Note
Go to the end to download the full example code.
102: Fuse kernels in a small Llama Model¶
This example leverages the function torch.compile and the ability to use a custom backend (see Custom Backends) to test the optimization of a model by fusing simple element-wise kernels.
It takes a small Llama model and uses a backend based on onnxruntime. The model is converted into ONNX and then optimized by fusing element-wise kernels.
python plot_custom_backend_llama --config large
The script requires the following packages beside pytorch, onnxruntime-training (for GPU), onnx-extended (compiled for GPU) and transformers.
from experimental_experiment.args import get_parsed_args
script_args = get_parsed_args(
"plot_custom_backend_llama",
config=("medium", "large or medium depending, large means closer to the real model"),
num_hidden_layers=(1, "number of hidden layers"),
with_mask=(0, "tries with a mask as a secondary input"),
optim=("", "Optimization to apply, empty string for all"),
description=__doc__,
expose="config,num_hidden_layers,with_mask,optim",
)
print(f"config={script_args.config!r}")
print(f"num_hidden_layers={script_args.num_hidden_layers!r}")
print(f"with_mask={script_args.with_mask!r}")
print(f"optim={script_args.optim!r}")
config='medium'
num_hidden_layers=1
with_mask=0
optim=''
Imports.
import time
import numpy as np
import pandas
from tqdm import tqdm
import torch
from transformers import LlamaConfig
from transformers.models.llama.modeling_llama import LlamaModel
from experimental_experiment.xbuilder import OptimizationOptions
from experimental_experiment.torch_dynamo import onnx_custom_backend
from experimental_experiment.bench_run import get_machine
from experimental_experiment.ext_test_case import unit_test_going
has_cuda = torch.cuda.device_count() > 0
machine = get_machine()
print(f"has_cuda={has_cuda}")
print(f"processor: {machine['processor_name']}")
print(f"device: {machine.get('device_name', '?')}")
has_cuda=True
processor: 13th Gen Intel(R) Core(TM) i7-13800H
device: NVIDIA GeForce RTX 4060 Laptop GPU
The dummy model¶
def ids_tensor(shape, vocab_size):
total_dims = 1
for dim in shape:
total_dims *= dim
values = []
for _ in range(total_dims):
values.append(np.random.randint(0, vocab_size - 1))
return torch.tensor(data=values, dtype=torch.long).view(shape).contiguous()
The size of the input.
if script_args.config == "large":
batch, seq, vocab_size = 2, 1024, 32000
intermediate_size = 11008
hidden_size = 4096
num_attention_heads = 32
else:
batch, seq, vocab_size = 2, 1024, 1024
intermediate_size = 1024
hidden_size = 512
num_attention_heads = 8
The configuration of the model.
config = LlamaConfig(
hidden_size=hidden_size,
num_hidden_layers=int(script_args.num_hidden_layers),
vocab_size=vocab_size,
intermediate_size=intermediate_size,
max_position_embeddings=2048,
num_attention_heads=num_attention_heads,
)
config._attn_implementation = "eager"
The number of time we run the model to measure the inference.
warmup = 10 if script_args.config == "medium" else 5
N = 50 if script_args.config == "medium" else 25
Let’s create the model with dummy inputs.
print("creates the model")
model = LlamaModel(config)
inputs = (ids_tensor([batch, seq], vocab_size),)
if script_args.with_mask in (1, "1"):
input_mask = torch.tril(torch.ones(batch, seq, dtype=torch.float32))
inputs = (*inputs, input_mask)
processor = "cuda" if has_cuda else "cpu"
print(f"moving model and inputs to processor={processor!r}")
model = model.to(processor)
inputs = tuple(i.to(processor) for i in inputs)
creates the model
moving model and inputs to processor='cuda'
Measure of eager mode¶
times = []
with torch.no_grad():
# warmup
print("warmup eager")
for _ in tqdm(range(warmup)):
# model(input_ids, input_mask)
model(*inputs)
if has_cuda:
torch.cuda.synchronize()
# repeat
print("repeat eager")
begin = time.perf_counter()
for _ in tqdm(range(N)):
model(*inputs)
if has_cuda:
torch.cuda.synchronize()
d = (time.perf_counter() - begin) / N
baseline = d
times.append(dict(optim="eager", processor=processor, avg_time=d, warmup=warmup, N=N))
print("avg time eager", d)
warmup eager
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:03<00:29, 3.26s/it]
30%|███ | 3/10 [00:03<00:06, 1.10it/s]
50%|█████ | 5/10 [00:03<00:02, 2.09it/s]
100%|██████████| 10/10 [00:03<00:00, 2.77it/s]
repeat eager
0%| | 0/50 [00:00<?, ?it/s]
32%|███▏ | 16/50 [00:00<00:00, 159.45it/s]
66%|██████▌ | 33/50 [00:00<00:00, 163.93it/s]
100%|██████████| 50/50 [00:00<00:00, 164.71it/s]
100%|██████████| 50/50 [00:00<00:00, 163.87it/s]
avg time eager 0.0061127098600263705
Measure with the custom backend¶
Three kind of optimization:
default: the onnx model is optimized with less onnx operators
default+onnxruntime: the onnx model is optimized with fused kernels implemented by onnxruntime
default+onnxruntime+experimental: the onnx model is optimized with fused kernels implemented by onnxruntime and also custom kernels, this does not work on CPU.
Some links:
experimental_experiment.xbuilder.OptimizationOptions: that class defines the optimizations to apply after the model is converted to onnx,experimental_experiment.torch_dynamo.onnx_custom_backend(): that function implements the custom backend based on onnxruntime, it converts the model into ONNX, optimizes and runs it, it does not support graph break, it does not work well with dynamic shapes yet.The CUDA kernels are implemented at onnx_extended/ortops/optim/cuda
See Pattern Optimizer to understand how these are applied to modify an onnx model.
The GPU memory is not fully freed before two iterations. Only one scenario should be handled in the same process. Results may be very different with a different chip.
optimization = (
[script_args.optim]
if script_args.optim
else ["default", "default+onnxruntime", "default+onnxruntime+experimental"]
)
if unit_test_going():
# It is too long.
optimization = []
times = []
with torch.no_grad():
for optim in optimization:
print("----------------------")
print(f"optim={optim}")
# This variable is used to retrieve the onnx models created by the backend.
# It can be set to None if it is not needed.
# Graph are usually small as they do not contain weights.
storage = None # {}
options = OptimizationOptions(
constant_folding=True,
patterns=None if optim == "" else optim,
verbose=0,
processor=processor.upper(),
)
# The backend used here overwrite some of the parameters provided by
# function onnx_custom_backend.
custom_custom_backend = lambda *args, optim=optim, options=options, storage=storage, **kwargs: onnx_custom_backend( # noqa: E731, E501
*args,
target_opset=18,
verbose=0,
options=options,
optimize=optim != "",
storage=storage,
dump_prefix=f"dump_onx_llama_{optim.replace('+', '_')}",
**kwargs,
)
# The function setting the backend.
compiled_model = torch.compile(
model, backend=custom_custom_backend, fullgraph=True, dynamic=False
)
# warmup
print("warmup compiled model")
for _ in tqdm(range(warmup)):
compiled_model(*inputs)
if has_cuda:
torch.cuda.synchronize()
# repeat
print("repeat compiled_model")
begin = time.perf_counter()
for _ in tqdm(range(N)):
compiled_model(*inputs)
if has_cuda:
torch.cuda.synchronize()
d = (time.perf_counter() - begin) / N
# let's measure the number of custom ops
n_custom_ops = None
if storage is not None:
onnx_model = storage["instance"][0]["onnx"]
n_custom_ops = len([node for node in onnx_model.graph.node if node.domain != ""])
times.append(
dict(
optim=optim,
processor=processor,
avg_time=d,
warmup=warmup,
N=N,
n_custom_ops=n_custom_ops,
speedup=baseline / d,
)
)
print(f"avg time custom backend with optimization={optim!r}", d)
----------------------
optim=default
warmup compiled model
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:06, 1.39it/s]
100%|██████████| 10/10 [00:00<00:00, 13.27it/s]
repeat compiled_model
0%| | 0/50 [00:00<?, ?it/s]
48%|████▊ | 24/50 [00:00<00:00, 235.27it/s]
96%|█████████▌| 48/50 [00:00<00:00, 230.61it/s]
100%|██████████| 50/50 [00:00<00:00, 232.23it/s]
avg time custom backend with optimization='default' 0.004314023240003735
----------------------
optim=default+onnxruntime
warmup compiled model
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:05, 1.64it/s]
100%|██████████| 10/10 [00:00<00:00, 15.49it/s]
repeat compiled_model
0%| | 0/50 [00:00<?, ?it/s]
58%|█████▊ | 29/50 [00:00<00:00, 286.58it/s]
100%|██████████| 50/50 [00:00<00:00, 295.20it/s]
avg time custom backend with optimization='default+onnxruntime' 0.0034040907999587943
----------------------
optim=default+onnxruntime+experimental
warmup compiled model
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:04, 1.90it/s]
100%|██████████| 10/10 [00:00<00:00, 17.90it/s]
repeat compiled_model
0%| | 0/50 [00:00<?, ?it/s]
62%|██████▏ | 31/50 [00:00<00:00, 302.99it/s]
100%|██████████| 50/50 [00:00<00:00, 305.68it/s]
avg time custom backend with optimization='default+onnxruntime+experimental' 0.0032805673999973806
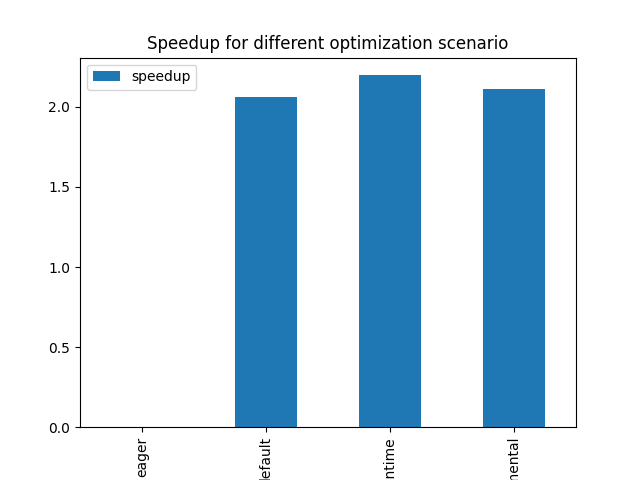
Final results¶
avg_time, lower is better, speedup compare to eager mode, higher is better.
if times:
df = pandas.DataFrame(times)
print(df)
optim processor avg_time warmup N n_custom_ops speedup
0 eager cuda 0.006113 10 50 NaN NaN
1 default cuda 0.004314 10 50 NaN 1.416939
2 default+onnxruntime cuda 0.003404 10 50 NaN 1.795695
3 default+onnxruntime+experimental cuda 0.003281 10 50 NaN 1.863309
Plot
if times:
df.set_index("optim")[["speedup"]].plot.bar(
title="Speedup for different optimization scenario"
)
Total running time of the script: (0 minutes 11.584 seconds)
Related examples


201: Evaluate different ways to export a torch model to ONNX
