Note
Go to the end to download the full example code.
to_onnx and submodules from LLMs¶
Big models are hard to read once converted into onnx. Let’s see how to improve their readibility. The code is inspired from LLM from scratch with Pytorch.
A simple LLM¶
All comments were removed from the code to make it less verbose. A few fixes were applied to the original code.
import onnx
from onnx.inliner import inline_local_functions
from onnx_array_api.plotting.graphviz_helper import plot_dot
from onnx_array_api.reference import compare_onnx_execution
from onnx_diagnostic.helpers import max_diff
from onnx_diagnostic.helpers.onnx_helper import pretty_onnx
import torch
from onnxruntime import InferenceSession
from experimental_experiment.reference import ExtendedReferenceEvaluator
from experimental_experiment.torch_interpreter import to_onnx
from experimental_experiment.xbuilder import OptimizationOptions
class Embedding(torch.nn.Module):
def __init__(self, vocab_size: int, embedding_dim: int):
super().__init__()
self.embedding = torch.nn.Embedding(vocab_size, embedding_dim)
self.pe = torch.nn.Embedding(vocab_size, embedding_dim)
def forward(self, x):
word_emb = self.embedding(x)
word_pe = self.pe(x)
return word_emb + word_pe
class AttentionBlock(torch.nn.Module):
def __init__(self, embedding_dim: int, context_size: int):
super().__init__()
self.query = torch.nn.Linear(embedding_dim, embedding_dim, bias=False)
self.key = torch.nn.Linear(embedding_dim, embedding_dim, bias=False)
self.value = torch.nn.Linear(embedding_dim, embedding_dim, bias=False)
ones = torch.ones(size=[context_size, context_size], dtype=torch.float)
self.register_buffer(name="mask", tensor=torch.tril(input=ones))
def forward(self, x):
_B, T, C = x.size()
query = self.query(x)
key = self.key(x)
value = self.value(x)
qk = query @ key.transpose(-2, -1) * C**-0.5
attention = qk.masked_fill(self.mask[:T, :T] == 0, float("-inf"))
attention = torch.nn.functional.softmax(input=attention, dim=-1)
out = attention @ value
return out
class MultiAttentionBlock(torch.nn.Module):
def __init__(self, embedding_dim: int, num_heads: int, context_size: int):
super().__init__()
self.attention = torch.nn.ModuleList(
modules=[AttentionBlock(embedding_dim, context_size) for _ in range(num_heads)]
)
self.linear = torch.nn.Linear(
in_features=embedding_dim * num_heads, out_features=embedding_dim
)
def forward(self, x):
out = torch.cat(tensors=[attention(x) for attention in self.attention], dim=-1)
x = self.linear(out)
return x
class FeedForward(torch.nn.Module):
def __init__(self, embedding_dim: int, ff_dim: int):
super().__init__()
self.linear_1 = torch.nn.Linear(embedding_dim, ff_dim)
self.relu = torch.nn.ReLU()
self.linear_2 = torch.nn.Linear(ff_dim, embedding_dim)
def forward(self, x):
x = self.linear_1(x)
x = self.relu(x)
x = self.linear_2(x)
return x
class DecoderLayer(torch.nn.Module):
def __init__(self, embedding_dim: int, num_heads: int, context_size: int, ff_dim: int):
super().__init__()
self.attention = MultiAttentionBlock(embedding_dim, num_heads, context_size)
self.feed_forward = FeedForward(embedding_dim, ff_dim)
self.norm_1 = torch.nn.LayerNorm(normalized_shape=embedding_dim)
self.norm_2 = torch.nn.LayerNorm(normalized_shape=embedding_dim)
def forward(self, x):
x_norm = self.norm_1(x)
attention = self.attention(x_norm)
attention = attention + x
attention_norm = self.norm_2(attention)
ff = self.feed_forward(attention_norm)
ff = ff + attention
return ff
class LLM(torch.nn.Module):
def __init__(
self,
vocab_size: int = 1024,
embedding_dim: int = 16,
num_heads: int = 2,
context_size: int = 256,
ff_dim: int = 128,
):
super().__init__()
self.embedding = Embedding(vocab_size, embedding_dim)
self.decoder = DecoderLayer(embedding_dim, num_heads, context_size, ff_dim)
def forward(self, input_ids):
x = self.embedding(input_ids)
y = self.decoder(x)
return y
llm = LLM()
dim = (1, 30)
input_ids = torch.randint(0, 1024, dim).to(torch.int64)
y = llm(input_ids)
print(f"output: shape={y.shape}, min={y.min()}, max={y.max()}")
output: shape=torch.Size([1, 30, 16]), min=-3.8575398921966553, max=3.8025996685028076
First conversion to ONNX¶
The conversion relies on torch.export.export().
which gives:
ep = torch.export.export(llm, (input_ids,))
print(ep.graph)
graph():
%p_embedding_embedding_weight : [num_users=1] = placeholder[target=p_embedding_embedding_weight]
%p_embedding_pe_weight : [num_users=1] = placeholder[target=p_embedding_pe_weight]
%p_decoder_attention_attention_0_query_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_0_query_weight]
%p_decoder_attention_attention_0_key_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_0_key_weight]
%p_decoder_attention_attention_0_value_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_0_value_weight]
%p_decoder_attention_attention_1_query_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_1_query_weight]
%p_decoder_attention_attention_1_key_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_1_key_weight]
%p_decoder_attention_attention_1_value_weight : [num_users=1] = placeholder[target=p_decoder_attention_attention_1_value_weight]
%p_decoder_attention_linear_weight : [num_users=1] = placeholder[target=p_decoder_attention_linear_weight]
%p_decoder_attention_linear_bias : [num_users=1] = placeholder[target=p_decoder_attention_linear_bias]
%p_decoder_feed_forward_linear_1_weight : [num_users=1] = placeholder[target=p_decoder_feed_forward_linear_1_weight]
%p_decoder_feed_forward_linear_1_bias : [num_users=1] = placeholder[target=p_decoder_feed_forward_linear_1_bias]
%p_decoder_feed_forward_linear_2_weight : [num_users=1] = placeholder[target=p_decoder_feed_forward_linear_2_weight]
%p_decoder_feed_forward_linear_2_bias : [num_users=1] = placeholder[target=p_decoder_feed_forward_linear_2_bias]
%p_decoder_norm_1_weight : [num_users=1] = placeholder[target=p_decoder_norm_1_weight]
%p_decoder_norm_1_bias : [num_users=1] = placeholder[target=p_decoder_norm_1_bias]
%p_decoder_norm_2_weight : [num_users=1] = placeholder[target=p_decoder_norm_2_weight]
%p_decoder_norm_2_bias : [num_users=1] = placeholder[target=p_decoder_norm_2_bias]
%b_decoder_attention_attention_0_mask : [num_users=1] = placeholder[target=b_decoder_attention_attention_0_mask]
%b_decoder_attention_attention_1_mask : [num_users=1] = placeholder[target=b_decoder_attention_attention_1_mask]
%input_ids : [num_users=2] = placeholder[target=input_ids]
%embedding : [num_users=1] = call_function[target=torch.ops.aten.embedding.default](args = (%p_embedding_embedding_weight, %input_ids), kwargs = {})
%embedding_1 : [num_users=1] = call_function[target=torch.ops.aten.embedding.default](args = (%p_embedding_pe_weight, %input_ids), kwargs = {})
%add : [num_users=2] = call_function[target=torch.ops.aten.add.Tensor](args = (%embedding, %embedding_1), kwargs = {})
%layer_norm : [num_users=6] = call_function[target=torch.ops.aten.layer_norm.default](args = (%add, [16], %p_decoder_norm_1_weight, %p_decoder_norm_1_bias, 1e-05, False), kwargs = {})
%linear : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_0_query_weight), kwargs = {})
%linear_1 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_0_key_weight), kwargs = {})
%linear_2 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_0_value_weight), kwargs = {})
%transpose : [num_users=1] = call_function[target=torch.ops.aten.transpose.int](args = (%linear_1, -2, -1), kwargs = {})
%matmul : [num_users=1] = call_function[target=torch.ops.aten.matmul.default](args = (%linear, %transpose), kwargs = {})
%mul : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%matmul, 0.25), kwargs = {})
%slice_1 : [num_users=1] = call_function[target=torch.ops.aten.slice.Tensor](args = (%b_decoder_attention_attention_0_mask, 0, 0, 30), kwargs = {})
%slice_2 : [num_users=1] = call_function[target=torch.ops.aten.slice.Tensor](args = (%slice_1, 1, 0, 30), kwargs = {})
%eq : [num_users=1] = call_function[target=torch.ops.aten.eq.Scalar](args = (%slice_2, 0), kwargs = {})
%masked_fill : [num_users=1] = call_function[target=torch.ops.aten.masked_fill.Scalar](args = (%mul, %eq, -inf), kwargs = {})
%softmax : [num_users=1] = call_function[target=torch.ops.aten.softmax.int](args = (%masked_fill, -1), kwargs = {})
%matmul_1 : [num_users=1] = call_function[target=torch.ops.aten.matmul.default](args = (%softmax, %linear_2), kwargs = {})
%linear_3 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_1_query_weight), kwargs = {})
%linear_4 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_1_key_weight), kwargs = {})
%linear_5 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm, %p_decoder_attention_attention_1_value_weight), kwargs = {})
%transpose_1 : [num_users=1] = call_function[target=torch.ops.aten.transpose.int](args = (%linear_4, -2, -1), kwargs = {})
%matmul_2 : [num_users=1] = call_function[target=torch.ops.aten.matmul.default](args = (%linear_3, %transpose_1), kwargs = {})
%mul_1 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%matmul_2, 0.25), kwargs = {})
%slice_3 : [num_users=1] = call_function[target=torch.ops.aten.slice.Tensor](args = (%b_decoder_attention_attention_1_mask, 0, 0, 30), kwargs = {})
%slice_4 : [num_users=1] = call_function[target=torch.ops.aten.slice.Tensor](args = (%slice_3, 1, 0, 30), kwargs = {})
%eq_1 : [num_users=1] = call_function[target=torch.ops.aten.eq.Scalar](args = (%slice_4, 0), kwargs = {})
%masked_fill_1 : [num_users=1] = call_function[target=torch.ops.aten.masked_fill.Scalar](args = (%mul_1, %eq_1, -inf), kwargs = {})
%softmax_1 : [num_users=1] = call_function[target=torch.ops.aten.softmax.int](args = (%masked_fill_1, -1), kwargs = {})
%matmul_3 : [num_users=1] = call_function[target=torch.ops.aten.matmul.default](args = (%softmax_1, %linear_5), kwargs = {})
%cat : [num_users=1] = call_function[target=torch.ops.aten.cat.default](args = ([%matmul_1, %matmul_3], -1), kwargs = {})
%linear_6 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%cat, %p_decoder_attention_linear_weight, %p_decoder_attention_linear_bias), kwargs = {})
%add_1 : [num_users=2] = call_function[target=torch.ops.aten.add.Tensor](args = (%linear_6, %add), kwargs = {})
%layer_norm_1 : [num_users=1] = call_function[target=torch.ops.aten.layer_norm.default](args = (%add_1, [16], %p_decoder_norm_2_weight, %p_decoder_norm_2_bias, 1e-05, False), kwargs = {})
%linear_7 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%layer_norm_1, %p_decoder_feed_forward_linear_1_weight, %p_decoder_feed_forward_linear_1_bias), kwargs = {})
%relu : [num_users=1] = call_function[target=torch.ops.aten.relu.default](args = (%linear_7,), kwargs = {})
%linear_8 : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%relu, %p_decoder_feed_forward_linear_2_weight, %p_decoder_feed_forward_linear_2_bias), kwargs = {})
%add_2 : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%linear_8, %add_1), kwargs = {})
return (add_2,)
Then function to_onnx
converts it into ONNX.
onx = to_onnx(llm, (input_ids,))
print(pretty_onnx(onx))
opset: domain='' version=18
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='b_decoder_attention_attention_0_mask' type=float32 shape=(256, 256)-- DynamoInterpret.placeholder.0
init: name='b_decoder_attention_attention_1_mask' type=float32 shape=(256, 256)-- DynamoInterpret.placeholder.0
init: name='init7_s1_1' type=int64 shape=(1,) -- array([1]) -- Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init7_s1_0' type=int64 shape=(1,) -- array([0]) -- Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init7_s1_30' type=int64 shape=(1,) -- array([30]) -- Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init1_s1_3' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- Opset.make_node.1/Small##Opset.make_node.1/Small
init: name='p_decoder_attention_attention_0_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_query_weight)##p_decoder_attention_attention_0_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.query.weight)
init: name='p_decoder_attention_attention_0_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_key_weight)##p_decoder_attention_attention_0_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.key.weight)
init: name='p_decoder_attention_attention_0_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_value_weight)##p_decoder_attention_attention_0_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.value.weight)
init: name='init1_s_::RSh1' type=float32 shape=(1,) -- array([0.25], dtype=float32)-- GraphBuilder.constant_folding.from/fold(init1_s_,init7_s1_1)##init1_s_/shape_type_compute._cast_inputs.1(mul_Tensor)##shape_type_compute._cast_inputs.1(mul_Tensor)##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init1_s_2::RSh1' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilder.constant_folding.from/fold(init1_s_2,init7_s1_1)##init1_s_2/shape_type_compute._cast_inputs.0##shape_type_compute._cast_inputs.0##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='p_decoder_attention_attention_1_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_query_weight)##p_decoder_attention_attention_1_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.query.weight)
init: name='p_decoder_attention_attention_1_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_key_weight)##p_decoder_attention_attention_1_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.key.weight)
init: name='p_decoder_attention_attention_1_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_value_weight)##p_decoder_attention_attention_1_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.value.weight)
init: name='p_decoder_attention_linear_weight::T10' type=float32 shape=(32, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_linear_weight)##p_decoder_attention_linear_weight/DynamoInterpret.placeholder.1/P(decoder.attention.linear.weight)
init: name='p_decoder_feed_forward_linear_1_weight::T10' type=float32 shape=(16, 128)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_1_weight)##p_decoder_feed_forward_linear_1_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.weight)
init: name='p_decoder_feed_forward_linear_2_weight::T10' type=float32 shape=(128, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_2_weight)##p_decoder_feed_forward_linear_2_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.weight)
init: name='init1_s16_' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.scale##LayerNormalizationPattern.apply.scale
init: name='init1_s16_2' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.bias##LayerNormalizationPattern.apply.bias
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.pe.weight)
init: name='decoder.attention.linear.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(decoder.attention.linear.bias)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.bias)
init: name='decoder.feed_forward.linear_2.bias' type=float32 shape=(16,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.bias)
Concat(init7_s1_0, init7_s1_1, axis=0) -> SliceSlicePattern_init7_s1_1_axis
Concat(init7_s1_30, init7_s1_30, axis=0) -> SliceSlicePattern_init7_s1_30_end
Concat(init7_s1_0, init7_s1_0, axis=0) -> SliceSlicePattern_init7_s1_0_start
Slice(b_decoder_attention_attention_0_mask, SliceSlicePattern_init7_s1_0_start, SliceSlicePattern_init7_s1_30_end, SliceSlicePattern_init7_s1_1_axis) -> slice_2
Equal(slice_2, init1_s_2::RSh1) -> eq
Gather(embedding.embedding.weight, input_ids) -> embedding
Gather(embedding.pe.weight, input_ids) -> embedding_1
Add(embedding, embedding_1) -> add
LayerNormalization(add, init1_s16_, init1_s16_2, axis=-1, epsilon=0.00, stash_type=1) -> _onx_div_sub_add
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_query_weight::T10) -> linear
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_key_weight::T10) -> linear_1
Transpose(linear_1, perm=[0,2,1]) -> transpose
MatMul(linear, transpose) -> matmul
Mul(matmul, init1_s_::RSh1) -> _onx_mul_matmul
Where(eq, init1_s1_3, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_value_weight::T10) -> linear_2
MatMul(softmax, linear_2) -> matmul_1
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_query_weight::T10) -> linear_3
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_key_weight::T10) -> linear_4
Transpose(linear_4, perm=[0,2,1]) -> transpose_1
MatMul(linear_3, transpose_1) -> matmul_2
Mul(matmul_2, init1_s_::RSh1) -> _onx_mul_matmul_2
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_value_weight::T10) -> linear_5
Slice(b_decoder_attention_attention_1_mask, SliceSlicePattern_init7_s1_0_start, SliceSlicePattern_init7_s1_30_end, SliceSlicePattern_init7_s1_1_axis) -> slice_4
Equal(slice_4, init1_s_2::RSh1) -> eq_1
Where(eq_1, init1_s1_3, _onx_mul_matmul_2) -> masked_fill_1
Softmax(masked_fill_1, axis=-1) -> softmax_1
MatMul(softmax_1, linear_5) -> matmul_3
Concat(matmul_1, matmul_3, axis=-1) -> cat
MatMul(cat, p_decoder_attention_linear_weight::T10) -> _onx_matmul_cat
Add(_onx_matmul_cat, decoder.attention.linear.bias) -> linear_6
Add(linear_6, add) -> add_1
LayerNormalization(add_1, init1_s16_, init1_s16_2, axis=-1, epsilon=0.00, stash_type=1) -> _onx_div_sub_add_1
MatMul(_onx_div_sub_add_1, p_decoder_feed_forward_linear_1_weight::T10) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_7
Relu(linear_7) -> relu
MatMul(relu, p_decoder_feed_forward_linear_2_weight::T10) -> _onx_matmul_relu
Add(_onx_matmul_relu, decoder.feed_forward.linear_2.bias) -> linear_8
Add(linear_8, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
Let’s check there is no discrepancy.
output: shape=(1, 30, 16), min=-3.857539653778076, max=3.8025996685028076
max discrepancy=2.384185791015625e-07
Let’s save the ONNX model.
onnx.save(onx, "plot_exporter_recipes_c_modules.inlined.onnx")
ONNX with submodules¶
Let’s produce an ONNX model with submodules.
Function to_onnx
is calling the function torch.export.unflatten.unflatten()
under the hood. The fx graph looks like the following.
ep = torch.export.export(llm, (input_ids,))
unflatten_ep = torch.export.unflatten(ep)
print(unflatten_ep.graph)
/usr/lib/python3.12/copyreg.py:99: FutureWarning: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
return cls.__new__(cls, *args)
graph():
%input_ids : [num_users=1] = placeholder[target=input_ids]
%embedding : [num_users=1] = call_module[target=embedding](args = (%input_ids,), kwargs = {})
%decoder : [num_users=1] = call_module[target=decoder](args = (%embedding,), kwargs = {})
return (decoder,)
The exported graph looks simpler and shows something like:
%decoder : [num_users=1] = call_module[target=decoder](args = (%embedding,), kwargs = {})
It preserves the hierarchy but it does not necessarily preserves the signatures
of the initial modules. That’s was not one of our goals.
The tricky part is module called (embedding) is not an instance Embedding
but an instance of InterpreterModule
and contains the fx nodes contributing to the submodule and coming from the
previous graph.
Now the ONNX graph.
onx_module = to_onnx(llm, (input_ids,), export_modules_as_functions=True)
print(pretty_onnx(onx_module))
/usr/lib/python3.12/copyreg.py:99: FutureWarning: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
return cls.__new__(cls, *args)
opset: domain='' version=18
opset: domain='aten_local_function' version=1
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.pe.weight)
init: name='mask' type=float32 shape=(256, 256) -- GraphBuilder.make_local_function/from(mask)
init: name='weight::T10' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T10)
init: name='weight::T102' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T102)
init: name='weight::T103' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T103)
init: name='mask2' type=float32 shape=(256, 256) -- GraphBuilder.make_local_function/from(mask2)
init: name='weight::T104' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T104)
init: name='weight::T1022' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1022)
init: name='weight::T1032' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1032)
init: name='weight::T105' type=float32 shape=(32, 16) -- GraphBuilder.make_local_function/from(weight::T105)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- GraphBuilder.make_local_function/from(decoder.feed_forward.linear_1.bias)
init: name='weight::T106' type=float32 shape=(16, 128) -- GraphBuilder.make_local_function/from(weight::T106)
init: name='weight::T1023' type=float32 shape=(128, 16) -- GraphBuilder.make_local_function/from(weight::T1023)
init: name='init1_s16__cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='init1_s16_2_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='init1_s1__cst2init' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='init1_s_::RSh1_cst2init' type=float32 shape=(1,) -- array([0.25], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='init1_s_2::RSh1_cst2init' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='SliceSlicePattern_init7_s1_0_start_cst2init' type=int64 shape=(2,) -- array([0, 0])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='SliceSlicePattern_init7_s1_30_end_cst2init' type=int64 shape=(2,) -- array([30, 30])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='SliceSlicePattern_init7_s1_1_axis_cst2init' type=int64 shape=(2,) -- array([0, 1])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='bias_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='bias2_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
Gather(embedding.embedding.weight, input_ids) -> embedding2
Gather(embedding.pe.weight, input_ids) -> pe
Add(embedding2, pe) -> embedding
LayerNormalization(embedding, init1_s16__cst2init, init1_s16_2_cst2init, axis=-1, epsilon=0.00, stash_type=1) -> norm_1
MatMul(norm_1, weight::T10) -> query
MatMul(norm_1, weight::T102) -> key
Transpose(key, perm=[0,2,1]) -> transpose
MatMul(query, transpose) -> matmul
Mul(matmul, init1_s_::RSh1_cst2init) -> _onx_mul_matmul
MatMul(norm_1, weight::T103) -> value
Slice(mask, SliceSlicePattern_init7_s1_0_start_cst2init, SliceSlicePattern_init7_s1_30_end_cst2init, SliceSlicePattern_init7_s1_1_axis_cst2init) -> slice_2
Equal(slice_2, init1_s_2::RSh1_cst2init) -> eq
Where(eq, init1_s1__cst2init, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(softmax, value) -> attention_0
MatMul(norm_1, weight::T104) -> query2
MatMul(norm_1, weight::T1022) -> key2
Transpose(key2, perm=[0,2,1]) -> transpose2
MatMul(query2, transpose2) -> matmul2
Mul(matmul2, init1_s_::RSh1_cst2init) -> _onx_mul_matmul2
MatMul(norm_1, weight::T1032) -> value2
Slice(mask2, SliceSlicePattern_init7_s1_0_start_cst2init, SliceSlicePattern_init7_s1_30_end_cst2init, SliceSlicePattern_init7_s1_1_axis_cst2init) -> slice_22
Equal(slice_22, init1_s_2::RSh1_cst2init) -> eq2
Where(eq2, init1_s1__cst2init, _onx_mul_matmul2) -> masked_fill2
Softmax(masked_fill2, axis=-1) -> softmax2
MatMul(softmax2, value2) -> attention_1
Concat(attention_0, attention_1, axis=-1) -> cat
MatMul(cat, weight::T105) -> _onx_matmul_cat
Add(_onx_matmul_cat, bias_cst2init) -> attention
Add(attention, embedding) -> add_1
LayerNormalization(add_1, init1_s16__cst2init, init1_s16_2_cst2init, axis=-1, epsilon=0.00, stash_type=1) -> norm_2
MatMul(norm_2, weight::T106) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_1
Relu(linear_1) -> relu
MatMul(relu, weight::T1023) -> _onx_matmul_relu
Add(_onx_matmul_relu, bias2_cst2init) -> feed_forward
Add(feed_forward, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
We check again there is no new discrepancies.
output: shape=(1, 30, 16), min=-3.857539653778076, max=3.8025996685028076
max discrepancy=2.384185791015625e-07
Let’s save the ONNX model.
onnx.save(onx_module, "plot_exporter_recipes_c_modules.module.onnx")
And visually.

Inlining¶
The ONNX graph can still be inline after this.
opset: domain='' version=18
opset: domain='aten_local_function' version=1
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.pe.weight)
init: name='mask' type=float32 shape=(256, 256) -- GraphBuilder.make_local_function/from(mask)
init: name='weight::T10' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T10)
init: name='weight::T102' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T102)
init: name='weight::T103' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T103)
init: name='mask2' type=float32 shape=(256, 256) -- GraphBuilder.make_local_function/from(mask2)
init: name='weight::T104' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T104)
init: name='weight::T1022' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1022)
init: name='weight::T1032' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1032)
init: name='weight::T105' type=float32 shape=(32, 16) -- GraphBuilder.make_local_function/from(weight::T105)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- GraphBuilder.make_local_function/from(decoder.feed_forward.linear_1.bias)
init: name='weight::T106' type=float32 shape=(16, 128) -- GraphBuilder.make_local_function/from(weight::T106)
init: name='weight::T1023' type=float32 shape=(128, 16) -- GraphBuilder.make_local_function/from(weight::T1023)
init: name='init1_s16__cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='init1_s16_2_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='init1_s1__cst2init' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='init1_s_::RSh1_cst2init' type=float32 shape=(1,) -- array([0.25], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='init1_s_2::RSh1_cst2init' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilderPatternOptimization.make_initializer.1/Small
init: name='SliceSlicePattern_init7_s1_0_start_cst2init' type=int64 shape=(2,) -- array([0, 0])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='SliceSlicePattern_init7_s1_30_end_cst2init' type=int64 shape=(2,) -- array([30, 30])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='SliceSlicePattern_init7_s1_1_axis_cst2init' type=int64 shape=(2,) -- array([0, 1])-- GraphBuilderPatternOptimization.make_initializer.1/Shape
init: name='bias_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
init: name='bias2_cst2init' type=float32 shape=(16,) -- GraphBuilderPatternOptimization.make_initializer.0
Gather(embedding.embedding.weight, input_ids) -> embedding2
Gather(embedding.pe.weight, input_ids) -> pe
Add(embedding2, pe) -> embedding
LayerNormalization(embedding, init1_s16__cst2init, init1_s16_2_cst2init, axis=-1, epsilon=0.00, stash_type=1) -> norm_1
MatMul(norm_1, weight::T10) -> query
MatMul(norm_1, weight::T102) -> key
Transpose(key, perm=[0,2,1]) -> transpose
MatMul(query, transpose) -> matmul
Mul(matmul, init1_s_::RSh1_cst2init) -> _onx_mul_matmul
MatMul(norm_1, weight::T103) -> value
Slice(mask, SliceSlicePattern_init7_s1_0_start_cst2init, SliceSlicePattern_init7_s1_30_end_cst2init, SliceSlicePattern_init7_s1_1_axis_cst2init) -> slice_2
Equal(slice_2, init1_s_2::RSh1_cst2init) -> eq
Where(eq, init1_s1__cst2init, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(softmax, value) -> attention_0
MatMul(norm_1, weight::T104) -> query2
MatMul(norm_1, weight::T1022) -> key2
Transpose(key2, perm=[0,2,1]) -> transpose2
MatMul(query2, transpose2) -> matmul2
Mul(matmul2, init1_s_::RSh1_cst2init) -> _onx_mul_matmul2
MatMul(norm_1, weight::T1032) -> value2
Slice(mask2, SliceSlicePattern_init7_s1_0_start_cst2init, SliceSlicePattern_init7_s1_30_end_cst2init, SliceSlicePattern_init7_s1_1_axis_cst2init) -> slice_22
Equal(slice_22, init1_s_2::RSh1_cst2init) -> eq2
Where(eq2, init1_s1__cst2init, _onx_mul_matmul2) -> masked_fill2
Softmax(masked_fill2, axis=-1) -> softmax2
MatMul(softmax2, value2) -> attention_1
Concat(attention_0, attention_1, axis=-1) -> cat
MatMul(cat, weight::T105) -> _onx_matmul_cat
Add(_onx_matmul_cat, bias_cst2init) -> attention
Add(attention, embedding) -> add_1
LayerNormalization(add_1, init1_s16__cst2init, init1_s16_2_cst2init, axis=-1, epsilon=0.00, stash_type=1) -> norm_2
MatMul(norm_2, weight::T106) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_1
Relu(linear_1) -> relu
MatMul(relu, weight::T1023) -> _onx_matmul_relu
Add(_onx_matmul_relu, bias2_cst2init) -> feed_forward
Add(feed_forward, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
Optimizations¶
The ONNX graph produced by the exporter without any optimization is very verbose and less efficient. That’s why some optimizations are made to the model by default. It is also possible to introduce kernels implemented in onnxruntime. Let’s how it goes.
onx_optimized = to_onnx(
llm,
(input_ids,),
options=OptimizationOptions(patterns="default+onnxruntime", constant_folding=True, verbose=2),
)
print(pretty_onnx(onx_optimized))
[GraphBuilder-EAA.optimize] start with 73 nodes
[GraphBuilder-EAA.optimize] #patterns=121
[GraphBuilder-EAA.remove_unused] remove_initializer 1:1/47:embedding.embedding.weight:torch.float32[torch.Size([1024, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 2:3/47:embedding.pe.weight:torch.float32[torch.Size([1024, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 3:5/47:decoder.attention.attention.0.query.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 4:7/47:decoder.attention.attention.0.key.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 5:9/47:decoder.attention.attention.0.value.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 6:11/47:decoder.attention.attention.1.query.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 7:13/47:decoder.attention.attention.1.key.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 8:15/47:decoder.attention.attention.1.value.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 9:17/47:decoder.attention.linear.weight:torch.float32[torch.Size([16, 32])]
[GraphBuilder-EAA.remove_unused] remove_initializer 10:19/47:decoder.attention.linear.bias:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 11:21/47:decoder.feed_forward.linear_1.weight:torch.float32[torch.Size([128, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 12:23/47:decoder.feed_forward.linear_1.bias:torch.float32[torch.Size([128])]
[GraphBuilder-EAA.remove_unused] remove_initializer 13:25/47:decoder.feed_forward.linear_2.weight:torch.float32[torch.Size([16, 128])]
[GraphBuilder-EAA.remove_unused] remove_initializer 14:27/47:decoder.feed_forward.linear_2.bias:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 15:29/47:decoder.norm_1.weight:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 16:31/47:decoder.norm_1.bias:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 17:33/47:decoder.norm_2.weight:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 18:35/47:decoder.norm_2.bias:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 1:2/46:p_decoder_attention_attention_0_query_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 2:3/46:p_decoder_attention_attention_0_key_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 3:4/46:p_decoder_attention_attention_0_value_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 4:5/46:p_decoder_attention_attention_1_query_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 5:6/46:p_decoder_attention_attention_1_key_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 6:7/46:p_decoder_attention_attention_1_value_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 7:8/46:p_decoder_attention_linear_weight:torch.float32[torch.Size([16, 32])]
[GraphBuilder-EAA.remove_unused] remove_initializer 8:10/46:p_decoder_feed_forward_linear_1_weight:torch.float32[torch.Size([128, 16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 9:12/46:p_decoder_feed_forward_linear_2_weight:torch.float32[torch.Size([16, 128])]
[GraphBuilder-EAA.remove_unused] remove_initializer 10:18/46:b_decoder_attention_attention_0_mask:torch.float32[torch.Size([256, 256])]
[GraphBuilder-EAA.remove_unused] remove_initializer 11:19/46:b_decoder_attention_attention_1_mask:torch.float32[torch.Size([256, 256])]
[GraphBuilder-EAA.remove_unused] remove_initializer 12:23/46:init1_s_:float32[()]
[GraphBuilder-EAA.remove_unused] remove_initializer 13:24/46:init7_s1_1:int64[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 14:25/46:init7_s1_0:int64[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 15:26/46:init7_s1_30:int64[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 16:27/46:init1_s_2:float32[()]
[GraphBuilder-EAA.remove_unused] remove_initializer 17:33/46:slice_1:torch.float32[torch.Size([30, 256])]
[GraphBuilder-EAA.remove_unused] remove_initializer 18:40/46:slice_3:torch.float32[torch.Size([30, 256])]
[GraphBuilderPatternOptimization-EAA.optimize] start with 53 nodes, 28 initializers, 121 patterns, priorities=[0, 1, 2, 3], max_iter=212
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 1/121 - P0 - BatchNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 2/121 - P0 - BatchNormalizationTrainingPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 3/121 - P0 - CastCastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 4/121 - P0 - CastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 5/121 - P0 - ConcatGatherPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 6/121 - P0 - ConcatReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 7/121 - P0 - ConvBiasNullPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 8/121 - P0 - ExpandPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 9/121 - P0 - FunctionAttentionGQAPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 10/121 - P0 - FunctionAttentionPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 11/121 - P0 - GeluErfPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 12/121 - P0 - GeluOrtPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 13/121 - P0 - GeluPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 14/121 - P0 - IdentityPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 15/121 - P0 - LeakyReluPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 16/121 - P0 - ReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 17/121 - P0 - ReshapeReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 18/121 - P0 - SameChildrenFromInputPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 19/121 - P0 - SameChildrenPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 20/121 - P0 - ShapeBasedEditDistanceReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 21/121 - P0 - ShapeBasedIdentityPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 22/121 - P0 - ShapeBasedReshapeIsSqueezePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 23/121 - P0 - ShapeBasedSameChildrenPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 24/121 - P0 - ShapeBasedShapeShapeAddPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 25/121 - P0 - ShapeBasedStaticExpandPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 26/121 - P0 - ShapedBasedReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 27/121 - P0 - SoftmaxCrossEntropyLossCastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 28/121 - P0 - SqueezeAddPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 29/121 - P0 - SqueezeBinaryUnsqueezePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 30/121 - P0 - SqueezeUnsqueezePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 31/121 - P0 - StaticConcatReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 32/121 - P0 - SwapExpandReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 33/121 - P0 - SwapUnaryPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 34/121 - P0 - SwapUnsqueezeTransposePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 35/121 - P0 - TransposeGatherPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 36/121 - P0 - TransposeReshapeTransposePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 37/121 - P0 - TransposeTransposePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 38/121 - P0 - UnsqueezeOrSqueezeReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 39/121 - P0 - UnsqueezeReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 40/121 - P0 - UnsqueezeUnsqueezePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 41/121 - P1 - BiasGeluPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 42/121 - P1 - BiasSoftmaxPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 43/121 - P1 - CastCastBinaryPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 44/121 - P1 - CastLayerNormalizationCastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 45/121 - P1 - CastOpCastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 46/121 - P1 - ClipClipPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 47/121 - P1 - ConcatEmptyPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 48/121 - P1 - ConcatTwiceUnaryPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 49/121 - P1 - ConstantToInitializerPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 50/121 - P1 - ContribRotaryEmbedding3DPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 51/121 - P1 - DropoutPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 52/121 - P1 - ExpandBroadcastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 53/121 - P1 - ExpandSwapPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 54/121 - P1 - FastGeluPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 55/121 - P1 - FunctionCausalMaskMulAddPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 56/121 - P1 - FunctionCausalMaskPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 57/121 - P1 - FunctionCosSinCachePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 58/121 - P1 - FunctionHalfRotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 59/121 - P1 - GathersSplitPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 60/121 - P1 - GemmTransposePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 61/121 - P1 - LayerNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 62/121 - P1 - LayerNormalizationScalePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 63/121 - P1 - MatMulReshape2Of3Pattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 64/121 - P1 - MissingCosSinPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 65/121 - P1 - MissingRangePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 66/121 - P1 - MissingReduceMaxPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 67/121 - P1 - MissingTopKPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 68/121 - P1 - MulMulMatMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 69/121 - P1 - MulMulMulScalarPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 70/121 - P1 - NotNotPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 71/121 - P1 - NotWherePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 72/121 - P1 - OrtBatchNormalizationTrainingPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 73/121 - P1 - QuickGeluPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 74/121 - P1 - RMSNormalizationMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 75/121 - P1 - RMSNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 76/121 - P1 - ReduceArgTopKPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 77/121 - P1 - ReduceReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 78/121 - P1 - ReduceSumNormalizePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 79/121 - P1 - Reshape2Of3Pattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 80/121 - P1 - ReshapeMatMulReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 81/121 - P1 - ReshapeReshapeBinaryPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 82/121 - P1 - RotaryConcatPartPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 83/121 - P1 - RotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 84/121 - P1 - SequenceConstructAtPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 85/121 - P1 - ShapeBasedConcatExpandPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 86/121 - P1 - ShapeBasedExpandBroadcastMatMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 87/121 - P1 - ShapeBasedExpandBroadcastPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 88/121 - P1 - ShapeBasedExpandCastWhereSwapPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 89/121 - P1 - ShapeBasedExpandSwapPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 90/121 - P1 - ShapeBasedMatMulToMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 91/121 - P1 - SimplifiedLayerNormalizationMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 92/121 - P1 - SimplifiedLayerNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 93/121 - P1 - SkipLayerNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 94/121 - P1 - SkipSimplifiedLayerNormalizationMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 95/121 - P1 - SkipSimplifiedLayerNormalizationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 96/121 - P1 - SliceSlicePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 97/121 - P1 - SlicesSplitPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 98/121 - P1 - SoftmaxGradPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 99/121 - P1 - SplitConcatPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 100/121 - P1 - Sub1MulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 101/121 - P1 - SwapRangeAddScalarPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 102/121 - P1 - SwitchOrderBinaryPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 103/121 - P1 - SwitchReshapeActivationPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 104/121 - P1 - TransposeEqualReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 105/121 - P1 - TransposeMatMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 106/121 - P1 - TransposeReshapeMatMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 107/121 - P1 - UnsqueezeEqualPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 108/121 - P1 - WhereAddPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 109/121 - P2 - AttentionGQAPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 110/121 - P2 - ContribRotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 111/121 - P2 - FusedConvPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 112/121 - P2 - FusedMatMulDivPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 113/121 - P2 - FusedMatMulPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 114/121 - P2 - GroupQueryAttention3DPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 115/121 - P2 - MultiHeadAttention3DPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 116/121 - P3 - FusedMatMulTransposePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 117/121 - P3 - FusedMatMulx2Pattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 118/121 - P3 - MatMulAddPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 119/121 - P3 - ReshapeGemmPattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 120/121 - P3 - ReshapeGemmReshapePattern()
[GraphBuilderPatternOptimization-EAA.optimize] use pattern 121/121 - P3 - TransposeFusedMatMulBPattern()
[GraphBuilderPatternOptimization-EAA.optimize] same children={'SameChildrenPattern', 'SameChildrenFromInputPattern'}
[GraphBuilderPatternOptimization-EAA.optimize] iteration 0: 53 nodes, priority=0
[GraphBuilderPatternOptimization-EAA.optimize] applies 6 matches, 2*CastPattern, 4*IdentityPattern - time=0.010 | max_time=SoftmaxCrossEntropyLossCastPattern:0.002
[GraphBuilder-EAA.remove_unused] remove_initializer 1:5/28:p_decoder_norm_1_weight:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 2:6/28:p_decoder_norm_1_bias:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 3:7/28:p_decoder_norm_2_weight:torch.float32[torch.Size([16])]
[GraphBuilder-EAA.remove_unused] remove_initializer 4:8/28:p_decoder_norm_2_bias:torch.float32[torch.Size([16])]
[GraphBuilderPatternOptimization-EAA.optimize] iteration 1: 47 nodes, priority=0
[GraphBuilderPatternOptimization-EAA.optimize] increase priority to 1
[GraphBuilderPatternOptimization-EAA.optimize] iteration 2: 47 nodes, priority=1
[GraphBuilderPatternOptimization-EAA.optimize] applies 2 matches, 2*LayerNormalizationPattern - time=0.007 | max_time=IdentityPattern:0.000
[GraphBuilder-EAA.remove_unused] remove_initializer 1:5/26:init7_s1_-1:int64[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 2:6/26:init1_s1_:float32[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 3:7/26:init1_s1_2:float32[(1,)]
[GraphBuilderPatternOptimization-EAA.optimize] iteration 3: 35 nodes, priority=1
[GraphBuilderPatternOptimization-EAA.optimize] applies 2 matches, 2*SkipLayerNormalizationPattern - time=0.006 | max_time=IdentityPattern:0.000
[GraphBuilderPatternOptimization-EAA.optimize] iteration 4: 33 nodes, priority=1
[GraphBuilderPatternOptimization-EAA.optimize] increase priority to 2
[GraphBuilderPatternOptimization-EAA.optimize] iteration 5: 33 nodes, priority=2
[GraphBuilderPatternOptimization-EAA.optimize] applies 2 matches, 2*FusedMatMulPattern - time=0.006 | max_time=IdentityPattern:0.000
[GraphBuilder-EAA.remove_unused] remove_initializer 1:9/23:init1_s_::RSh1:float32[(1,)]
[GraphBuilder-EAA.remove_unused] remove_initializer 2:15/23:init1_s_::RSh12:float32[(1,)]
[GraphBuilderPatternOptimization-EAA.optimize] iteration 6: 29 nodes, priority=2
[GraphBuilderPatternOptimization-EAA.optimize] increase priority to 3
[GraphBuilderPatternOptimization-EAA.optimize] iteration 7: 29 nodes, priority=3
[GraphBuilderPatternOptimization-EAA.optimize] stops current_priority_index=4, priorities=[0, 1, 2, 3]
[GraphBuilderPatternOptimization-EAA.optimize] done after 8 iterations with 29 nodes in 0.069
STAT apply_CastPattern +2 -2 #it=1 maxmatch=1 i=2 - time=0.0002860429958673194
STAT apply_FusedMatMulPattern +2 -6 #it=1 maxmatch=1 i=2 - time=0.0007790100062265992
STAT apply_IdentityPattern +4 -4 #it=1 maxmatch=5 i=4 - time=0.0004455059897736646
STAT apply_LayerNormalizationPattern +2 -14 #it=1 maxmatch=1 i=2 - time=0.0007283020022441633
STAT apply_SkipLayerNormalizationPattern +2 -4 #it=1 maxmatch=1 i=2 - time=0.00033534901012899354
STAT build_graph_for_pattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.0017056899887393229
STAT check_pattern_00 +0 -0 #it=1 maxmatch=0 i=0 - time=0.00015481599984923378
STAT check_pattern_A10 +0 -0 #it=4 maxmatch=0 i=0 - time=1.1683005141094327e-05
STAT check_pattern_A20 +0 -0 #it=8 maxmatch=0 i=0 - time=0.000881986998138018
STAT check_pattern_BD0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0007480690037482418
STAT check_pattern_BI0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0007900379932834767
STAT check_pattern_BU0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0007875739975133911
STAT insert_and_remove_nodes +0 -0 #it=0 maxmatch=0 i=0 - time=0.0010953340024570934
STAT iteration_0 +0 -0 #it=1 maxmatch=0 i=0 - time=0.012647089002712164
STAT iteration_1 +0 -0 #it=1 maxmatch=0 i=0 - time=0.004608982002537232
STAT iteration_2 +0 -0 #it=1 maxmatch=0 i=0 - time=0.009446561998629477
STAT iteration_3 +0 -0 #it=1 maxmatch=0 i=0 - time=0.008148878005158622
STAT iteration_4 +0 -0 #it=1 maxmatch=0 i=0 - time=0.013961549993837252
STAT iteration_5 +0 -0 #it=1 maxmatch=0 i=0 - time=0.00793398599489592
STAT iteration_6 +0 -0 #it=1 maxmatch=0 i=0 - time=0.005819630998303182
STAT match_AttentionGQAPattern +0 -0 #it=3 maxmatch=0 i=0 - time=7.925799582153559e-05
STAT match_BatchNormalizationPattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.0003406409887247719
STAT match_BatchNormalizationTrainingPattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.0002844090122380294
STAT match_BiasGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020976599626010284
STAT match_BiasSoftmaxPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022205498680705205
STAT match_CastCastBinaryPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0005340769930626266
STAT match_CastCastPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.00031491199479205534
STAT match_CastLayerNormalizationCastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002316430036444217
STAT match_CastOpCastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0004972940005245619
STAT match_CastPattern +0 -0 #it=8 maxmatch=2 i=2 - time=0.0003099699897575192
STAT match_ClipClipPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.00019658400560729206
STAT match_ConcatEmptyPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002669509995030239
STAT match_ConcatGatherPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.0003603480145102367
STAT match_ConcatReshapePattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.00028484001086326316
STAT match_ConcatTwiceUnaryPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002214330088463612
STAT match_ConstantToInitializerPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0001876279930002056
STAT match_ContribRotaryEmbedding3DPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002094449955620803
STAT match_ContribRotaryEmbeddingPattern +0 -0 #it=3 maxmatch=0 i=0 - time=0.00010075999307446182
STAT match_ConvBiasNullPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.00030334298935486004
STAT match_DropoutPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0001694570019026287
STAT match_ExpandBroadcastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0001868599938461557
STAT match_ExpandPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.0002756060057436116
STAT match_ExpandSwapPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.00018095600535161793
STAT match_FastGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021817300148541108
STAT match_FunctionAttentionGQAPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003973829952883534
STAT match_FunctionAttentionPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0010128219946636818
STAT match_FunctionCausalMaskMulAddPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00032485600240761414
STAT match_FunctionCausalMaskPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002314160010428168
STAT match_FunctionCosSinCachePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002374159957980737
STAT match_FunctionHalfRotaryEmbeddingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022281001292867586
STAT match_FusedConvPattern +0 -0 #it=3 maxmatch=0 i=0 - time=8.622900350019336e-05
STAT match_FusedMatMulDivPattern +0 -0 #it=3 maxmatch=2 i=0 - time=0.00022438000451074913
STAT match_FusedMatMulPattern +0 -0 #it=3 maxmatch=2 i=2 - time=0.0004862389905611053
STAT match_FusedMatMulTransposePattern +0 -0 #it=1 maxmatch=0 i=0 - time=7.577399810543284e-05
STAT match_FusedMatMulx2Pattern +0 -0 #it=1 maxmatch=0 i=0 - time=7.985399861354381e-05
STAT match_GathersSplitPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.00024274700263049453
STAT match_GeluErfPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.003666188997158315
STAT match_GeluOrtPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.005019265998271294
STAT match_GeluPattern +0 -0 #it=8 maxmatch=2 i=0 - time=7.975002517923713e-06
STAT match_GemmTransposePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020285699429223314
STAT match_GroupQueryAttention3DPattern +0 -0 #it=3 maxmatch=0 i=0 - time=0.00010309099889127538
STAT match_IdentityPattern +0 -0 #it=8 maxmatch=6 i=4 - time=0.002766459008853417
STAT match_LayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=2 - time=0.00037449800583999604
STAT match_LayerNormalizationScalePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021956999989924952
STAT match_LeakyReluPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0034703869896475226
STAT match_MatMulAddPattern +0 -0 #it=1 maxmatch=0 i=0 - time=7.667000318178907e-05
STAT match_MatMulReshape2Of3Pattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0008281329937744886
STAT match_MissingCosSinPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020591599604813382
STAT match_MissingRangePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00019272400095360354
STAT match_MissingReduceMaxPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00019710299966391176
STAT match_MissingTopKPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0001945850090123713
STAT match_MulMulMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00046741801634198055
STAT match_MulMulMulScalarPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002488940008333884
STAT match_MultiHeadAttention3DPattern +0 -0 #it=3 maxmatch=2 i=0 - time=0.00010643000132404268
STAT match_NotNotPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00018978298612637445
STAT match_NotWherePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0001819200042518787
STAT match_OrtBatchNormalizationTrainingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00033227600215468556
STAT match_QuickGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020351699640741572
STAT match_RMSNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002063340143649839
STAT match_RMSNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021428400214063004
STAT match_ReduceArgTopKPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022289999469649047
STAT match_ReduceReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00024637999740662053
STAT match_ReduceSumNormalizePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002065009975922294
STAT match_Reshape2Of3Pattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0006804819931858219
STAT match_ReshapeGemmPattern +0 -0 #it=1 maxmatch=0 i=0 - time=2.726900129346177e-05
STAT match_ReshapeGemmReshapePattern +0 -0 #it=1 maxmatch=0 i=0 - time=2.7182999474462122e-05
STAT match_ReshapeMatMulReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00040938601159723476
STAT match_ReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00029495898343157023
STAT match_ReshapeReshapeBinaryPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00040913900738814846
STAT match_ReshapeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00027460799901746213
STAT match_RotaryConcatPartPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002946459935628809
STAT match_RotaryEmbeddingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00023018800129648298
STAT match_SameChildrenFromInputPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0005969650010229088
STAT match_SameChildrenPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0010694059965317138
STAT match_SequenceConstructAtPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020498999947449192
STAT match_ShapeBasedConcatExpandPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020895700436085463
STAT match_ShapeBasedEditDistanceReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00028443899645935744
STAT match_ShapeBasedExpandBroadcastMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0006300949971773662
STAT match_ShapeBasedExpandBroadcastPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0005508530011866242
STAT match_ShapeBasedExpandCastWhereSwapPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00023806600802345201
STAT match_ShapeBasedExpandSwapPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0005076640009065159
STAT match_ShapeBasedIdentityPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003886499907821417
STAT match_ShapeBasedMatMulToMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0005099700065329671
STAT match_ShapeBasedReshapeIsSqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003352430067025125
STAT match_ShapeBasedSameChildrenPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003185010064044036
STAT match_ShapeBasedShapeShapeAddPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00036401101533556357
STAT match_ShapeBasedStaticExpandPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003041789968847297
STAT match_ShapedBasedReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00028991300496272743
STAT match_SimplifiedLayerNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00023812198196537793
STAT match_SimplifiedLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0003915529960067943
STAT match_SkipLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=2 - time=0.0002451850086799823
STAT match_SkipSimplifiedLayerNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002113519949489273
STAT match_SkipSimplifiedLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00018638300389284268
STAT match_SliceSlicePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000189096994290594
STAT match_SlicesSplitPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020342000789241865
STAT match_SoftmaxCrossEntropyLossCastPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.004723661004391033
STAT match_SoftmaxGradPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00018962498870678246
STAT match_SplitConcatPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00019338700803928077
STAT match_SqueezeAddPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004355750061222352
STAT match_SqueezeBinaryUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.000280373016721569
STAT match_SqueezeUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00030584100022679195
STAT match_StaticConcatReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00027274600142845884
STAT match_Sub1MulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00023766600497765467
STAT match_SwapExpandReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0002707110033952631
STAT match_SwapRangeAddScalarPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022525800159201026
STAT match_SwapUnaryPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003967070078942925
STAT match_SwapUnsqueezeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003188519840477966
STAT match_SwitchOrderBinaryPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0005761369975516573
STAT match_SwitchReshapeActivationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0003185170062351972
STAT match_TransposeEqualReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00029591500060632825
STAT match_TransposeFusedMatMulBPattern +0 -0 #it=1 maxmatch=0 i=0 - time=0.00011855600314447656
STAT match_TransposeGatherPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003086620054091327
STAT match_TransposeMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000500725996971596
STAT match_TransposeReshapeMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0004509639911702834
STAT match_TransposeReshapeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003127879972453229
STAT match_TransposeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00031054199644131586
STAT match_UnsqueezeEqualPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00038572499761357903
STAT match_UnsqueezeOrSqueezeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.000320604995067697
STAT match_UnsqueezeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0002773789965431206
STAT match_UnsqueezeUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0002844379923772067
STAT match_WhereAddPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002816110063577071
STAT remove_duplicated_shape +0 -0 #it=8 maxmatch=0 i=0 - time=5.9851983678527176e-05
STAT remove_identity_nodes +9 -15 #it=8 maxmatch=0 i=0 - time=0.0023228010104503483
STAT remove_unused +0 -0 #it=8 maxmatch=0 i=0 - time=0.0025592949968995526
--MODEL: 29 nodes, 1 inputs, 1 outputs, 21 initializers--
INPUT: 1 x 7t
INPUT-SEQ: 1 x Falset
OUTPUT: 1 x 1t
OUTPUT-SEQ: 1 x Falset
INIT: 21 x 1t
NODE: 4 x Add
NODE: 1 x Concat
NODE: 2 x Equal
NODE: 2 x Gather
NODE: 11 x MatMul
NODE: 1 x Relu
NODE: 2 x Softmax
NODE: 2 x Where
NODE: 2 x com.microsoft.FusedMatMul
NODE: 2 x com.microsoft.SkipLayerNormalization
--MODEL: 29 nodes, 1 inputs, 1 outputs, 21 initializers--DETAILED--
INPUT: 1 x 7t[1x30]
OUTPUT: 1 x 1t[1x30x16]
INIT: 2 x 1t[1024x16]
INIT: 1 x 1t[128]
INIT: 1 x 1t[128x16]
INIT: 4 x 1t[16]
INIT: 1 x 1t[16x128]
INIT: 6 x 1t[16x16]
INIT: 3 x 1t[1]
INIT: 2 x 1t[30x30]
INIT: 1 x 1t[32x16]
NODE: 1 x Add -SIG- 1t[1x30x128], 1t[128]
NODE: 2 x Add -SIG- 1t[1x30x16], 1t[16]
NODE: 1 x Add -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 1 x Concat -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 2 x Equal -SIG- 1t[30x30], 1t[1]
NODE: 2 x Gather -SIG- 1t[1024x16], 7t[1x30]
NODE: 1 x MatMul -SIG- 1t[1x30x128], 1t[128x16]
NODE: 1 x MatMul -SIG- 1t[1x30x16], 1t[16x128]
NODE: 6 x MatMul -SIG- 1t[1x30x16], 1t[16x16]
NODE: 2 x MatMul -SIG- 1t[1x30x30], 1t[1x30x16]
NODE: 1 x MatMul -SIG- 1t[1x30x32], 1t[32x16]
NODE: 1 x Relu -SIG- 1t[1x30x128]
NODE: 2 x Softmax -SIG- 1t[1x30x30]
NODE: 2 x Where -SIG- 9t[30x30], 1t[1], 1t[1x30x30]
NODE: 2 x com.microsoft.FusedMatMul -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 2 x com.microsoft.SkipLayerNormalization -SIG- 1t[1x30x16], 1t[1x30x16], 1t[16], 1t[16]
[GraphBuilder-EAA.remove_unused] remove_initializer 1:15/21:init1_s_2::RSh12:float32[(1,)]
[OrderOptimization.optimize] ALGO-2
[OrderOptimization.random_order] -- starts with 29 nodes, 20 initializers
[OrderOptimization.shape_order] done after in 0.00021789500169688836s with changed=0 scale=0
[GraphBuilder-EAA.optimize] done with 29 nodes in 0.080
opset: domain='' version=18
opset: domain='com.microsoft' version=1
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='init1_s1_3' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- Opset.make_node.1/Small##Opset.make_node.1/Small
init: name='p_decoder_attention_attention_0_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_query_weight)##p_decoder_attention_attention_0_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.query.weight)
init: name='p_decoder_attention_attention_0_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_key_weight)##p_decoder_attention_attention_0_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.key.weight)
init: name='p_decoder_attention_attention_0_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_value_weight)##p_decoder_attention_attention_0_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.value.weight)
init: name='slice_2' type=float32 shape=(30, 30) -- GraphBuilder.constant_folding.from/fold(init7_s1_0,init7_s1_1,init7_s1_30,slice_1)##slice_1/GraphBuilder.constant_folding.from/fold(b_decoder_attention_attention_0_mask,init7_s1_0,init7_s1_30)##b_decoder_attention_attention_0_mask/DynamoInterpret.placeholder.0##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init1_s_2::RSh1' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilder.constant_folding.from/fold(init1_s_2,init7_s1_1)##init1_s_2/shape_type_compute._cast_inputs.0##shape_type_compute._cast_inputs.0##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='p_decoder_attention_attention_1_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_query_weight)##p_decoder_attention_attention_1_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.query.weight)
init: name='p_decoder_attention_attention_1_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_key_weight)##p_decoder_attention_attention_1_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.key.weight)
init: name='p_decoder_attention_attention_1_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_value_weight)##p_decoder_attention_attention_1_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.value.weight)
init: name='slice_4' type=float32 shape=(30, 30) -- GraphBuilder.constant_folding.from/fold(init7_s1_0,init7_s1_1,init7_s1_30,slice_3)##slice_3/GraphBuilder.constant_folding.from/fold(b_decoder_attention_attention_1_mask,init7_s1_0,init7_s1_30)##b_decoder_attention_attention_1_mask/DynamoInterpret.placeholder.0##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='p_decoder_attention_linear_weight::T10' type=float32 shape=(32, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_linear_weight)##p_decoder_attention_linear_weight/DynamoInterpret.placeholder.1/P(decoder.attention.linear.weight)
init: name='p_decoder_feed_forward_linear_1_weight::T10' type=float32 shape=(16, 128)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_1_weight)##p_decoder_feed_forward_linear_1_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.weight)
init: name='p_decoder_feed_forward_linear_2_weight::T10' type=float32 shape=(128, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_2_weight)##p_decoder_feed_forward_linear_2_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.weight)
init: name='init1_s16_' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.scale##LayerNormalizationPattern.apply.scale
init: name='init1_s16_2' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.bias##LayerNormalizationPattern.apply.bias
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.pe.weight)
init: name='decoder.attention.linear.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(decoder.attention.linear.bias)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.bias)
init: name='decoder.feed_forward.linear_2.bias' type=float32 shape=(16,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.bias)
Equal(slice_2, init1_s_2::RSh1) -> eq
Gather(embedding.embedding.weight, input_ids) -> embedding
Gather(embedding.pe.weight, input_ids) -> embedding_1
SkipLayerNormalization[com.microsoft](embedding, embedding_1, init1_s16_, init1_s16_2, epsilon=0.00) -> _onx_div_sub_add, unused, unused2, add
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_query_weight::T10) -> linear
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_key_weight::T10) -> linear_1
FusedMatMul[com.microsoft](linear, linear_1, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul
Where(eq, init1_s1_3, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_value_weight::T10) -> linear_2
MatMul(softmax, linear_2) -> matmul_1
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_query_weight::T10) -> linear_3
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_key_weight::T10) -> linear_4
FusedMatMul[com.microsoft](linear_3, linear_4, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul_2
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_value_weight::T10) -> linear_5
Equal(slice_4, init1_s_2::RSh1) -> eq_1
Where(eq_1, init1_s1_3, _onx_mul_matmul_2) -> masked_fill_1
Softmax(masked_fill_1, axis=-1) -> softmax_1
MatMul(softmax_1, linear_5) -> matmul_3
Concat(matmul_1, matmul_3, axis=-1) -> cat
MatMul(cat, p_decoder_attention_linear_weight::T10) -> _onx_matmul_cat
Add(_onx_matmul_cat, decoder.attention.linear.bias) -> linear_6
SkipLayerNormalization[com.microsoft](linear_6, add, init1_s16_, init1_s16_2, epsilon=0.00) -> _onx_div_sub_add_1, unused3, unused4, add_1
MatMul(_onx_div_sub_add_1, p_decoder_feed_forward_linear_1_weight::T10) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_7
Relu(linear_7) -> relu
MatMul(relu, p_decoder_feed_forward_linear_2_weight::T10) -> _onx_matmul_relu
Add(_onx_matmul_relu, decoder.feed_forward.linear_2.bias) -> linear_8
Add(linear_8, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
This shows a kernel FusedMatMul[com.microsoft] which implement a kernel equivalent Gemm
but working for any tensors, not only 2D.
How does it work on the model which keeps exports the moduels as local functions?
The optimizer optimizes every local function independantly.
We reduce the verbosity…
onx_module_optimized = to_onnx(
llm,
(input_ids,),
options=OptimizationOptions(patterns="default+onnxruntime", constant_folding=True),
export_modules_as_functions=True,
)
print(pretty_onnx(onx_module_optimized))
/usr/lib/python3.12/copyreg.py:99: FutureWarning: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
return cls.__new__(cls, *args)
opset: domain='' version=18
opset: domain='aten_local_function' version=1
opset: domain='com.microsoft' version=1
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- GraphBuilder.make_local_function/from(embedding.pe.weight)
init: name='weight::T10' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T10)
init: name='weight::T102' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T102)
init: name='weight::T103' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T103)
init: name='slice_2' type=float32 shape=(30, 30) -- GraphBuilder.make_local_function/from(slice_2)
init: name='weight::T104' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T104)
init: name='weight::T1022' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1022)
init: name='weight::T1032' type=float32 shape=(16, 16) -- GraphBuilder.make_local_function/from(weight::T1032)
init: name='slice_4' type=float32 shape=(30, 30) -- GraphBuilder.make_local_function/from(slice_4)
init: name='weight::T105' type=float32 shape=(32, 16) -- GraphBuilder.make_local_function/from(weight::T105)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- GraphBuilder.make_local_function/from(decoder.feed_forward.linear_1.bias)
init: name='weight::T106' type=float32 shape=(16, 128) -- GraphBuilder.make_local_function/from(weight::T106)
init: name='weight::T1023' type=float32 shape=(128, 16) -- GraphBuilder.make_local_function/from(weight::T1023)
init: name='init1_s16_3' type=float32 shape=(16,) -- GraphBuilder.constant_folding.from/fold()
init: name='init1_s16_22' type=float32 shape=(16,) -- GraphBuilder.constant_folding.from/fold()
init: name='bias2' type=float32 shape=(16,) -- GraphBuilder.constant_folding.from/fold()
init: name='bias' type=float32 shape=(16,) -- GraphBuilder.constant_folding.from/fold()
init: name='init1_s1_2' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- GraphBuilder.constant_folding.from/fold()
init: name='init1_s_2::RSh12' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilder.constant_folding.from/fold()
Equal(slice_2, init1_s_2::RSh12) -> eq
Gather(embedding.embedding.weight, input_ids) -> embedding2
Gather(embedding.pe.weight, input_ids) -> pe
SkipLayerNormalization[com.microsoft](embedding2, pe, init1_s16_3, init1_s16_22, epsilon=0.00) -> norm_1, unused, unused2, embedding
MatMul(norm_1, weight::T10) -> query
MatMul(norm_1, weight::T102) -> key
FusedMatMul[com.microsoft](query, key, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul
Where(eq, init1_s1_2, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(norm_1, weight::T103) -> value
MatMul(softmax, value) -> attention_0
MatMul(norm_1, weight::T104) -> query2
MatMul(norm_1, weight::T1022) -> key2
FusedMatMul[com.microsoft](query2, key2, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul2
MatMul(norm_1, weight::T1032) -> value2
Equal(slice_4, init1_s_2::RSh12) -> eq2
Where(eq2, init1_s1_2, _onx_mul_matmul2) -> masked_fill2
Softmax(masked_fill2, axis=-1) -> softmax2
MatMul(softmax2, value2) -> attention_1
Concat(attention_0, attention_1, axis=-1) -> cat
MatMul(cat, weight::T105) -> _onx_matmul_cat
Add(_onx_matmul_cat, bias) -> attention
SkipLayerNormalization[com.microsoft](attention, embedding, init1_s16_3, init1_s16_22, epsilon=0.00) -> norm_2, unused3, unused4, add_1
MatMul(norm_2, weight::T106) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_1
Relu(linear_1) -> relu
MatMul(relu, weight::T1023) -> _onx_matmul_relu
Add(_onx_matmul_relu, bias2) -> feed_forward
Add(feed_forward, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
It seems to be working as well on this simple case even though the optimizers were not tested on such models. However, keeping the submodule information might be useful to implement optimizer for a fmaily of models sharing the same components.
Optimizations for CUDA¶
The optimizer may have a different behaviour knowning the model is running on CUDA. It may use different kernels and do different optimization if needed. That may not be the good place to do it as the runtime may choose to run one kernel on CPU, another one on CUDA. The current optimization does not know that and is not able to decide which provider would be more useful for some kernels. This coudl even be decided at runtime.
onx_cuda_optimized = to_onnx(
llm,
(input_ids,),
options=OptimizationOptions(
patterns="default+onnxruntime", constant_folding=True, verbose=2, processor="CUDA"
),
)
print(pretty_onnx(onx_cuda_optimized))
[GraphBuilder-KSU.optimize] start with 73 nodes
[GraphBuilder-KSU.optimize] #patterns=121
[GraphBuilder-KSU.remove_unused] remove_initializer 1:1/47:embedding.embedding.weight:torch.float32[torch.Size([1024, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 2:3/47:embedding.pe.weight:torch.float32[torch.Size([1024, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 3:5/47:decoder.attention.attention.0.query.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 4:7/47:decoder.attention.attention.0.key.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 5:9/47:decoder.attention.attention.0.value.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 6:11/47:decoder.attention.attention.1.query.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 7:13/47:decoder.attention.attention.1.key.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 8:15/47:decoder.attention.attention.1.value.weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 9:17/47:decoder.attention.linear.weight:torch.float32[torch.Size([16, 32])]
[GraphBuilder-KSU.remove_unused] remove_initializer 10:19/47:decoder.attention.linear.bias:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 11:21/47:decoder.feed_forward.linear_1.weight:torch.float32[torch.Size([128, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 12:23/47:decoder.feed_forward.linear_1.bias:torch.float32[torch.Size([128])]
[GraphBuilder-KSU.remove_unused] remove_initializer 13:25/47:decoder.feed_forward.linear_2.weight:torch.float32[torch.Size([16, 128])]
[GraphBuilder-KSU.remove_unused] remove_initializer 14:27/47:decoder.feed_forward.linear_2.bias:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 15:29/47:decoder.norm_1.weight:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 16:31/47:decoder.norm_1.bias:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 17:33/47:decoder.norm_2.weight:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 18:35/47:decoder.norm_2.bias:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 1:2/46:p_decoder_attention_attention_0_query_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 2:3/46:p_decoder_attention_attention_0_key_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 3:4/46:p_decoder_attention_attention_0_value_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 4:5/46:p_decoder_attention_attention_1_query_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 5:6/46:p_decoder_attention_attention_1_key_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 6:7/46:p_decoder_attention_attention_1_value_weight:torch.float32[torch.Size([16, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 7:8/46:p_decoder_attention_linear_weight:torch.float32[torch.Size([16, 32])]
[GraphBuilder-KSU.remove_unused] remove_initializer 8:10/46:p_decoder_feed_forward_linear_1_weight:torch.float32[torch.Size([128, 16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 9:12/46:p_decoder_feed_forward_linear_2_weight:torch.float32[torch.Size([16, 128])]
[GraphBuilder-KSU.remove_unused] remove_initializer 10:18/46:b_decoder_attention_attention_0_mask:torch.float32[torch.Size([256, 256])]
[GraphBuilder-KSU.remove_unused] remove_initializer 11:19/46:b_decoder_attention_attention_1_mask:torch.float32[torch.Size([256, 256])]
[GraphBuilder-KSU.remove_unused] remove_initializer 12:23/46:init1_s_:float32[()]
[GraphBuilder-KSU.remove_unused] remove_initializer 13:24/46:init7_s1_1:int64[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 14:25/46:init7_s1_0:int64[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 15:26/46:init7_s1_30:int64[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 16:27/46:init1_s_2:float32[()]
[GraphBuilder-KSU.remove_unused] remove_initializer 17:33/46:slice_1:torch.float32[torch.Size([30, 256])]
[GraphBuilder-KSU.remove_unused] remove_initializer 18:40/46:slice_3:torch.float32[torch.Size([30, 256])]
[GraphBuilderPatternOptimization-KSU.optimize] start with 53 nodes, 28 initializers, 121 patterns, priorities=[0, 1, 2, 3], max_iter=212
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 1/121 - P0 - BatchNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 2/121 - P0 - BatchNormalizationTrainingPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 3/121 - P0 - CastCastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 4/121 - P0 - CastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 5/121 - P0 - ConcatGatherPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 6/121 - P0 - ConcatReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 7/121 - P0 - ConvBiasNullPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 8/121 - P0 - ExpandPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 9/121 - P0 - FunctionAttentionGQAPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 10/121 - P0 - FunctionAttentionPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 11/121 - P0 - GeluErfPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 12/121 - P0 - GeluOrtPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 13/121 - P0 - GeluPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 14/121 - P0 - IdentityPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 15/121 - P0 - LeakyReluPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 16/121 - P0 - ReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 17/121 - P0 - ReshapeReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 18/121 - P0 - SameChildrenFromInputPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 19/121 - P0 - SameChildrenPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 20/121 - P0 - ShapeBasedEditDistanceReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 21/121 - P0 - ShapeBasedIdentityPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 22/121 - P0 - ShapeBasedReshapeIsSqueezePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 23/121 - P0 - ShapeBasedSameChildrenPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 24/121 - P0 - ShapeBasedShapeShapeAddPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 25/121 - P0 - ShapeBasedStaticExpandPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 26/121 - P0 - ShapedBasedReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 27/121 - P0 - SoftmaxCrossEntropyLossCastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 28/121 - P0 - SqueezeAddPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 29/121 - P0 - SqueezeBinaryUnsqueezePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 30/121 - P0 - SqueezeUnsqueezePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 31/121 - P0 - StaticConcatReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 32/121 - P0 - SwapExpandReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 33/121 - P0 - SwapUnaryPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 34/121 - P0 - SwapUnsqueezeTransposePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 35/121 - P0 - TransposeGatherPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 36/121 - P0 - TransposeReshapeTransposePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 37/121 - P0 - TransposeTransposePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 38/121 - P0 - UnsqueezeOrSqueezeReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 39/121 - P0 - UnsqueezeReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 40/121 - P0 - UnsqueezeUnsqueezePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 41/121 - P1 - BiasGeluPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 42/121 - P1 - BiasSoftmaxPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 43/121 - P1 - CastCastBinaryPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 44/121 - P1 - CastLayerNormalizationCastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 45/121 - P1 - CastOpCastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 46/121 - P1 - ClipClipPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 47/121 - P1 - ConcatEmptyPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 48/121 - P1 - ConcatTwiceUnaryPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 49/121 - P1 - ConstantToInitializerPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 50/121 - P1 - ContribRotaryEmbedding3DPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 51/121 - P1 - DropoutPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 52/121 - P1 - ExpandBroadcastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 53/121 - P1 - ExpandSwapPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 54/121 - P1 - FastGeluPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 55/121 - P1 - FunctionCausalMaskMulAddPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 56/121 - P1 - FunctionCausalMaskPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 57/121 - P1 - FunctionCosSinCachePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 58/121 - P1 - FunctionHalfRotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 59/121 - P1 - GathersSplitPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 60/121 - P1 - GemmTransposePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 61/121 - P1 - LayerNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 62/121 - P1 - LayerNormalizationScalePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 63/121 - P1 - MatMulReshape2Of3Pattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 64/121 - P1 - MissingCosSinPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 65/121 - P1 - MissingRangePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 66/121 - P1 - MissingReduceMaxPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 67/121 - P1 - MissingTopKPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 68/121 - P1 - MulMulMatMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 69/121 - P1 - MulMulMulScalarPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 70/121 - P1 - NotNotPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 71/121 - P1 - NotWherePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 72/121 - P1 - OrtBatchNormalizationTrainingPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 73/121 - P1 - QuickGeluPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 74/121 - P1 - RMSNormalizationMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 75/121 - P1 - RMSNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 76/121 - P1 - ReduceArgTopKPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 77/121 - P1 - ReduceReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 78/121 - P1 - ReduceSumNormalizePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 79/121 - P1 - Reshape2Of3Pattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 80/121 - P1 - ReshapeMatMulReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 81/121 - P1 - ReshapeReshapeBinaryPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 82/121 - P1 - RotaryConcatPartPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 83/121 - P1 - RotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 84/121 - P1 - SequenceConstructAtPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 85/121 - P1 - ShapeBasedConcatExpandPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 86/121 - P1 - ShapeBasedExpandBroadcastMatMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 87/121 - P1 - ShapeBasedExpandBroadcastPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 88/121 - P1 - ShapeBasedExpandCastWhereSwapPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 89/121 - P1 - ShapeBasedExpandSwapPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 90/121 - P1 - ShapeBasedMatMulToMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 91/121 - P1 - SimplifiedLayerNormalizationMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 92/121 - P1 - SimplifiedLayerNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 93/121 - P1 - SkipLayerNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 94/121 - P1 - SkipSimplifiedLayerNormalizationMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 95/121 - P1 - SkipSimplifiedLayerNormalizationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 96/121 - P1 - SliceSlicePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 97/121 - P1 - SlicesSplitPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 98/121 - P1 - SoftmaxGradPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 99/121 - P1 - SplitConcatPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 100/121 - P1 - Sub1MulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 101/121 - P1 - SwapRangeAddScalarPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 102/121 - P1 - SwitchOrderBinaryPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 103/121 - P1 - SwitchReshapeActivationPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 104/121 - P1 - TransposeEqualReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 105/121 - P1 - TransposeMatMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 106/121 - P1 - TransposeReshapeMatMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 107/121 - P1 - UnsqueezeEqualPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 108/121 - P1 - WhereAddPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 109/121 - P2 - AttentionGQAPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 110/121 - P2 - ContribRotaryEmbeddingPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 111/121 - P2 - FusedConvPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 112/121 - P2 - FusedMatMulDivPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 113/121 - P2 - FusedMatMulPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 114/121 - P2 - GroupQueryAttention3DPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 115/121 - P2 - MultiHeadAttention3DPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 116/121 - P3 - FusedMatMulTransposePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 117/121 - P3 - FusedMatMulx2Pattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 118/121 - P3 - MatMulAddPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 119/121 - P3 - ReshapeGemmPattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 120/121 - P3 - ReshapeGemmReshapePattern()
[GraphBuilderPatternOptimization-KSU.optimize] use pattern 121/121 - P3 - TransposeFusedMatMulBPattern()
[GraphBuilderPatternOptimization-KSU.optimize] same children={'SameChildrenPattern', 'SameChildrenFromInputPattern'}
[GraphBuilderPatternOptimization-KSU.optimize] iteration 0: 53 nodes, priority=0
[GraphBuilderPatternOptimization-KSU.optimize] applies 6 matches, 2*CastPattern, 4*IdentityPattern - time=0.011 | max_time=SoftmaxCrossEntropyLossCastPattern:0.003
[GraphBuilder-KSU.remove_unused] remove_initializer 1:5/28:p_decoder_norm_1_weight:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 2:6/28:p_decoder_norm_1_bias:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 3:7/28:p_decoder_norm_2_weight:torch.float32[torch.Size([16])]
[GraphBuilder-KSU.remove_unused] remove_initializer 4:8/28:p_decoder_norm_2_bias:torch.float32[torch.Size([16])]
[GraphBuilderPatternOptimization-KSU.optimize] iteration 1: 47 nodes, priority=0
[GraphBuilderPatternOptimization-KSU.optimize] increase priority to 1
[GraphBuilderPatternOptimization-KSU.optimize] iteration 2: 47 nodes, priority=1
[GraphBuilderPatternOptimization-KSU.optimize] applies 2 matches, 2*LayerNormalizationPattern - time=0.009 | max_time=SameChildrenPattern:0.000
[GraphBuilder-KSU.remove_unused] remove_initializer 1:5/26:init7_s1_-1:int64[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 2:6/26:init1_s1_:float32[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 3:7/26:init1_s1_2:float32[(1,)]
[GraphBuilderPatternOptimization-KSU.optimize] iteration 3: 35 nodes, priority=1
[GraphBuilderPatternOptimization-KSU.optimize] applies 2 matches, 2*SkipLayerNormalizationPattern - time=0.007 | max_time=IdentityPattern:0.001
[GraphBuilderPatternOptimization-KSU.optimize] iteration 4: 33 nodes, priority=1
[GraphBuilderPatternOptimization-KSU.optimize] increase priority to 2
[GraphBuilderPatternOptimization-KSU.optimize] iteration 5: 33 nodes, priority=2
[GraphBuilderPatternOptimization-KSU.optimize] applies 2 matches, 2*FusedMatMulPattern - time=0.007 | max_time=IdentityPattern:0.000
[GraphBuilder-KSU.remove_unused] remove_initializer 1:9/23:init1_s_::RSh1:float32[(1,)]
[GraphBuilder-KSU.remove_unused] remove_initializer 2:15/23:init1_s_::RSh12:float32[(1,)]
[GraphBuilderPatternOptimization-KSU.optimize] iteration 6: 29 nodes, priority=2
[GraphBuilderPatternOptimization-KSU.optimize] increase priority to 3
[GraphBuilderPatternOptimization-KSU.optimize] iteration 7: 29 nodes, priority=3
[GraphBuilderPatternOptimization-KSU.optimize] stops current_priority_index=4, priorities=[0, 1, 2, 3]
[GraphBuilderPatternOptimization-KSU.optimize] done after 8 iterations with 29 nodes in 0.078
STAT apply_CastPattern +2 -2 #it=1 maxmatch=1 i=2 - time=0.0003799129990511574
STAT apply_FusedMatMulPattern +2 -6 #it=1 maxmatch=1 i=2 - time=0.0013199890017858706
STAT apply_IdentityPattern +4 -4 #it=1 maxmatch=5 i=4 - time=0.00040493699634680524
STAT apply_LayerNormalizationPattern +2 -14 #it=1 maxmatch=1 i=2 - time=0.0010906219977186993
STAT apply_SkipLayerNormalizationPattern +2 -4 #it=1 maxmatch=1 i=2 - time=0.00044314600381767377
STAT build_graph_for_pattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.001616968002053909
STAT check_pattern_00 +0 -0 #it=1 maxmatch=0 i=0 - time=0.0003647859994089231
STAT check_pattern_A10 +0 -0 #it=4 maxmatch=0 i=0 - time=1.496501499786973e-05
STAT check_pattern_A20 +0 -0 #it=8 maxmatch=0 i=0 - time=0.001112366997404024
STAT check_pattern_BD0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0009510379968560301
STAT check_pattern_BI0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0008700979960849509
STAT check_pattern_BU0 +0 -0 #it=8 maxmatch=0 i=0 - time=0.0007897210016380996
STAT insert_and_remove_nodes +0 -0 #it=0 maxmatch=0 i=0 - time=0.0015978989904397167
STAT iteration_0 +0 -0 #it=1 maxmatch=0 i=0 - time=0.013713204003579449
STAT iteration_1 +0 -0 #it=1 maxmatch=0 i=0 - time=0.004929210001137108
STAT iteration_2 +0 -0 #it=1 maxmatch=0 i=0 - time=0.012362689005385619
STAT iteration_3 +0 -0 #it=1 maxmatch=0 i=0 - time=0.009276724995288532
STAT iteration_4 +0 -0 #it=1 maxmatch=0 i=0 - time=0.012674511002842337
STAT iteration_5 +0 -0 #it=1 maxmatch=0 i=0 - time=0.00957526899583172
STAT iteration_6 +0 -0 #it=1 maxmatch=0 i=0 - time=0.007365725999989081
STAT match_AttentionGQAPattern +0 -0 #it=3 maxmatch=0 i=0 - time=8.454598719254136e-05
STAT match_BatchNormalizationPattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.00040083199564833194
STAT match_BatchNormalizationTrainingPattern +0 -0 #it=8 maxmatch=0 i=0 - time=0.0003731440083356574
STAT match_BiasGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020832900918321684
STAT match_BiasSoftmaxPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0005890430111321621
STAT match_CastCastBinaryPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0007036970055196434
STAT match_CastCastPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.0003282509933342226
STAT match_CastLayerNormalizationCastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002449460080242716
STAT match_CastOpCastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0005555180105147883
STAT match_CastPattern +0 -0 #it=8 maxmatch=2 i=2 - time=0.0003622660005930811
STAT match_ClipClipPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002456459842505865
STAT match_ConcatEmptyPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0003663100069388747
STAT match_ConcatGatherPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.00041878999763866886
STAT match_ConcatReshapePattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.000358330988092348
STAT match_ConcatTwiceUnaryPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002621790117700584
STAT match_ConstantToInitializerPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.00021522199676837772
STAT match_ContribRotaryEmbedding3DPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020380900241434574
STAT match_ContribRotaryEmbeddingPattern +0 -0 #it=3 maxmatch=0 i=0 - time=0.00011477199586806819
STAT match_ConvBiasNullPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.0003001199947902933
STAT match_DropoutPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0001775639902916737
STAT match_ExpandBroadcastPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0001969820004887879
STAT match_ExpandPattern +0 -0 #it=8 maxmatch=2 i=0 - time=0.0002937300014309585
STAT match_ExpandSwapPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.00019026400696020573
STAT match_FastGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002177159913117066
STAT match_FunctionAttentionGQAPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003811080168816261
STAT match_FunctionAttentionPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0014863910037092865
STAT match_FunctionCausalMaskMulAddPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000313991004077252
STAT match_FunctionCausalMaskPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002463549972162582
STAT match_FunctionCosSinCachePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021250700228847563
STAT match_FunctionHalfRotaryEmbeddingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002039320024778135
STAT match_FusedConvPattern +0 -0 #it=3 maxmatch=0 i=0 - time=8.83270040503703e-05
STAT match_FusedMatMulDivPattern +0 -0 #it=3 maxmatch=2 i=0 - time=0.00020081800903426483
STAT match_FusedMatMulPattern +0 -0 #it=3 maxmatch=2 i=2 - time=0.00048233500274363905
STAT match_FusedMatMulTransposePattern +0 -0 #it=1 maxmatch=0 i=0 - time=0.00011378400085959584
STAT match_FusedMatMulx2Pattern +0 -0 #it=1 maxmatch=0 i=0 - time=9.085299825528637e-05
STAT match_GathersSplitPattern +0 -0 #it=6 maxmatch=0 i=0 - time=0.0002626529967528768
STAT match_GeluErfPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.003265564992034342
STAT match_GeluOrtPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.003978441010985989
STAT match_GeluPattern +0 -0 #it=8 maxmatch=2 i=0 - time=8.243005140684545e-06
STAT match_GemmTransposePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00019486799283185974
STAT match_GroupQueryAttention3DPattern +0 -0 #it=3 maxmatch=0 i=0 - time=0.00011627699859673157
STAT match_IdentityPattern +0 -0 #it=8 maxmatch=6 i=4 - time=0.0034807730044121854
STAT match_LayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=2 - time=0.00043891699897358194
STAT match_LayerNormalizationScalePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00023871299345046282
STAT match_LeakyReluPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.004011420016468037
STAT match_MatMulAddPattern +0 -0 #it=1 maxmatch=0 i=0 - time=8.423200051765889e-05
STAT match_MatMulReshape2Of3Pattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.001080175003153272
STAT match_MissingCosSinPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002653400006238371
STAT match_MissingRangePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021976999414619058
STAT match_MissingReduceMaxPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022433100821217522
STAT match_MissingTopKPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00025139900390058756
STAT match_MulMulMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0004922000007354654
STAT match_MulMulMulScalarPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002542769943829626
STAT match_MultiHeadAttention3DPattern +0 -0 #it=3 maxmatch=2 i=0 - time=0.0001642420029384084
STAT match_NotNotPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0001914429885800928
STAT match_NotWherePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00018558299052529037
STAT match_OrtBatchNormalizationTrainingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0003982310008723289
STAT match_QuickGeluPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021956599812256172
STAT match_RMSNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00019225399591960013
STAT match_RMSNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00020280000171624124
STAT match_ReduceArgTopKPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022197000362211838
STAT match_ReduceReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002507500030333176
STAT match_ReduceSumNormalizePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00018912400992121547
STAT match_Reshape2Of3Pattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0007343459947151132
STAT match_ReshapeGemmPattern +0 -0 #it=1 maxmatch=0 i=0 - time=2.997800038428977e-05
STAT match_ReshapeGemmReshapePattern +0 -0 #it=1 maxmatch=0 i=0 - time=2.693499845918268e-05
STAT match_ReshapeMatMulReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0004933130039717071
STAT match_ReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00030413500644499436
STAT match_ReshapeReshapeBinaryPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00045125799806555733
STAT match_ReshapeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003016780101461336
STAT match_RotaryConcatPartPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0004875790109508671
STAT match_RotaryEmbeddingPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00022467200324172154
STAT match_SameChildrenFromInputPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0006565860021510161
STAT match_SameChildrenPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0013903679937357083
STAT match_SequenceConstructAtPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002331449941266328
STAT match_ShapeBasedConcatExpandPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00021523699251702055
STAT match_ShapeBasedEditDistanceReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00028336900868453085
STAT match_ShapeBasedExpandBroadcastMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0006248749850783497
STAT match_ShapeBasedExpandBroadcastPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000579297004151158
STAT match_ShapeBasedExpandCastWhereSwapPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002832770114764571
STAT match_ShapeBasedExpandSwapPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000693285015586298
STAT match_ShapeBasedIdentityPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00032220200955634937
STAT match_ShapeBasedMatMulToMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0007400510148727335
STAT match_ShapeBasedReshapeIsSqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004116850032005459
STAT match_ShapeBasedSameChildrenPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003413759986869991
STAT match_ShapeBasedShapeShapeAddPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004142869947827421
STAT match_ShapeBasedStaticExpandPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0002988049964187667
STAT match_ShapedBasedReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003461660089669749
STAT match_SimplifiedLayerNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000301182983093895
STAT match_SimplifiedLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00039626099169254303
STAT match_SkipLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=2 - time=0.00027409198810346425
STAT match_SkipSimplifiedLayerNormalizationMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00028284400468692183
STAT match_SkipSimplifiedLayerNormalizationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002075140000670217
STAT match_SliceSlicePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002362770028412342
STAT match_SlicesSplitPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002739189949352294
STAT match_SoftmaxCrossEntropyLossCastPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.005445867995149456
STAT match_SoftmaxGradPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002443630000925623
STAT match_SplitConcatPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000332327006617561
STAT match_SqueezeAddPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00048581101145828143
STAT match_SqueezeBinaryUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00032259499130304903
STAT match_SqueezeUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00033409999014111236
STAT match_StaticConcatReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0002990829962072894
STAT match_Sub1MulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002516960012144409
STAT match_SwapExpandReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00039179901068564504
STAT match_SwapRangeAddScalarPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0002471970146871172
STAT match_SwapUnaryPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00048597600834909827
STAT match_SwapUnsqueezeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004732509914902039
STAT match_SwitchOrderBinaryPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0006613340010517277
STAT match_SwitchReshapeActivationPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00036211300175637007
STAT match_TransposeEqualReshapePattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0003489570153760724
STAT match_TransposeFusedMatMulBPattern +0 -0 #it=1 maxmatch=0 i=0 - time=0.00014889500016579404
STAT match_TransposeGatherPattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004976970012648962
STAT match_TransposeMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.0004932349911541678
STAT match_TransposeReshapeMatMulPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00048223399790003896
STAT match_TransposeReshapeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003626409961725585
STAT match_TransposeTransposePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003360579939908348
STAT match_UnsqueezeEqualPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.000418407995312009
STAT match_UnsqueezeOrSqueezeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.00029855100001441315
STAT match_UnsqueezeReshapePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0003244840117986314
STAT match_UnsqueezeUnsqueezePattern +0 -0 #it=8 maxmatch=6 i=0 - time=0.0004890339841949753
STAT match_WhereAddPattern +0 -0 #it=6 maxmatch=2 i=0 - time=0.00034541900822659954
STAT remove_duplicated_shape +0 -0 #it=8 maxmatch=0 i=0 - time=7.171400648076087e-05
STAT remove_identity_nodes +9 -15 #it=8 maxmatch=0 i=0 - time=0.002848258001904469
STAT remove_unused +0 -0 #it=8 maxmatch=0 i=0 - time=0.002574593003373593
--MODEL: 29 nodes, 1 inputs, 1 outputs, 21 initializers--
INPUT: 1 x 7t
INPUT-SEQ: 1 x Falset
OUTPUT: 1 x 1t
OUTPUT-SEQ: 1 x Falset
INIT: 21 x 1t
NODE: 4 x Add
NODE: 1 x Concat
NODE: 2 x Equal
NODE: 2 x Gather
NODE: 11 x MatMul
NODE: 1 x Relu
NODE: 2 x Softmax
NODE: 2 x Where
NODE: 2 x com.microsoft.FusedMatMul
NODE: 2 x com.microsoft.SkipLayerNormalization
--MODEL: 29 nodes, 1 inputs, 1 outputs, 21 initializers--DETAILED--
INPUT: 1 x 7t[1x30]
OUTPUT: 1 x 1t[1x30x16]
INIT: 2 x 1t[1024x16]
INIT: 1 x 1t[128]
INIT: 1 x 1t[128x16]
INIT: 4 x 1t[16]
INIT: 1 x 1t[16x128]
INIT: 6 x 1t[16x16]
INIT: 3 x 1t[1]
INIT: 2 x 1t[30x30]
INIT: 1 x 1t[32x16]
NODE: 1 x Add -SIG- 1t[1x30x128], 1t[128]
NODE: 2 x Add -SIG- 1t[1x30x16], 1t[16]
NODE: 1 x Add -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 1 x Concat -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 2 x Equal -SIG- 1t[30x30], 1t[1]
NODE: 2 x Gather -SIG- 1t[1024x16], 7t[1x30]
NODE: 1 x MatMul -SIG- 1t[1x30x128], 1t[128x16]
NODE: 1 x MatMul -SIG- 1t[1x30x16], 1t[16x128]
NODE: 6 x MatMul -SIG- 1t[1x30x16], 1t[16x16]
NODE: 2 x MatMul -SIG- 1t[1x30x30], 1t[1x30x16]
NODE: 1 x MatMul -SIG- 1t[1x30x32], 1t[32x16]
NODE: 1 x Relu -SIG- 1t[1x30x128]
NODE: 2 x Softmax -SIG- 1t[1x30x30]
NODE: 2 x Where -SIG- 9t[30x30], 1t[1], 1t[1x30x30]
NODE: 2 x com.microsoft.FusedMatMul -SIG- 1t[1x30x16], 1t[1x30x16]
NODE: 2 x com.microsoft.SkipLayerNormalization -SIG- 1t[1x30x16], 1t[1x30x16], 1t[16], 1t[16]
[GraphBuilder-KSU.remove_unused] remove_initializer 1:15/21:init1_s_2::RSh12:float32[(1,)]
[OrderOptimization.optimize] ALGO-2
[OrderOptimization.random_order] -- starts with 29 nodes, 20 initializers
[OrderOptimization.shape_order] done after in 0.00021615599689539522s with changed=0 scale=0
[GraphBuilder-KSU.optimize] done with 29 nodes in 0.094
opset: domain='' version=18
opset: domain='com.microsoft' version=1
input: name='input_ids' type=dtype('int64') shape=[1, 30]
init: name='init1_s1_3' type=float32 shape=(1,) -- array([-inf], dtype=float32)-- Opset.make_node.1/Small##Opset.make_node.1/Small
init: name='p_decoder_attention_attention_0_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_query_weight)##p_decoder_attention_attention_0_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.query.weight)
init: name='p_decoder_attention_attention_0_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_key_weight)##p_decoder_attention_attention_0_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.key.weight)
init: name='p_decoder_attention_attention_0_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_0_value_weight)##p_decoder_attention_attention_0_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.0.value.weight)
init: name='slice_2' type=float32 shape=(30, 30) -- GraphBuilder.constant_folding.from/fold(init7_s1_0,init7_s1_1,init7_s1_30,slice_1)##slice_1/GraphBuilder.constant_folding.from/fold(b_decoder_attention_attention_0_mask,init7_s1_0,init7_s1_30)##b_decoder_attention_attention_0_mask/DynamoInterpret.placeholder.0##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='init1_s_2::RSh1' type=float32 shape=(1,) -- array([0.], dtype=float32)-- GraphBuilder.constant_folding.from/fold(init1_s_2,init7_s1_1)##init1_s_2/shape_type_compute._cast_inputs.0##shape_type_compute._cast_inputs.0##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='p_decoder_attention_attention_1_query_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_query_weight)##p_decoder_attention_attention_1_query_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.query.weight)
init: name='p_decoder_attention_attention_1_key_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_key_weight)##p_decoder_attention_attention_1_key_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.key.weight)
init: name='p_decoder_attention_attention_1_value_weight::T10' type=float32 shape=(16, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_attention_1_value_weight)##p_decoder_attention_attention_1_value_weight/DynamoInterpret.placeholder.1/P(decoder.attention.attention.1.value.weight)
init: name='slice_4' type=float32 shape=(30, 30) -- GraphBuilder.constant_folding.from/fold(init7_s1_0,init7_s1_1,init7_s1_30,slice_3)##slice_3/GraphBuilder.constant_folding.from/fold(b_decoder_attention_attention_1_mask,init7_s1_0,init7_s1_30)##b_decoder_attention_attention_1_mask/DynamoInterpret.placeholder.0##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_0/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_30/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##init7_s1_1/Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape##Opset.make_node.1/Shape
init: name='p_decoder_attention_linear_weight::T10' type=float32 shape=(32, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_attention_linear_weight)##p_decoder_attention_linear_weight/DynamoInterpret.placeholder.1/P(decoder.attention.linear.weight)
init: name='p_decoder_feed_forward_linear_1_weight::T10' type=float32 shape=(16, 128)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_1_weight)##p_decoder_feed_forward_linear_1_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.weight)
init: name='p_decoder_feed_forward_linear_2_weight::T10' type=float32 shape=(128, 16)-- GraphBuilder.constant_folding.from/fold(p_decoder_feed_forward_linear_2_weight)##p_decoder_feed_forward_linear_2_weight/DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.weight)
init: name='init1_s16_' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.scale##LayerNormalizationPattern.apply.scale
init: name='init1_s16_2' type=float32 shape=(16,) -- LayerNormalizationPattern.apply.bias##LayerNormalizationPattern.apply.bias
init: name='embedding.embedding.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.embedding.weight)
init: name='embedding.pe.weight' type=float32 shape=(1024, 16) -- DynamoInterpret.placeholder.1/P(embedding.pe.weight)
init: name='decoder.attention.linear.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(decoder.attention.linear.bias)
init: name='decoder.feed_forward.linear_1.bias' type=float32 shape=(128,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_1.bias)
init: name='decoder.feed_forward.linear_2.bias' type=float32 shape=(16,)-- DynamoInterpret.placeholder.1/P(decoder.feed_forward.linear_2.bias)
Equal(slice_2, init1_s_2::RSh1) -> eq
Gather(embedding.embedding.weight, input_ids) -> embedding
Gather(embedding.pe.weight, input_ids) -> embedding_1
SkipLayerNormalization[com.microsoft](embedding, embedding_1, init1_s16_, init1_s16_2, epsilon=0.00) -> _onx_div_sub_add, unused, unused2, add
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_query_weight::T10) -> linear
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_key_weight::T10) -> linear_1
FusedMatMul[com.microsoft](linear, linear_1, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul
Where(eq, init1_s1_3, _onx_mul_matmul) -> masked_fill
Softmax(masked_fill, axis=-1) -> softmax
MatMul(_onx_div_sub_add, p_decoder_attention_attention_0_value_weight::T10) -> linear_2
MatMul(softmax, linear_2) -> matmul_1
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_query_weight::T10) -> linear_3
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_key_weight::T10) -> linear_4
FusedMatMul[com.microsoft](linear_3, linear_4, alpha=0.25, transA=0, transB=1, transBatchA=0, transBatchB=0) -> _onx_mul_matmul_2
MatMul(_onx_div_sub_add, p_decoder_attention_attention_1_value_weight::T10) -> linear_5
Equal(slice_4, init1_s_2::RSh1) -> eq_1
Where(eq_1, init1_s1_3, _onx_mul_matmul_2) -> masked_fill_1
Softmax(masked_fill_1, axis=-1) -> softmax_1
MatMul(softmax_1, linear_5) -> matmul_3
Concat(matmul_1, matmul_3, axis=-1) -> cat
MatMul(cat, p_decoder_attention_linear_weight::T10) -> _onx_matmul_cat
Add(_onx_matmul_cat, decoder.attention.linear.bias) -> linear_6
SkipLayerNormalization[com.microsoft](linear_6, add, init1_s16_, init1_s16_2, epsilon=0.00) -> _onx_div_sub_add_1, unused3, unused4, add_1
MatMul(_onx_div_sub_add_1, p_decoder_feed_forward_linear_1_weight::T10) -> _onx_matmul_layer_norm_1
Add(_onx_matmul_layer_norm_1, decoder.feed_forward.linear_1.bias) -> linear_7
Relu(linear_7) -> relu
MatMul(relu, p_decoder_feed_forward_linear_2_weight::T10) -> _onx_matmul_relu
Add(_onx_matmul_relu, decoder.feed_forward.linear_2.bias) -> linear_8
Add(linear_8, add_1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 30, 16]
Comparison optimized and not optimized?¶
The following tools is trying to match the node and shape inference from two models. If they are not too different, the functions is able to find out the differences. We can use to see which operators were fused into bigger ones only implemented by onnxruntime.
res1, res2, align, dc = compare_onnx_execution(
onx, onx_optimized, verbose=1, cls=ExtendedReferenceEvaluator
)
print("------------")
text = dc.to_str(res1, res2, align)
print(text)
[compare_onnx_execution] generate inputs
[compare_onnx_execution] execute with 1 inputs
[compare_onnx_execution] execute first model
[compare_onnx_execution] got 66 results
[compare_onnx_execution] execute second model
[compare_onnx_execution] got 66 results (first model)
[compare_onnx_execution] got 57 results (second model)
[compare_onnx_execution] compute edit distance
[compare_onnx_execution] got 66 pairs
[compare_onnx_execution] done
------------
001 ~ | INITIA float32 2:256x256 AOCQ b_ | INITIA float32 1:1 ?AAA in
002 - | INITIA float32 2:256x256 AOCQ b_ |
003 - | INITIA int64 1:1 BAAA in |
004 - | INITIA int64 1:1 AAAA in |
005 - | INITIA int64 1:1 EAAA in |
006 ~ | INITIA float32 1:1 ?AAA in | INITIA float32 2:16x16 BAAB p_
007 ~ | INITIA float32 2:16x16 BAAB p_ | INITIA float32 2:16x16 AAAD p_
008 ~ | INITIA float32 2:16x16 AAAD p_ | INITIA float32 2:16x16 ZYBA p_
009 ~ | INITIA float32 2:16x16 ZYBA p_ | INITIA float32 2:30x30 KGSP sl
010 = | INITIA float32 1:1 AAAA in | INITIA float32 1:1 AAAA in
011 ~ | INITIA float32 1:1 AAAA in | INITIA float32 2:16x16 ABZY p_
012 ~ | INITIA float32 2:16x16 ABZY p_ | INITIA float32 2:16x16 AAAB p_
013 ~ | INITIA float32 2:16x16 AAAB p_ | INITIA float32 2:16x16 AYDB p_
014 ~ | INITIA float32 2:16x16 AYDB p_ | INITIA float32 2:30x30 KGSP sl
015 = | INITIA float32 2:32x16 YAAB p_ | INITIA float32 2:32x16 YAAB p_
016 = | INITIA float32 2:16x128 ZXCD p_ | INITIA float32 2:16x128 ZXCD p_
017 = | INITIA float32 2:128x16 AACA p_ | INITIA float32 2:128x16 AACA p_
018 = | INITIA float32 1:16 EEEE in | INITIA float32 1:16 EEEE in
019 = | INITIA float32 1:16 AAAA in | INITIA float32 1:16 AAAA in
020 = | INITIA float32 2:1024x16 EXPH em | INITIA float32 2:1024x16 EXPH em
021 = | INITIA float32 2:1024x16 PGMP em | INITIA float32 2:1024x16 PGMP em
022 = | INITIA float32 1:16 AAAA de | INITIA float32 1:16 AAAA de
023 = | INITIA float32 1:128 AAAB de | INITIA float32 1:128 AAAB de
024 = | INITIA float32 1:16 AAAA de | INITIA float32 1:16 AAAA de
025 = | INPUT int64 2:1x30 COAD in | INPUT int64 2:1x30 COAD in
026 - | RESULT int64 1:2 ABAA Concat Sl |
027 - | RESULT int64 1:2 EEAA Concat Sl |
028 - | RESULT int64 1:2 AAAA Concat Sl |
029 = | RESULT float32 3:1x30x16 LFVS Gather em | RESULT float32 3:1x30x16 LFVS Gather em
030 = | RESULT float32 3:1x30x16 OREZ Gather em | RESULT float32 3:1x30x16 OREZ Gather em
031 ~ | RESULT float32 3:1x30x16 ZXAR Add ad | RESULT float32 3:1x30x16 ZBXD SkipLayerNormal _o
032 ~ | RESULT float32 3:1x30x16 ZBXD LayerNormalizat _o | RESULT float32 3:1x30x1 ABAZ SkipLayerNormal un
033 ~ | RESULT float32 3:1x30x16 UBZF MatMul li | RESULT float32 3:1x30x1 GGGE SkipLayerNormal un
034 ~ | RESULT float32 3:1x30x16 AEEC MatMul li | RESULT float32 3:1x30x16 ZXAR SkipLayerNormal ad
035 ~ | RESULT float32 3:1x30x16 THYD MatMul li | RESULT float32 3:1x30x16 UBZF MatMul li
036 ~ | RESULT float32 3:1x16x30 PHII Transpose tr | RESULT float32 3:1x30x16 AEEC MatMul li
037 ~ | RESULT float32 3:1x30x30 RSPV MatMul ma | RESULT float32 3:1x30x30 YEDF FusedMatMul _o
038 ~ | RESULT float32 3:1x30x30 YEDF Mul _o | RESULT float32 3:1x30x16 THYD MatMul li
039 - | RESULT float32 2:30x30 KGSP Slice sl |
040 = | RESULT bool 2:30x30 HLZC Equal eq | RESULT bool 2:30x30 HLZC Equal eq
041 = | RESULT float32 3:1x30x30 ???? Where ma | RESULT float32 3:1x30x30 ???? Where ma
042 = | RESULT float32 3:1x30x30 IHHH Softmax so | RESULT float32 3:1x30x30 IHHH Softmax so
043 = | RESULT float32 3:1x30x16 YYAA MatMul ma | RESULT float32 3:1x30x16 YYAA MatMul ma
044 = | RESULT float32 3:1x30x16 GCMB MatMul li | RESULT float32 3:1x30x16 GCMB MatMul li
045 = | RESULT float32 3:1x30x16 UAXB MatMul li | RESULT float32 3:1x30x16 UAXB MatMul li
046 ~ | RESULT float32 3:1x30x16 CFBZ MatMul li | RESULT float32 3:1x30x30 AXEA FusedMatMul _o
047 ~ | RESULT float32 3:1x16x30 URBH Transpose tr | RESULT float32 3:1x30x16 CFBZ MatMul li
048 ~ | RESULT float32 3:1x30x30 BOQB MatMul ma | RESULT bool 2:30x30 HLZC Equal eq
049 ~ | RESULT float32 3:1x30x30 AXEA Mul _o | RESULT float32 3:1x30x30 ???? Where ma
050 ~ | RESULT float32 2:30x30 KGSP Slice sl | RESULT float32 3:1x30x30 IHHH Softmax so
051 - | RESULT bool 2:30x30 HLZC Equal eq |
052 ~ | RESULT float32 3:1x30x30 ???? Where ma | RESULT float32 3:1x30x16 QEDB MatMul ma
053 ~ | RESULT float32 3:1x30x30 IHHH Softmax so | RESULT float32 3:1x30x32 MDDD Concat ca
054 ~ | RESULT float32 3:1x30x16 QEDB MatMul ma | RESULT float32 3:1x30x16 VAAA MatMul _o
055 ~ | RESULT float32 3:1x30x32 MDDD Concat ca | RESULT float32 3:1x30x16 SXYX Add li
056 ~ | RESULT float32 3:1x30x16 VAAA MatMul _o | RESULT float32 3:1x30x16 AAXD SkipLayerNormal _o
057 ~ | RESULT float32 3:1x30x16 SXYX Add li | RESULT float32 3:1x30x1 ABAZ SkipLayerNormal un
058 ~ | RESULT float32 3:1x30x16 QUXO Add ad | RESULT float32 3:1x30x1 GGGE SkipLayerNormal un
059 ~ | RESULT float32 3:1x30x16 AAXD LayerNormalizat _o | RESULT float32 3:1x30x16 QUXO SkipLayerNormal ad
060 = | RESULT float32 3:1x30x128 SBXL MatMul _o | RESULT float32 3:1x30x128 SBXL MatMul _o
061 = | RESULT float32 3:1x30x128 CNGY Add li | RESULT float32 3:1x30x128 CNGY Add li
062 = | RESULT float32 3:1x30x128 GDQJ Relu re | RESULT float32 3:1x30x128 GDQJ Relu re
063 = | RESULT float32 3:1x30x16 DGGD MatMul _o | RESULT float32 3:1x30x16 DGGD MatMul _o
064 = | RESULT float32 3:1x30x16 EHIE Add li | RESULT float32 3:1x30x16 EHIE Add li
065 = | RESULT float32 3:1x30x16 VBES Add ou | RESULT float32 3:1x30x16 VBES Add ou
066 = | OUTPUT float32 3:1x30x16 VBES ou | OUTPUT float32 3:1x30x16 VBES ou
The conversion should handle dynamic shapes as well as the input sequence can be of any length. But that’s a topic for another example.
Total running time of the script: (0 minutes 2.673 seconds)
Related examples

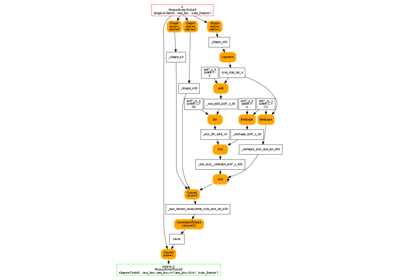
to_onnx and padding one dimension to a mulitple of a constant

to_onnx and a custom operator registered with a function