Note
Go to the end to download the full example code.
201: Evaluate DORT Training¶
It compares DORT to eager mode and onnxrt backend.
To run the script:
python _doc/examples/plot_torch_aot --help
Some helpers¶
import warnings
try:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
import onnxruntime
has_cuda = "CUDAExecutionProvider" in onnxruntime.get_available_providers()
except ImportError:
print("onnxruntime not available.")
import sys
sys.exit(0)
import torch._dynamo
import contextlib
import itertools
import os
import gc
import platform
# import pickle
import pprint
import multiprocessing
import time
import cProfile
import pstats
import io
import logging
from pstats import SortKey
import numpy as np
import matplotlib.pyplot as plt
import pandas
import onnx
from onnx_array_api.profiling import profile2graph
import torch
from torch import nn
import torch.nn.functional as F
import experimental_experiment
from experimental_experiment.plotting.memory import memory_peak_plot
from experimental_experiment.ext_test_case import measure_time, get_figure
from experimental_experiment.args import get_parsed_args
from experimental_experiment.memory_peak import start_spying_on
from experimental_experiment.torch_models.training_helper import make_aot_ort
from tqdm import tqdm
has_cuda = has_cuda and torch.cuda.device_count() > 0
logging.disable(logging.ERROR)
def system_info():
obs = {}
obs["processor"] = platform.processor()
obs["cores"] = multiprocessing.cpu_count()
try:
obs["cuda"] = 1 if torch.cuda.device_count() > 0 else 0
obs["cuda_count"] = torch.cuda.device_count()
obs["cuda_name"] = torch.cuda.get_device_name()
obs["cuda_capa"] = torch.cuda.get_device_capability()
except (RuntimeError, AssertionError):
# no cuda
pass
return obs
pprint.pprint(system_info())
{'cores': 20,
'cuda': 1,
'cuda_capa': (8, 9),
'cuda_count': 1,
'cuda_name': 'NVIDIA GeForce RTX 4060 Laptop GPU',
'processor': 'x86_64'}
Scripts arguments
script_args = get_parsed_args(
"plot_torch_aot",
description=__doc__,
scenarios={
"small": "small model to test",
"middle": "55Mb model",
"large": "1Gb model",
},
warmup=5,
repeat=5,
repeat1=(1, "repeat for the first iteration"),
maxtime=(
2,
"maximum time to run a model to measure the computation time, "
"it is 0.1 when scenario is small",
),
expose="scenarios,repeat,repeat1,warmup",
)
if script_args.scenario in (None, "small"):
script_args.maxtime = 0.1
print(f"scenario={script_args.scenario or 'small'}")
print(f"warmup={script_args.warmup}")
print(f"repeat={script_args.repeat}")
print(f"repeat1={script_args.repeat1}")
print(f"maxtime={script_args.maxtime}")
scenario=small
warmup=5
repeat=5
repeat1=1
maxtime=0.1
The model¶
A simple model to convert.
class MyModelClass(nn.Module):
def __init__(self, scenario=script_args.scenario):
super().__init__()
if scenario == "middle":
self.large = False
self.conv1 = nn.Conv2d(1, 32, 5)
# self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(30752, 1024)
self.fcs = []
self.fc2 = nn.Linear(1024, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "small"):
self.large = False
self.conv1 = nn.Conv2d(1, 16, 5)
# self.conv2 = nn.Conv2d(16, 16, 5)
self.fc1 = nn.Linear(144, 512)
self.fcs = []
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "large"):
self.large = True
self.conv1 = nn.Conv2d(1, 32, 5)
# self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(30752, 4096)
# torch script does not support loops.
self.fca = nn.Linear(4096, 4096)
self.fcb = nn.Linear(4096, 4096)
self.fcc = nn.Linear(4096, 4096)
self.fcd = nn.Linear(4096, 4096)
self.fce = nn.Linear(4096, 4096)
self.fcf = nn.Linear(4096, 4096)
self.fcg = nn.Linear(4096, 4096)
self.fch = nn.Linear(4096, 4096)
self.fci = nn.Linear(4096, 4096)
# end of the unfolded loop.
self.fc2 = nn.Linear(4096, 128)
self.fc3 = nn.Linear(128, 10)
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (4, 4))
# x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
if self.large:
# loop
x = F.relu(self.fca(x))
x = F.relu(self.fcb(x))
x = F.relu(self.fcc(x))
x = F.relu(self.fcd(x))
x = F.relu(self.fce(x))
x = F.relu(self.fcf(x))
x = F.relu(self.fcg(x))
x = F.relu(self.fch(x))
x = F.relu(self.fci(x))
# end of the loop
x = F.relu(self.fc2(x))
y = self.fc3(x)
return y
def create_model_and_input(scenario=script_args.scenario):
if scenario == "middle":
shape = [1, 1, 128, 128]
elif scenario in (None, "small"):
shape = [1, 1, 16, 16]
elif scenario == "large":
shape = [1, 1, 128, 128]
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
input_tensor = torch.rand(*shape).to(torch.float32)
y = torch.rand((1, 10)).to(torch.float32)
model = MyModelClass(scenario=scenario)
assert model(input_tensor) is not None
return model, (input_tensor, y)
def torch_model_size(model):
size_model = 0
for param in model.parameters():
size = param.numel() * torch.finfo(param.data.dtype).bits / 8
size_model += size
return size_model
model, input_tensors = create_model_and_input()
model_size = torch_model_size(model)
print(f"model size={model_size / 2 ** 20} Mb")
model size=0.5401992797851562 Mb
Backends¶
def run(model, tensor_x, tensor_y):
tensor_x = tensor_x.detach()
tensor_y = tensor_y.detach()
for param in model.parameters():
param.grad = None
try:
output = model(tensor_x)
except Exception as e:
raise AssertionError(f"issue with {type(tensor_x)}") from e
loss = F.mse_loss(output, tensor_y)
# return loss
def _backward_():
loss.backward()
_backward_()
return loss, (param.grad for param in model.parameters())
def get_torch_eager(model, *args):
def my_compiler(gm, example_inputs):
return gm.forward
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
optimized_mod = torch.compile(model, fullgraph=True, backend=my_compiler)
assert run(optimized_mod, *args)
return optimized_mod
def get_torch_default(model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
optimized_mod = torch.compile(model, fullgraph=True, mode="reduce-overhead")
assert run(optimized_mod, *args)
return optimized_mod
def get_torch_dort(model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
local_aot_ort, _ = make_aot_ort(dynamic=True, rewrite=True)
optimized_mod = torch.compile(model, backend=local_aot_ort, fullgraph=True)
run(optimized_mod, *args)
assert run(optimized_mod, *args)
return optimized_mod
Let’s check they are working.
export_functions = [
get_torch_eager,
get_torch_default,
get_torch_dort,
]
exporters = {f.__name__.replace("get_", ""): f for f in export_functions}
supported_exporters = {}
for k, v in exporters.items():
print(f"run function {k}")
filename = f"plot_torch_aot_{k}.onnx"
torch._dynamo.reset()
model, input_tensors = create_model_and_input()
try:
run(model, *input_tensors)
except Exception as e:
print(f"skipped due to {str(e)[:1000]}") # noqa: F821
continue
supported_exporters[k] = v
del model
gc.collect()
time.sleep(1)
run function torch_eager
run function torch_default
run function torch_dort
Compile and Memory¶
def flatten(ps):
obs = ps["cpu"].to_dict(unit=2**20)
if "gpus" in ps:
for i, g in enumerate(ps["gpus"]):
for k, v in g.to_dict(unit=2**20).items():
obs[f"gpu{i}_{k}"] = v
return obs
data = []
for k in supported_exporters:
print(f"run compile for memory {k} on cpu")
filename = f"plot_torch_aot_{k}.onnx"
if has_cuda:
torch.cuda.set_device(0)
torch._dynamo.reset()
# CPU
model, input_tensors = create_model_and_input()
stat = start_spying_on(cuda=1 if has_cuda else 0)
run(model, *input_tensors)
obs = flatten(stat.stop())
print("done.")
obs.update(dict(export=k, p="cpu"))
data.append(obs)
del model
gc.collect()
time.sleep(1)
if not has_cuda:
continue
torch._dynamo.reset()
# CUDA
model, input_tensors = create_model_and_input()
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
print(f"run compile for memory {k} on cuda")
stat = start_spying_on(cuda=1 if has_cuda else 0)
run(model, *input_tensors)
obs = flatten(stat.stop())
print("done.")
obs.update(dict(export=k, p="cuda"))
data.append(obs)
del model
gc.collect()
time.sleep(1)
run compile for memory torch_eager on cpu
done.
run compile for memory torch_eager on cuda
done.
run compile for memory torch_default on cpu
done.
run compile for memory torch_default on cuda
done.
run compile for memory torch_dort on cpu
done.
run compile for memory torch_dort on cuda
done.
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_aot_1_memory.csv", index=False)
df1.to_excel("plot_torch_aot_1_memory.xlsx", index=False)
print(df1)
for p in ["cpu", "cuda"]:
if not has_cuda and p == "cuda":
continue
ax = memory_peak_plot(
df1[df1["p"] == p],
key=("export",),
bars=[model_size * i / 2**20 for i in range(1, 5)],
suptitle=f"Memory Consumption of the Compilation on {p}\n"
f"model size={model_size / 2**20:1.0f} Mb",
)
get_figure(ax).savefig(f"plot_torch_aot_1_memory_{p}.png")
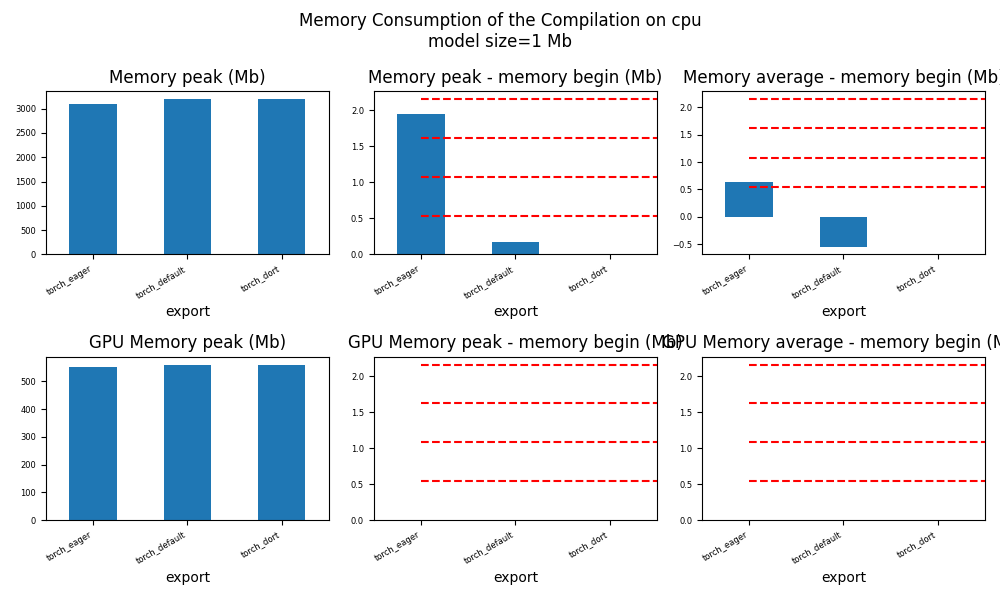
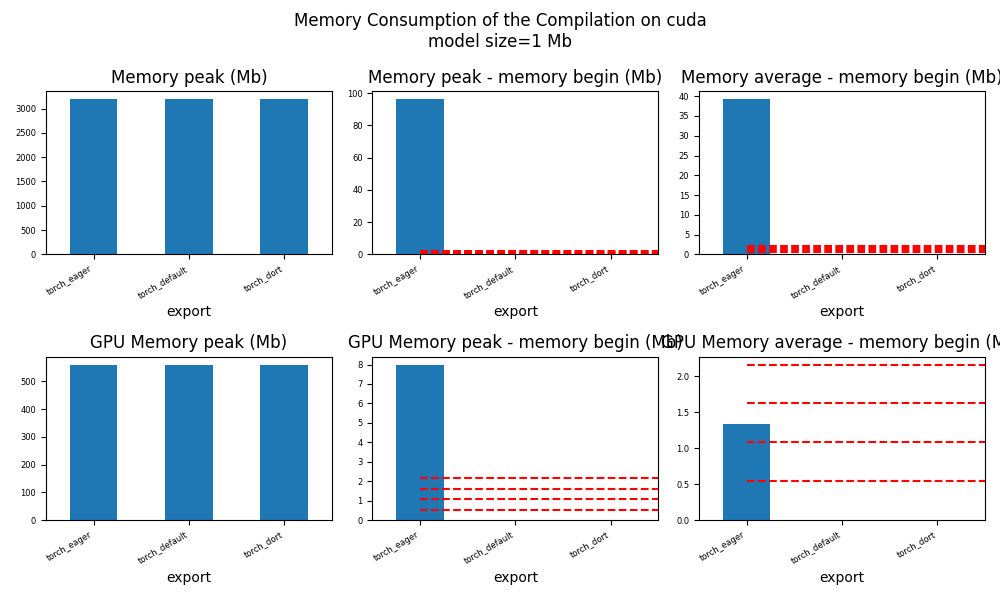
peak mean n begin end gpu0_peak gpu0_mean gpu0_n gpu0_begin gpu0_end export p
0 6689.011719 6687.843750 5 6689.011719 6687.082031 1627.617188 1627.617188 5 1627.617188 1627.617188 torch_eager cpu
1 6690.183594 6688.385156 5 6687.089844 6690.183594 1655.617188 1648.417187 5 1627.617188 1655.617188 torch_eager cuda
2 6692.156250 6690.670898 4 6692.156250 6690.175781 1655.617188 1655.617188 4 1655.617188 1655.617188 torch_default cpu
3 6692.226562 6692.193359 2 6692.160156 6692.226562 1655.617188 1655.617188 2 1655.617188 1655.617188 torch_default cuda
4 6692.222656 6691.231445 4 6690.242188 6692.222656 1655.617188 1655.617188 4 1655.617188 1655.617188 torch_dort cpu
5 6690.242188 6690.242188 3 6690.242188 6690.242188 1655.617188 1655.617188 3 1655.617188 1655.617188 torch_dort cuda
dort first iteration speed¶
data = []
for k in supported_exporters:
print(f"run dort cpu {k}: {script_args.repeat1}")
times = []
for _ in range(int(script_args.repeat1)):
model, input_tensors = create_model_and_input()
torch._dynamo.reset()
begin = time.perf_counter()
run(model, *input_tensors)
duration = time.perf_counter() - begin
times.append(duration)
del model
gc.collect()
time.sleep(1)
print(f"done: {times[-1]}")
data.append(
dict(
export=k,
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
p="cpu",
)
)
if not has_cuda:
continue
print(f"run dort cuda {k}: {script_args.repeat1}")
times = []
for i in range(int(script_args.repeat1)):
model, input_tensors = create_model_and_input()
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
torch._dynamo.reset()
begin = time.perf_counter()
run(model, *input_tensors)
duration = time.perf_counter() - begin
times.append(duration)
del model
gc.collect()
time.sleep(1)
print(f"done: {times[-1]}")
data.append(
dict(
export=k,
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
p="cuda",
)
)
run dort cpu torch_eager: 1
done: 0.003287102998001501
run dort cuda torch_eager: 1
done: 0.0035699260006367695
run dort cpu torch_default: 1
done: 0.002399967997916974
run dort cuda torch_default: 1
done: 0.003152430999762146
run dort cpu torch_dort: 1
done: 0.0028190020020701922
run dort cuda torch_dort: 1
done: 0.0026354479996371083
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_aot_1_time.csv", index=False)
df1.to_excel("plot_torch_aot_1_time.xlsx", index=False)
print(df1)
fig, ax = plt.subplots(1, 1)
dfi = df1[["export", "p", "time", "std"]].set_index(["export", "p"])
dfi["time"].plot.bar(ax=ax, title="Compilation time", yerr=dfi["std"], rot=30)
fig.tight_layout()
fig.savefig("plot_torch_aot_1_time.png")
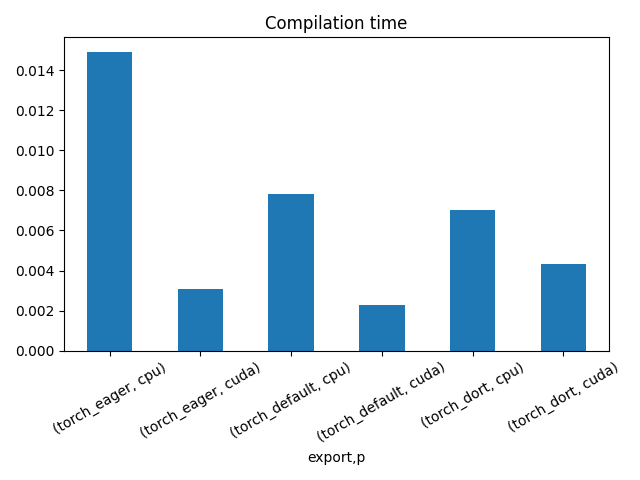
export time min max first last std p
0 torch_eager 0.003287 0.003287 0.003287 0.003287 0.003287 0.0 cpu
1 torch_eager 0.003570 0.003570 0.003570 0.003570 0.003570 0.0 cuda
2 torch_default 0.002400 0.002400 0.002400 0.002400 0.002400 0.0 cpu
3 torch_default 0.003152 0.003152 0.003152 0.003152 0.003152 0.0 cuda
4 torch_dort 0.002819 0.002819 0.002819 0.002819 0.002819 0.0 cpu
5 torch_dort 0.002635 0.002635 0.002635 0.002635 0.002635 0.0 cuda
Compilation Profiling¶
def clean_text(text):
pathes = [
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(torch.__file__), ".."))),
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(onnx.__file__), ".."))),
os.path.abspath(
os.path.normpath(
os.path.join(os.path.dirname(experimental_experiment.__file__), "..")
)
),
]
for p in pathes:
text = text.replace(p, "")
text = text.replace("experimental_experiment", "experimental_experiment".upper())
return text
def profile_function(name, export_function, with_args=True, verbose=False, suffix="export"):
if verbose:
print(f"profile {name}: {export_function}")
if with_args:
model, input_tensors = create_model_and_input()
export_function(model, input_tensors)
pr = cProfile.Profile()
pr.enable()
for _ in range(int(script_args.repeat1)):
export_function(model, input_tensors)
pr.disable()
else:
pr = cProfile.Profile()
pr.enable()
for _ in range(int(script_args.repeat1)):
export_function()
pr.disable()
s = io.StringIO()
sortby = SortKey.CUMULATIVE
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
# with open(f"plot_torch_aot_profile_{name}_{suffix}.pickle", "wb") as f:
# pickle.dump(ps, f)
raw = s.getvalue()
text = "\n".join(raw.split("\n")[:200])
if verbose:
print(text)
with open(f"plot_torch_aot_profile_{name}_{suffix}.txt", "w") as f:
f.write(raw)
root, nodes = profile2graph(ps, clean_text=clean_text)
text = root.to_text()
with open(f"plot_torch_aot_profile_{name}_{suffix}_h.txt", "w") as f:
f.write(text)
if verbose:
print("done.")
model, input_tensors = create_model_and_input()
def function_to_profile(model=model, input_tensors=input_tensors):
return get_torch_dort(model, *input_tensors)
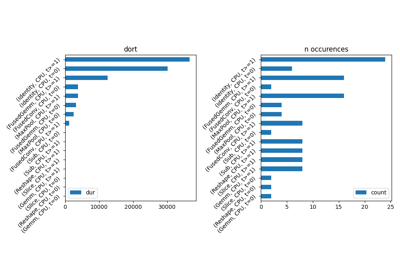
profile_function("dort", function_to_profile, verbose=True, suffix="1")
profile dort: <function function_to_profile at 0x7fe929da3ba0>
1763137 function calls (1729633 primitive calls) in 2.764 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
13/8 0.000 0.000 1.889 0.236 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1159(call_function)
41/10 0.000 0.000 1.886 0.189 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:197(realize_and_forward)
1 0.000 0.000 1.667 1.667 ~/github/experimental-experiment/experimental_experiment/torch_models/training_helper.py:6(make_aot_ort)
1 0.000 0.000 1.666 1.666 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/onnxruntime.py:801(__init__)
1 0.000 0.000 1.586 1.586 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:256(__init__)
1 0.000 0.000 1.319 1.319 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:80(__init__)
1 0.001 0.001 1.319 1.319 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:104(_initiate_registry_from_torchlib)
1 0.029 0.029 1.314 1.314 ~/github/onnxscript/onnxscript/_framework_apis/torch_2_5.py:82(get_torchlib_ops)
468 0.011 0.000 1.280 0.003 ~/github/onnxscript/onnxscript/values.py:645(function_ir)
468 0.007 0.000 0.534 0.001 ~/github/onnxscript/onnxscript/_internal/ast_utils.py:13(get_src_and_ast)
595/499 0.001 0.000 0.422 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:805(__call__)
468 0.002 0.000 0.381 0.001 ~/github/onnxscript/onnxscript/converter.py:1458(translate_function_signature)
468 0.002 0.000 0.378 0.001 /usr/lib/python3.12/inspect.py:1279(getsource)
468 0.026 0.000 0.376 0.001 ~/github/onnxscript/onnxscript/converter.py:1373(_translate_function_signature_common)
468 0.047 0.000 0.375 0.001 /usr/lib/python3.12/inspect.py:1258(getsourcelines)
468 0.026 0.000 0.329 0.001 /usr/lib/python3.12/inspect.py:1606(getclosurevars)
14852 0.110 0.000 0.280 0.000 /usr/lib/python3.12/dis.py:434(_get_instructions_bytes)
1 0.001 0.001 0.267 0.267 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/decomposition_table.py:73(create_onnx_friendly_decomposition_table)
468 0.076 0.000 0.255 0.001 /usr/lib/python3.12/inspect.py:1239(getblock)
15675/3259 0.047 0.000 0.226 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:138(is_value_type)
1 0.000 0.000 0.202 0.202 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:137(items)
1 0.000 0.000 0.202 0.202 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:154(_materialize_if_needed)
1 0.000 0.000 0.202 0.202 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:141(materialize)
1 0.000 0.000 0.201 0.201 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1240(_collect_all_valid_cia_ops)
27 0.002 0.000 0.201 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1223(_collect_all_valid_cia_ops_for_namespace)
2792 0.182 0.000 0.182 0.000 {built-in method builtins.compile}
27 0.065 0.002 0.182 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1158(_materialize_cpp_cia_ops)
201440/196058 0.080 0.000 0.163 0.000 {built-in method builtins.isinstance}
50155 0.086 0.000 0.158 0.000 /usr/lib/python3.12/tokenize.py:563(_generate_tokens_from_c_tokenizer)
596 0.007 0.000 0.157 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2000(dispatch)
1889 0.003 0.000 0.150 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:179(is_valid_type)
219 0.003 0.000 0.147 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1418(_cached_dispatch_impl)
128 0.026 0.000 0.145 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/functional_tensor.py:356(__torch_dispatch__)
85 0.000 0.000 0.141 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:300(call_function)
2 0.027 0.014 0.137 0.069 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/decomposition_table.py:14(_create_onnx_supports_op_overload_table)
103/35 0.001 0.000 0.133 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1225(step)
468 0.002 0.000 0.125 0.000 /usr/lib/python3.12/ast.py:34(parse)
8 0.000 0.000 0.124 0.016 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/_pass.py:225(run)
4 0.000 0.000 0.122 0.030 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1648(_run)
12/6 0.000 0.000 0.119 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:821(wrapper)
12/6 0.000 0.000 0.118 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2932(CALL)
12/6 0.000 0.000 0.118 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2891(_call)
89 0.003 0.000 0.118 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1568(run_node)
15675 0.024 0.000 0.094 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:130(_is_tensor_type)
297/276 0.001 0.000 0.091 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1414(__torch_dispatch__)
47891/47433 0.026 0.000 0.085 0.000 {built-in method builtins.next}
4 0.000 0.000 0.085 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/nn_module.py:939(call_function)
5/4 0.000 0.000 0.083 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/functions.py:441(call_function)
5/4 0.000 0.000 0.082 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/functions.py:284(call_function)
28 0.000 0.000 0.082 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2315(LOAD_ATTR)
69/54 0.003 0.000 0.082 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:770(proxy_call)
28 0.000 0.000 0.082 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2306(_load_attr)
1370 0.001 0.000 0.081 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:175(is_attr_type)
2315 0.011 0.000 0.078 0.000 ~/github/onnxscript/onnxscript/converter.py:444(_eval_constant_expr)
5/4 0.000 0.000 0.078 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1189(inline_user_function_return)
5/4 0.000 0.000 0.078 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:3730(inline_call)
5/4 0.000 0.000 0.077 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:3928(inline_call_)
106684/106682 0.068 0.000 0.072 0.000 {built-in method builtins.getattr}
49688 0.039 0.000 0.071 0.000 /usr/lib/python3.12/collections/__init__.py:447(_make)
202 0.002 0.000 0.068 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1925(_output_from_cache_entry)
1 0.000 0.000 0.067 0.067 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:2469(min_cut_rematerialization_partition)
468 0.010 0.000 0.066 0.000 /usr/lib/python3.12/inspect.py:1070(findsource)
208 0.007 0.000 0.066 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1852(_get_output_tensor_from_cache_entry)
29821 0.054 0.000 0.064 0.000 /usr/lib/python3.12/dis.py:623(_unpack_opargs)
16278 0.019 0.000 0.063 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:77(_remove_annotation)
219 0.002 0.000 0.061 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1497(_cache_key)
16956 0.007 0.000 0.061 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:189(is_registered_op)
219 0.000 0.000 0.057 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:64(realize)
817/226 0.009 0.000 0.057 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1607(_prep_args_for_hash)
17018 0.013 0.000 0.055 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:167(get_op_functions)
469 0.017 0.000 0.054 0.000 /usr/lib/python3.12/dis.py:647(findlabels)
3/2 0.000 0.000 0.054 0.027 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:614(add_input)
3/2 0.000 0.000 0.054 0.027 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:271(_wrap_torch_value_to_tensor)
3/2 0.099 0.033 0.054 0.027 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:200(dtype)
40/29 0.000 0.000 0.052 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:1142(call_function)
71 0.001 0.000 0.051 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:22(realize)
4/2 0.205 0.051 0.050 0.025 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:171(shape)
75 0.001 0.000 0.049 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:424(__call__)
1898/1682 0.002 0.000 0.049 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/base.py:220(__instancecheck__)
29 0.000 0.000 0.049 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:978(builtin_dispatch)
28 0.000 0.000 0.049 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:856(call_self_handler)
51/35 0.000 0.000 0.048 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/nn_module.py:1111(var_getattr)
28 0.000 0.000 0.048 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:1920(call_getattr)
12 0.000 0.000 0.048 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1528(python_code)
35/19 0.001 0.000 0.047 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/user_defined.py:1064(var_getattr)
20169 0.026 0.000 0.047 0.000 /usr/lib/python3.12/typing.py:2344(get_origin)
40 0.002 0.000 0.046 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:601(_wrap)
13 0.000 0.000 0.046 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2902(from_tensor)
13 0.000 0.000 0.043 0.003 {built-in method torch._to_functional_tensor}
2 0.000 0.000 0.042 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/onnxruntime.py:1114(compile)
2 0.000 0.000 0.042 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/infra/partitioner.py:372(partition_and_fuse)
18 0.000 0.000 0.041 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:2698(wrap_fake_exception)
1843/1617 0.002 0.000 0.041 0.000 /usr/lib/python3.12/contextlib.py:132(__enter__)
668 0.004 0.000 0.041 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1065(create_node)
47790 0.026 0.000 0.039 0.000 {method 'get' of 'dict' objects}
314 0.001 0.000 0.039 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1557(tree_map_only)
9 0.000 0.000 0.039 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/torch.py:1062(call_function)
12 0.000 0.000 0.038 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1605(_python_code)
2 0.000 0.000 0.038 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/infra/partitioner.py:285(fuse_partitions)
2 0.000 0.000 0.038 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/fuser_utils.py:250(fuse_by_partitions)
428/388 0.001 0.000 0.038 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1316(__torch_function__)
12 0.004 0.000 0.038 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:373(_gen_python_code)
26/13 0.001 0.000 0.038 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:341(from_real_tensor)
9 0.000 0.000 0.037 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:810(recompile)
6799 0.013 0.000 0.037 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:846(__setattr__)
168/136 0.001 0.000 0.036 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1960(__setattr__)
1 0.000 0.000 0.035 0.035 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/backends/common.py:70(_wrapped_bw_compiler)
79356 0.035 0.000 0.035 0.000 {built-in method __new__ of type object at 0xa20960}
9 0.001 0.000 0.034 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:1796(wrap_tensor)
477 0.002 0.000 0.034 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1459(node_copy)
14 0.000 0.000 0.034 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:566(graph)
31 0.001 0.000 0.033 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:1835(__call__)
27 0.033 0.001 0.033 0.001 {built-in method torch._C._dispatch_get_registrations_for_dispatch_key}
11 0.000 0.000 0.032 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:453(__init__)
31 0.001 0.000 0.032 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:871(meta_tensor)
12/9 0.000 0.000 0.032 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/nn/functional.py:1702(relu)
9 0.001 0.000 0.031 0.003 {built-in method torch.relu}
4 0.000 0.000 0.030 0.008 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/aot_autograd.py:495(convert)
643 0.001 0.000 0.030 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1264(tree_flatten)
72499 0.029 0.000 0.029 0.000 {method 'split' of 'str' objects}
18 0.000 0.000 0.029 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2479(wrap_fx_proxy)
18 0.000 0.000 0.029 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2552(wrap_fx_proxy_cls)
2457/946 0.007 0.000 0.029 0.000 /usr/lib/python3.12/copy.py:118(deepcopy)
1971/643 0.010 0.000 0.028 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1272(helper)
264 0.007 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:999(_flatten_into)
10185 0.013 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/registration.py:55(from_qualified_name)
17983 0.012 0.000 0.027 0.000 {built-in method builtins.issubclass}
128064/127982 0.027 0.000 0.027 0.000 {built-in method builtins.len}
692 0.004 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:368(prepend)
4/1 0.000 0.000 0.027 0.027 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/fx_onnx_interpreter.py:343(run_node)
2/1 0.000 0.000 0.027 0.027 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/fx_onnx_interpreter.py:476(placeholder)
12/9 0.002 0.000 0.026 0.003 {built-in method torch._C._nn.linear}
31 0.001 0.000 0.026 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:273(__exit__)
9 0.000 0.000 0.026 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2638(_wrap_fx_proxy)
1843/1615 0.002 0.000 0.026 0.000 /usr/lib/python3.12/contextlib.py:141(__exit__)
469 0.006 0.000 0.025 0.000 /usr/lib/python3.12/inspect.py:951(getsourcefile)
109 0.001 0.000 0.025 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:214(create_proxy)
442 0.005 0.000 0.025 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:585(emit_node)
2616 0.021 0.000 0.024 0.000 {built-in method builtins.eval}
44261/44225 0.020 0.000 0.024 0.000 {built-in method builtins.hasattr}
468 0.004 0.000 0.024 0.000 /usr/lib/python3.12/textwrap.py:419(dedent)
320 0.007 0.000 0.023 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:702(__new__)
9 0.000 0.000 0.023 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:3223(wrap_to_fake_tensor_and_record)
9 0.001 0.000 0.022 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:3126(get_fake_value)
4 0.000 0.000 0.022 0.006 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/fuser_utils.py:95(fuse_as_graphmodule)
49687 0.022 0.000 0.022 0.000 /usr/lib/python3.12/inspect.py:1196(tokeneater)
17060 0.011 0.000 0.022 0.000 <frozen abc>:117(__instancecheck__)
9 0.000 0.000 0.021 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:3261(<lambda>)
3 0.000 0.000 0.020 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:930(print_readable)
890/42 0.002 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_stats.py:22(wrapper)
3 0.000 0.000 0.020 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:310(_print_readable)
17018 0.009 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/registration.py:45(from_name_parts)
592/42 0.002 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1333(__torch_dispatch__)
264 0.006 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1021(extract_tensor_metadata)
9 0.000 0.000 0.020 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:3201(<lambda>)
61 0.000 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:602(track_tensor_tree)
9 0.000 0.000 0.020 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:3339(run_node)
4 0.001 0.000 0.019 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:171(_extract_graph_with_inputs_outputs)
54 0.001 0.000 0.019 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/guards.py:1308(get_guard_manager)
1 0.001 0.001 0.019 0.019 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/compile_utils.py:42(fx_graph_cse)
56994 0.019 0.000 0.019 0.000 /usr/lib/python3.12/dis.py:195(_deoptop)
76/61 0.000 0.000 0.019 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:624(wrap_with_proxy)
469 0.008 0.000 0.018 0.000 /usr/lib/python3.12/dis.py:342(get_instructions)
829/685 0.006 0.000 0.018 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/recording.py:246(wrapper)
444 0.001 0.000 0.018 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:215(_set_current_node)
4 0.000 0.000 0.017 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/overrides.py:1674(handle_torch_function)
62 0.000 0.000 0.017 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/onnxfunction_dispatcher.py:70(dispatch)
1843 0.017 0.000 0.017 0.000 {method 'copy' of 'dict' objects}
1792/1791 0.004 0.000 0.017 0.000 {built-in method builtins.any}
103/56 0.006 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/guards.py:958(get_guard_manager_from_source)
342 0.000 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1144(_is_preservable_cia_op)
1 0.000 0.000 0.015 0.015 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:786(_extract_fwd_bwd_modules)
111 0.001 0.000 0.015 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:148(create_node)
2 0.000 0.000 0.015 0.008 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/metrics_context.py:79(__exit__)
444 0.001 0.000 0.015 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/traceback.py:197(set_current_meta)
2 0.000 0.000 0.015 0.008 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:1512(record_compilation_metrics)
13162 0.007 0.000 0.015 0.000 <frozen abc>:121(__subclasscheck__)
46539/44697 0.014 0.000 0.015 0.000 {built-in method builtins.hash}
500 0.002 0.000 0.014 0.000 /usr/lib/python3.12/linecache.py:52(checkcache)
1 0.000 0.000 0.014 0.014 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:893(__deepcopy__)
17122 0.010 0.000 0.014 0.000 /usr/lib/python3.12/inspect.py:302(isclass)
4 0.000 0.000 0.014 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/common.py:26(lift_subgraph_as_module)
123/13 0.001 0.000 0.014 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:222(run_node)
69/54 0.000 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:2342(maybe_handle_decomp)
20653 0.008 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:813(__hash__)
211 0.002 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/traceback.py:55(__init__)
448 0.000 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1491(wrapped)
3 0.000 0.000 0.013 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_decomp/__init__.py:146(_fn)
3 0.000 0.000 0.013 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/wrappers.py:287(_fn)
3 0.000 0.000 0.013 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_decomp/decompositions.py:221(threshold_backward)
12 0.000 0.000 0.013 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1538(_maybe_promote_node)
2149 0.003 0.000 0.013 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:195(is_sparse_any)
1 0.000 0.000 0.013 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/functions.py:981(call_function)
146/78 0.001 0.000 0.013 0.000 /usr/lib/python3.12/copy.py:217(_deepcopy_dict)
31 0.002 0.000 0.013 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:269(__enter__)
done.
Benchmark exported models with ORT¶
def benchmark(shape):
data = []
data_mem_first_run = []
data_mem_run = []
confs = list(
itertools.product(
export_functions,
["CPU", "CUDA"],
)
)
loop = tqdm(confs)
print(f"number of experiments: {len(loop)}")
for export_fct, p in loop:
name = export_fct.__name__.replace("get_torch_", "")
obs = {} # system_info()
obs["name"] = name
obs["compute"] = p
obs["export"] = name
model, input_tensors = create_model_and_input()
if p == "CUDA":
if not has_cuda:
continue
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
try:
exported_model = export_fct(model, *input_tensors)
except Exception as e:
obs["error"] = str(e)
data.append(obs)
continue
def call_model(
export_fct=export_fct,
exported_model=exported_model,
input_tensors=input_tensors,
):
res = run(exported_model, *input_tensors)
return res
stat = start_spying_on(cuda=1 if has_cuda else 0)
try:
call_model()
except Exception as e:
loop.set_description(f"ERROR-run: {name} {e}")
obs.update({"error": e, "step": "load"})
data.append(obs)
stat.stop()
continue
memobs = flatten(stat.stop())
memobs.update(obs)
data_mem_first_run.append(memobs)
# memory consumption
stat = start_spying_on(cuda=1 if has_cuda else 0)
for _ in range(0, script_args.warmup):
call_model()
memobs = flatten(stat.stop())
memobs.update(obs)
data_mem_run.append(memobs)
obs.update(
measure_time(
call_model,
max_time=script_args.maxtime,
repeat=script_args.repeat,
number=1,
)
)
profile_function(name, call_model, with_args=False, suffix=f"run_{p}")
loop.set_description(f"{obs['average']} {name} {p}")
data.append(obs)
del model
del exported_model
gc.collect()
time.sleep(1)
df = pandas.DataFrame(data)
df.to_csv("plot_torch_aot_ort_time.csv", index=False)
df.to_excel("plot_torch_aot_ort_time.xlsx", index=False)
dfmemr = pandas.DataFrame(data_mem_run)
dfmemr.to_csv("plot_torch_aot_ort_run_mem.csv", index=False)
dfmemr.to_excel("plot_torch_aot_ort_run_mem.xlsx", index=False)
dfmemfr = pandas.DataFrame(data_mem_first_run)
dfmemfr.to_csv("plot_torch_aot_ort_first_run_mem.csv", index=False)
dfmemfr.to_excel("plot_torch_aot_ort_first_run_mem.xlsx", index=False)
return df, dfmemfr, dfmemr
df, dfmemfr, dfmemr = benchmark(list(input_tensors[0].shape))
print(df)
0%| | 0/6 [00:00<?, ?it/s]number of experiments: 6
0.005037054666495856 eager CPU: 0%| | 0/6 [00:00<?, ?it/s]
0.005037054666495856 eager CPU: 17%|█▋ | 1/6 [00:02<00:12, 2.51s/it]
0.0020226596567606892 eager CUDA: 17%|█▋ | 1/6 [00:03<00:12, 2.51s/it]
0.0020226596567606892 eager CUDA: 33%|███▎ | 2/6 [00:04<00:09, 2.29s/it]
0.004044640444287022 default CPU: 33%|███▎ | 2/6 [00:10<00:09, 2.29s/it]
0.004044640444287022 default CPU: 50%|█████ | 3/6 [00:12<00:13, 4.61s/it]
0.0010882789008990602 default CUDA: 50%|█████ | 3/6 [00:22<00:13, 4.61s/it]
0.0010882789008990602 default CUDA: 67%|██████▋ | 4/6 [00:23<00:14, 7.43s/it]~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/utils.py:130: UserWarning: Your compiler for AOTAutograd is returning a function that doesn't take boxed arguments. Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale.
warnings.warn(
0.004137020805703489 dort CPU: 67%|██████▋ | 4/6 [00:25<00:14, 7.43s/it]
0.004137020805703489 dort CPU: 83%|████████▎ | 5/6 [00:27<00:05, 5.98s/it]~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/utils.py:130: UserWarning: Your compiler for AOTAutograd is returning a function that doesn't take boxed arguments. Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale.
warnings.warn(
0.005982100952158882 dort CUDA: 83%|████████▎ | 5/6 [00:28<00:05, 5.98s/it]
0.005982100952158882 dort CUDA: 100%|██████████| 6/6 [00:30<00:00, 4.96s/it]
0.005982100952158882 dort CUDA: 100%|██████████| 6/6 [00:30<00:00, 5.03s/it]
name compute export average deviation min_exec max_exec repeat number ttime context_size warmup_time
0 eager CPU eager 0.005037 0.000327 0.004594 0.006317 1 27.0 0.136000 64 0.007767
1 eager CUDA eager 0.002023 0.000178 0.001674 0.002332 1 67.0 0.135518 64 0.002674
2 default CPU default 0.004045 0.000213 0.003028 0.004140 1 27.0 0.109205 64 0.005214
3 default CUDA default 0.001088 0.000290 0.000851 0.002801 1 111.0 0.120799 64 0.003801
4 dort CPU dort 0.004137 0.000697 0.002370 0.004654 1 36.0 0.148933 64 0.005381
5 dort CUDA dort 0.005982 0.001217 0.004532 0.008390 1 21.0 0.125624 64 0.005022
Other view
def view_time(df, title, suffix="time"):
piv = pandas.pivot_table(df, index="export", columns=["compute"], values="average")
print(piv)
piv.to_csv(f"plot_torch_aot_{suffix}_compute.csv")
piv.to_excel(f"plot_torch_aot_{suffix}_compute.xlsx")
piv_cpu = pandas.pivot_table(
df[df.compute == "CPU"],
index="export",
columns=["compute"],
values="average",
)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
fig.suptitle(title)
piv_cpu.plot.barh(ax=ax[0], title="CPU", logx=True)
if has_cuda:
piv_gpu = pandas.pivot_table(
df[df.compute == "CUDA"],
index="export",
columns=["compute"],
values="average",
)
piv_gpu.plot.barh(ax=ax[1], title="CUDA", logx=True)
fig.tight_layout()
fig.savefig(f"plot_torch_aot_{suffix}.png")
return ax
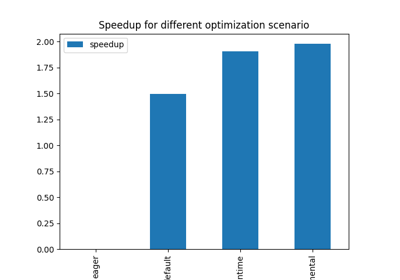
view_time(df, "Compares processing time on backends")
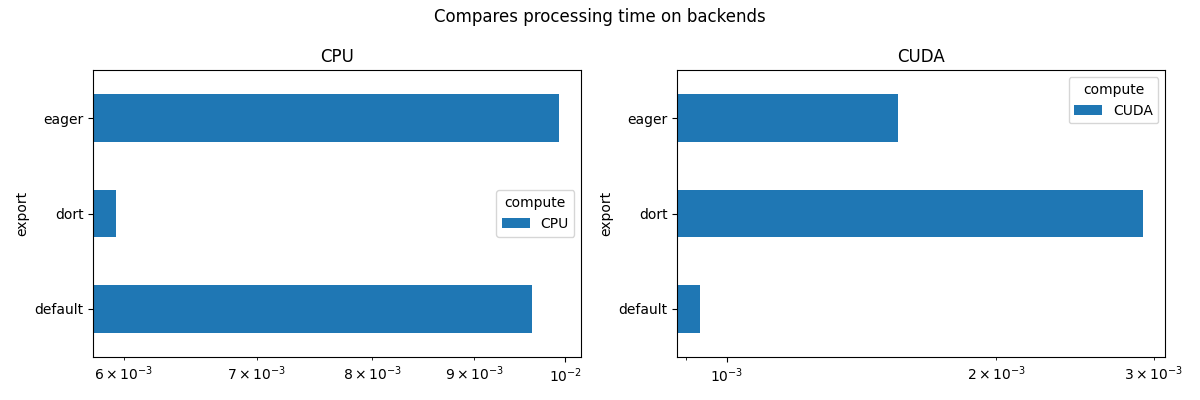
compute CPU CUDA
export
default 0.004045 0.001088
dort 0.004137 0.005982
eager 0.005037 0.002023
array([<Axes: title={'center': 'CPU'}, ylabel='export'>,
<Axes: title={'center': 'CUDA'}, ylabel='export'>], dtype=object)
Memory First Running Time (ORT)¶
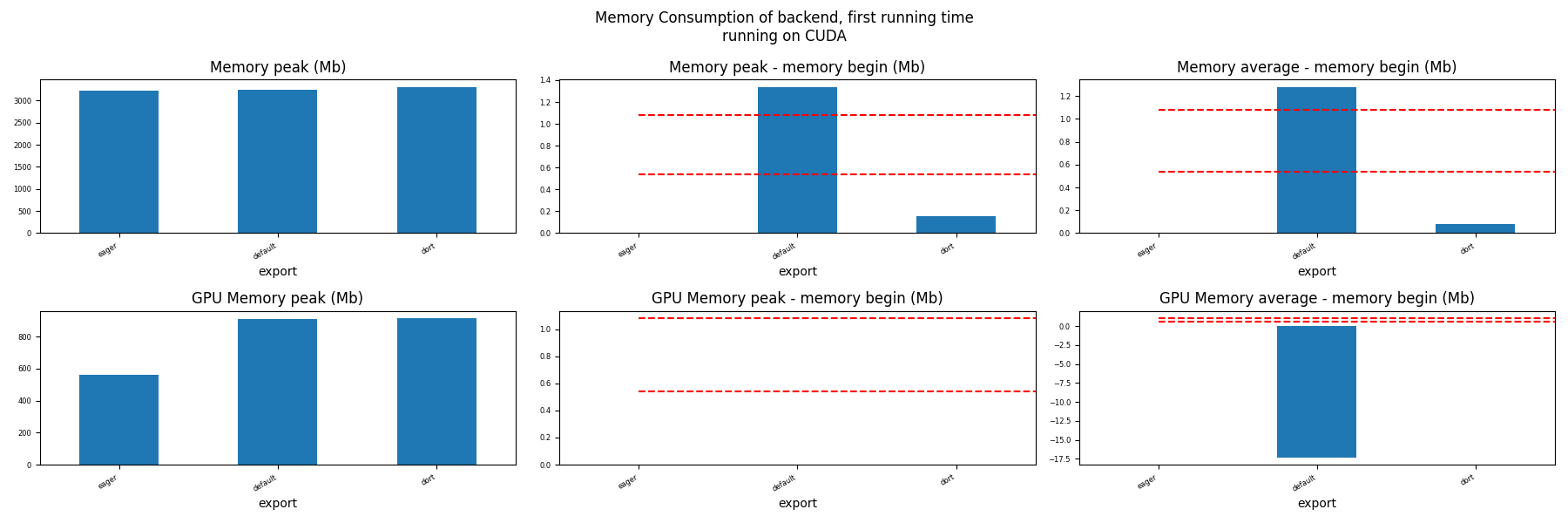
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemfr[dfmemfr.compute == compute],
("export",),
suptitle=f"Memory Consumption of backend, first running time"
f"\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_aot_first_run_mem_{compute}.png")
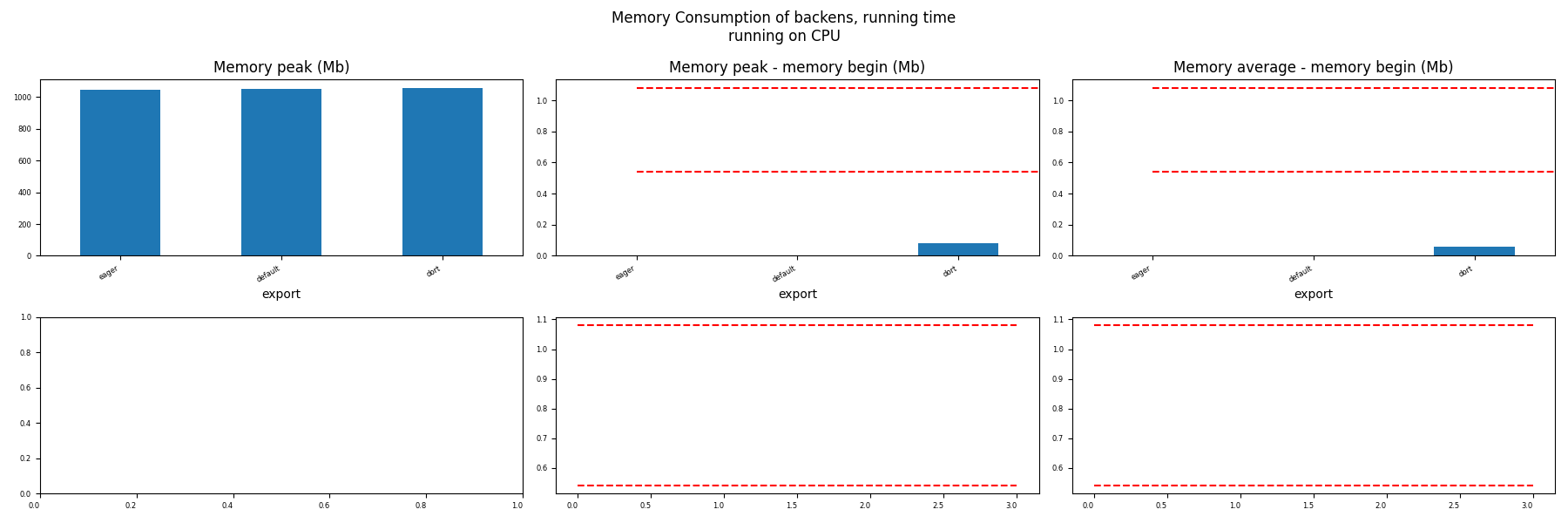
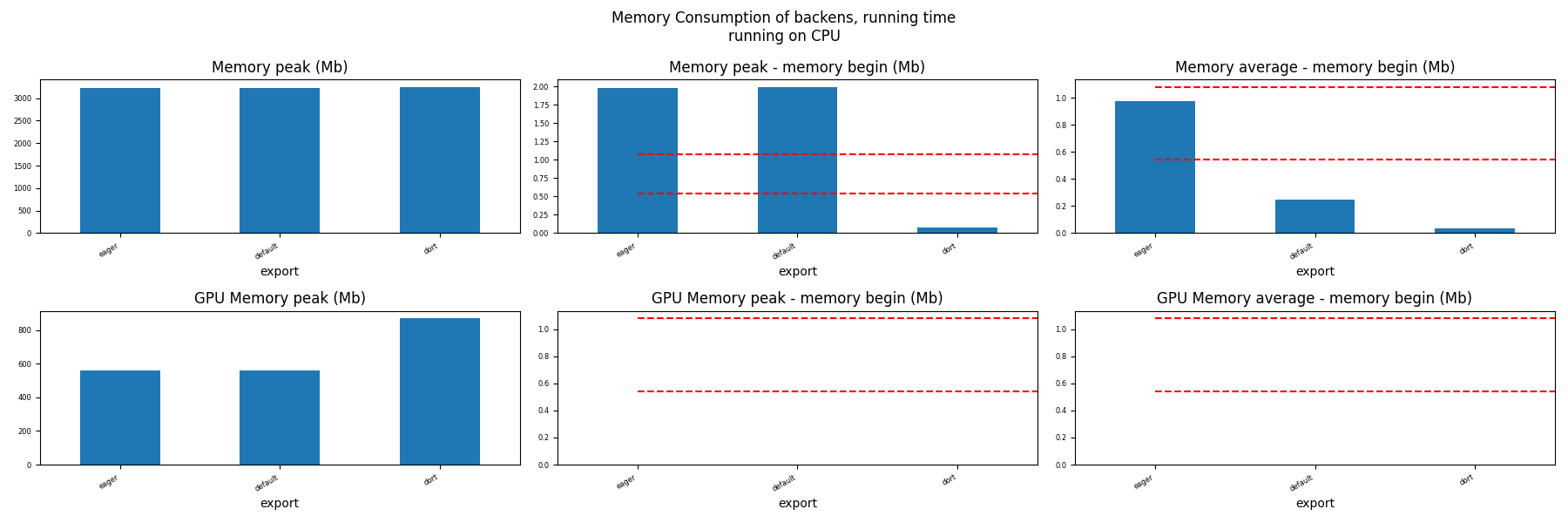
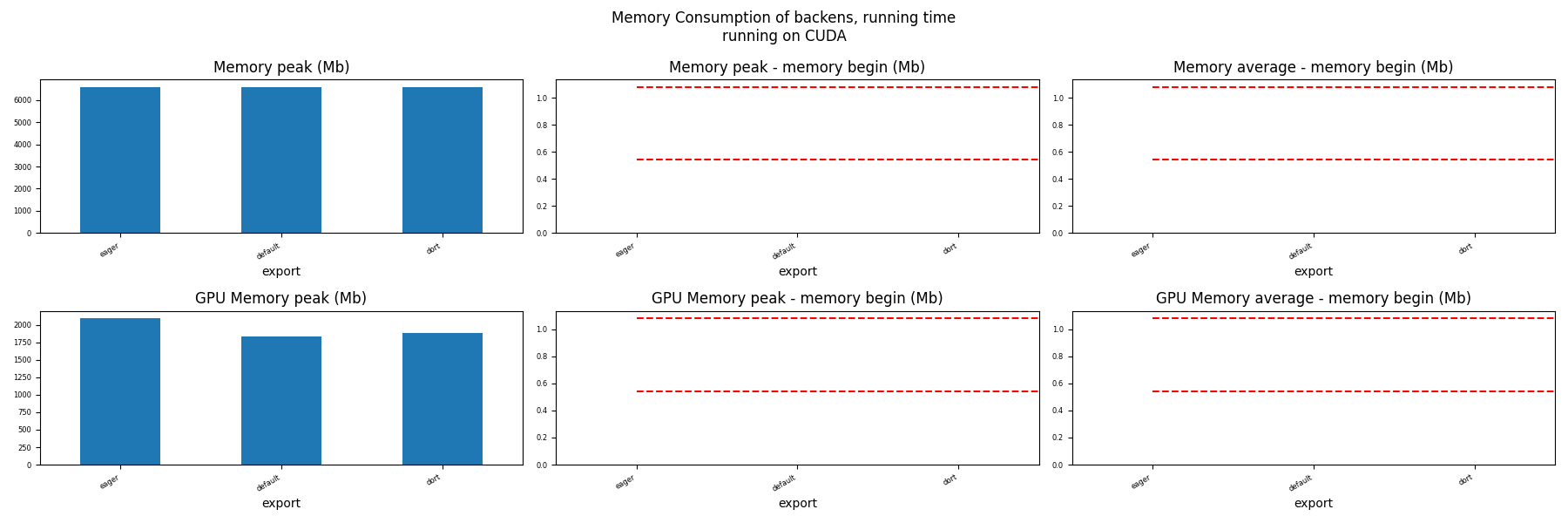
Memory Running Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemr[dfmemr.compute == compute],
("export",),
suptitle=f"Memory Consumption of backens, running time\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_aot_run_mem_{compute}.png")
Total running time of the script: (1 minutes 3.280 seconds)
Related examples

201: Evaluate different ways to export a torch model to ONNX
201: Evaluate different ways to export a torch model to ONNX