La régression¶
Le bruit blanc est une variable aléatoire couramment utilisé pour désigner le hasard ou la part qui ne peut être modélisée dans une régression ou tout autre problème d’apprentissage. On suppose parfois que ce bruit suive une loi normale.
Définition D1 : bruit blanc
Une suite de variables aléatoires réelles
 est un bruit blanc :
est un bruit blanc :
 ,
, 

Une régression consiste à résoudre le problème suivant :
Problème P1 : Régression
Soient deux variables aléatoires  et
et  ,
l’objectif est d’approximer la fonction
,
l’objectif est d’approximer la fonction
 .
Les données du problème sont
un échantillon de points
.
Les données du problème sont
un échantillon de points  et un modèle paramétré avec :math:theta` :
et un modèle paramétré avec :math:theta` :

avec  ,
,
 bruit blanc,
bruit blanc,
 est une fonction de paramètre
est une fonction de paramètre  .
.
La fonction peut être une fonction linéaire,
un polynôme, un réseau de neurones…
Lorsque le bruit blanc est normal, la théorie de l’estimateur
de vraisemblance (voir [Saporta1990]) permet d’affirmer
que le meilleur paramètre  minimisant l’erreur de prédiction est :
minimisant l’erreur de prédiction est :

Le lien entre les variables et dépend des hypothèses faites
sur . Généralement, cette fonction n’est supposée non linéaire
que lorsqu’une régression linéaire
donne de mauvais résultats.
Cette hypothèse est toujours testée car la résolution du problème dans
ce cas-là est déterministe et aboutit à la résolution d’un système
linéaire avec autant d’équations que d’inconnues.
Voici ce que ce la donne avec un nuage de points  défini par
défini par  .
.
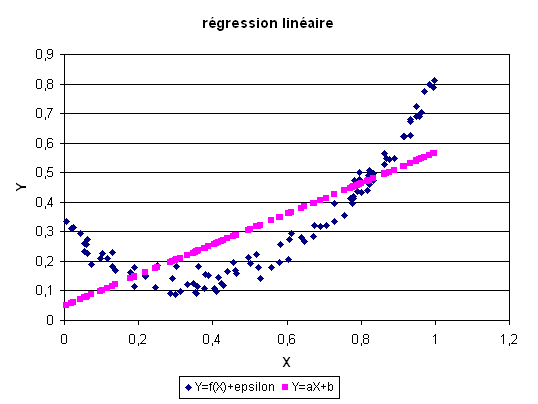
Une fonction non linéaire permet de s’approcher un peu plus de la véritable
fonction. Premier cas : est un réseau avec un neurone sur la couche cachée.
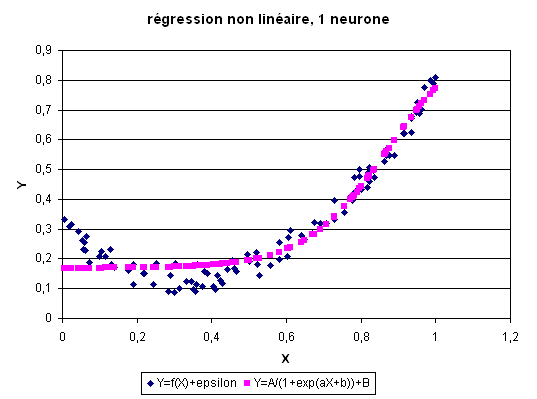
Second cas : est un réseau avec deux neurones sur la couche cachée.
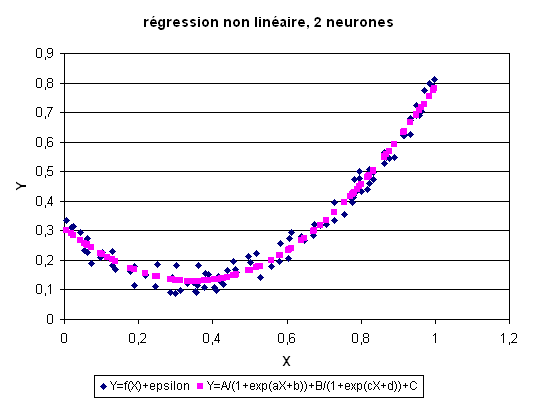
Troisième cas : est un réseau avec 100 neurones sur la couche cachée.
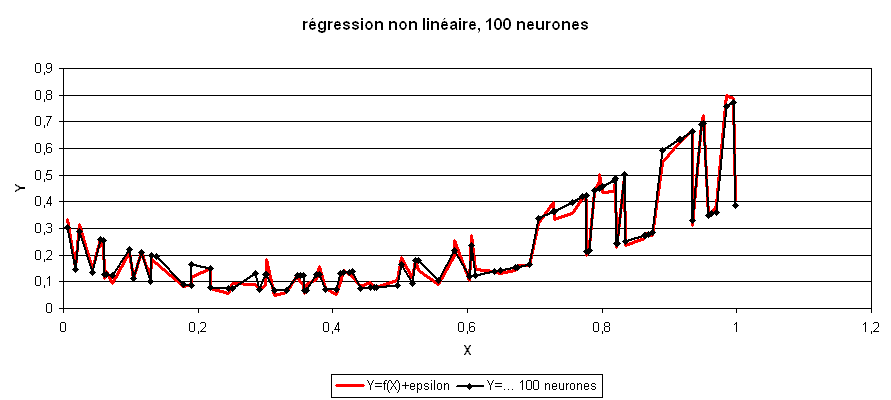
L’erreur de prédiction de ce réseau de neurones est très inférieure à celle des
modèles précédent, ce modèle a appris par coe ur
le nuage de points  sans vraiment « comprendre » ce qu’il apprenait.
Dans le cas d’une régression à cent neurones,
le nombre de coefficients du réseau de neurones (301)
est largement supérieur au nombre de points (50).
Il en résulte que contrairement aux trois précédents cas,
la « richesse » du modèle choisi lui permet d’apprendre le « hasard ».
Lorsque ce cas de figure se présente, on dit que le réseau
de neurones a appris coeur, son pouvoir de généralisation est mauvais ou
il fait de l”overfitting
(voir aussi Generalization Error).
L’erreur minime estimée sur ce nuage de points (ou base d’apprentissage)
sera considérablement accrue sur un autre nuage de points ou base de test
suivant la même loi.
Cet exemple montre que le choix du réseau de neurones le mieux adapté
au problème n’est pas évident. Il existe des méthodes permettant
d’approcher l’architecture optimale mais elles sont généralement
coûteuses en calcul.
sans vraiment « comprendre » ce qu’il apprenait.
Dans le cas d’une régression à cent neurones,
le nombre de coefficients du réseau de neurones (301)
est largement supérieur au nombre de points (50).
Il en résulte que contrairement aux trois précédents cas,
la « richesse » du modèle choisi lui permet d’apprendre le « hasard ».
Lorsque ce cas de figure se présente, on dit que le réseau
de neurones a appris coeur, son pouvoir de généralisation est mauvais ou
il fait de l”overfitting
(voir aussi Generalization Error).
L’erreur minime estimée sur ce nuage de points (ou base d’apprentissage)
sera considérablement accrue sur un autre nuage de points ou base de test
suivant la même loi.
Cet exemple montre que le choix du réseau de neurones le mieux adapté
au problème n’est pas évident. Il existe des méthodes permettant
d’approcher l’architecture optimale mais elles sont généralement
coûteuses en calcul.