Note
Go to the end to download the full example code.
102: Measure LLAMA speed¶
The script is calling many times the script
experimental_experiment.torch_bench.dort_bench.py.
python _doc/examples/plot_llama_bench_102.py --help
For exemple, to check mixed precision on multiple backend:
python _doc/examples/plot_llama_bench_102.py \
--device=cuda --num_hidden_layers=2 --mixed=1
python _doc/examples/plot_llama_bench_102.py --device=cuda --num_hidden_layers=2 \
--mixed=1 --backend=eager,dynger,ortmodule,inductor,ort+,custom --config=large
With 32Gb GPU memory, the script runs with 6 layers.
python _doc/examples/plot_llama_bench_102.py --device=cuda \
--num_hidden_layers=6 --mixed=1 \
--backend=eager,dynger,ortmodule,inductor,trt,ort+,custom --config=large
python _doc/examples/plot_llama_bench_102.py --device=cuda \
--num_hidden_layers=2 --mixed=1 \
--backend=eager,ort+,custom --config=large
Run the following command to run one experiment and get the available options:
python -m experimental_experiment.torch_bench.dort_bench --help
from experimental_experiment.args import get_parsed_args, check_cuda_availability
parsed_args = get_parsed_args(
"plot_llama_bench",
description=__doc__,
warmup=5,
repeat=10,
model=("llama", "model to benchmark"),
backend=(
"eager,inductor,custom",
"backend to test, among eager,dynger,inductor,"
"ort,ort+,custom,plug,ortmodule,backort,",
"eager,dynger,inductor,custom,ortmodule",
),
device=("cuda" if check_cuda_availability() else "cpu", "device to test"),
num_hidden_layers=("1", "hidden layers to test"),
mixed=("0", "boolean value to test (mixed precision or not)"),
dynamic=("0", "boolean value to test dynamic shapes or not"),
script_name=("experimental_experiment.torch_bench.dort_bench", "script to run"),
dump=(0, "dump the models with env ONNXRT_DUMP_PATH"),
check=(0, "just check the script is working, ignores all other parameters"),
config=("medium", "configuration to use, default or medium"),
patterns=(
"none,default,default+onnxruntime,default+onnxruntime+experimental",
"optimization patterns to use",
),
implementation=("eager", "eager or sdpa or both values comma separated value"),
with_mask=(1, "with or without a second input (mask"),
disable_pattern=("none", "pattern or patterns to disable"),
ort_optimize=(
"0,1",
"enable or disable onnxruntime optimization, by default, tries both",
),
order=("none", "optimization order see class OrderAlgorithm, none by default"),
shape_scenario=(
"",
"shapes to use, 2x1024 by default, 'batch' to get "
"shapes with different batch dimensions, 'length' to get "
"different length sizes",
),
verbose=(1, "verbosity"),
expose="backend,device,num_hidden_layers,mixed,scipt_name,repeat,"
"warmup,dump,check,config,patterns,dynamic,disable_pattern,model"
"implementation,with_mask,ort_optimize,verbose,order,shape_scenario",
)
import numpy as np
import pandas
import matplotlib.pyplot as plt
import itertools
import torch
from experimental_experiment.ext_test_case import unit_test_going
from experimental_experiment.bench_run import run_benchmark, get_machine, BenchmarkError
script_name = "experimental_experiment.torch_bench.dort_bench"
machine = {} if unit_test_going() else get_machine(False)
repeat = parsed_args.repeat
warmup = parsed_args.warmup
def make_config(
model,
backend,
device,
num_hidden_layers,
repeat,
mixed,
dynamic,
config,
warmup,
pattern,
disable_pattern,
implementation,
with_mask,
ort_optimize,
order,
shape_scenario,
verbose,
existing=None,
):
if backend not in ("custom", "ort+"):
ort_optimize = None
pattern = None
disable_pattern = None
cf = dict(
model=model,
backend=backend,
device=device,
num_hidden_layers=num_hidden_layers,
repeat=repeat,
mixed=mixed,
dynamic=dynamic,
config=config,
warmup=warmup,
implementation=implementation,
with_mask=with_mask,
ort_optimize=ort_optimize,
order=order,
shape_scenario=shape_scenario,
verbose=verbose,
)
cf = {k: v for k, v in cf.items() if v is not None}
if existing and backend not in ("custom", "ort+"):
for ex in existing:
if not ex:
continue
equal = True
for k in cf:
if cf[k] != ex[k]:
equal = False
break
if equal:
return None
if pattern is None:
opt = {}
elif pattern == "none":
opt = dict(enable_pattern="default", disable_pattern="default")
elif pattern in "default" or "+" in pattern or "-" in pattern:
opt = dict(enable_pattern=pattern)
else:
raise AssertionError(f"unexpected value for pattern={pattern!r}")
cf.update(opt)
if disable_pattern not in ("none", None):
if "disable_pattern" in cf:
cf["disable_pattern"] += f",{disable_pattern}"
else:
cf["disable_pattern"] = disable_pattern
if "enable_pattern" in cf and "+experimental" in cf["enable_pattern"]:
try:
import onnx_extended # noqa: F401
except ImportError:
return None
elif not ort_optimize and backend in ("custom", "ort+"):
return None
assert (
cf["backend"] != "eager" or cf.get("ort_optimize", None) is None
), f"Wrong configuration {cf}"
return cf
if parsed_args.check not in (1, "1") and not unit_test_going():
def _split(s):
if isinstance(s, int):
return [s]
return [int(i) for i in s.split(",")]
verbose = parsed_args.verbose
configs = []
for (
backend,
device,
num_hidden_layers,
mixed,
dynamic,
pattern,
impl,
ort_optimize,
) in itertools.product(
parsed_args.backend.split(","),
parsed_args.device.split(","),
_split(parsed_args.num_hidden_layers),
_split(parsed_args.mixed),
_split(parsed_args.dynamic),
parsed_args.patterns.split(","),
parsed_args.implementation.split(","),
_split(parsed_args.ort_optimize),
):
if mixed == 1 and device == "cpu":
continue
if machine.get("capability", (0, 0)) < (7, 0) and backend == "inductor":
continue
configs.append(
make_config(
model=parsed_args.model,
backend=backend,
device=device,
num_hidden_layers=num_hidden_layers,
repeat=repeat,
mixed=mixed,
dynamic=dynamic,
config=parsed_args.config,
warmup=warmup,
pattern=pattern,
disable_pattern=parsed_args.disable_pattern,
existing=configs,
implementation=impl,
with_mask=parsed_args.with_mask,
ort_optimize=ort_optimize,
order=parsed_args.order,
shape_scenario=parsed_args.shape_scenario,
verbose=verbose,
)
)
else:
verbose = 5
device = "cuda" if torch.cuda.device_count() > 0 else "cpu"
configs = [
dict(
model=parsed_args.model,
backend="custom",
device=device,
num_hidden_layers=1,
repeat=1,
mixed=0,
dynamic=0,
warmup=1,
config="small",
),
]
All configurations to consider.
config 1: {'model': 'llama', 'backend': 'eager', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1}
config 2: {'model': 'llama', 'backend': 'inductor', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1}
config 3: {'model': 'llama', 'backend': 'custom', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'ort_optimize': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1, 'enable_pattern': 'default', 'disable_pattern': 'default'}
config 4: {'model': 'llama', 'backend': 'custom', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'ort_optimize': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1, 'enable_pattern': 'default'}
config 5: {'model': 'llama', 'backend': 'custom', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'ort_optimize': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1, 'enable_pattern': 'default+onnxruntime'}
config 6: {'model': 'llama', 'backend': 'custom', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'ort_optimize': 0, 'order': 'none', 'shape_scenario': '', 'verbose': 1, 'enable_pattern': 'default+onnxruntime+experimental'}
config 7: {'model': 'llama', 'backend': 'custom', 'device': 'cuda', 'num_hidden_layers': 1, 'repeat': 10, 'mixed': 0, 'dynamic': 0, 'config': 'medium', 'warmup': 5, 'implementation': 'eager', 'with_mask': 1, 'ort_optimize': 1, 'order': 'none', 'shape_scenario': '', 'verbose': 1, 'enable_pattern': 'default+onnxruntime+experimental'}
Running configuration.
try:
data = run_benchmark(
parsed_args.script_name,
configs,
verbose=verbose,
stop_if_exception=False,
dump=parsed_args.dump in ("1", 1),
)
data_collected = True
except BenchmarkError as e:
if verbose:
print(e)
data_collected = False
0%| | 0/7 [00:00<?, ?it/s]
[llama]: 0%| | 0/7 [00:00<?, ?it/s]
[llama]: 14%|█▍ | 1/7 [00:15<01:30, 15.03s/it]
[llama]: 14%|█▍ | 1/7 [00:15<01:30, 15.03s/it]
[llama]: 29%|██▊ | 2/7 [01:03<02:53, 34.66s/it]
[llama]: 29%|██▊ | 2/7 [01:03<02:53, 34.66s/it]
[llama]: 43%|████▎ | 3/7 [01:26<01:57, 29.48s/it]
[llama]: 43%|████▎ | 3/7 [01:26<01:57, 29.48s/it]
[llama]: 57%|█████▋ | 4/7 [01:45<01:16, 25.41s/it]
[llama]: 57%|█████▋ | 4/7 [01:45<01:16, 25.41s/it]
[llama]: 71%|███████▏ | 5/7 [02:02<00:44, 22.32s/it]
[llama]: 71%|███████▏ | 5/7 [02:02<00:44, 22.32s/it]
[llama]: 86%|████████▌ | 6/7 [02:20<00:20, 20.73s/it]
[llama]: 86%|████████▌ | 6/7 [02:20<00:20, 20.73s/it]
[llama]: 100%|██████████| 7/7 [02:44<00:00, 21.74s/it]
[llama]: 100%|██████████| 7/7 [02:44<00:00, 23.46s/it]
Let’s process the data.
prefix = (
f"plot_{parsed_args.model}-{parsed_args.with_mask}-"
f"m{parsed_args.mixed}d{parsed_args.dynamic}h{parsed_args.num_hidden_layers}-"
f"{parsed_args.implementation}"
)
if data_collected:
def clean_pattern(s):
s = s.replace("+default-default", "")
return s
def make_legend(row):
row = row.to_dict()
val = [
row["device"],
f"h{row['num_hidden_layers']}",
row["implementation"],
row["backend"],
]
if row["mixed"]:
val.append("mix")
if row["dynamic"]:
val.append("dyn")
if "patterns" in row and row["patterns"] and "nan" not in str(row["patterns"]):
val.append(f"({clean_pattern(row['patterns'])})")
s = "-".join(map(str, val))
assert "nan" not in s, f"Legend {s!r} is wrong, row={row}"
return s
df = pandas.DataFrame(data)
df = df.drop(["OUTPUT", "ERROR"], axis=1)
if "implementation" in df.columns:
df["legend"] = df.apply(make_legend, axis=1)
df["time"] = df["time"].astype(float)
df_eager = df[(df["implementation"] == "eager") & (df["backend"] == "eager")][
"time"
].dropna()
if df_eager.shape[0] > 0:
min_eager = df_eager.min()
df["increase"] = df["time"] / min_eager - 1
# df["ERROR"] = df["ERROR"].apply(lambda s: s.replace("\n", " "))
filename = f"plot_{prefix}_bench_with_cmd.csv"
df.to_csv(filename, index=False)
filename = f"plot_{prefix}_bench_with_cmd.xlsx"
df.to_excel(filename, index=False)
df = df.drop(["CMD"], axis=1)
filename = f"plot_{prefix}_bench.csv"
df.to_csv(filename, index=False)
df = pandas.read_csv(filename) # to cast type
print(df)
# summary
cs = [
c
for c in ["backend", "patterns", "warmup_time", "time", "increase"]
if c in df.columns
]
dfs = df[cs]
filename = f"plot_{prefix}_summary.xlsx"
dfs.to_excel(filename, index=False)
filename = f"plot_{prefix}_summary.csv"
dfs.to_csv(filename, index=False)
print(dfs)
llama config mixed dynamic optimize order ... disable_pattern config_ort_optimize config_enable_pattern config_disable_pattern legend increase
0 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN NaN NaN NaN cuda-h1-eager-eager 0.000000
1 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN NaN NaN NaN cuda-h1-eager-inductor 7.162037
2 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... default 1.0 default default cuda-h1-eager-custom-(+oo) 8.802154
3 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default NaN cuda-h1-eager-custom-(+default-+oo) 8.641940
4 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default+onnxruntime NaN cuda-h1-eager-custom-(+default+onnxruntime-+oo) 8.068504
5 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 0.0 default+onnxruntime+experimental NaN cuda-h1-eager-custom-(+default+onnxruntime+exp... 7.679248
6 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default+onnxruntime+experimental NaN cuda-h1-eager-custom-(+default+onnxruntime+exp... 7.774919
[7 rows x 58 columns]
backend patterns warmup_time time increase
0 eager NaN 0.786398 0.028021 0.000000
1 inductor NaN 27.450114 0.228707 7.162037
2 custom +default-default+oo 5.152271 0.274664 8.802154
3 custom +default-+oo 4.265339 0.270175 8.641940
4 custom +default+onnxruntime-+oo 4.573150 0.254106 8.068504
5 custom +default+onnxruntime+experimental- 4.607407 0.243199 7.679248
6 custom +default+onnxruntime+experimental-+oo 5.017455 0.245880 7.774919
First lines.
print(df.head(2).T)
0 1
llama (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False
config medium medium
mixed 0 0
dynamic 0 0
optimize True True
order none none
ort_optimize True True
backend eager inductor
repeat 10 10
warmup 5 5
with_mask 1 1
implementation eager eager
torch 2.8.0.dev20250519+cu126 2.8.0.dev20250519+cu126
transformers 4.52.0.dev0 4.52.0.dev0
memory_peak 1282.988281 1167.246094
memory_mean 1173.551091 1097.798816
memory_n 101 2678
memory_begin 928.476562 970.332031
memory_end 1282.988281 1167.246094
memory_gpu0_peak 1966.234375 1916.234375
memory_gpu0_mean 1835.264078 1819.672762
memory_gpu0_n 101 2678
memory_gpu0_begin 1684.234375 1672.234375
memory_gpu0_end 1966.234375 1916.234375
warmup_time 0.786398 27.450114
time 0.028021 0.228707
model llama llama
device cuda cuda
num_hidden_layers 1 1
shape_scenario NaN NaN
verbose 1 1
DATE 2025-05-20 2025-05-20
ITER 0 1
TIME_ITER 15.030627 48.403791
ERR_stdout model=llamamodel config={'input_dims': [(2 102... model=llamamodel config={'input_dims': [(2 102...
config_model llama llama
config_backend eager inductor
config_device cuda cuda
config_num_hidden_layers 1 1
config_repeat 10 10
config_mixed 0 0
config_dynamic 0 0
config_config medium medium
config_warmup 5 5
config_implementation eager eager
config_with_mask 1 1
config_order none none
config_shape_scenario NaN NaN
config_verbose 1 1
ERR_std NaN homexaduprevvthis312libpython3.12site-packages...
patterns NaN NaN
enable_pattern NaN NaN
disable_pattern NaN NaN
config_ort_optimize NaN NaN
config_enable_pattern NaN NaN
config_disable_pattern NaN NaN
legend cuda-h1-eager-eager cuda-h1-eager-inductor
increase 0.0 7.162037
More simple
Simplified data
print(df.sort_values("legend") if "legend" in df.columns else df)
llama config mixed dynamic optimize order ... disable_pattern config_ort_optimize config_enable_pattern config_disable_pattern legend increase
5 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 0.0 default+onnxruntime+experimental NaN cuda-h1-eager-custom-(+default+onnxruntime+exp... 7.679248
6 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default+onnxruntime+experimental NaN cuda-h1-eager-custom-(+default+onnxruntime+exp... 7.774919
4 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default+onnxruntime NaN cuda-h1-eager-custom-(+default+onnxruntime-+oo) 8.068504
3 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN 1.0 default NaN cuda-h1-eager-custom-(+default-+oo) 8.641940
2 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... default 1.0 default default cuda-h1-eager-custom-(+oo) 8.802154
0 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN NaN NaN NaN cuda-h1-eager-eager 0.000000
1 (2, 1024)-1024-1-1024-1024-1024-2-eager-1-False medium 0 0 True none ... NaN NaN NaN NaN cuda-h1-eager-inductor 7.162037
[7 rows x 58 columns]
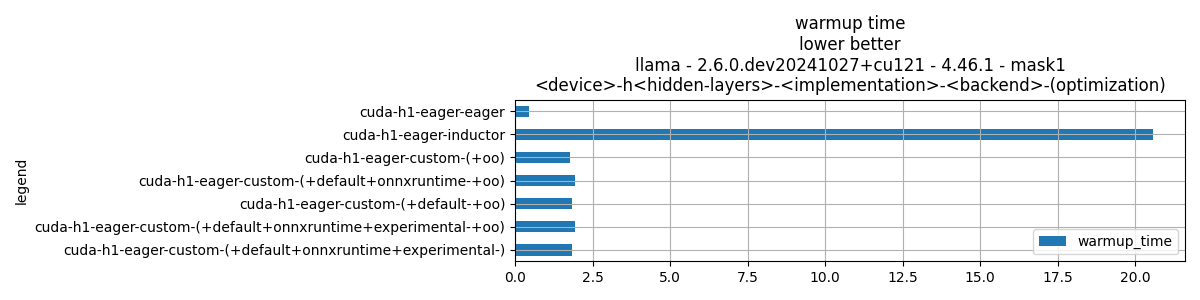
Plot warmup time.
torch_version = list(set(df["torch"].dropna())) if "torch" in df.columns else (0, 0)
transformers_version = (
list(set(df["transformers"].dropna())) if "transformers" in df.columns else (0, 0)
)
ver = f"{torch_version[0]} - {transformers_version[0]}"
model = parsed_args.model
modeldf = list(set(df[model].dropna()))[0] if model in df.columns else "?" # noqa: RUF015
title_prefix = (
f"lower better\n"
f"{parsed_args.model} - {ver} - mask{parsed_args.with_mask}"
f"\n<device>-h<hidden-layers>-<implementation>-<backend>-(optimization)"
)
if data_collected and "legend" in df.columns:
fig, ax = plt.subplots(1, 1, figsize=(12, df.shape[0] // 3 + 1))
df = df.sort_values("time").set_index("legend")
df[["warmup_time"]].plot.barh(ax=ax, title=f"warmup time\n{title_prefix}")
ax.grid(True)
fig.tight_layout()
fig.savefig(f"plot_{prefix}_bench_warmup_time.png")
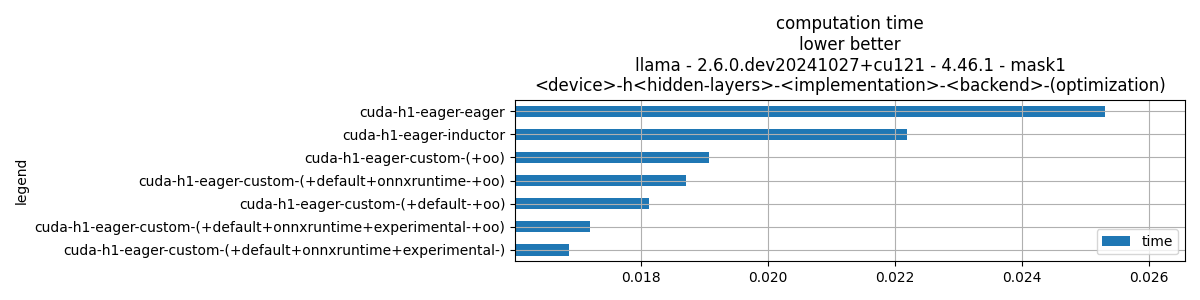
Plot time.
if data_collected and "time" in df.columns:
fig, ax = plt.subplots(1, 1, figsize=(12, df.shape[0] // 3 + 1))
df[["time"]].plot.barh(ax=ax, title=f"computation time\n{title_prefix}")
mi, ma = df["time"].min(), df["time"].max()
mi = mi - (ma - mi) / 10
if not np.isnan(mi):
ax.set_xlim(left=mi)
ax.grid(True)
fig.tight_layout()
fig.savefig(f"plot_{prefix}_bench_time.png")
Plot increase.
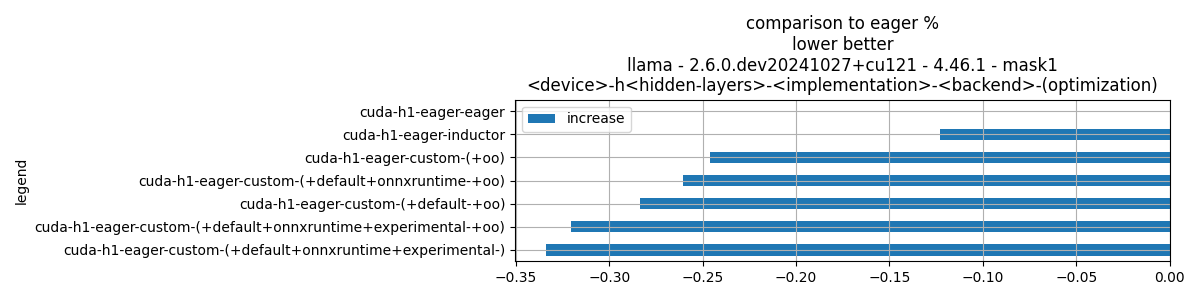
if data_collected and "increase" in df.columns:
fig, ax = plt.subplots(1, 1, figsize=(12, df.shape[0] // 3 + 1))
df[["increase"]].plot.barh(ax=ax, title=f"comparison to eager %\n{title_prefix}")
ax.grid(True)
fig.tight_layout()
fig.savefig(f"plot_{prefix}_bench_relative.png")
Total running time of the script: (2 minutes 44.904 seconds)
Related examples
201: Evaluate different ways to export a torch model to ONNX
201: Evaluate different ways to export a torch model to ONNX