Tri plus rapide que prévu¶
Dans le cas général, le coût d’un algorithme de tri est en  . Mais il existe des cas particuliers pour lesquels on peut faire plus court. Par exemple, on suppose que l’ensemble à trier contient plein de fois le même élément.
. Mais il existe des cas particuliers pour lesquels on peut faire plus court. Par exemple, on suppose que l’ensemble à trier contient plein de fois le même élément.
[21]:
%matplotlib inline
trier un plus petit ensemble¶
[22]:
import random
ens = [random.randint(0, 99) for i in range(10000)]
On peut calculer la distribution de ces éléments.
[23]:
def histogram(ens):
hist = {}
for e in ens:
hist[e] = hist.get(e, 0) + 1
return hist
hist = histogram(ens)
list(hist.items())[:5]
[23]:
[(35, 106), (50, 111), (32, 103), (18, 102), (78, 105)]
Plutôt que de trier le tableau initial, on peut trier l’histogramme qui contient moins d’élément.
[24]:
sorted_hist = list(hist.items())
sorted_hist.sort()
Puis on recontruit le tableau initial mais trié :
[25]:
def tableau(sorted_hist):
res = []
for k, v in sorted_hist:
for i in range(v):
res.append(k)
return res
sorted_ens = tableau(sorted_hist)
sorted_ens[:5]
[25]:
[0, 0, 0, 0, 0]
On crée une fonction qui assemble toutes les opérations. Le coût du nouveau tri est en  où
où  est le nombre d’éléments distincts de l’ensemble initial.
est le nombre d’éléments distincts de l’ensemble initial.
[26]:
def sort_with_hist(ens):
hist = histogram(ens)
sorted_hist = list(hist.items())
sorted_hist.sort()
return tableau(sorted_hist)
from random import shuffle
shuffle(ens)
%timeit sort_with_hist(ens)
599 μs ± 50 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
[27]:
def sort_with_nohist(ens):
return list(sorted(ens))
[28]:
shuffle(ens)
%timeit sort_with_nohist(ens)
1.11 ms ± 88.9 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Les temps d’exécution ne sont pas très probants car la fonction sort est immplémentée en C et qu’elle utilise l’algorithme timsort. Cet algorithme est un algorithme adaptatif tel que smoothsort. Le coût varie en fonction des données à trier. Il identifie d’abord les séquences déjà triées, trie les autres parties et fusionne l’ensemble. Trier un tableau déjà trié revient à détecter qu’il est déjà trié.
Le coût est alors linéaire  . Cela explique le commentaire The slowest run took 19.47 times longer than the fastest. ci-dessous où le premier tri est beaucoup plus long que les suivant qui s’appliquent à un tableau déjà trié. Quoiqu’il en soit, il n’est pas facile de comparer les deux implémentations en terme de temps.
. Cela explique le commentaire The slowest run took 19.47 times longer than the fastest. ci-dessous où le premier tri est beaucoup plus long que les suivant qui s’appliquent à un tableau déjà trié. Quoiqu’il en soit, il n’est pas facile de comparer les deux implémentations en terme de temps.
[29]:
def sort_with_nohist_nocopy(ens):
ens.sort()
return ens
shuffle(ens)
%timeit sort_with_nohist_nocopy(ens)
23.6 μs ± 2.33 μs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
évolution en fonction de n¶
Pour réussir à valider l’idée de départ. On regarde l’évolution des deux algorithmes en fonction du nombre d’observations.
[30]:
def tableaux_aleatoires(ns, d):
for n in ns:
yield [random.randint(0, d - 1) for i in range(n)]
import pandas
import time
def mesure(enss, fonc):
res = []
for ens in enss:
cl = time.perf_counter()
fonc(ens)
diff = time.perf_counter() - cl
res.append(dict(n=len(ens), time=diff))
return pandas.DataFrame(res)
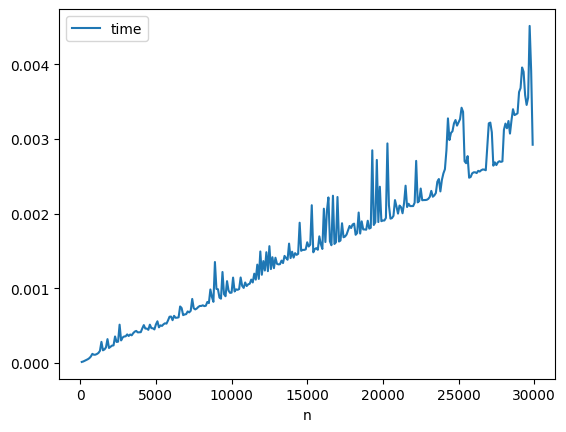
df = mesure(tableaux_aleatoires(range(100, 30000, 100), 100), sort_with_nohist)
df.plot(x="n", y="time");
[31]:
df = mesure(tableaux_aleatoires(range(100, 30000, 100), 100), sort_with_hist)
df.plot(x="n", y="time");
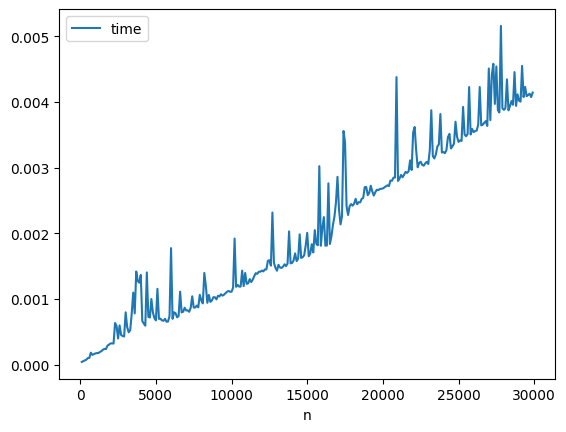
L’algorithme de tri de Python est plutôt efficace puisque son coût paraît linéaire en apparence.
[32]:
df = mesure(tableaux_aleatoires(range(100, 30000, 200), int(1e10)), sort_with_nohist)
df.plot(x="n", y="time");
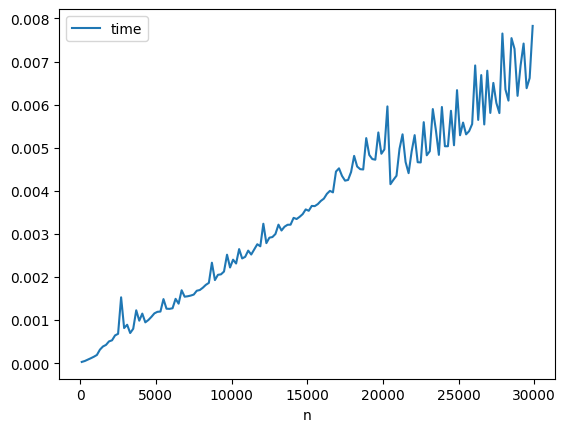
On ajoute un logarithme.
[33]:
from math import log
df["nlnn"] = df["n"] * df["n"].apply(log) * 4.6e-8
df.plot(x="n", y=["time", "nlnn"]);
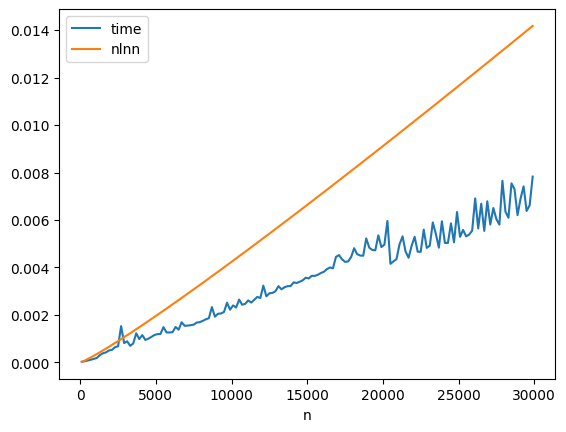
Il faut grossier le trait.
[34]:
from math import exp
list(map(int, map(exp, range(5, 14))))
[34]:
[148, 403, 1096, 2980, 8103, 22026, 59874, 162754, 442413]
[42]:
h100 = list(tableaux_aleatoires(map(int, map(exp, range(5, 14))), 100))
df100 = mesure(h100, sort_with_nohist)
hm = list(tableaux_aleatoires(map(int, map(exp, range(5, 14))), int(1e9)))
dfM = mesure(hm, sort_with_nohist)
df = df100.copy()
df.columns = ["n", "d=100"]
df["d=1e9"] = dfM["time"]
df.plot(
x="n",
y=["d=100", "d=1e9"],
title=f"Nombre d'éléments uniques\nd=100: {len(set(h100[-1]))}\nd=1e9: {len(set(hm[-1]))}",
);
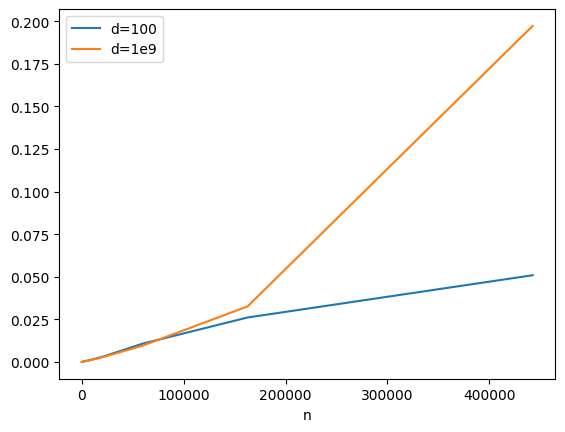
L’algorithme de tri timsort est optimisé pour le cas où le nombre de valeurs distinctes est faible par rapport à la taille du tableau à trier.
[ ]: