Quelques rappels¶
Sans rentrer véritablement dans le détail, cette partie rappelle quelques notions qui apparaissent à de nombreux endroits. Ces éléments mathématiques et informatiques sont nécessaires afin de comprendre comment fonctionnent les modèles de machine learning exposés.
Les illustrations sont soit faites maisons soit extraites de Wikipedia.
Rappels mathématiques¶
Fonction¶
Une fonction  symbolise le lien entre deux grandeurs
symbolise le lien entre deux grandeurs
 et
et  qu’on note
qu’on note
 ou
ou  .
Par exemple,
.
Par exemple,  est la fonction
qui associe à un nombre son carré.
Le graphe suivant représente ce lien :
est la fonction
qui associe à un nombre son carré.
Le graphe suivant représente ce lien :

Fonction continue¶
Une fonction continue
signifie en gros que si varie un petit peu, varie aussi un petit peu.
On exprime cette propriété comme suit en terme mathématique.

On résume visuellement cette propriété comme suit. La fonction de gauche est continue, celle de droite ne l’est pas.

Les puristes vous diront qu’il existe quelques cas intéressants qui sont trompeurs visuellement mais cela suffira pour comprendre les notions de machine learning.
Fonction dérivable¶
Beaucoup de fonctions continues sont dérivables mais ce qui est sûr,
c’est la fonction qui n’est pas continue en un point
ne peut pas être dérivable en ce point mais elle peut l’être ailleurs.
Et pour être plus précis, une fonction dérivable en un point
signifie, quand on y regarde de près, qu’elle n’est pas très loin de
ressembler à une droite.
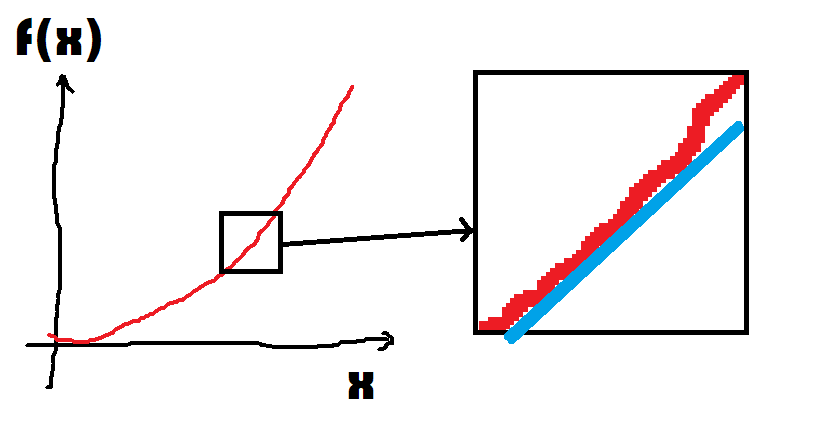
Et comme elle y ressemble fortement, on n’a pas besoin de la connaître
très bien pour savoir si on monte ou on descend quand on va à gauche
ou à droite. Il existe des fonctions qui sont si compliquées
à écrire que les connaître se révèle un défi. Quand elles sont dérivables,
on peut les confondre localement à une droite qu’on sait le plus souvent
calculer. C’est une information très précieuse quand on cherche à
trouver le minimum. Sans hésiter, sur ce dessin, vous iriez à gauche,
et tout ça grâce au fait que la fonction est dérivable.
Mathématiquement, cela signifie que la fonction  admet une
limite lorsque
admet une
limite lorsque  tend vers 0.
tend vers 0.

Espace vectoriel¶
Jusqu’à présent, avait plutôt la tête d’un nombre
et c’était pratique à dessiner mais notre poisson rouge était
décrit par sa position, soit un couple  .
Beaucoup de fonctions en machine learning s’écrivent
.
Beaucoup de fonctions en machine learning s’écrivent
 où
où  est un vecteur
de
est un vecteur
de  coordonnées. Ca ne change pas grand-chose sauf
que c’est plus compliqué à dessiner voire impossible.
Il faudra faire avec.
coordonnées. Ca ne change pas grand-chose sauf
que c’est plus compliqué à dessiner voire impossible.
Il faudra faire avec.
Produit scalaire¶
Le produit scalaire est un opérateur bilinéaire, il est utilisé pour définir la norme d’un vecteur, il est relié aussi à l’angle qui les sépare.

Norme¶
La norme est pour simplifier une distance entre deux vecteurs. La distance euclidienne est nommé norme L2 :

La norme L1 utilise les valeurs absolues :

Ce sont les deux principales normes utilisées en machine learning.
Matrice¶
Les matrices sont incontournables. Ces simples tableaux de nombres viennent avec les opérations comme la multiplication, l’addition, la transposée… Elles simplifient beaoucoup l’écriture des calculs et interviennent dans tous les modèles linéaires.

Les notations mathématiques utilisent le plus souvent les minuscules pour représenter un nombre, les majuscules pour représenter un vecteur ou une matrice, les lettres grecques pour des nombres très petits utilisés comme intermédiaires de calcul.
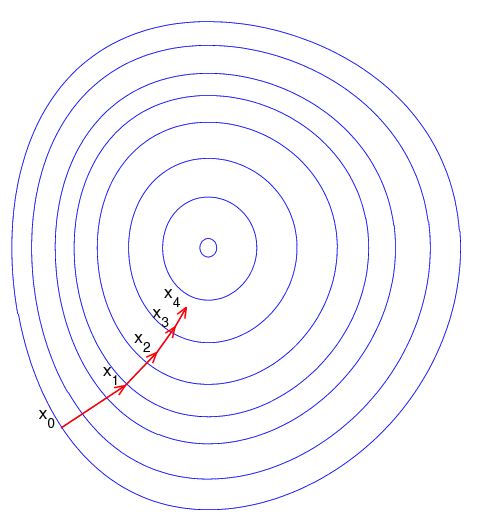
Problème d’optimisation¶
C’est le vif du sujet. Le machine learning commence par exprimer de façon mathématique un problème à résoudre, et le plus souvent cette réflexion à un problème d’optimisation comme le suivant :

Le problème se résoud avec une méthode à base de gradient
lorsque la fonction est dérivable comme la méthode
de Newton,
l’algorithme du gradient.
Variable aléatoire¶
C’est un concept qui permet de synthétiser une information, de saisir la variabilité d’une donnée en peu de termes. Un biologiste a mesuré la taille d’une centaine de poissons rouges, voici quelques exemples :
10.2 10.1 9.9 13.5 ...
Il raconte sa journée à son ami et se met en tête de réciter tous les nombres qu’il a observés. Voyant son ami qui s’endort, il finit par lui dire que la taille des poissons rouges est comprise entre 9.5 cm et 14.1 cm. Son ami paresseux lui retourne : « Donc si je prends un nombre au hasard entre ces deux extrémités, j’aurai une taille de poissons rouges. »
C’est l’idée d’une variable aléatoire Cela résume la façon dont une chose peut varier. Un nombre aléatoire choisi dans un intervalle est appelé loi uniforme. La loi la plus connue est la loi normale qu’on connaît aussi sous la forme d’un chapeau.

Ce graphique représente une fonction et celle-ci indique la probabilité
de tirer un nombre égale à selon une loi normale. Ce dessine nous dit
que ce nombre aléatoire a plus de chance d’être petit que grand. On peut même dire
que ce nombre aléatoire a 95% de chance d’être entre -2 et 2.
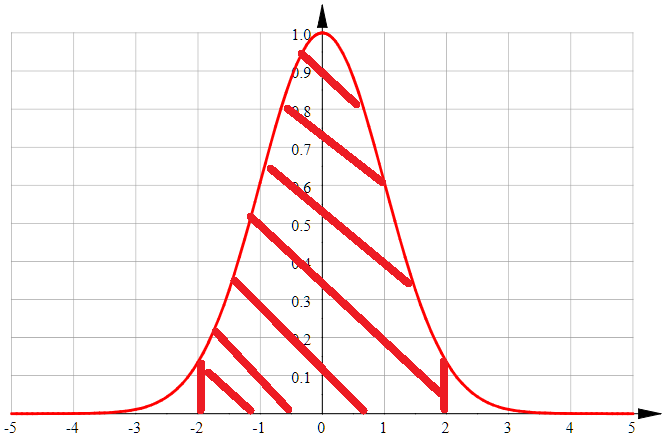
Une variable aléatoire résume une dizaine, une centaine, un millier, une infinité de nombres fabriqués de la même manière, la taille d’une personne, la durée de vie d’une ampoule, l’efficacité d’un traitement médical…
Histogramme¶
L’histogramme est un graphique très utilisé pour se faire une idée d’une variable aléatoire. C’est humainement très difficile de comprendre une série de longue surtout si elle est très longue. Une idée consiste à compter le nombre de nombres qui sont tombés dans une dizaine d’intervalles définis à l’avance.

C’est une vision plus fine de la taille de nos poissons rouges, plutôt que de déterminer une taille minimale et maximale, on donne une indication de ce qu’il se passe au milieu.
Corrélation¶
Il est très facile de comparer deux nombres, surtout de dire s’ils sont
loin de l’un de l’autre. Mais après avoir
inventé les variables aléatoires, il fallait pouvoir dire la même chose
de deux variables aléatoires et des milliers de nombres qu’elles représentent.
On considère deux ensembles de nombres  et
et
 qui vont de pair, c’est-à-dire que
qui vont de pair, c’est-à-dire que
 et
et  sont liés, comme la taille du poisson rouge
et son poids, leur deux vont ensemble. La corrélation mesure le fait que
et varient dans le même sens. Si est grand,
alors est grand, si est petit alors est petit.
On dit alors que les variables aléatoires
sont liés, comme la taille du poisson rouge
et son poids, leur deux vont ensemble. La corrélation mesure le fait que
et varient dans le même sens. Si est grand,
alors est grand, si est petit alors est petit.
On dit alors que les variables aléatoires  et
et  qui résument les deux ensembles de points sont corrélées.
Il y a plusieurs façons de mesurer la corrélation mais le plus connu
est la corrélation de Pearson :
qui résument les deux ensembles de points sont corrélées.
Il y a plusieurs façons de mesurer la corrélation mais le plus connu
est la corrélation de Pearson :

Une autre très connue est la corrélation de
Spearman
est est définie comme la corrélation des rangs des variables X, Y.
On convertit la séquence  en
en  qui vérifie
qui vérifie  et
et
 Les deux suites
Les deux suites
 et
et  sont triées. La corrélation
de Spearman est définie comme :
sont triées. La corrélation
de Spearman est définie comme :

Cette corrélation est moins sensibles aux valeurs extrêmes puisqu’elle s’intéresse à l’ordre des valeurs et non aux valeurs elles-mêmes.
Nuage de points¶
C’est la traduction visuel de la corrélation. On dessine plutôt que de calculer un indicateur de la proximité de deux variables. On ne dessine jamais assez. Voici le nuage de points.
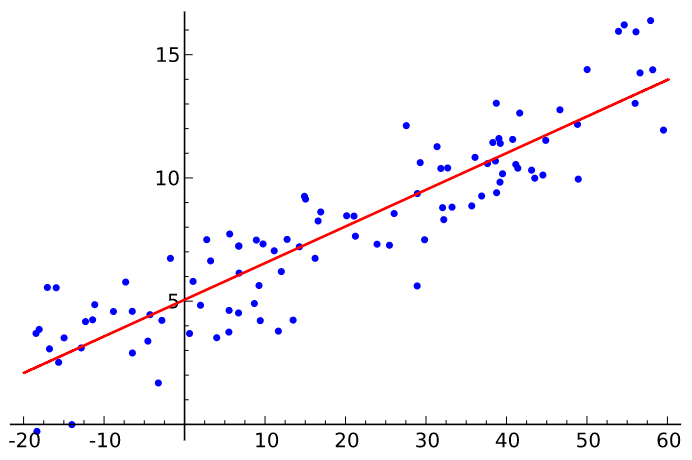
En dessinant chaque point du nuage, on observe que ceux-ci s’agence selon une droite. Elle n’est pas parfaite mais elle décrit assez bien ce qu’on observe. Les variables sont clairement liées et donc corrélées.
Rappels informatiques¶
Il vaut mieux savoir programmer avant de lire la suite à moins de n’être intéressé que par les concepts sans avoir la volonté de pratiquer. Tous les exemples sont proposés en langage Python. Vous devriez comprendre les gammes proposées par Structures de données, et savoir choisir quel objet est le plus approprié : Liste, tuple, ensemble, dictionnaire, liste chaînée, coût des opérations. La programmation a pris beaucoup d’ampleur aujourd’hui. Il faut imaginer que les mathématiciens ont fait tous leur calculs sans machine jusqu’à la seconde guerre mondiale alors qu’il est très simple maintenant de vérifier une intuition mathématique en créant un programme qui la vérifie. Si ça ne marche, il est clair que le théorème est faux, si l’ordinateur dit que cela marche, c’est une bonne indication que le théorème peut être démontré. Une fois qu’il l’est, il peut être appliqué à l’infini sur quantité de problèmes.
Le fichier csv¶
C’est un format de fichier qui structure l’information de telle sorte
qu’il est très facile de la reconstruire. Nous aimons les tableaux,
simples à visualiser, simples à manipuler. L’ordinateur ne connaît pas
grand chose et tout se résume peu ou prou à une séquence de caractères.
Le format csv
est une convention pour retrouver l’information qui était à telle ligne
et telle colonne. Un caractère indique qu’on passe à la colonne suivante,
le plus souvent ,, un autre indique qu’on passe à la ligne suivante
\n.
DataFrame¶
La traduction est littéralement tableau de données, il a un nombre fixé de colonnes et de lignes. On suppose en plus que chaque colonne contient le même type d’information, nombre ou texte le plus souvent. Le module pandas a considérablement facilité leur utilisation en Python. Pour vous exercez DataFrame et Graphes.
Array¶
C’est la représentation informatique d’une matrice et des opérations qui lui sont associées. Pour vous exercez : Calcul Matriciel, Optimisation.
Fonction de hash¶
Les fonctions de hashing sont principalement dans deux cas. La fonction crypte les informations, il est impossible de retrouver la donnée originale à moins d’essayer toutes les possibilités. Elle ne crypte pas nécessairement de façon unique d’ailleurs puisque deux données peuvent être identiques une fois hashées. Cette fonction est aussi une façon d’uniformiser une distribution. Cette propriété est utilisée pour optimiser le coût de nombreux algorithmes. Elle garantit la construction d’arbres équilibrés et améliore la répartition des calculs. Pour en savoir plus à ce sujet : Hash et distribution.
Arbre¶
Les arbres ou graphes sont des structures de données très utilisées en machine learning. Le modèle le plus connu est l”arbre de décision. Les deux examens suivant illustrent en quoi les arbres de décision sont intéressants : ENSAE TD noté, mardi 12 décembre 2017. Les exercices suivant vous montre un cas concret d’utilisation : Arbre et Trie.
Rappels algorithmiques¶
C’est un domaine que l’école française a trop longtemps laissé
de côté et une connaissance incontournable pour qui
veut écrire un programme efficace. C’est un enseignement qui est
dispensé au lycée dans les pays de l’Est, souvent après 20 ans
et pas dans toutes les écoles en France.
Pour avoir un aperçu de tout ce que vous avez raté :
Culture Algorithmique.
En accéléré, très accéléré, il faut absolument connaître l’algorithme
du plus court chemin,
celui du voyageur de commerce
et la recherche dichotomique.
Le premier a un coût algorithmique
en  , le coût suivant est exponentiel, le dernier est en
, le coût suivant est exponentiel, le dernier est en  .
est en quelque sorte la taille du problème, le nombre d’informations auxquelles
l’algorithme s’applique. Il indique que le temps passé va quadrupler
si la quantité d’information double. x2 d’un côté, x4 de l’autre.
Ces trois algorithmes donnent trois exemples de temps différents,
temps quadratique pour la recherche du plus court chemin,
temps exponentiel et quasiment infini pour le voyageur
du commerce, temps logarithmique pour la recherche dichotomique.
Pour vous exercer : Algorithmes.
.
est en quelque sorte la taille du problème, le nombre d’informations auxquelles
l’algorithme s’applique. Il indique que le temps passé va quadrupler
si la quantité d’information double. x2 d’un côté, x4 de l’autre.
Ces trois algorithmes donnent trois exemples de temps différents,
temps quadratique pour la recherche du plus court chemin,
temps exponentiel et quasiment infini pour le voyageur
du commerce, temps logarithmique pour la recherche dichotomique.
Pour vous exercer : Algorithmes.
Le plus court chemin dans un graphe¶
Il existe plusieurs versions de cet algorithme sans pour autant changer l’idée principale. Le plus connu est sans doute la version de Dijkstra. On retrouve la même idée lorsqu’il s’agit de déterminer la séquence d’états la plus probable dans une chaîne de Markov avec l”algorithme de Viterbi On le retrouve également dans la distance d’édition ou de Levenstein. Quelques exerices pour vous exercer : Programmation dynamique et plus court chemin, La distance d’édition. La page suivante Distance d’édition se propose d’aller un peu plus loin.
La recherche dichotomique¶
C’est en général le premier qu’on apprend dans un court d’algorithmie.
Il consiste à optimiser la recherche d’un élément dans un tableau trié.
La recherche dichotomique
est une des petites choses qu’on teste lors d’un entretien d’embauche.
Quelques exercices pour vous exercer :
Recherche dichotomique.
La recherche dichotomique en plusieurs dimensions
est utilisée via des structures telles que
k-d tree.
Ce besoin intervient dès qu’il faut accélérer la recherche des voisins
d’un point dans un espace vectoriel de dimension  (
( ).
).
Le voyageur du commerce¶
Le problème du voyageur de commerce consiste à parcourir une série de villes le plus rapidement possibles. C’est un des problèmes qu’on cite en premier pour illustrer les problèmes NP-complet : la solution de ceux-ci ne peut pas être trouvé avec un algorithme au coût polynômial. Il n’y a pas d’autres options que de tester toutes les permutations des villes pour déterminer le chemin le plus court. Et comme c’est rapidement très long, il faut rapidement proposer une solution approchée. La dénomination anglaise est parfois plus connue : Travelling Salesman Problem (TSP).
Modules incourtournables en Python¶
Le langage Python est le langage le plus utilisé depuis quelques après que le modules qui suivent sont devenus matures.
numpy¶
numpy gère tout ce qui est calcul matriciel. Le langage Python est un des langages les plus lents qui soient. Tous les calculs rapides ne sont pas écrits en Python mais en C++, voire fortran. C’est le cas du module numpy, il est incontournable dès qu’on veut être rapide. Le module scipy est une extension où l’on peut trouver des fonctions statistiques, d’optimisation.
pandas¶
pandas est incontournable dès qu’on veut manipuler des données. Il gère la plupart des formats de données. Il est lui aussi implémenté en C++. Il est rapide mais pas tant que ça, il utilise en règle générale trois fois plus d’espace en mémoire que les données n’en prennent sur le disque.
matplotlib¶
matplotlib s’occupe de tout ce qui est graphique. Il faut également connaître seaborn qui propose des graphiques étudiés pour un usage statistique.
scikit-learn¶
scikit-learn est le module le plus populaire pour deux raisons. Son design a été pensé pour être simple avec deux méthodes fit et predict pour apprendre et prédire. Sa documentation est un modèle à suivre.
statsmodels¶
statsmodels plaira plus aux statisticiens, il implémente des modèles similaires à scikit-learn, il est meilleur pour tout ce qui est linéaire avec une présentation des résultats très proche de ce qu’on trouve en R.
Dessiner des cartes¶
Voir Tracer une carte.
Exercices¶
Si tous ces rappels vous sont connus, vous devriez être prêt à résoudre quelques exercices et énigmes :
Un dernier lien vers des exercices dont les questions sont plus détaillées et corrigées Séances notées.