Apprentissage d’un réseau de neurones¶
Le terme apprentissage est encore inspiré de la biologie et se traduit
par la minimisation de la fonction (2) où
 est un réseau de neurone défini par un perceptron.
Il existe plusieurs méthodes pour effectuer celle-ci.
Chacune d’elles vise à minimiser la fonction d’erreur :
est un réseau de neurone défini par un perceptron.
Il existe plusieurs méthodes pour effectuer celle-ci.
Chacune d’elles vise à minimiser la fonction d’erreur :

Dans tous les cas, les différents apprentissages utilisent la suite
suivante  vérifiant (1)
et proposent une convergence vers un minimum local.
vérifiant (1)
et proposent une convergence vers un minimum local.
(1)¶
Il est souhaitable d’apprendre plusieurs fois la même fonction en modifiant les conditions initiales de ces méthodes de manière à améliorer la robustesse de la solution.
Apprentissage avec gradient global¶
L’algorithme de rétropropagation permet d’obtenir
la dérivée de l’erreur  pour un vecteur d’entrée
pour un vecteur d’entrée  . Or l’erreur
. Or l’erreur
 à minimiser est la somme des erreurs pour chaque exemple
à minimiser est la somme des erreurs pour chaque exemple
 , le gradient global
, le gradient global  de cette erreur
globale est la somme des gradients pour chaque exemple
(voir équation (3)).
Parmi les méthodes d’optimisation basées sur le gradient global, on distingue deux catégories :
de cette erreur
globale est la somme des gradients pour chaque exemple
(voir équation (3)).
Parmi les méthodes d’optimisation basées sur le gradient global, on distingue deux catégories :
Les méthodes du premier ordre, elles sont calquées sur la méthode de Newton et n’utilisent que le gradient.
Les méthodes du second ordre ou méthodes utilisant un gradient conjugué elles sont plus coûteuses en calcul mais plus performantes puisque elles utilisent la dérivée seconde ou une valeur approchée.
Méthodes du premier ordre¶
Les méthodes du premier ordre sont rarement utilisées. Elles sont toutes basées sur le principe de la descente de gradient de Newton présentée dans la section Algorithme et convergence :
Algorithme A1 : optimisation du premier ordre
Initialiation
Le premier jeu de coefficients  du réseau
de neurones est choisi aléatoirement.
du réseau
de neurones est choisi aléatoirement.

Calcul du gradient

Mise à jour

Terminaison
Si  (ou
(ou  )
alors l’apprentissage a convergé sinon retour au calcul du gradient.
)
alors l’apprentissage a convergé sinon retour au calcul du gradient.
La condition d’arrêt peut-être plus ou moins stricte selon les besoins du problème. Cet algorithme converge vers un minimum local de la fonction d’erreur (d’après le théorème de convergence mais la vitesse de convergence est inconnue.
Méthodes du second ordre¶
L’algorithme apprentissage global fournit le canevas des méthodes d’optimisation du second ordre. La mise à jour des coefficients est différente car elle prend en compte les dernières valeurs des coefficients ainsi que les derniers gradients calculés. Ce passé va être utilisé pour estimer une direction de recherche pour le minimum différente de celle du gradient, cette direction est appelée gradient conjugué (voir [Moré1977]).
Ces techniques sont basées sur une approximation du second degré de la fonction à minimiser.
On note  le nombre de coefficients du réseau de neurones (biais compris).
Soit
le nombre de coefficients du réseau de neurones (biais compris).
Soit  la fonction d’erreur associée au réseau de neurones :
la fonction d’erreur associée au réseau de neurones :
 .
Au voisinage de
.
Au voisinage de  , un développement limité donne :
, un développement limité donne :

Par conséquent, sur un voisinage de , la fonction  admet un minimum local si
admet un minimum local si  est définie positive strictement.
est définie positive strictement.
Rappel :  est définie positive strictement
est définie positive strictement  .
.
Une matrice symétrique définie strictement positive est inversible, et le minimum est atteint pour la valeur :
(2)¶![\begin{eqnarray}
W_{\min}= W_0 + \frac{1}{2}\left[ \dfrac{\partial^{2}h\left( W_{0}\right) }
{\partial W^{2}}\right] ^{-1}\left[ \frac{\partial h\left( W_{0}\right)
}{\partial W}\right] \nonumber
\end{eqnarray}](../../_images/math/06cec53733bd1fac736fa67e71a42d1a5a7b43e7.svg)
Néanmoins, pour un réseau de neurones, le calcul de la dérivée seconde est coûteux, son inversion également. C’est pourquoi les dernières valeurs des coefficients et du gradient sont utilisées afin d’approcher cette dérivée seconde ou directement son inverse. Deux méthodes d’approximation sont présentées :
L’algorithme BFGS (Broyden-Fletcher-Goldfarb-Shano) ([Broyden1967], [Fletcher1993]), voir aussi les versions L-BFGS.
L’algoritmhe DFP (Davidon-Fletcher-Powell) ([Davidon1959], [Fletcher1963]).
La figure du gradient conjugué est couramment employée
pour illustrer l’intérêt des méthodes de gradient conjugué.
Le problème consiste à trouver le minimum d’une fonction quadratique,
par exemple,  . Tandis que le gradient est orthogonal
aux lignes de niveaux de la fonction
. Tandis que le gradient est orthogonal
aux lignes de niveaux de la fonction  , le gradient conjugué se dirige plus
sûrement vers le minimum global.
, le gradient conjugué se dirige plus
sûrement vers le minimum global.
Figure F1 : Gradient conjugué
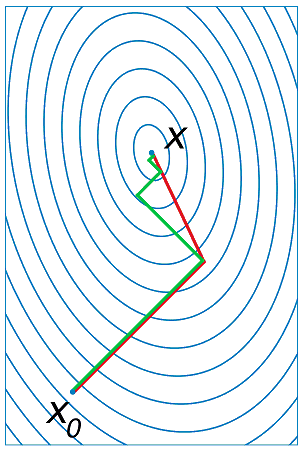
Gradient et gradient conjugué sur une ligne de niveau de la fonction ,
le gradient est orthogonal aux lignes de niveaux de la fonction ,
mais cette direction est rarement la bonne à moins que le point
 se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
Ces méthodes proposent une estimation de la dérivée seconde
(ou de son inverse) utilisée en (2).
Dans les méthodes du premier ordre, une itération permet de calculer les
poids  à partir des poids
à partir des poids  et du
gradient
et du
gradient  . Si ce gradient est petit, on peut supposer
que
. Si ce gradient est petit, on peut supposer
que  est presque égal au produit de la dérivée seconde par
. Cette relation est mise à profit pour construire une estimation
de la dérivée seconde. Cette matrice notée
est presque égal au produit de la dérivée seconde par
. Cette relation est mise à profit pour construire une estimation
de la dérivée seconde. Cette matrice notée  dans
l’algorithme BFGS
est d’abord supposée égale à l’identité puis actualisée à chaque
itération en tenant de l’information apportée par chaque déplacement.
dans
l’algorithme BFGS
est d’abord supposée égale à l’identité puis actualisée à chaque
itération en tenant de l’information apportée par chaque déplacement.
Algorithme A2 : BFGS
Le nombre de paramètres de la fonction est .
Initialisation
Le premier jeu de coefficients du réseau de neurones est
choisi aléatoirement.

Calcul du gradient

Mise à jour des coefficients

Mise à jour de la marice :math:`B_t`
 ou
ou  ou
ou 





Terminaison
Si alors l’apprentissage a convergé sinon retour au calcul
du gradient.
Lorsque la matrice est égale à l’identité,
le gradient conjugué est égal au gradient. Au fur et
à mesure des itérations, cette matrice toujours
symétrique évolue en améliorant la convergence de l’optimisation.
Néanmoins, la matrice doit être « nettoyée »
(égale à l’identité) fréquemment afin d’éviter qu’elle
n’agrège un passé trop lointain. Elle est aussi nettoyée lorsque
le gradient conjugué semble trop s’éloigner du véritable gradient
et devient plus proche d’une direction perpendiculaire.
La convergence de cet algorithme dans le cas des réseaux de neurones est plus rapide qu’un algorithme du premier ordre, une preuve en est donnée dans [Driancourt1996].
En pratique, la recherche de  est réduite car
le calcul de l’erreur est souvent coûteux, il peut être effectué
sur un grand nombre d’exemples. C’est pourquoi on remplace
l’étape de mise à jour de l’algorithme BFGS
par celle-ci :
est réduite car
le calcul de l’erreur est souvent coûteux, il peut être effectué
sur un grand nombre d’exemples. C’est pourquoi on remplace
l’étape de mise à jour de l’algorithme BFGS
par celle-ci :
Algorithme A3 : BFGS”
Le nombre de paramètre de la fonction est .
Initialisation, calcul du gradient
Voir BFGS.
Recherche de :math:`epsilon^*`

 et
et 



 et
et 


Mise à jour des coefficients

Mise à jour de la matrice :math:`B_t`, temrinaison
Voir BFGS.
L’algorithme DFP est aussi un algorithme de gradient conjugué qui propose une approximation différente de l’inverse de la dérivée seconde.
Algorithme A4 : DFP
Le nombre de paramètre de la fonction est .
Initialisation
Le premier jeu de coefficients
du réseau de neurones est choisi aléatoirement.
Calcul du gradient
Mise à jour des coefficients

Mise à jour de la matrice :math:`B_t`
ou ou 


 B_{t-1} + dfrac{d_t d’_t} {d’_t s_t} - dfrac{B_{t-1} s_t s’_t B_{t-1} } { s’_t B_{t-1} s_t }`
B_{t-1} + dfrac{d_t d’_t} {d’_t s_t} - dfrac{B_{t-1} s_t s’_t B_{t-1} } { s’_t B_{t-1} s_t }`Terminaison
Si alors l’apprentissage a convergé sinon retour à
du calcul du gradient.
Seule l’étape de mise à jour diffère dans les
algorithmes BFGS et DFP.
Comme l’algorithme BFGS,
on peut construire une version DFP”
inspirée de l’algorithme BFGS”.
Apprentissage avec gradient stochastique¶
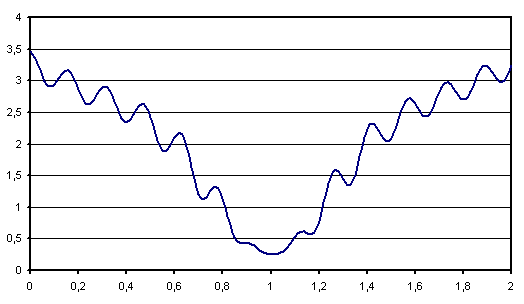
Compte tenu des courbes d’erreurs très accidentées dessinées par les réseaux de neurones, il existe une multitude de minima locaux. De ce fait, l’apprentissage global converge rarement vers le minimum global de la fonction d’erreur lorsqu’on applique les algorithmes basés sur le gradient global. L’apprentissage avec gradient stochastique est une solution permettant de mieux explorer ces courbes d’erreurs. De plus, les méthodes de gradient conjugué nécessite le stockage d’une matrice trop grande parfois pour des fonctions ayant quelques milliers de paramètres. C’est pourquoi l’apprentissage avec gradient stochastique est souvent préféré à l’apprentissage global pour de grands réseaux de neurones alors que les méthodes du second ordre trop coûteuses en calcul sont cantonnées à de petits réseaux. En contrepartie, la convergence est plus lente. La démonstration de cette convergence nécessite l’utilisation de quasi-martingales et est une convergence presque sûre [Bottou1991].
Figure F2 : Exemple de minimal locaux
Algprithme A1 : apprentissage stochastique
Initialisation
Le premier jeu de coefficients
du réseau de neurones est choisi aléatoirement.

Récurrence

 in
in 
 nombre aléatoire dans
nombre aléatoire dans 





Terminaison
Si
alors l’apprentissage a convergé sinon retour au
calcul du gradient.
En pratique, il est utile de converser le meilleur jeu de
coefficients :  car la suite
car la suite  n’est pas une suite décroissante.
n’est pas une suite décroissante.