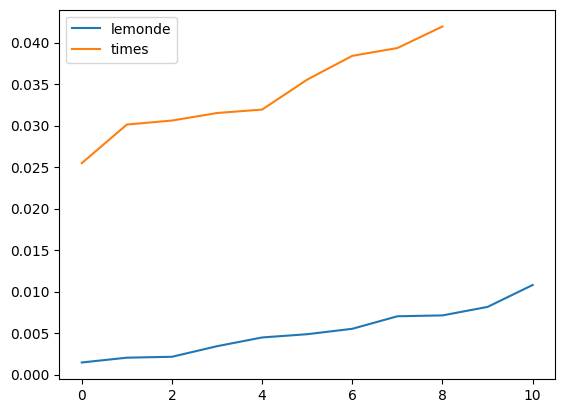
Ca marche plutôt bien.
Q5 : score¶
On recommence avec deux lettres et on trace un nuage de points pour les articles des mêmes journaux.
[51]:
scores = {}
for text in texts:
norm = normalize(histogram2(read_file_enc(text)[1]))
h, w = norm.get("h", 0), norm.get("w", 0)
scores[text] = (h, w)
lem = [v for k, v in scores.items() if "lemonde" in k]
ny = [v for k, v in scores.items() if "times" in k]
[53]:
plt.scatter(x=[_[0] for _ in lem], y=[_[1] for _ in lem], label="lemonde")
plt.scatter(x=[_[0] for _ in ny], y=[_[1] for _ in ny], label="times")
plt.xlabel("h")
plt.ylabel("w")
plt.legend();
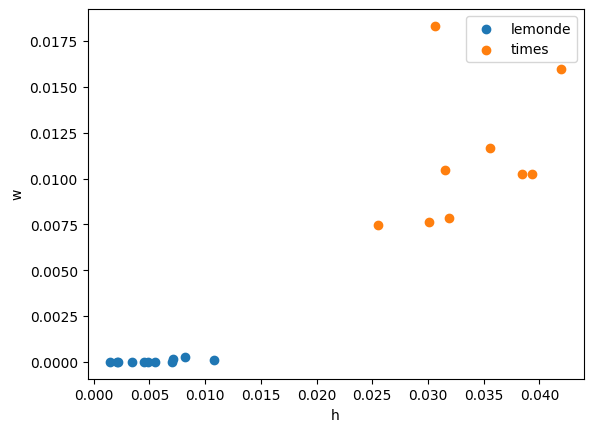
Les textes anglais et français apparaissent bien séparés. On place les autres.
[54]:
other = [v for k, v in scores.items() if "times" not in k and "monde" not in k]
[55]:
plt.scatter(x=[_[0] for _ in lem], y=[_[1] for _ in lem], label="lemonde")
plt.scatter(x=[_[0] for _ in ny], y=[_[1] for _ in ny], label="times")
plt.scatter(x=[_[0] for _ in other], y=[_[1] for _ in other], label="autres", s=15)
plt.xlabel("h")
plt.ylabel("w")
plt.legend();
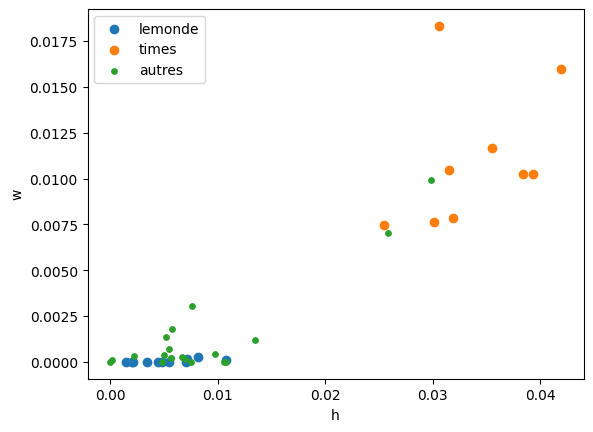
On ajoute le nom du texte sur le graphique.
[56]:
text_others = [k for k, v in scores.items() if "times" not in k and "monde" not in k]
[57]:
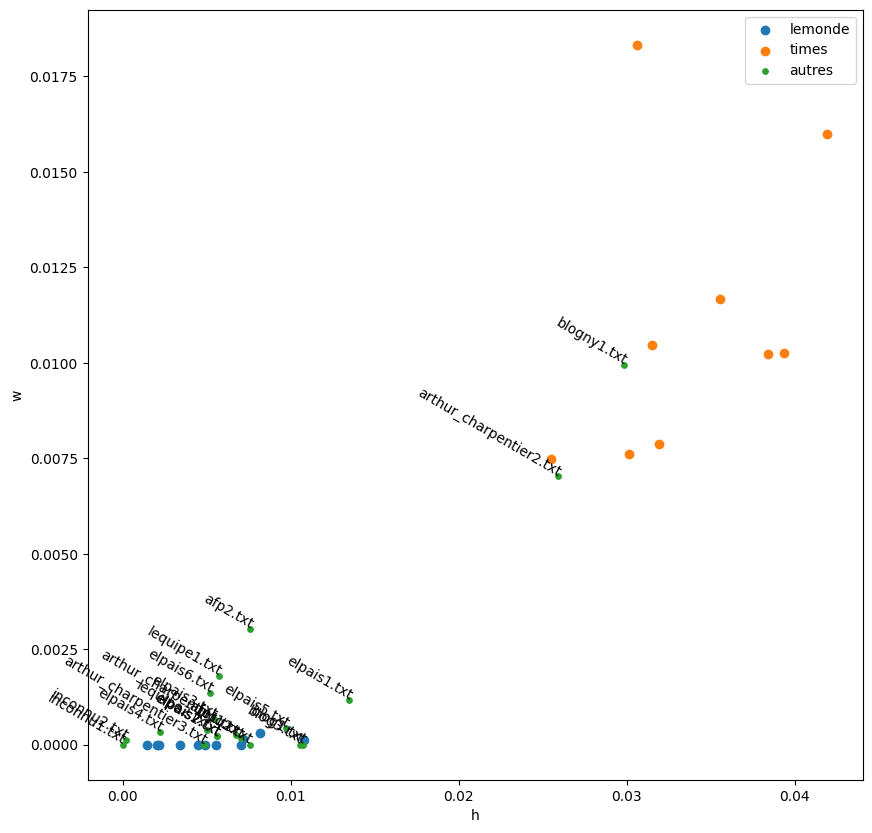
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.scatter(x=[_[0] for _ in lem], y=[_[1] for _ in lem], label="lemonde")
ax.scatter(x=[_[0] for _ in ny], y=[_[1] for _ in ny], label="times")
ax.scatter(x=[_[0] for _ in other], y=[_[1] for _ in other], label="autres", s=15)
for (x, y), t in zip(other, text_others):
ax.text(x, y, t, ha="right", rotation=-30, wrap=True)
ax.set_xlabel("h")
ax.set_ylabel("w")
ax.legend();
[ ]: