Liens entre factorisation de matrices, ACP, k-means¶
La factorisation de matrice non négative. Cette méthode est utilisée dans le cadre de la recommandation de produits à des utilisateurs. Lire également [Acara2011], [Gupta2010].
Factorisation de matrices et rang¶
La factorisation d’une matrice
est un problème d’optimisation qui consiste à trouver pour une matrice
 à coefficients positifs ou nuls :
à coefficients positifs ou nuls :

Où  et
et  sont de rang
sont de rang  et de dimension
et de dimension
 et
et  .
On s’intéresse ici au cas où les coefficients ne sont pas nécessairement positifs.
Si
.
On s’intéresse ici au cas où les coefficients ne sont pas nécessairement positifs.
Si  , le produit
, le produit  ne peut être égal à
ne peut être égal à  .
Dans ce cas, on cherchera les matrices qui minimise :
.
Dans ce cas, on cherchera les matrices qui minimise :
Problème P1 : Factorisation de matrices positifs
Soit , on cherche les matrices à coefficients positifs
et qui sont solution
du problème d’optimisation :

Quelques cas simples¶
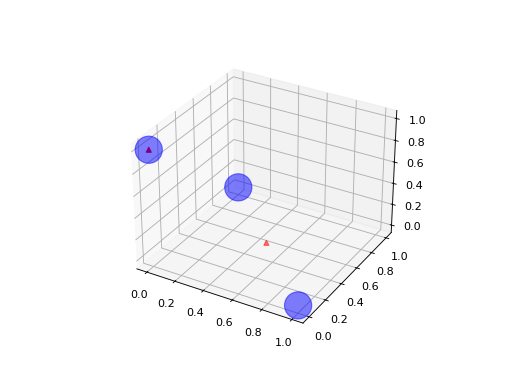
Le notebook Valeurs manquantes et factorisation de matrices montre la décroissante de l’erreur en fonction du rang et l’impact de la corrélation sur cette même erreur. Le dernier paragraphe montre qu’il n’existe pas de solution unique à un problème donné. L’exemple suivant s’intéresse à une matrice 3x3. Les trois points forment un triangle dans un plan.
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from numpy import identity, array
M = identity(3)
W = array([[0.5, 0.5, 0], [0, 0, 1]]).T
H = array([[1, 1, 0], [0.0, 0.0, 1.0]])
wh = W @ H
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(M[:,0], M[:,1], M[:,2], c='b', marker='o', s=600, alpha=0.5)
ax.scatter(wh[:,0], wh[:,1], wh[:,2], c='r', marker='^')
plt.show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
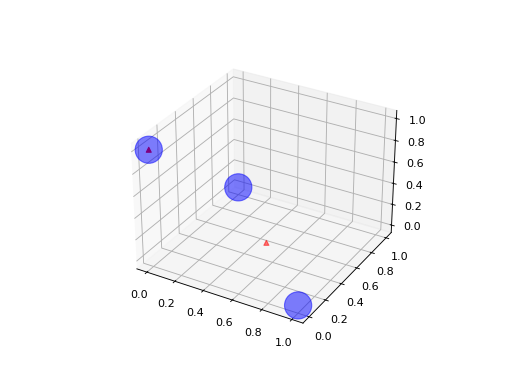
On peut voir la matrice comme un ensemble de  points dans un espace vectoriel.
La matrice est un ensemble de
points dans un espace vectoriel.
La matrice est un ensemble de  points dans le même espace.
La matrice , de rang est une approximation de cet ensemble
dans le même espace, c’est aussi
points dans le même espace.
La matrice , de rang est une approximation de cet ensemble
dans le même espace, c’est aussi  combinaisons linéaires de
points de façon à former points les plus proches proches de
points de la matrice .
combinaisons linéaires de
points de façon à former points les plus proches proches de
points de la matrice .
Intuition géométrique¶
L’exemple précédente suggère une interprétation géométrique d’une factorisation de matrice. Sans valeur manquante, ce problème est équivalent à une Analyse en Composantes Principales (ACP) (voir aussi [Boutsidis2008] (décomposition en valeurs singulières comme algorithme d’initialisation). Nous allons le montrer grâce à quelques lemmes et théorèmes.
Lemme L1 : Rang k
On note  ,
,
 ,
,  avec
avec
 ,
,  ,
et
,
et  avec
avec  .
On suppose que les matrices
sont solution du problème d’optimisation
.
On suppose que les matrices
sont solution du problème d’optimisation
 .
On suppose que
.
On suppose que  .
Alors les les matrices
.
Alors les les matrices  et
et  sont de rang .
sont de rang .
On procède par récurrence. Ce lemme est nécessairement vrai pour
 car la matrice n’est pas nulle.
De manière évidente,
car la matrice n’est pas nulle.
De manière évidente,
 .
Comme , il existe un vecteur colonne
.
Comme , il existe un vecteur colonne  de la matrice
qui ne fait pas partie de l’espace vectoriel engendré par les
de la matrice
qui ne fait pas partie de l’espace vectoriel engendré par les
 vecteurs de la matrice
vecteurs de la matrice  . On construit la matrice
. On construit la matrice
![Y^k= [W^{k-1}, V]](../_images/math/0980e342fb3a8ff9b13bcb435ba77248e8ee32d1.svg) . Par construction,
. Par construction,  . De même,
on construit
. De même,
on construit  à partir de
à partir de  en remplaçant la dernière colonne et
en ajoutant une ligne :
en remplaçant la dernière colonne et
en ajoutant une ligne :
![G^k=\cro{\begin{array}{cc} H^{k-1}[1..p-1] & 0 \\ 0 & 1 \end{array}}](../_images/math/dffeb25674d4677655104896dc01c1d0982716dc.svg)
Par construction, le dernier vecteur est de la matrice produit est identique
à celui de la matrice .

Nous avons fabriqué une matrice de rang k qui fait décroître l’erreur
du problème d’optimisation.
On procède par l’absurde pour dire que si
 , on peut construire une matrice de rang k
qui fait décroître l’erreur ce qui est impossible. Le lemme est donc vrai.
, on peut construire une matrice de rang k
qui fait décroître l’erreur ce qui est impossible. Le lemme est donc vrai.
Ce lemme fait également apparaître la construction de q points
dans un espace vectoriel engendré par les k vecteurs colonnes
de la matrice  . Il est donc possible de choisir
n’importe quel base
. Il est donc possible de choisir
n’importe quel base  de cet espace et d’exprimer
les q points de
de cet espace et d’exprimer
les q points de  avec cette nouvelle base.
Cela signifie qu’on peut écrire la matrice dans une base
avec cette nouvelle base.
Cela signifie qu’on peut écrire la matrice dans une base
 comme
comme  et
et  .
.
Lemme L2 : Projection
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de  points dans dans un espace vectoriel de dimension
points dans dans un espace vectoriel de dimension  .
La matrice représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice .
.
La matrice représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice .
La figure suivante illustre ce lemme.
 s’écrit comme la somme des distances entre
q points :
s’écrit comme la somme des distances entre
q points :
![\norm{ M - WH }^2 = \sum_{j=1}^q \norme{M[j] - W_kH_k[j]}^2](../_images/math/57d0ccecc393ab6b40fed122dbe268e48b566833.svg)
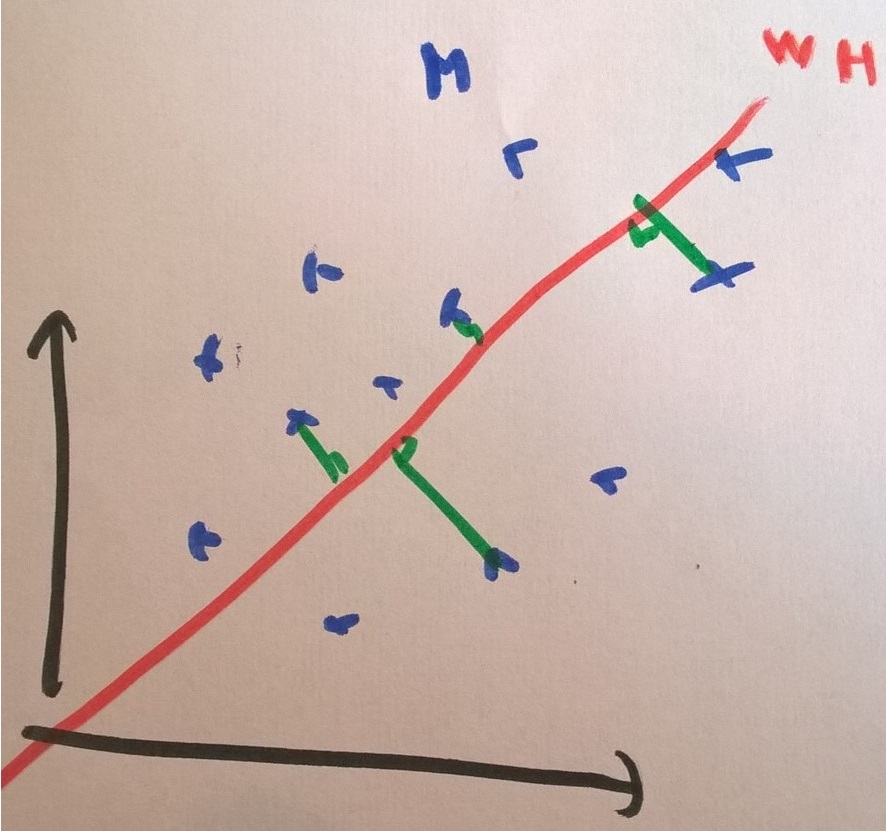
Or on sait que si est fixé, les q points de la matrice
évolue sur un hyperplan de dimension .
Le point de ce plan le plus du vecteur ![M[j]](../_images/math/f87c6da6694698ed1e64ed901149a07b07797052.svg) est sa projection
sur ce plan.
est sa projection
sur ce plan.
Théorème T1 : La factorisation de matrice est équivalente à une analyse en composantes principales
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de
points dans dans un espace vectoriel de dimension .
On suppose  .
La matrice définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
.
La matrice définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
 où
où  est la transposée de .
est la transposée de .
Une analyse en composante principale consiste à trouver l’hyperplan qui maximise l’inertie de la projection d’un nuage sur ce plan. Le théorème résolution de l’ACP a montré que :
(1)¶
Dans notre cas, chaque ligne de la matrice est un vecteur  .
La matrice est identique à celle cherchée lors du problème de factorisation
de matrices. Les colonnes de la matrice
.
La matrice est identique à celle cherchée lors du problème de factorisation
de matrices. Les colonnes de la matrice  sont égales à
sont égales à  .
Il reste à montrer que le minimum trouvé dans les deux problèmes est le même.
La démonstration du théorème montre également que
.
Il reste à montrer que le minimum trouvé dans les deux problèmes est le même.
La démonstration du théorème montre également que  et dans ce cas précis,
et dans ce cas précis,  représente les coordonnées de la projection
du point sur le plan défini par les vecteurs .
C’est aussi ce que montre second lemmme.
S’il s’agit du même plan, cela signifie que les deux formulations, ACP et factorisation
de matrices, aboutissent au même minimum. Comme l’algorithme de l’ACP détermine le meilleur
plan projecteur, nécessairement, il correspond à celui trouvé par la factorisation de matrice.
représente les coordonnées de la projection
du point sur le plan défini par les vecteurs .
C’est aussi ce que montre second lemmme.
S’il s’agit du même plan, cela signifie que les deux formulations, ACP et factorisation
de matrices, aboutissent au même minimum. Comme l’algorithme de l’ACP détermine le meilleur
plan projecteur, nécessairement, il correspond à celui trouvé par la factorisation de matrice.
k-means¶
On peut construire deux matrices et à partir des résultats d’un
k-means. Celui-ci détermine centres auxquels on effecte les points
du nuage de départ. Dans ce cas-ci, la matrice est constituée des coordonnées
de ces centres. On note  le cluster
le cluster  ,
la matrice est définie comme suit :
,
la matrice est définie comme suit :

Les coefficients sont soit 0 ou 1.
On peut alors essayer de forcer la factorisation de matrice vers une matrice
avec pas de un 1 sur chaque colonne et des zéros partout ailleurs.
Le résultat sera assez proche d’un clustering.
Quelques résultats¶
Le notebook suivant illustre le lien entre ACP et factorisation de matrices en deux dimensions.
Prolongements¶
Tous les résultats montrés ici ne sont valables que si la norme  est utilisée. Cela permet de mieux comprendre
les références proposées dans la documentation de
Non-negative matrix factorization (NMF or NNMF).
Si l’ACP et la factorisation de matrices sont équivalentes, les algorithmes pour
trouver le minimum diffèrent et sont plus ou moins appropriés dans
certaines configurations.
Lire [Gilles2014].
est utilisée. Cela permet de mieux comprendre
les références proposées dans la documentation de
Non-negative matrix factorization (NMF or NNMF).
Si l’ACP et la factorisation de matrices sont équivalentes, les algorithmes pour
trouver le minimum diffèrent et sont plus ou moins appropriés dans
certaines configurations.
Lire [Gilles2014].
Factorisation non-négative¶
Le problème le plus souvent évoqué est celui de la factorisation
non-négative : NMF.
Ce problème est une optimisation avec contrainte : les coefficients doivent
tous être positifs ou nuls. Il n’est bien sûr plus équivalent
à une ACP. En revanche, la factorisation de matrice est un problème
équivalent à celui résolu par la
Décomposition en Valeur Singulière (SVD)
qui cherche à décomposer une matrice  . La matrice
. La matrice  est une matrice diagonale et la matrice initiale M
n’est pas nécessairement carrée contrairement au cas d’une ACP
mais SVD et ACP sont très similaires.
est une matrice diagonale et la matrice initiale M
n’est pas nécessairement carrée contrairement au cas d’une ACP
mais SVD et ACP sont très similaires.
Prédiction¶
Prédire revient à supposer que la matrice est composée de vecteurs
lignes  . La matrice reste inchangée et la prédiction
revient à déterminer les coordonnées de la projection d’un nouveau point
. La matrice reste inchangée et la prédiction
revient à déterminer les coordonnées de la projection d’un nouveau point  dans le plan défini par les vecteurs de la matrice .
Pour de nouvelles observations
dans le plan défini par les vecteurs de la matrice .
Pour de nouvelles observations  ,
la fonction transform
de la classe
,
la fonction transform
de la classe sklearn.decomposition.NMF réestime une matrice
 qui projette les vecteurs lignes de
qui projette les vecteurs lignes de  sur
les vecteurs de H en conservant des coefficients de projection positifs.
sur
les vecteurs de H en conservant des coefficients de projection positifs.
Problème P2 : Prédiction
Soit et ,
on cherche les matrices à coefficients positifs
qui sont solution
du problème d’optimisation :

Les recommandations s’obtiennent en multipliant par .
Ce produit peut être approchée en relâchant la contrainte des poids
positifs pour la matrice W. C’est la piste proposée par le
modèle ApproximateNMFPredictor qui utilise une transformation
SVD pour projeter sur l’espace vectoriel formé par les vecteurs
de H.
Norme¶
L’ACP avec une norme  revient à trouver le plan qui minimise la somme
des distances à la projection et non la somme des distances au carrés. Cela réduit
l’impact des points aberrants mais le problème n’est plus équivalent à la factorisation
de matrices avec une norme .
revient à trouver le plan qui minimise la somme
des distances à la projection et non la somme des distances au carrés. Cela réduit
l’impact des points aberrants mais le problème n’est plus équivalent à la factorisation
de matrices avec une norme .
Sparsité¶
Une ACP suppose que le calcul de valeurs propres d’une matrice et c’est fastidieux lorsque la dimension du problème est très grande. On lui préfère alors un algorithme tel que Sparse PCA. La factorisation de matrice est plus efficace qu’une ACP sur les problèmes sparses et de grande dimension. Lire Non-negative Matrix Factorization with Sparseness Constraints.
Valeurs manquantes¶
Contourner le problème des valeurs manquantes veut souvent dire, soit supprimer les enregistrements contenant des valeurs manquantes, soit choisir un modèle capable de faire avec ou soit trouver un moyen de les remplacer. On peut gérer plus facilement le problème des valeurs manquantes avec une factorisation de matrices. On peut également se server de la méthode pour calculer une ACP avec des valeurs manquantes.
Interprétation¶
La factorisation de matrice peut être utilisée comme outil de segmentation et d’interprétation pour des images, des vidéos. Lire A tutorial on Non-Negative Matrix Factorisation with Applications to Audiovisual Content Analysis.
NTF¶
Le problème de Non-Negative Matrix Factorisation (NMF) est un cas particulier de Non-Negative Tensor Factorisation (NTF). Lire aussi PARAFAC. Tutorial and applications.
Bibliographie¶
Scalable tensorfactorizations for incomplete data, Evrim Acara Daniel, M.Dunlavyc, Tamara G.Koldab. Morten Mørupd, Chemometrics and Intelligent Laboratory Systems, Volume 106, Issue 1, 15 March 2011, Pages 41-56, or ArXiv 1005.2197
SVD-based initialization: A head start for nonnegative matrix factorization. Christos Boutsidis and Efstratios Gallopoulos Pattern Recognition, 41(4): 1350-1362, 2008.
The Why and How of Nonnegative Matrix Factorization, Nicolas Gillis, ArXiv 1401.5226