Classification¶
Vraisemblance d’un échantillon de variable suivant une loi multinomiale¶
Soit  un échantillon de variables aléatoires i.i.d. suivant la loi multinomiale
un échantillon de variables aléatoires i.i.d. suivant la loi multinomiale
 .
On définit
.
On définit  .
La vraisemblance de l’échantillon est :
.
La vraisemblance de l’échantillon est :
(1)¶
Cette fonction est aussi appelée distance de Kullback-Leiber ([Kullback1951]), elle mesure la distance entre deux distributions de variables aléatoires discrètes. L”estimateur de maximum de vraisemblance (emv) est la solution du problème suivant :
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur  tel que :
tel que :

On cherche le vecteur  vérifiant :
vérifiant :

Théorème T1 : résolution du problème du maximum de vraisemblance
La solution du problème du maximum de vraisemblance est le vecteur :

Démonstration
Soit un vecteur  vérifiant les conditions :
vérifiant les conditions :

La fonction  est concave, d’où :
est concave, d’où :

La distance de KullBack-Leiber compare deux distributions de probabilités entre elles. C’est elle qui va faire le lien entre le problème de classification discret et les réseaux de neurones pour lesquels il faut impérativement une fonction d’erreur dérivable.
Problème de classification pour les réseaux de neurones¶
Le problème de classification est un cas particulier de celui qui suit pour lequel il n’est pas nécessaire de connaître la classe d’appartenance de chaque exemple mais seulement les probabilités d’appartenance de cet exemple à chacune des classes.
Soient une variable aléatoire continue  et une variable aléatoire discrète multinomiale
et une variable aléatoire discrète multinomiale
 , on veut estimer la loi de :
, on veut estimer la loi de :

Le vecteur  est une fonction
est une fonction  de
de  où
où
 est l’ensemble des
est l’ensemble des  paramètres du modèle.
Cette fonction possède
paramètres du modèle.
Cette fonction possède  entrées et
entrées et  sorties.
Comme pour le problème de la régression, on cherche les
poids qui correspondent le mieux à l’échantillon :
sorties.
Comme pour le problème de la régression, on cherche les
poids qui correspondent le mieux à l’échantillon :

On suppose que les variables  suivent les lois respectives
suivent les lois respectives  et sont indépendantes entre elles, la vraisemblance du modèle
vérifie d’après l’équation (1) :
et sont indépendantes entre elles, la vraisemblance du modèle
vérifie d’après l’équation (1) :

La solution du problème  est celle d’un problème d’optimisation sous contrainte. Afin de contourner
ce problème, on définit la fonction :
est celle d’un problème d’optimisation sous contrainte. Afin de contourner
ce problème, on définit la fonction :

Les contraintes sur  sont bien vérifiées :
sont bien vérifiées :

On en déduit que :

D’où :
(2)¶![\begin{eqnarray}
\begin{array}[c]{c}
\ln L_W \propto \sum_{i=1}^{N} \sum_{k=1}^{C} \eta_i^k f_k\pa{W,X_i} - \sum_{i=1}^{N}
\ln \cro{ \sum_{l=1}^{C} e^{f_l\pa{W,X_i} }}
\end{array} \nonumber
\end{eqnarray}](../../_images/math/21cbaf83eb8da974c3d5670ae8a0f43e2b11af33.svg)
Ceci mène à la définition du problème de classification suivant :
Problème P2 : classification
Soit  l’échantillon suivant :
l’échantillon suivant :

 représente la probabilité que l’élément
représente la probabilité que l’élément
 appartiennent à la classe
appartiennent à la classe  :
:

Le classifieur cherché est une fonction définie par :

Dont le vecteur de poids  est égal à :
est égal à :

Réseau de neurones adéquat¶
Dans le problème précédent, la maximisation de
 aboutit au choix d’une fonction :
aboutit au choix d’une fonction :

Le réseau de neurones suivant
 choisi pour modéliser aura pour sorties :
choisi pour modéliser aura pour sorties :

Figure F1 : Réseau de neurones adéquat pour la classification
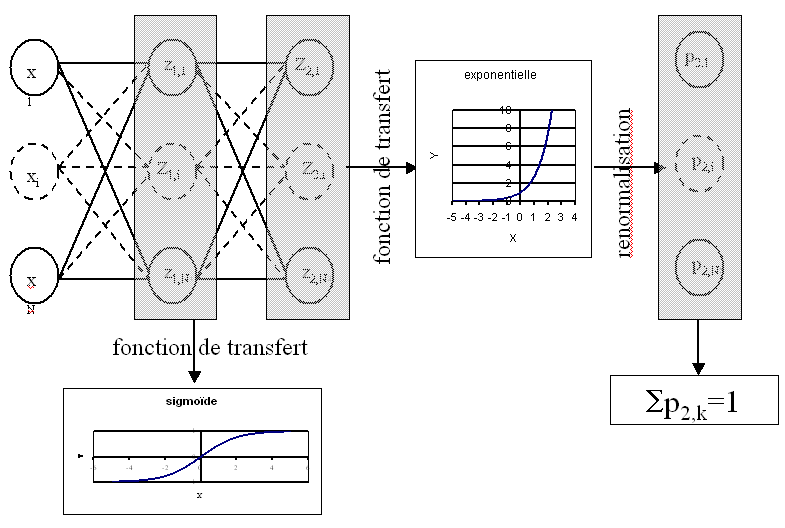
On en déduit que la fonction de transert des neurones de la couche de sortie est :
 .
La probabilité pour le vecteur
.
La probabilité pour le vecteur  d’appartenir à la classe
d’appartenir à la classe  est
est
 .
La fonction d’erreur à minimiser est l’opposé de la log-vraisemblance du modèle :
.
La fonction d’erreur à minimiser est l’opposé de la log-vraisemblance du modèle :

On note  le nombre de couches du réseau de neurones,
le nombre de couches du réseau de neurones,
 est la sortie avec
est la sortie avec
 ,
,
 où
où
 est le potentiel du neurone de la couche de sortie.
est le potentiel du neurone de la couche de sortie.
On calcule :

Cette équation permet d’adapter l’algorithme de la rétropropagation
décrivant rétropropagation pour le problème de la classification et pour
un exemple  .
Seule la couche de sortie change.
.
Seule la couche de sortie change.
Algorithme A1 : rétropropagation
Cet algorithme de rétropropagation est l’adaptation de
rétropropagation pour le problème
de la classification. Il suppose que l’algorithme de propagation
a été préalablement exécuté.
On note  ,
,
 et
et
 .
.
Initialiasation
 in
in 

Récurrence, Terminaison
Voir rétropropagation.
On vérifie que le gradient s’annule lorsque le réseau de neurones
retourne pour l’exemple  la
distribution de
la
distribution de  .
Cet algorithme de rétropropagation utilise un vecteur désiré de
probabilités
.
Cet algorithme de rétropropagation utilise un vecteur désiré de
probabilités  vérifiant
vérifiant
 .
L’expérience montre qu’il est préférable d’utiliser un vecteur vérifiant la contrainte :
.
L’expérience montre qu’il est préférable d’utiliser un vecteur vérifiant la contrainte :

Généralement,  est de l’ordre de
est de l’ordre de  ou
ou
 . Cette contrainte facilite le calcul de la vraisemblance
et évite l’obtention de gradients quasi-nuls qui freinent l’apprentissage
lorsque les fonctions exponnetielles sont saturées (voir [Bishop1995]).
. Cette contrainte facilite le calcul de la vraisemblance
et évite l’obtention de gradients quasi-nuls qui freinent l’apprentissage
lorsque les fonctions exponnetielles sont saturées (voir [Bishop1995]).