Régression quantile ou régression L1¶
La régression quantile est moins sensible aux points aberrants. Elle peut être définie comme une régression avec une norme L1 (une valeur absolue).
Médiane et valeur absolue¶
On considère un ensemble de nombre réels
 . La médiane est le
nombre M qui vérifie :
. La médiane est le
nombre M qui vérifie :

Plus simplement, la médiane est obtenue en triant les éléments
par ordre croissant. La médiane
est alors le nombre au milieu  .
.
propriété P1 : Médiane et valeur absolue
La médiane M de l’ensemble
minimise la quantité  .
.
Avant de démontrer la propriété, voyons ce qu’il
se passe entre deux réels. La médiane de  peut être n’importe où sur le segment.
peut être n’importe où sur le segment.
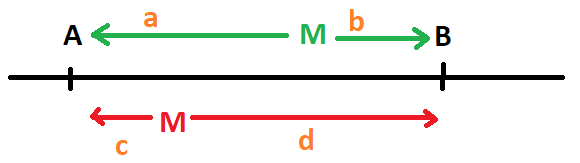
De manière évidente, les distances
des deux côtés du point M sont égales :
 . Mais si M n’est pas sur le segment,
on voit de manière évidente que la somme
des distances sera plus grande.
. Mais si M n’est pas sur le segment,
on voit de manière évidente que la somme
des distances sera plus grande.
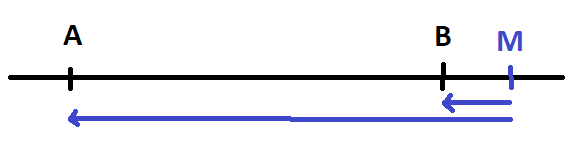
N’importe quel point sur le segment M minimise
 .
On revient aux n réels triés par ordre croissant
et on considère les paires
.
On revient aux n réels triés par ordre croissant
et on considère les paires
 ,
,  , …,
, …,
 .
L’intersection de tous ces intervalles est
et on sait d’après la petit exemple avec deux points
que n’importe quel point dans cet intervalle minimise
.
L’intersection de tous ces intervalles est
et on sait d’après la petit exemple avec deux points
que n’importe quel point dans cet intervalle minimise
 .
La propriété est démontrée.
.
La propriété est démontrée.
Régression et quantile¶
Maintenant que la médiane est définie par un problème de minimisation, il est possible de l’appliquer à un problème de régression.
Définition D1 : Régression quantile
On dispose d’un ensemble de n couples
 avec
avec  et
et  . La régression quantile
consiste à trouver
. La régression quantile
consiste à trouver  tels que la
somme
tels que la
somme  est minimale.
est minimale.
Résolution d’une régression quantile¶
La première option consiste à utiliser une méthode
de descente de gradient puisque la fonction
est presque
partout dérivable. Une autre option consiste à
utiliser l’algorithme
Iteratively reweighted least squares.
L’implémentation est faite par la classe QuantileLinearRegression.
L’algorithme est tiré de [Chen2014].
Algorithme A1 : Iteratively reweighted least squares
On souhaite trouver les paramètres  qui minimise :
qui minimise :

Etape 1
On pose  .
.
Etape 2
On calcule  avec
avec
 .
.
Etape 3
On met à jour les poids
 .
Puis on retourne à l’étape 2.
.
Puis on retourne à l’étape 2.
Le paramètre  gère le cas où la prédiction est identique
à la valeur attendue pour un point
gère le cas où la prédiction est identique
à la valeur attendue pour un point  donné.
Il y a plusieurs choses à démontrer. On suppose que l’algorithme
converge, ce qu’on n’a pas encore démontré. Dans ce cas,
donné.
Il y a plusieurs choses à démontrer. On suppose que l’algorithme
converge, ce qu’on n’a pas encore démontré. Dans ce cas,
 et les coefficients
et les coefficients
 optimise la quantité :
optimise la quantité :

On remarque également que  est l’erreur L1
pour les paramètres .
Donc si l’algorithme converge, celui-ci optimise bien
l’erreur de la régression quantile. Dans le cas d’une régression
linéaire, on sait exprimer la solution :
est l’erreur L1
pour les paramètres .
Donc si l’algorithme converge, celui-ci optimise bien
l’erreur de la régression quantile. Dans le cas d’une régression
linéaire, on sait exprimer la solution :

D’après le théorème du point fixe, on sait que la suite converge si la fonction g est contractante.

Quantile et optimisation¶
De la même manière que nous avons défini la médiane comme la solution d’un problème d’optimisation, nous pouvons définir n’importe quel quantile comme tel.
propriété P2 : Quantile et optimisation
Le quantile  de l’ensemble
est le nombre qui vérifie :
de l’ensemble
est le nombre qui vérifie :

Ce nombre minimise la quantité :

Où  et
et
 .
.
On vérifie qu’on retrouve bien ce qui était énoncé pour
la médiane avec  . Il faut démontrer
que la solution de ce programme d’optimisation
atterrit dans l’intervalle souhaité.
. Il faut démontrer
que la solution de ce programme d’optimisation
atterrit dans l’intervalle souhaité.
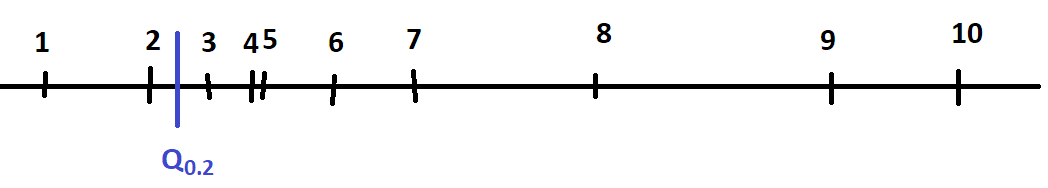
On choisit un réel P à l’intérieur d’un intervale et on calcule :
 .
On note
.
On note  et
et
 . Comme le point P
est à l’intérieur d’un intervalle,
. Comme le point P
est à l’intérieur d’un intervalle,  .
Soit dx un réel tel que
.
Soit dx un réel tel que  soit toujours dans l’intervalle :
soit toujours dans l’intervalle :

On voit que si P est choisi de telle sorte que  , la fonction
, la fonction
 est constante sur cette intervalle et c’est précisément le cas
lorsque
est constante sur cette intervalle et c’est précisément le cas
lorsque  . Comme la fonction E est une somme positive de fonctions
convexes, elle l’est aussi. Si on a trouvé un intervalle où la fonction est
constante alors celui-ci contient la solution. Sinon, il suffit juste de
trouver les intervalles
. Comme la fonction E est une somme positive de fonctions
convexes, elle l’est aussi. Si on a trouvé un intervalle où la fonction est
constante alors celui-ci contient la solution. Sinon, il suffit juste de
trouver les intervalles  et
et  pour lesquelles la fonction E est respectivement décroissante et croissante.
On cherche donc le point P tel que
pour lesquelles la fonction E est respectivement décroissante et croissante.
On cherche donc le point P tel que  si
si  et
et  si
si  et ce point correspond au quantile
. Ceci conclut la démonstration.
et ce point correspond au quantile
. Ceci conclut la démonstration.
Régression quantile pour un quantile p quelconque¶
Comme pour la médiane, il est possible de définir la régression quantile pour un quantile autre que la médiane.
Définition D2 : Régression quantile
On dispose d’un ensemble de n couples
avec
et . La régression quantile
consiste à trouver tels que la
somme  est minimale.
est minimale.
Résolution d’une régression quantile pour un quantile p quelconque¶
La première option consiste encore à utiliser une méthode de descente de gradient puisque la fonction à minimiser est presque partout dérivable. On peut aussi adapter l’algorithme Iteratively reweighted least squares. L’implémentation est faite par la classe QuantileLinearRegression (voir [Koenker2017]).
Algorithme A2 : Iteratively reweighted least squares
On souhaite trouver les paramètres
qui minimise :

Etape 1
On pose .
Etape 2
On calcule avec
.
Etape 3
On met à jour les poids
 .
Puis on retourne à l’étape 2.
.
Puis on retourne à l’étape 2.
On suppose que l’algorithme
converge, ce qu’on n’a pas encore démontré. Dans ce cas,
et les coefficients
optimise la quantité :

Notebook¶
Bilbiographie¶
Des références sont disponibles sur la page de statsmodels : QuantReg ou là : Régression quantile.
Quantile Regression, 40 years on, Roger Koenker (2017)
Fast Iteratively Reweighted Least Squares Algorithms for Analysis-Based Sparsity Reconstruction Chen Chen, Junzhou Huang, Lei He, Hongsheng Li