Régression Ridge, Lasso et nouvel estimateur¶
Ce notebook présente la régression Ridge, Lasso, et l’API de scikit-learn. Il explique plus en détail pourquoi la régression Lasso contraint les coefficients de la régression à s’annuler.
[4]:
%matplotlib inline
Un jeu de données pour un problème de régression¶
[5]:
from sklearn.datasets import load_diabetes
data = load_diabetes()
X, y = data.data, data.target / 10
/ 10 ou normaliser pour éviter les problèmes numériques lors que l’optimisation.
[6]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
On apprend la première régression linéaire.
[7]:
from sklearn.linear_model import LinearRegression
lin = LinearRegression()
lin.fit(X_train, y_train)
lin.coef_
[7]:
array([ 0.56507947, -24.63366763, 51.67654224, 34.74727391,
-79.27261232, 43.79683015, 14.9985268 , 27.18645867,
64.50606168, 11.08885871])
[8]:
from sklearn.metrics import r2_score
r2_score(y_test, lin.predict(X_test))
[8]:
0.5338804549709038
Régression Ridge¶
La régression Ridge optimise le problème qui suit :

C’est une régression linéaire avec une contrainte quadratique sur les coefficients. C’est utile lorsque les variables sont très corrélées, ce qui fausse souvent la résolution numérique. La solution peut s’exprimer de façon exacte.

On voit qu’il est possible de choisir un  pour lequel la matrice
pour lequel la matrice  est inversible. C’est aussi utile lorsqu’il y a beaucoup de variables car la probabilité d’avoir des variables corrélées est grande. Il est possible de choisir un suffisamment grand pour que la matrice
est inversible. C’est aussi utile lorsqu’il y a beaucoup de variables car la probabilité d’avoir des variables corrélées est grande. Il est possible de choisir un suffisamment grand pour que la matrice  soit inversible et la solution unique.
soit inversible et la solution unique.
[9]:
from sklearn.linear_model import Ridge
rid = Ridge(10).fit(X_train, y_train)
r2_score(y_test, rid.predict(X_test))
[9]:
0.14638204850109837
[10]:
(r2_score(y_train, lin.predict(X_train)), r2_score(y_train, rid.predict(X_train)))
[10]:
(0.5078580798207908, 0.1546076751624358)
La contrainte introduite sur les coefficients augmente l’erreur sur la base d’apprentissage mais réduit la norme des coefficients.
[11]:
import numpy
import matplotlib.pyplot as plt
r = numpy.abs(lin.coef_) / numpy.abs(rid.coef_)
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
ax.plot(r)
ax.set_title("Ratio des coefficients\npour une régression Ridge");
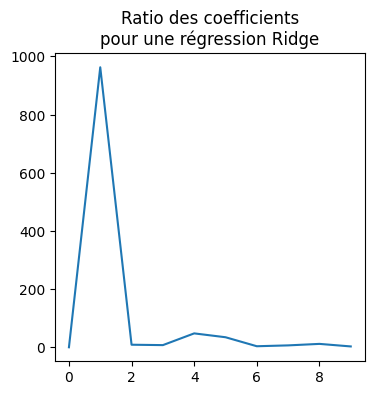
Un des coefficients est 10 fois plus grand et la norme des coefficients est plus petite.
[12]:
numpy.linalg.norm(lin.coef_), numpy.linalg.norm(rid.coef_)
[12]:
(133.92288256836204, 11.468149305335954)
De fait, il est préféreable de normaliser les variables avant d’appliquer la contrainte.
[13]:
rid = Ridge(0.2).fit(X_train, y_train)
r2_score(y_test, rid.predict(X_test))
[13]:
0.5109393397213065
[14]:
numpy.linalg.norm(lin.coef_), numpy.linalg.norm(rid.coef_)
[14]:
(133.92288256836204, 69.14560512791194)
Régression Lasso¶
La régression Lasso optimise le problème qui suit :

C’est une régression linéaire avec une contrainte linéaire sur les coefficients. C’est utile lorsque les variables sont très corrélées, ce qui fausse souvent la résolution numérique. La solution ne s’exprime de façon exacte et la résolution utilise une méthode à base de gradient.
[15]:
from sklearn.linear_model import Lasso
las = Lasso(5.0).fit(X_train, y_train)
las.coef_
[15]:
array([ 0., 0., 0., 0., 0., 0., -0., 0., 0., 0.])
On voit que beaucoup de coefficients sont nuls.
[16]:
las.coef_ == 0
[16]:
array([ True, True, True, True, True, True, True, True, True,
True])
[17]:
sum(las.coef_ == 0)
[17]:
10
Comme pour la régression Ridge, il est préférable de normaliser. On étudie également le nombre de coefficients nuls en fonction de la valeur .
[18]:
from tqdm import tqdm
res = []
for alf in tqdm(
[
0.00001,
0.0001,
0.005,
0.01,
0.015,
0.02,
0.025,
0.03,
0.04,
0.05,
0.06,
0.07,
0.08,
0.09,
0.1,
0.2,
0.3,
0.4,
]
):
las = Lasso(alf).fit(X_train, y_train)
r2 = r2_score(y_test, las.predict(X_test))
res.append({"lambda": alf, "r2": r2, "nbnull": sum(las.coef_ == 0)})
from pandas import DataFrame
df = DataFrame(res)
df.head(5)
100%|██████████| 18/18 [00:00<00:00, 354.37it/s]
[18]:
| lambda | r2 | nbnull | |
|---|---|---|---|
| 0 | 0.00001 | 0.533887 | 0 |
| 1 | 0.00010 | 0.533923 | 0 |
| 2 | 0.00500 | 0.533023 | 2 |
| 3 | 0.01000 | 0.529573 | 3 |
| 4 | 0.01500 | 0.522538 | 3 |
[19]:
fig, ax = plt.subplots(1, 2, figsize=(8, 3))
ax[0].plot(df["lambda"], df["r2"], label="r2")
ax[1].plot(df["lambda"], df["nbnull"], label="nbnull")
ax[1].plot(df["lambda"], las.coef_.shape[0] - df["nbnull"], label="nbvar")
ax[0].set_xscale("log")
ax[1].set_xscale("log")
ax[0].set_xlabel("lambda")
ax[1].set_xlabel("lambda")
ax[0].legend()
ax[1].legend();
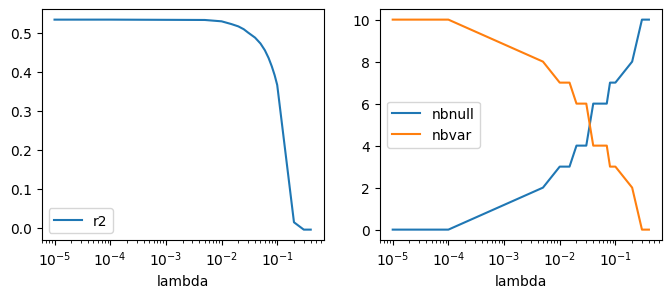
La régression Lasso annule les coefficients, voire tous les coefficients si le paramètre est assez grand. Voyons cela pour une régression avec une seule variable. On doit minimiser l’expression :

Trouver  qui minimise l’expression nécessite de trouver le paramètre
qui minimise l’expression nécessite de trouver le paramètre  tel que
tel que  . On calcule la dérivée
. On calcule la dérivée  :
:

Et :

On voit que pour une grande valeur de  , le paramètre n’a pas de solution. Dans le premier cas, la valeur est nécessairement négative alors que la solution ne fonctionne que si est positive. C’est la même situation contradictoire dans l’autre cas. La seule option possible lorsque est très grand, c’est
, le paramètre n’a pas de solution. Dans le premier cas, la valeur est nécessairement négative alors que la solution ne fonctionne que si est positive. C’est la même situation contradictoire dans l’autre cas. La seule option possible lorsque est très grand, c’est  . On montre donc que ce qu’on a observé ci-dessus est vrai pour une régression à une dimension.
. On montre donc que ce qu’on a observé ci-dessus est vrai pour une régression à une dimension.
Application à la sélection d’arbre d’une forêt aléatoire¶
Une forêt aléatoire est simplement une moyenne des prédictions d’arbres de régression.

Pourquoi ne pas utiliser une régression Lasso pour réduire le nombre d’arbres et exprimer la forêt aléatoire avec des coefficients estimés à l’aide d’une régression Lasso et choisis de telle sorte que beaucoup soient nuls.

[20]:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(100).fit(X_train, y_train)
La prédiction d’un arbre s’obtient avec :
[21]:
rf.estimators_[0].predict(X_test)
[21]:
array([ 3.9, 9.7, 16.4, 31.1, 3.9, 27.5, 28.1, 5.1, 18.3, 4.3, 10.2,
27. , 25.7, 26.5, 8.7, 5.5, 9.7, 6.9, 11.6, 9.6, 9.6, 12.4,
14.4, 6.7, 7.8, 4.8, 9.7, 7.2, 5.2, 25.9, 30.3, 19.6, 6.4,
17.3, 7.5, 17.3, 5.2, 31.7, 6.9, 5.5, 30.3, 9.7, 28.8, 30.6,
7.2, 25.3, 11.3, 20. , 28.8, 10.1, 9.1, 14.4, 28.8, 5.9, 11.6,
14.4, 28.1, 14.3, 26.5, 15.2, 20. , 7.8, 9.6, 7. , 4.8, 30.8,
16.4, 6.9, 8.5, 20.9, 31.1, 20.6, 13.4, 7. , 14.4, 5.2, 8.5,
20.1, 18.6, 15.1, 9. , 14.3, 30.8, 12.5, 5.2, 23.7, 11.6, 20.2,
20.9, 17.8, 23.6, 14.4, 20. , 16. , 21.4, 13.1, 25.7, 17.8, 7.8,
16.4, 12.2, 17.2, 20.9, 18.5, 6.9, 10.1, 21.7, 12.9, 12.8, 29.2,
17.3])
On construit une fonction qui concatène les prédictions des arbres.
[22]:
def concatenate_prediction(X):
preds = []
for i in range(len(rf.estimators_)):
pred = rf.estimators_[i].predict(X)
preds.append(pred)
return numpy.vstack(preds).T
concatenate_prediction(X_test).shape
[22]:
(111, 100)
Et on observe la performance en fonction du paramètre de la régression Lasso.
[23]:
X_train_rf = concatenate_prediction(X_train)
X_test_rf = concatenate_prediction(X_test)
res = []
for alf in tqdm(
[
0.0001,
0.01,
0.1,
0.2,
0.5,
1.0,
1.2,
1.5,
2.0,
4.0,
6.0,
8.0,
10.0,
12.0,
14,
16,
18,
20,
]
):
las = Lasso(alf, max_iter=40000).fit(X_train_rf, y_train)
r2 = r2_score(y_test, las.predict(X_test_rf))
r2_rf = r2_score(y_test, rf.predict(X_test))
res.append({"lambda": alf, "r2": r2, "r2_rf": r2_rf, "nbnull": sum(las.coef_ == 0)})
0%| | 0/18 [00:00<?, ?it/s]100%|██████████| 18/18 [00:03<00:00, 5.14it/s]
[24]:
df = DataFrame(res)
df.head(3)
[24]:
| lambda | r2 | r2_rf | nbnull | |
|---|---|---|---|---|
| 0 | 0.0001 | 0.436048 | 0.477698 | 0 |
| 1 | 0.0100 | 0.437957 | 0.477698 | 2 |
| 2 | 0.1000 | 0.453785 | 0.477698 | 18 |
[25]:
fig, ax = plt.subplots(1, 2, figsize=(8, 3))
ax[0].plot(df["lambda"], df["r2"], label="r2")
ax[0].plot(df["lambda"], df["r2_rf"], label="r2_rf")
ax[1].plot(df["lambda"], df["nbnull"], label="nbnull")
ax[1].plot(df["lambda"], las.coef_.shape[0] - df["nbnull"], label="nbvar")
ax[0].set_xscale("log")
ax[1].set_xscale("log")
ax[0].legend()
ax[1].legend();
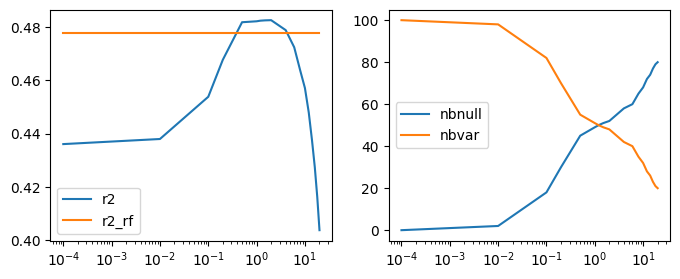
Explication géométrique de la nullité des coefficients dans une régression Lasso¶
On se place dans le cas d’un modèle très simple :  . Les coefficients optimaux sont obtenus en minimisant l’erreur
. Les coefficients optimaux sont obtenus en minimisant l’erreur  . On note
. On note  .
.  est l’erreur de régression,
est l’erreur de régression,  est l’erreur de Lasso. Les coefficients optimaux pour l’erreur sont
est l’erreur de Lasso. Les coefficients optimaux pour l’erreur sont  . On représente
maintenant sur un graphe les courbes de niveaux de ces deux erreurs.
. On représente
maintenant sur un graphe les courbes de niveaux de ces deux erreurs.
[26]:
import math
def xyl1(t):
return t, numpy.minimum(1 - t, t + 1)
def xyl2(t):
return t, numpy.minimum(2.3 - t, t + 2.3)
def xyl3(t):
return t, 0.4 - t
t = numpy.arange(1000) * 2 * math.pi / 1000
t2 = numpy.arange(500) / 500 - 0.2
fig, ax = plt.subplots(1, 1)
# ax.text(0.35, 2.7, "lambda1")
# ax.text(0.05, 2.5, "lambda2")
ax.plot([0.66], [1.66], "yo", label="a^*", ms=10)
ax.plot([0.0], [1.0], "yo", ms=10)
ax.plot([0.0], [0.5], "yo", ms=10)
# ax.plot([0.0], [2.5], "yo")
ax.plot([0, 0], [0, 3], "k--")
ax.plot([0, 2], [0, 0], "k--")
ax.plot(numpy.cos(t) * 0.5 + 1, numpy.sin(t) * 0.5 + 2, "g", label="Er")
ax.plot(numpy.cos(t) * 2**0.5 + 1, numpy.sin(t) * 2**0.5 + 2, "g", lw=4)
ax.plot(numpy.cos(t) * 1.8 + 1, numpy.sin(t) * 1.8 + 2, "g", lw=6)
x, y = xyl1(t2)
ax.plot(x, y, "r", label="El")
x, y = xyl2(t2)
ax.plot(x, y, "r", lw=4)
x, y = xyl3(t2 - 0.5)
ax.plot(x, y, "r--", lw=2)
ax.legend();
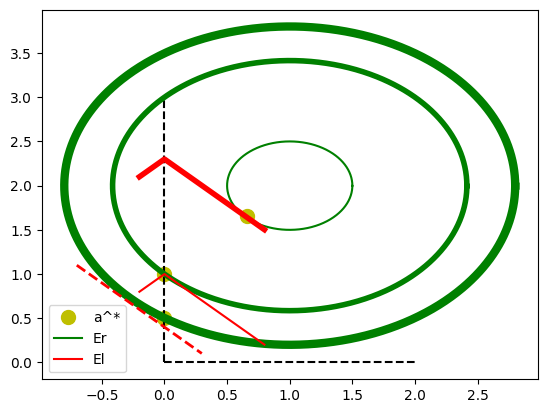
reste constante sur un cercle. reste constante sur une droite. Le point optimal solution de la régression Ridge est sur la tangente entre le cercle et la droite. Lorsqu’on augmente  , il faut réduire l’erreur, donc passer sur une courbe de niveaux plus grande pour l’erreur . Il arrive un moment où ce point tangent est situé sur un des axes. Ensuite, ce point tangent est situé de l’autre côté de l’axe et en annulant le coefficient
, il faut réduire l’erreur, donc passer sur une courbe de niveaux plus grande pour l’erreur . Il arrive un moment où ce point tangent est situé sur un des axes. Ensuite, ce point tangent est situé de l’autre côté de l’axe et en annulant le coefficient  , on
décroît à la fois et . Vérifions numériquement sur une exemple en estimant les coefficients d’une régression Lasso en deux dimensions
, on
décroît à la fois et . Vérifions numériquement sur une exemple en estimant les coefficients d’une régression Lasso en deux dimensions  et en faisant varier la paramètre de la contrainte.
et en faisant varier la paramètre de la contrainte.
[27]:
import warnings
from sklearn.metrics import mean_squared_error
import pandas
X = numpy.random.randn(100, 2) + 1.0
X[:, 1] += 1.0
y = numpy.sum(X, axis=1) + X[:, 1] + numpy.random.randn(100) / 10
def train_lasso(X, y, c):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
lasso = Lasso(c, fit_intercept=False)
lasso.fit(X, y)
Er = mean_squared_error(y, lasso.predict(X))
El = numpy.abs(lasso.coef_).sum() * c
return Er, El, lasso.coef_
obs = []
for i in tqdm(range(0, 61)):
c = i / 4.0
Er, El, coef = train_lasso(X, y, c)
obs.append(dict(c=c, Er=Er, El=El, E=Er + El, a1=coef[0], a2=coef[1]))
df = pandas.DataFrame(obs).set_index("c")
fig, ax = plt.subplots(1, 4, figsize=(14, 4))
ax[0].plot(X[:, 0], X[:, 1], ".", label="X")
ax[0].set_title("Features")
ax[0].set_xlabel("x1")
ax[0].set_ylabel("x2")
df[["Er", "El", "E"]].plot(ax=ax[1])
ax[1].set_title("Errors")
ax[1].set_xlabel("lambda")
ax[1].set_ylabel("Errors")
df.plot.scatter(x="a1", y="a2", ax=ax[2])
ax[2].set_title("Coefficients de la régression")
ax[2].set_xlabel("a1")
ax[2].set_ylabel("a2")
df[["a1", "a2"]].plot(ax=ax[3])
ax[3].set_title("Coefficients")
ax[3].set_xlabel("lambda")
ax[3].set_ylabel("Coefficients");
100%|██████████| 61/61 [00:00<00:00, 331.56it/s]
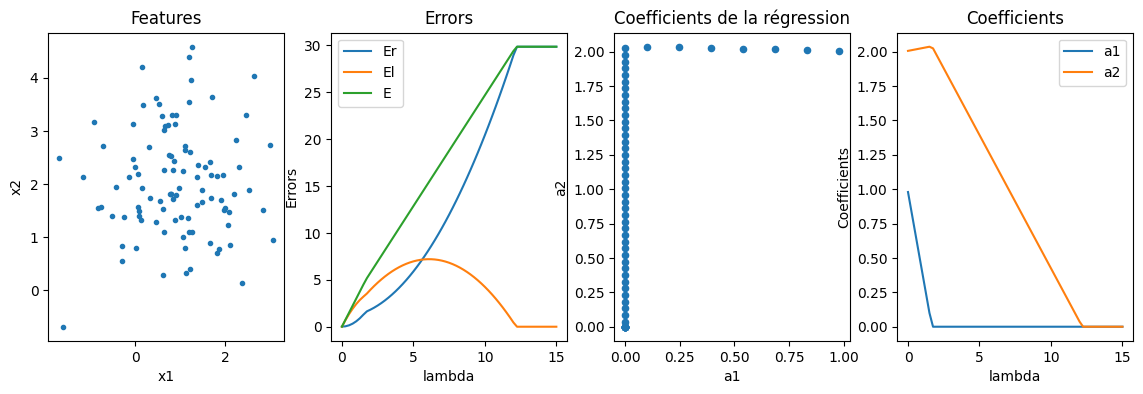
On retrouve numériquement le résultat énoncé ci-dessus.
Validation croisée et API scikit-learn¶
La validation croisée est simple à faire dans scikit-learn est simple à faire si le modèle suit l’API de scikit-learn mais ce n’est pas le cas avec notre nouveau modèle. C’est pourtant essentiel pour s’assurer que le modèle est robuste. Toutefois scikit-learn permet de créer de nouveau modèle à la sauce scikit-learn.
[28]:
from sklearn.base import BaseEstimator, RegressorMixin
class LassoRandomForestRegressor(BaseEstimator, RegressorMixin):
def __init__(
self,
# Lasso
alpha=1.0,
fit_intercept=True,
precompute=False,
copy_X=True,
max_iter=1000,
tol=1e-4,
warm_start_lasso=False,
positive=False,
random_state=None,
selection="cyclic",
# RF
n_estimators=100,
criterion="squared_error",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=1.0,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
# random_state=None,
verbose=0,
warm_start_rf=False,
ccp_alpha=0.0,
max_samples=None,
):
# Lasso
self.alpha = alpha
self.fit_intercept = fit_intercept
self.precompute = precompute
self.copy_X = copy_X
self.max_iter = max_iter
self.tol = tol
self.warm_start_lasso = warm_start_lasso
self.positive = positive
self.random_state = random_state
self.selection = selection
# RF
self.n_estimators = n_estimators
self.criterion = criterion
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.min_samples_leaf = min_samples_leaf
self.min_weight_fraction_leaf = min_weight_fraction_leaf
self.max_features = max_features
self.max_leaf_nodes = max_leaf_nodes
self.min_impurity_decrease = min_impurity_decrease
self.bootstrap = bootstrap
self.oob_score = oob_score
self.n_jobs = n_jobs
self.random_state = random_state
self.verbose = verbose
self.warm_start_rf = warm_start_rf
self.ccp_alpha = ccp_alpha
self.max_samples = max_samples
def _concatenate_prediction(self, X):
preds = []
for i in range(len(self.rf_.estimators_)):
pred = self.rf_.estimators_[i].predict(X)
preds.append(pred)
return numpy.vstack(preds).T
def fit(self, X, y, sample_weight=None):
self.rf_ = RandomForestRegressor(
n_estimators=self.n_estimators,
criterion=self.criterion,
max_depth=self.max_depth,
min_samples_split=self.min_samples_split,
min_samples_leaf=self.min_samples_leaf,
min_weight_fraction_leaf=self.min_weight_fraction_leaf,
max_features=self.max_features,
max_leaf_nodes=self.max_leaf_nodes,
min_impurity_decrease=self.min_impurity_decrease,
bootstrap=self.bootstrap,
oob_score=self.oob_score,
n_jobs=self.n_jobs,
random_state=self.random_state,
verbose=self.verbose,
warm_start=self.warm_start_rf,
ccp_alpha=self.ccp_alpha,
max_samples=self.max_samples,
)
self.rf_.fit(X, y, sample_weight=sample_weight)
X_rf = self._concatenate_prediction(X)
self.lasso_ = Lasso(
alpha=self.alpha,
max_iter=self.max_iter,
fit_intercept=self.fit_intercept,
precompute=self.precompute,
copy_X=self.copy_X,
tol=self.tol,
warm_start=self.warm_start_lasso,
positive=self.positive,
random_state=self.random_state,
selection=self.selection,
)
self.lasso_.fit(X_rf, y)
return self
def predict(self, X):
X_rf = self._concatenate_prediction(X)
return self.lasso_.predict(X_rf)
model = LassoRandomForestRegressor(alpha=1, n_estimators=100, max_iter=10000)
model.fit(X_train, y_train)
pred = model.predict(X_test)
r2_score(y_test, pred)
[28]:
0.47415783259761723
Et la validation croisée fut :
[29]:
from sklearn.model_selection import cross_val_score
cross_val_score(model, X_train, y_train, cv=5)
[29]:
array([0.26413444, 0.49396068, 0.44598638, 0.52062164, 0.10872839])
Ce n’est pas très robuste. Peut-être est-ce dû à l’ordre des données (un léger effet temporel).
[30]:
from sklearn.model_selection import ShuffleSplit
cross_val_score(
LassoRandomForestRegressor(n_estimators=100, alpha=10, max_iter=10000),
X_train,
y_train,
cv=ShuffleSplit(5),
)
[30]:
array([0.23637803, 0.33097263, 0.35233357, 0.40361275, 0.45858455])
Pas beaucoup mieux. Le modèle n’est pas très robuste.
On essaye néanmoins de trouver les meilleurs paramètres à l’aide d’une grille de recherche.
[40]:
from sklearn.model_selection import GridSearchCV
params = {
"alpha": [0.1, 0.5, 1.0, 2.0, 5.0, 10],
"n_estimators": [10, 20, 50],
"max_iter": [10000],
}
grid = GridSearchCV(LassoRandomForestRegressor(), param_grid=params, verbose=1)
grid.fit(X_train, y_train)
Fitting 5 folds for each of 18 candidates, totalling 90 fits
[40]:
GridSearchCV(estimator=LassoRandomForestRegressor(),
param_grid={'alpha': [0.1, 0.5, 1.0, 2.0, 5.0, 10],
'max_iter': [10000], 'n_estimators': [10, 20, 50]},
verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=LassoRandomForestRegressor(),
param_grid={'alpha': [0.1, 0.5, 1.0, 2.0, 5.0, 10],
'max_iter': [10000], 'n_estimators': [10, 20, 50]},
verbose=1)LassoRandomForestRegressor()
LassoRandomForestRegressor()
[41]:
grid.best_params_
[41]:
{'alpha': 10, 'max_iter': 10000, 'n_estimators': 50}
[42]:
r2_score(y_test, grid.best_estimator_.predict(X_test))
[42]:
0.44775063104195545
[43]:
sum(grid.best_estimator_.lasso_.coef_ == 0)
[43]:
25
On a réussi à supprimer 27 arbres.
Optimisation mémoire¶
Le modèle précédent n’est pas optimal dans le sens où il stocke en mémoire tous les arbres, mêmes ceux associés à un coefficient nuls après la régression Lasso alors que le calcul ne sert à rien puisque ignoré.
[44]:
class OptimizedLassoRandomForestRegressor(BaseEstimator, RegressorMixin):
def __init__(
self,
# Lasso
alpha=1.0,
fit_intercept=True,
precompute=False,
copy_X=True,
max_iter=1000,
tol=1e-4,
warm_start_lasso=False,
positive=False,
random_state=None,
selection="cyclic",
# RF
n_estimators=100,
criterion="squared_error",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=1.0,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
# random_state=None,
verbose=0,
warm_start_rf=False,
ccp_alpha=0.0,
max_samples=None,
):
# Lasso
self.alpha = alpha
self.fit_intercept = fit_intercept
self.precompute = precompute
self.copy_X = copy_X
self.max_iter = max_iter
self.tol = tol
self.warm_start_lasso = warm_start_lasso
self.positive = positive
self.random_state = random_state
self.selection = selection
# RF
self.n_estimators = n_estimators
self.criterion = criterion
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.min_samples_leaf = min_samples_leaf
self.min_weight_fraction_leaf = min_weight_fraction_leaf
self.max_features = max_features
self.max_leaf_nodes = max_leaf_nodes
self.min_impurity_decrease = min_impurity_decrease
self.bootstrap = bootstrap
self.oob_score = oob_score
self.n_jobs = n_jobs
self.random_state = random_state
self.verbose = verbose
self.warm_start_rf = warm_start_rf
self.ccp_alpha = ccp_alpha
self.max_samples = max_samples
def _concatenate_prediction(self, X):
preds = []
for i in range(len(self.rf_.estimators_)):
pred = self.rf_.estimators_[i].predict(X)
preds.append(pred)
return numpy.vstack(preds).T
def fit(self, X, y, sample_weight=None):
self.rf_ = RandomForestRegressor(
n_estimators=self.n_estimators,
criterion=self.criterion,
max_depth=self.max_depth,
min_samples_split=self.min_samples_split,
min_samples_leaf=self.min_samples_leaf,
min_weight_fraction_leaf=self.min_weight_fraction_leaf,
max_features=self.max_features,
max_leaf_nodes=self.max_leaf_nodes,
min_impurity_decrease=self.min_impurity_decrease,
bootstrap=self.bootstrap,
oob_score=self.oob_score,
n_jobs=self.n_jobs,
random_state=self.random_state,
verbose=self.verbose,
warm_start=self.warm_start_rf,
ccp_alpha=self.ccp_alpha,
max_samples=self.max_samples,
)
self.rf_.fit(X, y, sample_weight=sample_weight)
X_rf = self._concatenate_prediction(X)
self.lasso_ = Lasso(
alpha=self.alpha,
max_iter=self.max_iter,
fit_intercept=self.fit_intercept,
precompute=self.precompute,
copy_X=self.copy_X,
tol=self.tol,
warm_start=self.warm_start_lasso,
positive=self.positive,
random_state=self.random_state,
selection=self.selection,
)
self.lasso_.fit(X_rf, y)
# on ne garde que les arbres associées à des coefficients non nuls
self.coef_ = []
self.intercept_ = self.lasso_.intercept_
self.estimators_ = []
for i in range(len(self.rf_.estimators_)):
if self.lasso_.coef_[i] != 0:
self.estimators_.append(self.rf_.estimators_[i])
self.coef_.append(self.lasso_.coef_[i])
self.coef_ = numpy.array(self.coef_)
del self.lasso_
del self.rf_
return self
def predict(self, X):
preds = []
for i in range(len(self.estimators_)):
pred = self.estimators_[i].predict(X)
preds.append(pred)
x_rf = numpy.vstack(preds).T
return x_rf @ self.coef_ + self.intercept_
model2 = OptimizedLassoRandomForestRegressor()
model2.fit(X_train, y_train)
pred = model2.predict(X_test)
r2_score(y_test, pred)
[44]:
0.4731987666983202
Le modèle produit bien les mêmes résultats. Vérifions que le nouveau modèle prend moins de place une fois enregistré sur le disque.
[45]:
import pickle
with open("optimzed_rf.pickle", "wb") as f:
pickle.dump(model2, f)
[46]:
with open("optimzed_rf.pickle", "rb") as f:
model2 = pickle.load(f)
r2_score(y_test, model2.predict(X_test))
[46]:
0.4731987666983202
[47]:
with open("lasso_rf.pickle", "wb") as f:
pickle.dump(model, f)
[48]:
import os
os.stat("optimzed_rf.pickle").st_size, os.stat("lasso_rf.pickle").st_size
[48]:
(1354238, 2979576)
C’est bien le cas.