Note
Go to the end to download the full example code.
Arbre d’indécision¶
La construction d’un arbre de décision appliqué à une classification binaire suppose qu’on puisse déterminer un seuil qui sépare les deux classes ou tout du moins qui aboutisse à deux sous-ensemble dans lesquels une classe est majoritaire. Mais certains cas, c’est une chose compliquée.
Un cas simple et un cas compliqué¶
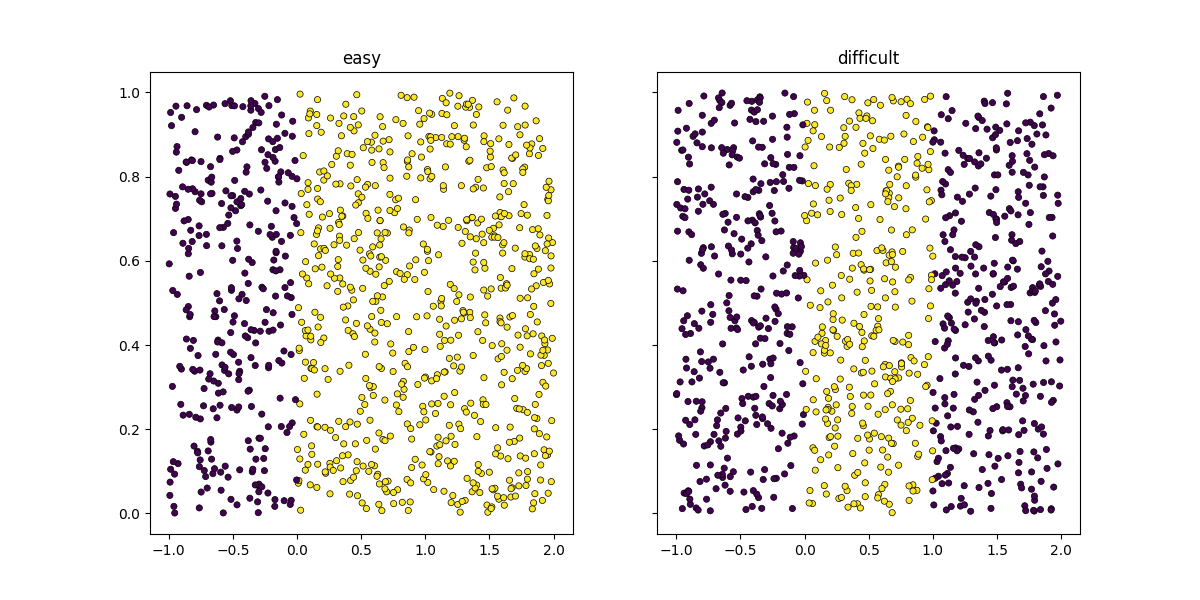
Il faut choisir un seuil sur l’axe des abscisses qui permette de classer le jeu de données.
import numpy
import matplotlib.pyplot as plt
from pandas import DataFrame
def random_set_1d(n, kind):
x = numpy.random.rand(n) * 3 - 1
if kind:
y = numpy.empty(x.shape, dtype=numpy.int32)
y[x < 0] = 0
y[(x >= 0) & (x <= 1)] = 1
y[x > 1] = 0
else:
y = numpy.empty(x.shape, dtype=numpy.int32)
y[x < 0] = 0
y[x >= 0] = 1
x2 = numpy.random.rand(n)
return numpy.vstack([x, x2]).T, y
def plot_ds(X, y, ax=None, title=None):
if ax is None:
ax = plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k", lw=0.5)
if title is not None:
ax.set_title(title)
return ax
X1, y1 = random_set_1d(1000, False)
X2, y2 = random_set_1d(1000, True)
fig, ax = plt.subplots(1, 2, figsize=(12, 6), sharey=True)
plot_ds(X1, y1, ax=ax[0], title="easy")
plot_ds(X2, y2, ax=ax[1], title="difficult")
<Axes: title={'center': 'difficult'}>
Seuil de décision¶
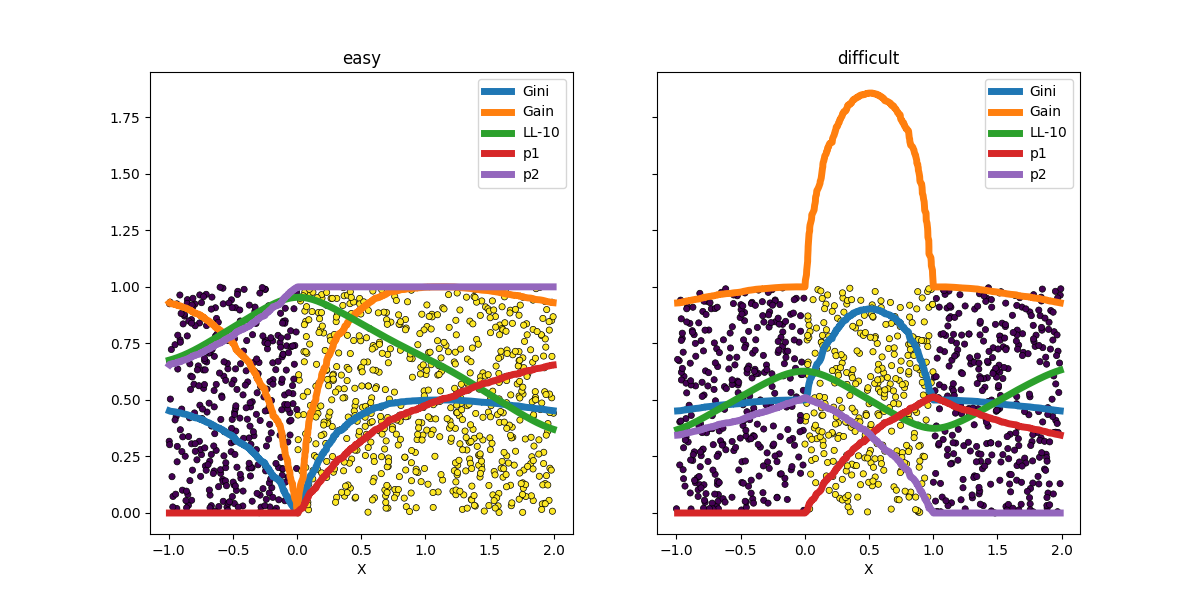
Les arbres de décision utilisent comme critère le critère de Gini ou l”entropie. L’apprentissage d’une régression logistique s’appuie sur la log-vraisemblance du jeu de données. On regarde l’évolution de ces critères en fonction des différents seuils possibles.
def plog2(p):
if p == 0:
return 0
return p * numpy.log(p) / numpy.log(2)
def logistic(x):
return 1.0 / (1.0 + numpy.exp(-x))
def likelihood(x, y, theta=1.0, th=0.0):
lr = logistic((x - th) * theta)
return y * lr + (1.0 - y) * (1 - lr)
def criteria(X, y):
res = numpy.empty((X.shape[0], 8))
res[:, 0] = X[:, 0]
res[:, 1] = y
order = numpy.argsort(res[:, 0])
res = res[order, :].copy()
x = res[:, 0].copy()
y = res[:, 1].copy()
for i in range(1, res.shape[0] - 1):
# gini
p1 = numpy.sum(y[:i]) / i
p2 = numpy.sum(y[i:]) / (y.shape[0] - i)
res[i, 2] = p1
res[i, 3] = p2
res[i, 4] = 1 - p1**2 - (1 - p1) ** 2 + 1 - p2**2 - (1 - p2) ** 2
res[i, 5] = -plog2(p1) - plog2(1 - p1) - plog2(p2) - plog2(1 - p2)
th = x[i]
res[i, 6] = logistic(th * 10.0)
res[i, 7] = numpy.sum(likelihood(x, y, 10.0, th)) / res.shape[0]
return DataFrame(
res[1:-1], columns=["X", "y", "p1", "p2", "Gini", "Gain", "lr", "LL-10"]
)
X1, y1 = random_set_1d(1000, False)
X2, y2 = random_set_1d(1000, True)
df = criteria(X1, y1)
print(df.head())
X y p1 p2 Gini Gain lr LL-10
0 -0.991554 0.0 0.0 0.683684 0.432521 0.900331 0.000049 0.709135
1 -0.990671 0.0 0.0 0.684369 0.432016 0.899567 0.000050 0.709295
2 -0.987143 0.0 0.0 0.685055 0.431509 0.898799 0.000052 0.709941
3 -0.987064 0.0 0.0 0.685743 0.430999 0.898027 0.000052 0.709955
4 -0.986999 0.0 0.0 0.686432 0.430486 0.897249 0.000052 0.709967
Et visuellement…
def plot_ds(X, y, ax=None, title=None):
if ax is None:
ax = plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k", lw=0.5)
if title is not None:
ax.set_title(title)
return ax
df1 = criteria(X1, y1)
df2 = criteria(X2, y2)
fig, ax = plt.subplots(1, 2, figsize=(12, 6), sharey=True)
plot_ds(X1, y1, ax=ax[0], title="easy")
plot_ds(X2, y2, ax=ax[1], title="difficult")
df1.plot(x="X", y=["Gini", "Gain", "LL-10", "p1", "p2"], ax=ax[0], lw=5.0)
df2.plot(x="X", y=["Gini", "Gain", "LL-10", "p1", "p2"], ax=ax[1], lw=5.0)
<Axes: title={'center': 'difficult'}, xlabel='X'>
Le premier exemple est le cas simple et tous les indicateurs trouvent bien la fontière entre les deux classes comme un extremum sur l’intervalle considéré. Le second cas est linéairement non séparable. Aucun des indicateurs ne semble trouver une des deux frontières. La log-vraisemblance montre deux maxima. L’un est bien situé sur une frontière, le second est situé à une extrémité de l’intervalle, ce qui revient à construire un classifier qui retourné une réponse constante. C’est donc inutile.
Total running time of the script: (0 minutes 0.958 seconds)