Listes des définitions et théorèmes¶
Corollaires¶
Corollaire C1 : Estimateur de l’aire sous la courbe ROC
On dispose des scores  des expériences qui ont réussi
et
des expériences qui ont réussi
et  les scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
Les scores
les scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
Les scores  sont identiquement distribués,
il en est de même pour les scores
sont identiquement distribués,
il en est de même pour les scores  .
Un estimateur de l’aire
.
Un estimateur de l’aire  sous la courbe ROC” est :
sous la courbe ROC” est :
(1)¶
Corollaire C1 : approximation d’une fonction créneau
Soit  ,
alors :
,
alors :

Corollaire C1 : nullité d’un coefficient
Les notations utilisées sont celles du théorème sur loi asymptotique des coefficients.
Soit  un poids du réseau de neurones
d’indice quelconque
un poids du réseau de neurones
d’indice quelconque  . Sa valeur estimée est
. Sa valeur estimée est  ,
sa valeur optimale
,
sa valeur optimale  . D’après le théorème :
. D’après le théorème :

Corollaire C2 : Variance de l’estimateur AUC
On note  et
et  .
.
 et
et  sont de même loi que
sont de même loi que  ,
,  ,
,  sont de même loi que
sont de même loi que  .
La variance de l’estimateur
.
La variance de l’estimateur  définie par (1) est :
définie par (1) est :

Corollaire C2 : approximation d’une fonction indicatrice
Soit  compact, alors :
compact, alors :

Corollaire C3 : famille libre de fonctions
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
avec  compact muni de la norme :
compact muni de la norme :
 Alors l’ensemble
Alors l’ensemble  des fonctions sigmoïdes :
des fonctions sigmoïdes :

est une base de .
Définitions¶
Définition D1 : B+ tree
Soit  un B+ tree, soit
un B+ tree, soit  un noeud de ,
il contient un vecteur
un noeud de ,
il contient un vecteur  avec
avec  et
et  .
Ce noeud contient aussi exactement
.
Ce noeud contient aussi exactement  noeuds fils
notés
noeuds fils
notés  . On désigne par
. On désigne par  l’ensemble des descendants du noeud
l’ensemble des descendants du noeud  et
et
 .
Le noeud vérifie :
.
Le noeud vérifie :

Définition D1 : Courbe ROC
On suppose que est la variable aléatoire des scores
des expériences qui ont réussi.
est celle des scores des expériences qui ont échoué.
On suppose également que tous les scores sont indépendants.
On note  et
et  les fonctions de répartition de ces variables.
les fonctions de répartition de ces variables.
 et
et  .
On définit en fonction d’un seuil
.
On définit en fonction d’un seuil  :
:


La courbe ROC est le graphe  lorsque
lorsque  varie dans
varie dans  .
.
Définition D1 : Dynamic Minimum Keystroke
On définit la façon optimale de saisir une requête sachant
un système de complétion  comme étant le
minimum obtenu :
comme étant le
minimum obtenu :
(1)¶![\begin{eqnarray*}
M'(q, S) &=& \min_{0 \leqslant k < l(q)} \acc{ M'(q[1..k], S) +
\min( K(q, k, S), l(q) - k) }
\end{eqnarray*}](_images/math/9c69c3ee6be2f50d6e58a57fbe787adcbd5da467.svg)
Définition D1 : Dynamic Minimum Keystroke arrière
On définit la façon optimale de saisir une requête
sachant un système de complétion
comme étant le minimum obtenu :
(1)¶![\begin{eqnarray*}
M'_b(q, S) &=& \min\acc{\begin{array}{l}
\min_{0 \leqslant k < l(q)} \acc{ M'_b(q[1..k], S) +
\min( K(q, k, S), l(q) - k) } \\
\min_{s \succ q} \acc{ M'_b(s, S) + l(s) - l(q) }
\end{array} }
\end{eqnarray*}](_images/math/1595286cb7291f6be9345f28e1a8f263b897e5a4.svg)
Définition D1 : Minimum Keystroke
On définit la façon optimale de saisir une requête sachant un système de complétion
comme étant le minimum obtenu :
(1)¶
La quantité  représente le nombre de touche vers le bas qu’il faut taper pour
obtenir la chaîne
représente le nombre de touche vers le bas qu’il faut taper pour
obtenir la chaîne  avec le système de complétion et les
premières lettres de .
avec le système de complétion et les
premières lettres de .
Définition D1 : Régression quantile
On dispose d’un ensemble de n couples
 avec
avec  et
et  . La régression quantile
consiste à trouver
. La régression quantile
consiste à trouver  tels que la
somme
tels que la
somme  est minimale.
est minimale.
Définition D1 : bruit blanc
Une suite de variables aléatoires réelles
 est un bruit blanc :
est un bruit blanc :
 ,
, 

Définition D1 : loi de Poisson et loi exponentielle
Si une variable suit une loi de Poisson de
paramète  , elle a pour densité :
, elle a pour densité :

Si une variable suit une loi exponentielle de paramètre  , elle a pour densité :
, elle a pour densité :

Définition D1 : mot
On note  l’espace des caractères ou des symboles. Un mot ou une séquence est
une suite finie de . On note
l’espace des caractères ou des symboles. Un mot ou une séquence est
une suite finie de . On note
 l’espace des mots formés
de caractères appartenant à .
l’espace des mots formés
de caractères appartenant à .
Définition D1 : mélange de lois normales
Soit une variable aléatoire d’un espace vectoriel de dimension  ,
suit un la loi d’un mélange de lois gaussiennes de paramètres
,
suit un la loi d’un mélange de lois gaussiennes de paramètres
 ,
alors la densité
,
alors la densité  de est de la forme :
de est de la forme :

Avec :  .
.
Définition D1 : neurone
Un neurone à  entrées est une fonction
entrées est une fonction
 définie par :
définie par :

 ,
, 
 avec
avec 
Définition D1 : neurone distance
Un neurone distance à entrées est une fonction
définie par :

- ,

 avec
avec
Définition D1 : orthonormalisation de Schmidt
L’orthonormalisation de Shmidt :
Soit  une base de
une base de 
On définit la famille  par :
par :

Définition D2 : Dynamic Minimum Keystroke modifié
On définit la façon optimale de saisir une requête sachant
un système de complétion comme étant le
minimum obtenu :
(2)¶![\begin{eqnarray*}
M"(q, S) &=& \min \left\{ \begin{array}{l}
\min_{1 \leqslant k \leqslant l(q)} \acc{ M"(q[1..k-1], S) + 1 +\min( K(q, k, S), l(q) - k) } \\
\min_{0 \leqslant k \leqslant l(q)} \acc{ M"(q[1..k], S) + \delta + \min( K(q, k, S), l(q) - k) }
\end{array} \right .
\end{eqnarray*}](_images/math/d0fe3ddfc9d9f0cd466520c02a4417e80ff8a033.svg)
Définition D2 : Régression quantile
On dispose d’un ensemble de n couples
avec
et . La régression quantile
consiste à trouver tels que la
somme  est minimale.
est minimale.
Définition D2 : couche de neurones
Soit et  deux entiers naturels,
on note
deux entiers naturels,
on note  avec
avec  .
Une couche de neurones et entrées est une fonction :
.
Une couche de neurones et entrées est une fonction :

vérfifiant :
 est un neurone.
est un neurone.
Définition D2 : distance d’édition
La distance d’édition sur  est définie par :
est définie par :

Définition D2 : neurone distance pondérée
Pour un vecteur donné  ,
on note
,
on note  .
Un neurone distance pondérée à entrées est une fonction
.
Un neurone distance pondérée à entrées est une fonction
 définie par :
définie par :
 ,
, 
 avec
avec
Définition D2 : taux de classification à erreur fixe
On cherche un taux de reconnaissance pour un taux d’erreur donné.
On dispose pour cela d’une courbe ROC obtenue par
l’algorithme de la courbe ROC et définie par les points
 .
On suppose ici que
.
On suppose ici que  et
et  .
Si ce n’est pas le cas, on
ajoute ces valeurs à l’ensemble
.
Si ce n’est pas le cas, on
ajoute ces valeurs à l’ensemble  .
.
Pour un taux d’erreur donné  , on cherche
, on cherche  tel que :
tel que :

Le taux de reconnaissance  cherché est donné par :
cherché est donné par :

Définition D3 : distance entre caractères
Soit  l’ensemble des caractères ajouté au caractère vide
l’ensemble des caractères ajouté au caractère vide ..
On note  la fonction coût définie comme suit :
la fonction coût définie comme suit :
(1)¶
On note  l’ensemble des suites finies de
l’ensemble des suites finies de  .
.
Définition D3 : réseau de neurones multi-couches ou perceptron
Un réseau de neurones multi-couches à sorties,
entrées et couches est une liste de couches
 connectées les unes aux autres de telle sorte que :
connectées les unes aux autres de telle sorte que :
 ,
chaque couche
,
chaque couche  possède
possède  neurones et
neurones et  entrées
entrées ,
de plus
,
de plus  et
et 
Les coefficients de la couche sont notés
 , cette couche définit une fonction
, cette couche définit une fonction
 .
Soit la suite
.
Soit la suite  définie par :
définie par :

On pose  ,
le réseau de neurones ainsi défini est une fonction
,
le réseau de neurones ainsi défini est une fonction  telle que :
telle que :

Définition D4 : mot acceptable
Soit  un mot tel qu’il est défini précédemment.
Soit
un mot tel qu’il est défini précédemment.
Soit  une suite infinie de caractères, on dit que
une suite infinie de caractères, on dit que
 est un mot acceptable pour
est un mot acceptable pour  si et seulement si la sous-suite
extraite de contenant tous les caractères différents de
si et seulement si la sous-suite
extraite de contenant tous les caractères différents de  est égal au mot . On note
est égal au mot . On note  l’ensemble des mots acceptables pour le mot .
l’ensemble des mots acceptables pour le mot .

Définition D6 : distance d’édition étendue
Soit d^* la distance d’édition définie en 2
pour laquelle les coûts de comparaison, d’insertion et de suppression
sont tous égaux à 1.
La distance d’édition  sur est définie par :
sur est définie par :
(6)¶
Définition D7 : distance d’édition tronquée
Soient deux mots  , on définit la suite :
, on définit la suite :

Par :
![\left\{
\begin{array}[c]{l}%
d_{0,0}=0\\
d_{i,j}=\min\left\{
\begin{array}{lll}
d_{i-1,j-1} & + & \text{comparaison} \left( m_1^i,m_2^j\right), \\
d_{i,j-1} & + & \text{insertion} \left( m_2^j\right), \\
d_{i-1,j} & + & \text{suppression} \left( m_1^i\right)
\end{array}
\right\}%
\end{array}
\right.](_images/math/5435d1d33e5aae5fc5a739c364c7b3c2f7ea7a9a.svg)
Définition D8 : distance d’édition tronquée étendue
Soit deux mots , on définit la suite :
par :
![\left\{
\begin{array}[c]{l}%
d_{0,0}=0\\
d_{i,j}=\min\left\{
\begin{array}{lll}
d_{i-1,j-1} & + & \text{comparaison} \pa{m_1^i,m_2^j}, \\
d_{i,j-1} & + & \text{insertion} \pa{m_2^j,i}, \\
d_{i-1,j} & + & \text{suppression} \pa{m_1^i,j}, \\
d_{i-2,j-2} & + & \text{permutation} \pa{ \pa{m_1^{i-1}, m_1^i},\pa{m_2^{j-1}, m_2^j}}
\end{array}
\right\}%
\end{array}
\right.](_images/math/46a0f990a1ff8c1ddbaa0d5598d9536e503510c6.svg)
Lemmes¶
 la longueur du plus long préfixe de
la longueur du plus long préfixe de 
![\begin{eqnarray*}
M'(q, S) &=& \min_{d(q, S) \leqslant k < l(q)} \acc{ M'(q[1..k], S) + \min( K(q, k, S), l(q) - k) }
\end{eqnarray*}](_images/math/50b4a7cbde33f5299a77073bd4838dd4a187bee7.svg)
Lemme L1 : M” et sous-ensemble
On suppose que la complétion est préfixe
pour la requête  et
et
 ce qui signifie
que la complétion est toujours affichée
avant la complétion si elles apparaissent ensemble.
Alors
ce qui signifie
que la complétion est toujours affichée
avant la complétion si elles apparaissent ensemble.
Alors  .
Plus spécifiquement, si on considère l’ensemble
.
Plus spécifiquement, si on considère l’ensemble
 (
( est la complétion
sans son préfixe ).
est la complétion
sans son préfixe ).

Lemme L1 : Rang k
On note  ,
,
 ,
,  avec
avec
 ,
,  ,
et
,
et  avec
avec  .
On suppose que les matrices
sont solution du problème d’optimisation
.
On suppose que les matrices
sont solution du problème d’optimisation
 .
On suppose que
.
On suppose que  .
Alors les les matrices
.
Alors les les matrices  et
et  sont de rang .
sont de rang .
Lemme L1 : inertie minimum
Soit  ,
,
 points de
points de  , le minimum de la quantité
, le minimum de la quantité
 :
:

est atteint pour  le barycentre des points
le barycentre des points  .
.
Lemme L2 : Projection
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de
points dans dans un espace vectoriel de dimension .
La matrice  représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice
représente des projections de ces points
dans l’espace vectoriel engendré par les vecteurs colonnes
de la matrice  .
.
Lemme L2 : calcul de *M”(q, S)*
On suppose que  est la complétion la plus longue
de l’ensemble qui commence :
est la complétion la plus longue
de l’ensemble qui commence :
![\begin{eqnarray*}
k^* &=& \max\acc{ k | q[[1..k]] \prec q \text{ et } q \in S} \\
p(q, S) &=& q[[1..k^*]]
\end{eqnarray*}](_images/math/e35e9815279f875e42d6a461ad6dc04132497f67.svg)
La métrique  vérifie la propriété suivante :
vérifie la propriété suivante :

Figures¶
Figure F1 : Gradient conjugué
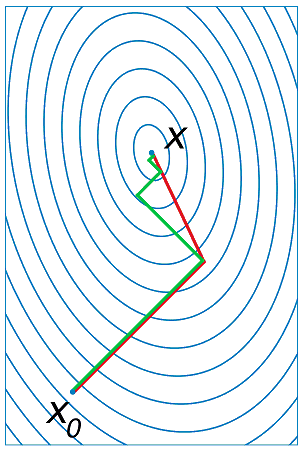
Gradient et gradient conjugué sur une ligne de niveau de la fonction  ,
le gradient est orthogonal aux lignes de niveaux de la fonction
,
le gradient est orthogonal aux lignes de niveaux de la fonction  ,
mais cette direction est rarement la bonne à moins que le point
,
mais cette direction est rarement la bonne à moins que le point
 se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
se situe sur un des axes des ellipses,
le gradient conjugué agrège les derniers déplacements et propose une direction
de recherche plus plausible pour le minimum de la fonction.
Voir Conjugate Gradient Method.
Figure F1 : Modèle optimal pour la base de test
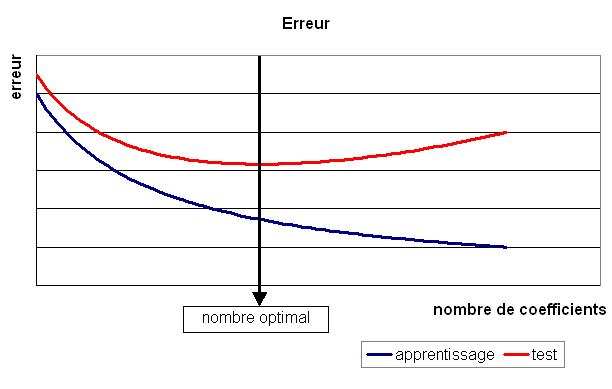
Figure F1 : Principe de la compression par un réseau diabolo

Figure F1 : Réseau de neurones adéquat pour la classification
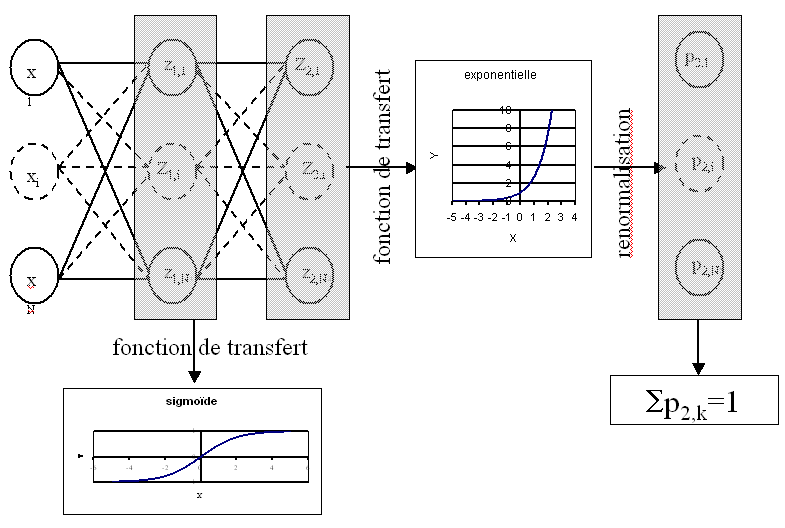
Figure F1 : neurone graphique

Le vecteur  joue le rôle des entrées.
joue le rôle des entrées.
 est appelé parfois le potentiel.
est appelé parfois le potentiel.
 .
.
 est appelée la sortie du neurone.
est appelée la fonction de transfert ou de seuil.
est appelée la sortie du neurone.
est appelée la fonction de transfert ou de seuil.
 .
.
Figure F2 : Exemple de minimal locaux
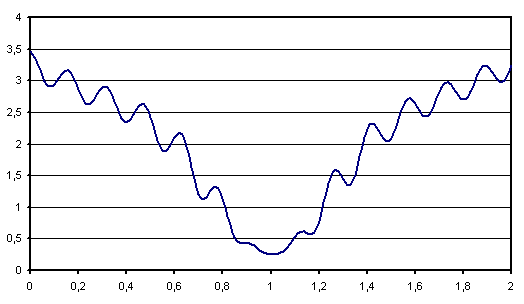
Figure F2 : Modèle du perceptron multi-couche (multi-layer perceptron, MLP)
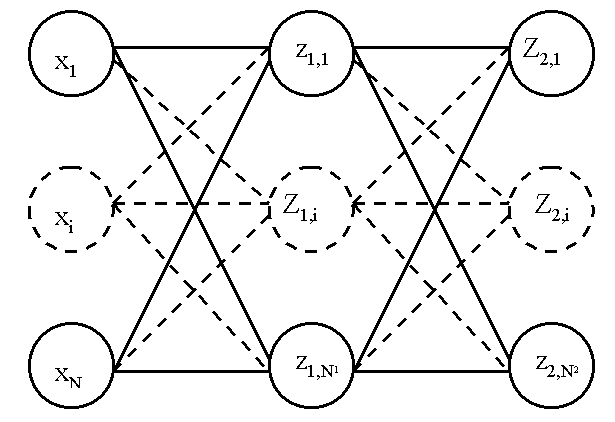
 : entrées
: entrées- nombre de neurones sur la couche
 ,
, 
 sortie du neurone , de la couche
sortie du neurone , de la couche  , par extension,
, par extension, 
 potentiel du neurone de la couche
potentiel du neurone de la couche  coefficient associé à l’entrée
coefficient associé à l’entrée  du neurone de la couche ,
du neurone de la couche , biais du neurone de la couche
biais du neurone de la couche  fonction de seuil du neurone de la couche
fonction de seuil du neurone de la couche
Figure F2 : Réseau de neurones pour lequel la sélection de connexions s’applique
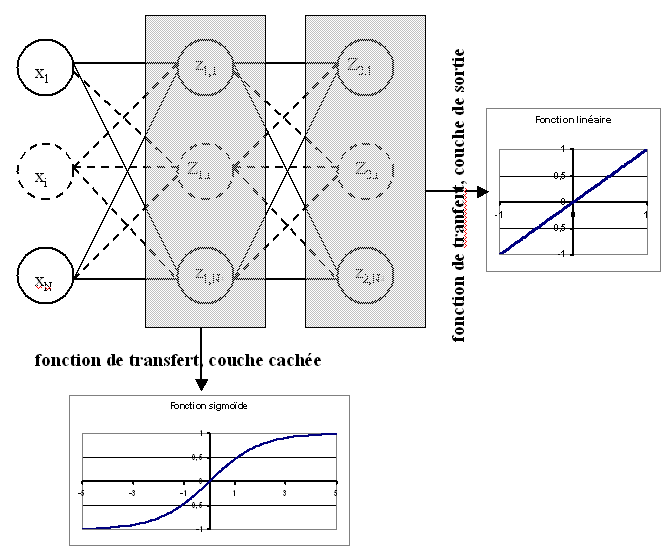
Figure F2 : Réseau diabolo : réduction d’une dimension

Ce réseau possède 3 entrées et 3 sorties
Minimiser l’erreur  revient à compresser un vecteur de dimension 3 en un vecteur de dimension 2.
Les coefficients de la
première couche du réseau de neurones permettent de compresser les données.
Les coefficients de la seconde couche permettent de les décompresser.
revient à compresser un vecteur de dimension 3 en un vecteur de dimension 2.
Les coefficients de la
première couche du réseau de neurones permettent de compresser les données.
Les coefficients de la seconde couche permettent de les décompresser.
Figure F3 : Courbe d’inertie pour l’ACP
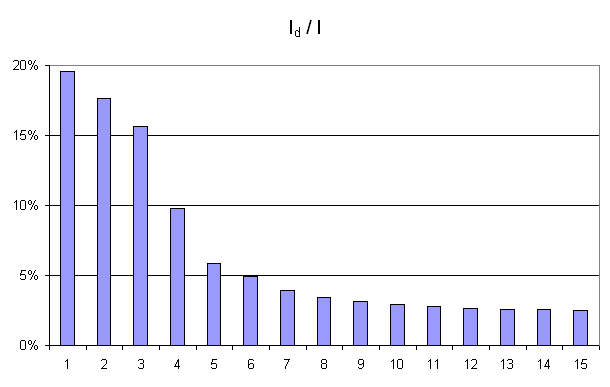
Courbe d’inertie : point d’inflexion pour  ,
l’expérience montre que généralement, seules les
projections sur un ou plusieurs des quatre premiers vecteurs propres
reflètera l’information contenue par le nuage de points.
,
l’expérience montre que généralement, seules les
projections sur un ou plusieurs des quatre premiers vecteurs propres
reflètera l’information contenue par le nuage de points.
Problèmes¶
Problème P1 : Classification
Soit une variable aléatoire
et une variable aléatoire discrète  ,
l’objectif est d’approximer la fonction
,
l’objectif est d’approximer la fonction  .
Les données du problème sont
un échantillon de points :
.
Les données du problème sont
un échantillon de points :  avec
avec  et un modèle paramétré avec
et un modèle paramétré avec  :
:

avec  ,
,  est une fonction de paramètre
à valeur dans
est une fonction de paramètre
à valeur dans  et vérifiant la
contrainte :
et vérifiant la
contrainte :  .
.
Problème P1 : Factorisation de matrices positifs
Soit  , on cherche les matrices à coefficients positifs
, on cherche les matrices à coefficients positifs
 et
et  qui sont solution
du problème d’optimisation :
qui sont solution
du problème d’optimisation :

Problème P1 : Optimiser un système de complétion
On suppose que l’ensemble des complétions  est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions
est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions  qu’on considère comme une permutation
qu’on considère comme une permutation
 de l’ensemble de départ :
de l’ensemble de départ :  .
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
 .
.
 est la requête,
est la requête,  est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :

Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise  .
.
Problème P1 : Régression
Soient deux variables aléatoires et ,
l’objectif est d’approximer la fonction
.
Les données du problème sont
un échantillon de points  et un modèle paramétré avec :math:theta` :
et un modèle paramétré avec :math:theta` :

avec ,
 bruit blanc,
est une fonction de paramètre .
bruit blanc,
est une fonction de paramètre .
Problème P1 : analyse en composantes principales (ACP)
Soit  avec
avec  .
Soit
.
Soit  ,
,  où les vecteurs
où les vecteurs  sont les colonnes de et
sont les colonnes de et  .
On suppose également que les forment une base othonormée.
Par conséquent :
.
On suppose également que les forment une base othonormée.
Par conséquent :

 est l’ensemble des
vecteurs
est l’ensemble des
vecteurs  projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver
projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver  tel que :
tel que :
(1)¶
Le terme  est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur  tel que :
tel que :

On cherche le vecteur  vérifiant :
vérifiant :

Problème P2 : Optimiser un système de complétion filtré
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
On utilise aussi une fonction qui filtre les suggestions montrées
à l’utilisateur, elle ne change pas l’ordre mais peut cacher certaines suggestions
si elles ne sont pas pertinentes.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :

Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise  .
.
Problème P2 : Prédiction
Soit et ,
on cherche les matrices à coefficients positifs
qui sont solution
du problème d’optimisation :

Problème P2 : classification
Soit l’échantillon suivant :

 représente la probabilité que l’élément
appartiennent à la classe :
représente la probabilité que l’élément
appartiennent à la classe :

Le classifieur cherché est une fonction définie par :

Dont le vecteur de poids est égal à :

Propriétés¶
Problème P1 : Classification
Soit une variable aléatoire
et une variable aléatoire discrète ,
l’objectif est d’approximer la fonction .
Les données du problème sont
un échantillon de points :
avec
et un modèle paramétré avec :
avec , est une fonction de paramètre
à valeur dans et vérifiant la
contrainte : .
Problème P1 : Factorisation de matrices positifs
Soit , on cherche les matrices à coefficients positifs
et qui sont solution
du problème d’optimisation :
Problème P1 : Optimiser un système de complétion
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise .
Problème P1 : Régression
Soient deux variables aléatoires et ,
l’objectif est d’approximer la fonction
.
Les données du problème sont
un échantillon de points
et un modèle paramétré avec :math:theta` :
avec ,
bruit blanc,
est une fonction de paramètre .
Problème P1 : analyse en composantes principales (ACP)
Soit avec .
Soit ,
où les vecteurs
sont les colonnes de et .
On suppose également que les forment une base othonormée.
Par conséquent :
est l’ensemble des
vecteurs projetés sur le sous-espace vectoriel
engendré par les vecteurs .
Réaliser une analyse en composantes principales, c’est trouver le
meilleur plan de projection pour les vecteurs
, celui qui maximise l’inertie de ce nuage de points,
c’est donc trouver tel que :
(1)¶
Le terme est l’inertie du nuage de points
projeté sur le sous-espace vectoriel défini par les
vecteurs colonnes de la matrice .
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur tel que :
On cherche le vecteur vérifiant :
Problème P2 : Optimiser un système de complétion filtré
On suppose que l’ensemble des complétions est connu.
On souhaite ordonner cet ensemble pour obtenir l’ensemble ordonné
des complétions qu’on considère comme une permutation
de l’ensemble de départ : .
On utilise aussi une fonction qui filtre les suggestions montrées
à l’utilisateur, elle ne change pas l’ordre mais peut cacher certaines suggestions
si elles ne sont pas pertinentes.
Ce système de complétion est destiné à un des utilisateurs qui forment des recherches ou requêtes
.
est la requête, est la fréquence associée
à cette requête. On définit l’effort demandé aux utilisateurs
par ce système de complétion :
Déterminer le meilleur système de complétion revient à trouver
la permutation qui minimise .
Problème P2 : Prédiction
Soit et ,
on cherche les matrices à coefficients positifs
qui sont solution
du problème d’optimisation :
Problème P2 : classification
Soit l’échantillon suivant :
représente la probabilité que l’élément
appartiennent à la classe :
Le classifieur cherché est une fonction définie par :
Dont le vecteur de poids est égal à :
Tables¶
Théorèmes¶
Théorème T1 : Aire sous la courbe (AUC)
On utilise les notations de la définition de la Courbe ROC.
L’aire sous la courbe ROC est égale à  .
.
Théorème T1 : La factorisation de matrice est équivalente à une analyse en composantes principales
On note ,
, avec
, ,
et avec .
On suppose que les matrices
sont solution du problème d’optimisation
.
On considère que la matrice est un ensemble de
points dans dans un espace vectoriel de dimension .
On suppose  .
La matrice
.
La matrice  définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
définit un hyperplan identique à celui défini
par les vecteurs propres associés aux
plus grande valeurs propres de la matrice
 où
où  est la transposée de .
est la transposée de .
Théorème T1 : M”, ordre et sous-ensemble
Soit une requête de l’ensemble de complétion
ordonnées selon  .
Si cet ordre vérifie :
.
Si cet ordre vérifie :
(1)¶![\forall k, \; \sigma(q[1..k]) \leqslant \sigma(q[1..k+1])](_images/math/b663cb8fb181ddfebf111d9c260278334f8fa92c.svg)
On note l’ensemble ![S'(q[1..k]) = \acc{ q[k+1..len(q)] \in S }](_images/math/c44a8a7b5ef4bd61c42664cc666fa5ebd2343672.svg) :
:
alors :
![\forall k, \; M'(q[1..k], S) = M'(q[k+1..l(q)], S'(q[1..k]) + M'(q[1..k], S)](_images/math/a63144c15f2d63a43b0a04a13abe64b9bef23fdf.svg)
Théorème T1 : Régression linéaire après Gram-Schmidt
Soit une matrice  avec
avec
 . Et un vecteur
. Et un vecteur  .
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
.
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
 ou
ou  .
.
 et
et  .
La matrice T est triangulaire supérieure
et vérifie
.
La matrice T est triangulaire supérieure
et vérifie  (
( est la matrice identité). Alors
est la matrice identité). Alors
 .
.
 est la solution du problème d’optimisation
est la solution du problème d’optimisation
 .
.
Théorème T1 : [Farago1993]_ 1
Les notations sont celles de l’algorithme précédent.
Il retourne le plus proche voisin  de
de
 inclus dans
inclus dans  .
Autrement dit,
.
Autrement dit,  .
.
Théorème T1 : convergence de la méthode de Newton
Soit une fonction continue  de classe
de classe  .
On suppose les hypothèses suivantes vérifiées :
.
On suppose les hypothèses suivantes vérifiées :
H1 :
 est un singleton
est un singletonH2 :
![\forall\varepsilon>0, \; \underset{\left| W-W^{\ast}\right|
>\varepsilon}{\inf}\left[ \left( W-W^{\ast}\right) ^{\prime}.\nabla
g\left( W\right) \right] >0](_images/math/cd5c8eeb11c1af5fd5a8957eef0148c34c6fbcbe.svg)
H3 :
 tels que
tels que 
H4 : la suite
 vérifie,
vérifie,
 et
et  ,
,

Alors la suite  construite de la manière suivante
construite de la manière suivante
 ,
,  :
:
 vérifie
vérifie  .
.
Théorème T1 : convergence des k-means
Quelque soit l’initialisation choisie, la suite  construite par l’algorithme des k-means
converge.
construite par l’algorithme des k-means
converge.
Théorème T1 : convexité des classes formées par une régression logistique
On définit l’application  qui associe la plus grande coordonnée
qui associe la plus grande coordonnée
 .
A est une matrice
.
A est une matrice  ,
B est un vecteur de
,
B est un vecteur de  ,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
Théorème T1 : densité des réseaux de neurones (Cybenko1989)
[Cybenko1989]
Soit  l’espace des réseaux de neurones à
entrées et sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
l’espace des réseaux de neurones à
entrées et sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
 ,
une couche de sortie dont la fonction de seuil est linéaire
Soit
,
une couche de sortie dont la fonction de seuil est linéaire
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
compact muni de la norme
Alors est dense dans .
avec
compact muni de la norme
Alors est dense dans .
Théorème T1 : distance d’édition
Soit et les fonctions définies respectivement par
(1) et (2), alors :
est une distance sur
Théorème T1 : loi asymptotique des coefficients
Soit un réseau de neurone défini par perceptron
composé de :
une couche d’entrées
une couche cachée dont les fonctions de transfert sont sigmoïdes
une couche de sortie dont les fonctions de transfert sont linéaires
Ce réseau sert de modèle pour la fonction
dans le problème de régression
avec un échantillon  ,
les résidus sont supposés normaux.
La suite
,
les résidus sont supposés normaux.
La suite  définie par (2) vérifie :
définie par (2) vérifie :

Et le vecteur aléatoire  vérifie :
vérifie :

Où la matrice  est définie par (2).
est définie par (2).
end{xtheorem}
Théorème T1 : résolution de l’ACP
Les notations utilisées sont celles du problème de l”ACP. Dans ce cas :
(2)¶
De plus est l’espace vectoriel engendré par les
vecteurs propres de la matrice
 associées aux
valeurs propres de plus grand module.
associées aux
valeurs propres de plus grand module.
Théorème T1 : résolution du problème du maximum de vraisemblance
La solution du problème du maximum de vraisemblance est le vecteur :

Théorème T1 : simulation d’une loi quelconque
Soit  une fonction de répartition de densité
vérifiant
une fonction de répartition de densité
vérifiant  , soit
, soit  une variable
aléatoire uniformément distribuée sur alors
une variable
aléatoire uniformément distribuée sur alors
 est variable aléatoire de densité .
est variable aléatoire de densité .
Théorème T2 : Borne supérieure de l’erreur produite par k-means++
On définit l’inertie par
 .
Si
.
Si  définit l’inertie optimale alors
définit l’inertie optimale alors
 .
.
Théorème T2 : [Farago1993]_ 2
Les notations sont celles du même algorithme.
On définit une mesure sur l’ensemble ,
 désigne la boule de centre
et de rayon
désigne la boule de centre
et de rayon  ,
,
 une variable aléatoire, de plus :
une variable aléatoire, de plus :

On suppose qu’il existe  et une fonction
et une fonction  tels que :
tels que :

La convergence doit être uniforme et presque sûre.
On note également  le nombre de calculs de
dissimilarité effectués par l’algorithme
où est le nombre d’élément de ,
désigne toujours le nombre de pivots, alors :
le nombre de calculs de
dissimilarité effectués par l’algorithme
où est le nombre d’élément de ,
désigne toujours le nombre de pivots, alors :

Théorème T2 : rétropropagation
Cet algorithme s’applique à un réseau de neurones vérifiant la définition du perceptron.
Il s’agit de calculer sa dérivée par rapport aux poids. Il se déduit des formules
(3), (4), (5) et (7)
et suppose que l’algorithme de propagation a été préalablement exécuté.
On note  ,
,  et
et
 .
.
Initialisation


Récurrence






Terminaison




Théorème T2 : simulation d’une loi de Poisson
On définit une suite infinie  de loi
exponentielle de paramètre
de loi
exponentielle de paramètre  . On définit ensuite
la série de variables aléatoires
. On définit ensuite
la série de variables aléatoires  et enfin
et enfin  .
Alors la variable aléatoire
.
Alors la variable aléatoire  suit une loi
de Poisson de paramètre .
suit une loi
de Poisson de paramètre .
Théorème T2 : sélection d’architecture
Les notations utilisées sont celles du théorème
loi asymptotique des coefficients.
est un réseau de neurones
de paramètres . On définit la constante  ,
en général
,
en général  puisque
puisque
 si
si  .
.
Initialisation
Une architecture est choisie pour le réseau de neurones incluant un nombre M de paramètres.
Apprentissage
Le réseau de neurones est appris. On calcule les nombre et matrice
 et .
La base d’apprentissage contient exemples.
et .
La base d’apprentissage contient exemples.
Test
in 

Sélection


 est supprimée ou le poids
est supprimée ou le poids  est maintenue à zéro.
est maintenue à zéro.
Théorème T3 : somme de loi exponentielle iid
Soit  variables aléatoires indépendantes
et identiquement distribuées de loi
variables aléatoires indépendantes
et identiquement distribuées de loi  alors la
somme
alors la
somme  suit une loi
suit une loi  .
.