Validation croisée (cross-validation)¶
Il est acquis qu’un modèle doit être évalué sur une base de test différente de celle utilisée pour l’apprentissage. Mais la performance est peut-être juste l’effet d’une aubaine et d’un découpage particulièrement avantageux. Pour être sûr que le modèle est robuste, on recommence plusieurs fois. On appelle cela la validation croisée ou cross validation.
[1]:
from IPython.display import Image
Image("images/cross.png", width=300)
[1]:
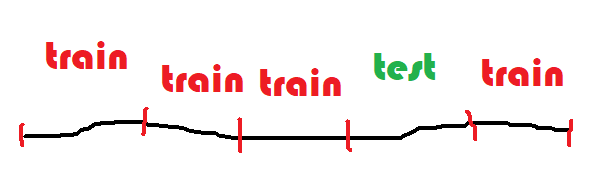
On découpe la base de données en cinq segments de façon aléatoire. On en utilise 4 pour l’apprentissage et 1 pour tester. On recommence 5 fois. Si le modèle est robuste, les cinq scores de test seront sensiblement égaux.
[2]:
%matplotlib inline
[1]:
from teachpyx.datasets import load_wines_dataset
df = load_wines_dataset()
X = df.drop(["quality", "color"], axis=1)
y = df["quality"]
df.head()
[1]:
| fixed_acidity | volatile_acidity | citric_acid | residual_sugar | chlorides | free_sulfur_dioxide | total_sulfur_dioxide | density | pH | sulphates | alcohol | quality | color | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 | red |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 | red |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 | red |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 | red |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 | red |
On utilise un modèle des plus proches voisins.
[2]:
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=1)
Nous allons utiliser la fonction cross_val_score.
[3]:
from sklearn.model_selection import cross_val_score
cross_val_score(knn, X, y, cv=5)
[3]:
array([-0.83897083, -0.4670711 , -0.59014921, -0.38119203, -0.77196458])
Le score par défaut est  :
:
[4]:
from sklearn.metrics import make_scorer, r2_score
cross_val_score(knn, X, y, cv=5, scoring=make_scorer(r2_score))
[4]:
array([-0.83897083, -0.4670711 , -0.59014921, -0.38119203, -0.77196458])
Si on souhaite utiliser score un autre score :
[5]:
from sklearn.metrics import mean_squared_error
cross_val_score(knn, X, y, cv=5, scoring=make_scorer(mean_squared_error))
[5]:
array([1.21615385, 1.21230769, 1.27328714, 1.14857583, 1.13702848])
Ou plusieurs à la fois :
[6]:
from sklearn.model_selection import cross_validate
cross_validate(
knn,
X,
y,
cv=5,
scoring=dict(r2=make_scorer(r2_score), e2=make_scorer(mean_squared_error)),
return_train_score=False,
)
[6]:
{'fit_time': array([0.01611519, 0.01256323, 0.01422715, 0.01552773, 0.01151872]),
'score_time': array([0.0266242 , 0.0449729 , 0.04643941, 0.03146887, 0.03442144]),
'test_r2': array([-0.83897083, -0.4670711 , -0.59014921, -0.38119203, -0.77196458]),
'test_e2': array([1.21615385, 1.21230769, 1.27328714, 1.14857583, 1.13702848])}
On obtient bien les mêmes résultats mais ils sont bien différents de ceux obtenus avec train_test_split et reproduits ci-dessous.
[7]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn.fit(X_train, y_train)
prediction = knn.predict(X_test)
r2_score(y_test, prediction)
[7]:
0.023381240522471147
Ca doit mettre la puce à l’oreille. De plus, étonnamment, le score est identique pour les tirages si on réexecute le code une seconde fois pour la validation croisée alors qu’il est différent pour une seconde répartition apprentissage test :
[8]:
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn.fit(X_train, y_train)
prediction = knn.predict(X_test)
r2_score(y_test, prediction)
[8]:
-0.05359981564444394
Les résultats sont rigoureusement identiques pour la validation croisée.
[9]:
cross_validate(
knn,
X,
y,
cv=5,
scoring=dict(r2=make_scorer(r2_score), e2=make_scorer(mean_squared_error)),
return_train_score=False,
)
[9]:
{'fit_time': array([0.02825642, 0.01596737, 0.01639652, 0.01254725, 0.00996113]),
'score_time': array([0.03756237, 0.05450106, 0.05501556, 0.0289607 , 0.0300467 ]),
'test_r2': array([-0.83897083, -0.4670711 , -0.59014921, -0.38119203, -0.77196458]),
'test_e2': array([1.21615385, 1.21230769, 1.27328714, 1.14857583, 1.13702848])}
C’est quelque peu suspect, très suspect en fait, en statistique, c’est quasi miraculeux pour un nombre aussi volatile. Cela ne peut être dû au fait que la fonction fait exactement les mêmes découpages. Mettons un peu plus d’aléatoire :
[10]:
from sklearn.model_selection import StratifiedKFold
from time import perf_counter
res = cross_validate(
knn,
X,
y,
scoring=dict(r2=make_scorer(r2_score), e2=make_scorer(mean_squared_error)),
return_train_score=False,
cv=StratifiedKFold(
n_splits=5, random_state=int(perf_counter() * 100), shuffle=True
),
)
res
[10]:
{'fit_time': array([0.01946974, 0.01295662, 0.01164722, 0.01231718, 0.01509309]),
'score_time': array([0.03926373, 0.03318691, 0.03969431, 0.04624486, 0.04102969]),
'test_r2': array([-0.07101199, -0.04884618, -0.06402385, -0.06367173, -0.12013179]),
'test_e2': array([0.81769231, 0.80076923, 0.80908391, 0.80985373, 0.85527329])}
[11]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(3, 3))
ax.plot(res["test_r2"])
ax.set_title("k-nn R2 validation croisée");
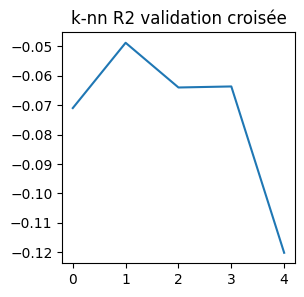
On retrouve les mêmes scores que pour train_test_split. Comment l’interpréter ? La raison la plus probable est que la validation croisée implémenté par scikit-learn n’est par défaut pas aléatoire. Cela explique qu’on retrouve les mêmes résultats sur deux exécutions. Il reste à expliquer le fait que les chiffres sont nettement mauvais pour le premier code et meilleurs pour ce second code.
Et si les vins n’étaient pas mélangés dans la base avec des vins rouges au début et blancs vers la fin ?
[12]:
dfi = df.reset_index(drop=False)
import pandas
pandas.concat([dfi[["index", "color"]].head(), dfi[["index", "color"]].tail()])
[12]:
| index | color | |
|---|---|---|
| 0 | 0 | red |
| 1 | 1 | red |
| 2 | 2 | red |
| 3 | 3 | red |
| 4 | 4 | red |
| 6492 | 6492 | white |
| 6493 | 6493 | white |
| 6494 | 6494 | white |
| 6495 | 6495 | white |
| 6496 | 6496 | white |
[13]:
dfi[["index", "color"]].groupby("color").min()
[13]:
| index | |
|---|---|
| color | |
| red | 0 |
| white | 1599 |
[14]:
dfi[["index", "color"]].groupby("color").max()
[14]:
| index | |
|---|---|
| color | |
| red | 1598 |
| white | 6496 |
Les éléments sont clairements triés par couleur et la validation croisée par défaut découpe selon cet ordre. Cela signifie presque que le modèle essaye de prédire la note d’un vin rouge en s’appuyant sur des vins blancs et cela ne marche visiblement pas. La validation croisée ne retourne pas de modèle mais cela peut être contourné avec GridSearchCV.
[15]:
from sklearn.model_selection import GridSearchCV
cvgrid = GridSearchCV(
estimator=knn,
param_grid={},
scoring=dict(r2=make_scorer(r2_score), e2=make_scorer(mean_squared_error)),
return_train_score=False,
refit="r2",
cv=StratifiedKFold(
n_splits=5, random_state=int(perf_counter() * 100), shuffle=True
),
)
[16]:
cvgrid.fit(X, y)
[16]:
GridSearchCV(cv=StratifiedKFold(n_splits=5, random_state=92053, shuffle=True),
estimator=KNeighborsRegressor(n_neighbors=1), param_grid={},
refit='r2',
scoring={'e2': make_scorer(mean_squared_error, response_method='predict'),
'r2': make_scorer(r2_score, response_method='predict')})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=StratifiedKFold(n_splits=5, random_state=92053, shuffle=True),
estimator=KNeighborsRegressor(n_neighbors=1), param_grid={},
refit='r2',
scoring={'e2': make_scorer(mean_squared_error, response_method='predict'),
'r2': make_scorer(r2_score, response_method='predict')})KNeighborsRegressor(n_neighbors=1)
KNeighborsRegressor(n_neighbors=1)
[17]:
cvgrid.cv_results_
[17]:
{'mean_fit_time': array([0.01401343]),
'std_fit_time': array([0.00290775]),
'mean_score_time': array([0.03055172]),
'std_score_time': array([0.00386653]),
'params': [{}],
'split0_test_r2': array([-0.03977834]),
'split1_test_r2': array([-0.0196276]),
'split2_test_r2': array([-0.01542904]),
'split3_test_r2': array([-0.05962735]),
'split4_test_r2': array([-0.06669616]),
'mean_test_r2': array([-0.0402317]),
'std_test_r2': array([0.02057409]),
'rank_test_r2': array([1], dtype=int32),
'split0_test_e2': array([0.79384615]),
'split1_test_e2': array([0.77846154]),
'split2_test_e2': array([0.77213241]),
'split3_test_e2': array([0.80677444]),
'split4_test_e2': array([0.81447267]),
'mean_test_e2': array([0.79313744]),
'std_test_e2': array([0.01611369]),
'rank_test_e2': array([1], dtype=int32)}
[18]:
cvgrid.best_estimator_
[18]:
KNeighborsRegressor(n_neighbors=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsRegressor(n_neighbors=1)