Calcul matriciel avec numpy (exercices)¶
numpy est la librairie incontournable pour faire des calculs en Python. Ces fonctionnalités sont disponibles dans tous les langages et utilisent les optimisations processeurs. Il est hautement improbable d’écrire un code aussi rapide sans l’utiliser.
numpy implémente ce qu’on appelle les opérations matricielles basiques ou plus communément appelées BLAS. Quelque soit le langage, l’implémentation est réalisée en langage bas niveau (C, fortran, assembleur) et a été peaufinée depuis 50 ans au gré des améliorations matérielles.
[1]:
%matplotlib inline
Enoncé¶
La librairie numpy propose principalement deux types : array et matrix. Pour faire simple, prenez toujours le premier. Ca évite les erreurs. Les array sont des tableaux à plusieurs dimensions.
La maîtrise du slice¶
Le slice est l’opérateur : (décrit sur la page indexing). Il permet de récupérer une ligne, une colonne, un intervalle de valeurs.
[2]:
import numpy
mat = numpy.array([[0, 5, 6, -3], [6, 7, -4, 8], [-5, 8, -4, 9]])
mat
[2]:
array([[ 0, 5, 6, -3],
[ 6, 7, -4, 8],
[-5, 8, -4, 9]])
[3]:
mat[:2], mat[:, :2], mat[0, 3], mat[0:2, 0:2]
[3]:
(array([[ 0, 5, 6, -3],
[ 6, 7, -4, 8]]),
array([[ 0, 5],
[ 6, 7],
[-5, 8]]),
-3,
array([[0, 5],
[6, 7]]))
La maîtrise du nan¶
nan est une convention pour désigner une valeur manquante. Elle réagit de façon un peut particulière. Elle n’est égale à aucune autre y compris elle-même.
[4]:
numpy.nan == numpy.nan
[4]:
False
[5]:
numpy.nan == 4
[5]:
False
Il faut donc utiliser une fonction spéciale isnan.
[7]:
numpy.isnan(numpy.nan)
[7]:
True
nan est un réel, cette convention n’existe pas pour les entiers.
[8]:
try:
int(numpy.nan)
except ValueError as e:
print(e)
cannot convert float NaN to integer
La maîtrise des types¶
Un tableau est défini par ses dimensions et le type unique des éléments qu’il contient.
[9]:
matint = numpy.array([0, 1, 2])
matint.shape, matint.dtype
[9]:
((3,), dtype('int64'))
C’est le même type pour toute la matrice. Il existe plusieurs type d’entiers et des réels pour des questions de performances.
[10]:
%timeit matint * matint
540 ns ± 39.9 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
[17]:
matintf = matint.astype(numpy.float64)
matintf.shape, matintf.dtype
[17]:
((3,), dtype('float64'))
[18]:
%timeit matintf * matintf
549 ns ± 46.4 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
[19]:
%timeit matintf * matint
1.07 µs ± 102 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
Un changement de type et le calcul est plus long car cela implique la conversion d’une matrice d’un type à l’autre. La règle est de choisir le type le plus générique, ici, le type réel.
La maîtrise du broadcasting¶
Le broadcasting signifie que certaines opérations ont un sens même si les dimensions des tableaux ne sont pas tout à fait égales.
[13]:
mat
[13]:
array([[ 0, 5, 6, -3],
[ 6, 7, -4, 8],
[-5, 8, -4, 9]])
Ajouter une constante à tous les éléments du tableau.
[14]:
mat + 1000
[14]:
array([[1000, 1005, 1006, 997],
[1006, 1007, 996, 1008],
[ 995, 1008, 996, 1009]])
Ajouter la même ligne à toutes les lignes.
[15]:
mat + numpy.array([0, 10, 100, 1000])
[15]:
array([[ 0, 15, 106, 997],
[ 6, 17, 96, 1008],
[ -5, 18, 96, 1009]])
Ajouter la même colonne à toutes les colonnes.
[21]:
mat + numpy.array([[0, 10, 100]]).T
[21]:
array([[ 0, 5, 6, -3],
[ 16, 17, 6, 18],
[ 95, 108, 96, 109]])
La maîtrise des index¶
[22]:
mat = numpy.array([[0, 5, 6, -3], [6, 7, -4, 8], [-5, 8, -4, 9]])
mat
[22]:
array([[ 0, 5, 6, -3],
[ 6, 7, -4, 8],
[-5, 8, -4, 9]])
Comparer tous les éléments du tableau à une constante (en utilisant le broadcasting).
[25]:
mat == 5
[25]:
array([[False, True, False, False],
[False, False, False, False],
[False, False, False, False]])
[26]:
mat == numpy.array([[0, -4, 9]]).T
[26]:
array([[ True, False, False, False],
[False, False, True, False],
[False, False, False, True]])
[27]:
(mat == numpy.array([[0, -4, 9]]).T).astype(numpy.int64)
[27]:
array([[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
Effectuer une comparaison et convertir le résultat en entier puis le multiplier à la matrice de départ. Le code suivant ne garde que les éléments qui valent -4 sur la seconde ligne et 9 sur la troisième. Tous les autres sont nuls.
[30]:
mat * (mat == numpy.array([[0, -4, 9]]).T).astype(numpy.int64)
[30]:
array([[ 0, 0, 0, 0],
[ 0, 0, -4, 0],
[ 0, 0, 0, 9]])
La maîtrise des opérations et des fonctions¶
On peut regrouper les opérations que numpy propose en différents thèmes. Mais avant il
L”initialisation : array, empty, zeros, ones, full, identity, rand, randn, randint
Les opérations basiques :
+,-,*,/,@, dotLes transformations : transpose, hstack, vstack, reshape, squeeze, expend_dims
Les opérations de réduction : minimum, maximum, argmin, argmax, sum, mean, prod, var, std
Tout le reste comme la génération de matrices aléatoires, le calcul des valeurs, vecteurs propres, des fonctions commme take, …
Q1 : calculer la valeur du  d’un tableau de contingence¶
d’un tableau de contingence¶
La formule est là. Et il faut le faire sans boucle. Vous pouvez comparer avec la fonction chisquare de la librairie scipy qui est une extension de numpy.

[22]:
Q2 : calculer une distribution un peu particulière¶
La fonction histogram permet de calculer la distribution empirique de variables. Pour cette question, on tire un vecteur aléatoire de taille 10 avec la fonction rand, on les trie par ordre croissant, on recommence plein de fois, on calcule la distribution du plus grand nombre, du second plus grand nombre, …, du plus petit nombre.
[23]:
Q3 : on veut créer une matrice identité un million par un million¶
Vous pouvez essayer sans réfléchir ou lire cette page d’abord : csr_matrix.
[24]:
Q4 : vous devez créer l’application StopCovid¶
Il existe une machine qui reçoit la position de 3 millions de téléphones portable. On veut identifier les cas contacts (rapidement).
[25]:
Réponses¶
Q1 : calculer la valeur du d’un tableau de contingence¶
La formule est là. Et il faut le faire sans boucle. Vous pouvez comparer avec la fonction chisquare de la librairie scipy qui est une extension de numpy.
[26]:
import numpy
O = numpy.array([[15.0, 20.0, 13.0], [4.0, 9.0, 5.0]])
O
[26]:
array([[15., 20., 13.],
[ 4., 9., 5.]])
[27]:
def chi_square(O):
N = numpy.sum(O)
pis = numpy.sum(O, axis=1, keepdims=True) / N
pjs = numpy.sum(O, axis=0, keepdims=True) / N
pispjs = pis @ pjs
chi = pispjs * ((O / N - pispjs) / pispjs) ** 2
return numpy.sum(chi) * N
chi_square(O)
[27]:
0.5798254016266716
Q2 : calculer une distribution un peu particulière¶
La fonction histogram permet de calculer la distribution empirique de variables. Pour cette question, on tire un vecteur aléatoire de taille 10 avec la fonction rand, on les trie par ordre croissant, on recommence plein de fois, on calcule la distribution du plus grand nombre, du second plus grand nombre, …, du plus petit nombre.
[28]:
rnd = numpy.random.rand(10)
rnd
[28]:
array([0.98556467, 0.47377301, 0.77148185, 0.26135908, 0.27373018,
0.0240458 , 0.55360714, 0.3575369 , 0.71740732, 0.3260206 ])
[29]:
numpy.sort(rnd)
[29]:
array([0.0240458 , 0.26135908, 0.27373018, 0.3260206 , 0.3575369 ,
0.47377301, 0.55360714, 0.71740732, 0.77148185, 0.98556467])
[30]:
def tirage(n):
rnd = numpy.random.rand(n)
trie = numpy.sort(rnd)
return trie[-1]
tirage(10)
[30]:
0.876020129318981
[31]:
def plusieurs_tirages(N, n):
rnd = numpy.random.rand(N, n)
return numpy.max(rnd, axis=1)
plusieurs_tirages(5, 10)
[31]:
array([0.99594032, 0.67914189, 0.98105965, 0.93181536, 0.86827764])
[32]:
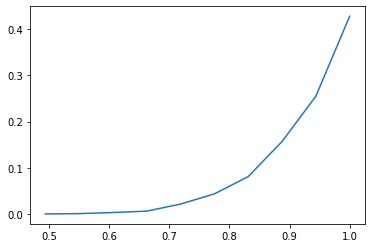
t = plusieurs_tirages(5000, 10)
hist = numpy.histogram(t)
hist
[32]:
(array([ 5, 8, 20, 35, 111, 221, 407, 785, 1273, 2135],
dtype=int64),
array([0.437878 , 0.49408914, 0.55030028, 0.60651142, 0.66272256,
0.7189337 , 0.77514485, 0.83135599, 0.88756713, 0.94377827,
0.99998941]))
[33]:
import matplotlib.pyplot as plt
plt.plot(hist[1][1:], hist[0] / hist[0].sum());
Q3 : on veut créer une matrice identité un million par un million¶
Vous pouvez essayer sans réfléchir ou lire cette page d’abord : csr_matrix.
 >10 Go, bref ça ne tient pas en mémoire sauf si on a une grosse machine. Les matrices creuses (ou sparses en anglais), sont adéquates pour représenter des matrices dont la grande majorité des coefficients sont nuls car ceux-ci ne sont pas stockés. Concrètement, la matrice enregistre uniquement les coordonnées des coefficients et les valeurs non nuls.
>10 Go, bref ça ne tient pas en mémoire sauf si on a une grosse machine. Les matrices creuses (ou sparses en anglais), sont adéquates pour représenter des matrices dont la grande majorité des coefficients sont nuls car ceux-ci ne sont pas stockés. Concrètement, la matrice enregistre uniquement les coordonnées des coefficients et les valeurs non nuls.
[34]:
import numpy
from scipy.sparse import csr_matrix
ide = csr_matrix((1000000, 1000000), dtype=numpy.float64)
ide.setdiag(1.0)
c:\python395_x64\lib\site-packages\scipy\sparse\_index.py:125: SparseEfficiencyWarning: Changing the sparsity structure of a csr_matrix is expensive. lil_matrix is more efficient.
self._set_arrayXarray(i, j, x)
Q4 : vous devez créer l’application StopCovid¶
Il existe une machine qui reçoit la position de 3 millions de téléphones portable. On veut identifier les cas contacts (rapidement).
Si on devait calculer toutes les paires de distance, cela prendrait un temps fou. Il faut ruser. Le plus simple est de construire une grille sur le territoire français puis d’associer à chaque téléphone portable la grille dans laquelle il se trouve. Dans une cellule de la grille, le nombre de paires est beaucoup plus réduit. Ce n’est pas la seule astuce qu’il faudra utiliser. Mais c’est un bon début.
[35]: