Note
Go to the end to download the full example code.
torch.onnx.export and Phi-2¶
Exports model Phi-2. We use a dummy model. The main difficulty is to set the dynamic shapes properly.
Model¶
import copy
from typing import Any, Dict
import onnx
import torch
import transformers
from onnx_array_api.plotting.graphviz_helper import plot_dot
from onnx_diagnostic.helpers.cache_helper import make_dynamic_cache
from experimental_experiment.helpers import string_type, pretty_onnx
def get_phi2_untrained(batch_size: int = 2, **kwargs) -> Dict[str, Any]:
"""
Gets a non initialized model with its inputs
:param batch_size: batch size
:param kwargs: to overwrite the configuration, example ``num_hidden_layers=1``
:return: dictionary
See `Phi-2/config.json
<https://huggingface.co/microsoft/phi-2/blob/main/config.json>`_.
"""
config = {
"_name_or_path": "microsoft/phi-2",
"architectures": ["PhiForCausalLM"],
"attention_dropout": 0.0,
"bos_token_id": 50256,
"embd_pdrop": 0.0,
"eos_token_id": 50256,
"hidden_act": "gelu_new",
"hidden_size": 2560,
"initializer_range": 0.02,
"intermediate_size": 10240,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 2048,
"model_type": "phi",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"partial_rotary_factor": 0.4,
"qk_layernorm": False,
"resid_pdrop": 0.1,
"rope_scaling": None,
"rope_theta": 10000.0,
"tie_word_embeddings": False,
"torch_dtype": "float16",
"transformers_version": "4.37.0",
"use_cache": True,
"vocab_size": 51200,
}
config.update(**kwargs)
conf = transformers.PhiConfig(**config)
model = transformers.PhiForCausalLM(conf)
model.eval()
batch = torch.export.Dim("batch", min=1, max=1024)
seq_length = torch.export.Dim("seq_length", min=1, max=4096)
shapes = {}
cache = make_dynamic_cache(
[
(torch.randn(batch_size, 32, 30, 80), torch.randn(batch_size, 32, 30, 80))
for i in range(config["num_hidden_layers"])
]
)
cache2 = make_dynamic_cache(
[
(torch.randn(batch_size + 1, 32, 31, 80), torch.randn(batch_size + 1, 32, 31, 80))
for i in range(config["num_hidden_layers"])
]
)
inputs = dict(
input_ids=torch.randint(0, 50285, (batch_size, 3)).to(torch.int64),
attention_mask=torch.ones((batch_size, 33)).to(torch.int64),
past_key_values=cache,
)
inputs2 = dict(
input_ids=torch.randint(0, 50285, (batch_size + 1, 4)).to(torch.int64),
attention_mask=torch.ones((batch_size + 1, 35)).to(torch.int64),
past_key_values=cache2,
)
n = len(cache.key_cache)
cache_length = torch.export.Dim("cache_length", min=1, max=4096)
shapes.update(
{
"input_ids": {0: batch, 1: seq_length},
"attention_mask": {
0: batch,
1: torch.export.Dim.DYNAMIC, # cache_length + seq_length
},
"past_key_values": [
[{0: batch, 2: cache_length} for _ in range(n)], # 0: batch,
[{0: batch, 2: cache_length} for _ in range(n)], # 0: batch,
],
}
)
return dict(inputs=inputs, model=model, dynamic_shapes=shapes, inputs2=inputs2)
data = get_phi2_untrained(num_hidden_layers=2)
model = data["model"]
inputs = data["inputs"]
dynamic_shapes = data["dynamic_shapes"]
print("inputs", string_type(inputs, with_shape=True))
print("dynamic_shapes", dynamic_shapes)
inputs dict(input_ids:T7s2x3,attention_mask:T7s2x33,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x80,T1s2x32x30x80], value_cache=#2[T1s2x32x30x80,T1s2x32x30x80]))
dynamic_shapes {'input_ids': {0: Dim('batch', min=1, max=1024), 1: Dim('seq_length', min=1, max=4096)}, 'attention_mask': {0: Dim('batch', min=1, max=1024), 1: _DimHint(type=<_DimHintType.DYNAMIC: 3>, min=None, max=None, _factory=True)}, 'past_key_values': [[{0: Dim('batch', min=1, max=1024), 2: Dim('cache_length', min=1, max=4096)}, {0: Dim('batch', min=1, max=1024), 2: Dim('cache_length', min=1, max=4096)}], [{0: Dim('batch', min=1, max=1024), 2: Dim('cache_length', min=1, max=4096)}, {0: Dim('batch', min=1, max=1024), 2: Dim('cache_length', min=1, max=4096)}]]}
Let’s check it is working. We need to copy the input before calling the model because it modifies the inputs and they are not properly set up when the export starts.
model(**copy.deepcopy(inputs))
CausalLMOutputWithPast(loss=None, logits=tensor([[[ 0.0233, 1.2090, -0.4298, ..., -1.6637, -0.8862, 1.0496],
[-1.1553, 0.3285, 1.3657, ..., 0.6885, 0.4215, 1.1989],
[-0.9946, 2.2888, 0.7936, ..., -0.5234, -0.1518, -1.0178]],
[[ 0.0459, 0.2453, 0.8995, ..., -2.2345, 0.3006, 0.7992],
[-0.7704, 0.7236, 1.1240, ..., -0.8099, 0.2912, -0.3429],
[ 0.1922, 0.7764, 0.3260, ..., 0.5502, -0.5678, 0.9791]]],
grad_fn=<ViewBackward0>), past_key_values=<transformers.cache_utils.DynamicCache object at 0x7fea23fa5400>, hidden_states=None, attentions=None)
Export¶
Let’s export with torch.onnx.export().
try:
torch.onnx.export(
copy.deepcopy(model),
(),
kwargs=copy.deepcopy(inputs),
dynamic_shapes=dynamic_shapes,
dynamo=True,
)
except Exception as e:
print(f"export failed due to {e}")
~/github/onnxscript/onnxscript/converter.py:816: FutureWarning: 'onnxscript.values.Op.param_schemas' is deprecated in version 0.1 and will be removed in the future. Please use '.op_signature' instead.
param_schemas = callee.param_schemas()
~/github/onnxscript/onnxscript/converter.py:816: FutureWarning: 'onnxscript.values.OnnxFunction.param_schemas' is deprecated in version 0.1 and will be removed in the future. Please use '.op_signature' instead.
param_schemas = callee.param_schemas()
[torch.onnx] Obtain model graph for `PhiForCausalLM([...]` with `torch.export.export(..., strict=False)`...
[torch.onnx] Obtain model graph for `PhiForCausalLM([...]` with `torch.export.export(..., strict=False)`... ✅
[torch.onnx] Run decomposition...
[torch.onnx] Run decomposition... ✅
[torch.onnx] Translate the graph into ONNX...
[torch.onnx] Translate the graph into ONNX... ✅
~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_dynamic_shapes.py:264: UserWarning: # The axis name: batch will not be used, since it shares the same shape constraints with another axis: batch.
warnings.warn(
~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_dynamic_shapes.py:264: UserWarning: # The axis name: cache_length will not be used, since it shares the same shape constraints with another axis: cache_length.
warnings.warn(
Applied 52 of general pattern rewrite rules.
The export fails for a couple of reason but it is possible to patch the
code to make it work. All those modifications are put in place by
torch_export_patches
and reverted after the export is done. Among other things, this function registers
serialization functions as shown in example
Export a model using a custom type as input.
from onnx_diagnostic.torch_export_patches import torch_export_patches
with torch_export_patches(patch_transformers=True, verbose=1) as modificator:
print("inputs before", string_type(inputs, with_shape=True))
inputs = modificator(inputs)
print("inputs after", string_type(inputs, with_shape=True))
# ep = torch.export.export(model, (), inputs, dynamic_shapes=dynamic_shapes, strict=False)
ep = torch.onnx.export(
model, (), kwargs=copy.deepcopy(inputs), dynamic_shapes=dynamic_shapes, dynamo=True
)
ep.optimize()
ep.save("plot_exporter_recipes_oe_phi2.onnx")
[torch_export_patches] replace torch.jit.isinstance, torch._dynamo.mark_static_address
[register_cache_serialization] register <class 'transformers.cache_utils.MambaCache'>
[register_cache_serialization] register <class 'transformers.cache_utils.EncoderDecoderCache'>
[torch_export_patches] sympy.__version__='1.13.3'
[torch_export_patches] patch sympy
[torch_export_patches] torch.__version__='2.8.0.dev20250519+cu126'
[torch_export_patches] stop_if_static=0
[torch_export_patches] patch pytorch
[torch_export_patches] modifies shape constraints
[torch_export_patches] transformers.__version__='4.52.0.dev0'
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_AttentionMaskConverter:
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_DynamicCache: reorder_cache, update, crop, from_batch_splits, get_seq_length
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GenerationMixin: _cache_dependant_input_preparation, _cache_dependant_input_preparation_exporting, prepare_inputs_for_generation
[torch_export_patches] done patching
inputs before dict(input_ids:T7s2x3,attention_mask:T7s2x33,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x80,T1s2x32x30x80], value_cache=#2[T1s2x32x30x80,T1s2x32x30x80]))
inputs after dict(input_ids:T7s2x3,attention_mask:T7s2x33,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x80,T1s2x32x30x80], value_cache=#2[T1s2x32x30x80,T1s2x32x30x80]))
[torch.onnx] Obtain model graph for `PhiForCausalLM([...]` with `torch.export.export(..., strict=False)`...
[torch.onnx] Obtain model graph for `PhiForCausalLM([...]` with `torch.export.export(..., strict=False)`... ✅
[torch.onnx] Run decomposition...
[torch.onnx] Run decomposition... ✅
[torch.onnx] Translate the graph into ONNX...
[torch.onnx] Translate the graph into ONNX... ✅
~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_dynamic_shapes.py:264: UserWarning: # The axis name: batch will not be used, since it shares the same shape constraints with another axis: batch.
warnings.warn(
~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_dynamic_shapes.py:264: UserWarning: # The axis name: cache_length will not be used, since it shares the same shape constraints with another axis: cache_length.
warnings.warn(
Applied 52 of general pattern rewrite rules.
Applied 1 of general pattern rewrite rules.
[torch_export_patches] remove patches
[torch_export_patches] restored sympy functions
[torch_export_patches] restored pytorch functions
[torch_export_patches] restored shape constraints
[torch_export_patches] unpatch transformers
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_AttentionMaskConverter:
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_DynamicCache: reorder_cache, update, crop, from_batch_splits, get_seq_length
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GenerationMixin: _cache_dependant_input_preparation, _cache_dependant_input_preparation_exporting, prepare_inputs_for_generation
[unregister_cache_serialization] unregistered MambaCache
[unregister_cache_serialization] unregistered EncoderDecoderCache
Exported Model¶
Let’s display the model.
onx = onnx.load("plot_exporter_recipes_oe_phi2.onnx")
print(pretty_onnx(onx))
opset: domain='' version=18
input: name='input_ids' type=dtype('int64') shape=['batch', 'seq_length']
input: name='attention_mask' type=dtype('int64') shape=['batch', 'seq_length + cache_length']
input: name='past_key_values_key_cache_0' type=dtype('float32') shape=['batch', 32, 'cache_length', 80]
input: name='past_key_values_key_cache_1' type=dtype('float32') shape=['batch', 32, 'cache_length', 80]
input: name='past_key_values_value_cache_0' type=dtype('float32') shape=['batch', 32, 'cache_length', 80]
input: name='past_key_values_value_cache_1' type=dtype('float32') shape=['batch', 32, 'cache_length', 80]
init: name='model.embed_tokens.weight' type=float32 shape=(51200, 2560)
init: name='model.layers.0.self_attn.q_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.0.self_attn.q_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.0.self_attn.k_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.0.self_attn.k_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.0.self_attn.v_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.0.self_attn.v_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.0.self_attn.dense.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.0.self_attn.dense.bias' type=float32 shape=(2560,)
init: name='model.layers.0.mlp.fc1.weight' type=float32 shape=(10240, 2560)
init: name='model.layers.0.mlp.fc1.bias' type=float32 shape=(10240,)
init: name='model.layers.0.mlp.fc2.weight' type=float32 shape=(2560, 10240)
init: name='model.layers.0.mlp.fc2.bias' type=float32 shape=(2560,)
init: name='model.layers.0.input_layernorm.weight' type=float32 shape=(2560,)
init: name='model.layers.0.input_layernorm.bias' type=float32 shape=(2560,)
init: name='model.layers.1.self_attn.q_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.1.self_attn.q_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.1.self_attn.k_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.1.self_attn.k_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.1.self_attn.v_proj.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.1.self_attn.v_proj.bias' type=float32 shape=(2560,)
init: name='model.layers.1.self_attn.dense.weight' type=float32 shape=(2560, 2560)
init: name='model.layers.1.self_attn.dense.bias' type=float32 shape=(2560,)
init: name='model.layers.1.mlp.fc1.weight' type=float32 shape=(10240, 2560)
init: name='model.layers.1.mlp.fc1.bias' type=float32 shape=(10240,)
init: name='model.layers.1.mlp.fc2.weight' type=float32 shape=(2560, 10240)
init: name='model.layers.1.mlp.fc2.bias' type=float32 shape=(2560,)
init: name='model.layers.1.input_layernorm.weight' type=float32 shape=(2560,)
init: name='model.layers.1.input_layernorm.bias' type=float32 shape=(2560,)
init: name='model.final_layernorm.weight' type=float32 shape=(2560,)
init: name='model.final_layernorm.bias' type=float32 shape=(2560,)
init: name='lm_head.weight' type=float32 shape=(51200, 2560)
init: name='lm_head.bias' type=float32 shape=(51200,)
init: name='expand_2' type=float32 shape=(1, 16, 1)
Constant(value_int=1) -> diagonal
Shape(input_ids, end=1, start=0) -> val_0
Shape(input_ids, end=2, start=1) -> val_1
Squeeze(val_1) -> sym_size_int_56
Shape(past_key_values_key_cache_0, end=3, start=2) -> val_2
Squeeze(val_2) -> sym_size_int_57
Add(sym_size_int_57, sym_size_int_56) -> add_4
Gather(model.embed_tokens.weight, input_ids, axis=0) -> embedding
LayerNormalization(embedding, model.layers.0.input_layernorm.weight, model.layers.0.input_layernorm.bias, stash_type=1, epsilon=0.00, axis=-1) -> layer_norm
Constant(value=1.0) -> val_3
Constant(value=1) -> val_4
Range(sym_size_int_57, add_4, val_4) -> arange
Constant(value=-3.4028234...) -> val_7
Constant(value=[-1]) -> val_10
Reshape(add_4, val_10, allowzero=0) -> val_11
Concat(val_1, val_11, axis=0) -> val_12
Expand(val_7, val_12) -> full
Trilu(full, diagonal, upper=1) -> triu
Constant(value=0) -> val_15
Constant(value=1) -> val_16
Range(val_15, add_4, val_16) -> arange_1
Constant(value=[-1, 1]) -> val_18
Reshape(arange, val_18, allowzero=0) -> view
Greater(arange_1, view) -> gt
Cast(gt, to=1) -> convert_element_type_default
Mul(triu, convert_element_type_default) -> mul_16
Constant(value=[1]) -> val_19
Constant(value=[0, 1]) -> val_608
Unsqueeze(mul_16, val_608) -> unsqueeze_4
Constant(value=0) -> val_20
Constant(value=2) -> val_28
Constant(value=[-1]) -> val_46
Concat(val_0, val_19, val_46, val_46, axis=0) -> val_47
Abs(val_47) -> val_49
Expand(unsqueeze_4, val_49) -> expand_1
Shape(expand_1, start=0) -> val_176
Gather(val_176, val_28, axis=0) -> val_177
Constant(value=1) -> val_58
Range(val_20, val_177, val_58) -> val_178
Unsqueeze(val_178, val_46) -> val_183
Constant(value_ints=[0]) -> val_69
Constant(value_ints=[-1]) -> val_71
Reshape(add_4, val_71, allowzero=0) -> val_72
Constant(value=[3]) -> val_75
Constant(value_ints=[1]) -> val_76
Slice(expand_1, val_69, val_72, val_75, val_76) -> slice_8
Constant(value=[1, 2]) -> val_609
Unsqueeze(attention_mask, val_609) -> unsqueeze_6
Cast(unsqueeze_6, to=1) -> convert_element_type_default_1
Add(slice_8, convert_element_type_default_1) -> add_89
Constant(value=0.0) -> scalar_tensor_default
Equal(add_89, scalar_tensor_default) -> eq_60
Constant(value_ints=[0]) -> val_116
Constant(value_ints=[-1]) -> val_118
Reshape(add_4, val_118, allowzero=0) -> val_119
Constant(value=[3]) -> val_122
Constant(value_ints=[1]) -> val_123
Slice(expand_1, val_116, val_119, val_122, val_123) -> slice_14
Constant(value=-3.4028234...) -> val_124
Where(eq_60, val_124, slice_14) -> masked_fill
Transpose(masked_fill, perm=[2,1,0,3]) -> val_184
Transpose(expand_1, perm=[2,1,0,3]) -> val_185
ScatterND(val_185, val_183, val_184, reduction=b'none') -> val_186
Transpose(val_186, perm=[1,2,0,3]) -> val_196
Shape(expand_1, start=0) -> val_188
Gather(val_188, val_58, axis=0) -> val_189
Range(val_20, val_189, val_58) -> val_190
Unsqueeze(val_190, val_46) -> val_195
Transpose(expand_1, perm=[1,0,2,3]) -> val_197
ScatterND(val_197, val_195, val_196, reduction=b'none') -> val_198
Transpose(val_198, perm=[1,0,2,3]) -> slice_scatter_1
Shape(expand_1, start=0) -> val_200
Gather(val_200, val_20, axis=0) -> val_201
Range(val_20, val_201, val_58) -> val_202
Unsqueeze(val_202, val_46) -> val_207
ScatterND(expand_1, val_207, slice_scatter_1, reduction=b'none') -> slice_scatter_2
Constant(value=[0, 1]) -> val_610
Unsqueeze(arange, val_610) -> unsqueeze_9
Cast(unsqueeze_9, to=1) -> _to_copy
MatMul(expand_2, _to_copy) -> matmul
Transpose(matmul, perm=[0,2,1]) -> transpose
Concat(transpose, transpose, axis=-1) -> cat
Cos(cat) -> cos
Unsqueeze(cos, val_19) -> unsqueeze_10
Sin(cat) -> sin
Unsqueeze(sin, val_19) -> unsqueeze_11
Transpose(model.layers.0.self_attn.q_proj.weight, perm=[1,0]) -> val_243
MatMul(layer_norm, val_243) -> val_244
Add(val_244, model.layers.0.self_attn.q_proj.bias) -> linear
Constant(value=[80]) -> val_249
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_250
Reshape(linear, val_250, allowzero=0) -> view_1
Transpose(view_1, perm=[0,2,1,3]) -> transpose_1
Transpose(model.layers.0.self_attn.k_proj.weight, perm=[1,0]) -> val_252
MatMul(layer_norm, val_252) -> val_253
Add(val_253, model.layers.0.self_attn.k_proj.bias) -> linear_1
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_258
Reshape(linear_1, val_258, allowzero=0) -> view_2
Transpose(view_2, perm=[0,2,1,3]) -> transpose_2
Transpose(model.layers.0.self_attn.v_proj.weight, perm=[1,0]) -> val_260
MatMul(layer_norm, val_260) -> val_261
Add(val_261, model.layers.0.self_attn.v_proj.bias) -> linear_2
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_266
Reshape(linear_2, val_266, allowzero=0) -> view_3
Transpose(view_3, perm=[0,2,1,3]) -> transpose_3
Concat(past_key_values_value_cache_0, transpose_3, axis=-2) -> cat_6
Constant(value=[0]) -> val_270
Constant(value=[32]) -> val_274
Constant(value=[3]) -> val_277
Constant(value_ints=[1]) -> val_278
Slice(transpose_1, val_270, val_274, val_277, val_278) -> slice_26
Mul(slice_26, unsqueeze_10) -> mul_213
Constant(value=[32]) -> val_281
Constant(value=[922337203...) -> val_284
Constant(value=[3]) -> val_287
Constant(value_ints=[1]) -> val_288
Slice(transpose_1, val_281, val_284, val_287, val_288) -> slice_27
Constant(value=[0]) -> val_291
Constant(value=[32]) -> val_294
Constant(value=[3]) -> val_297
Constant(value_ints=[1]) -> val_298
Slice(transpose_2, val_291, val_294, val_297, val_298) -> slice_28
Mul(slice_28, unsqueeze_10) -> mul_238
Constant(value=[32]) -> val_301
Constant(value=[922337203...) -> val_304
Constant(value=[3]) -> val_307
Constant(value_ints=[1]) -> val_308
Slice(transpose_2, val_301, val_304, val_307, val_308) -> slice_29
Constant(value=[0]) -> val_311
Constant(value=[16]) -> val_315
Constant(value=[3]) -> val_318
Constant(value_ints=[1]) -> val_319
Slice(slice_26, val_311, val_315, val_318, val_319) -> slice_30
Constant(value=[16]) -> val_322
Constant(value=[922337203...) -> val_325
Constant(value=[3]) -> val_328
Constant(value_ints=[1]) -> val_329
Slice(slice_26, val_322, val_325, val_328, val_329) -> slice_31
Neg(slice_31) -> neg
Concat(neg, slice_30, axis=-1) -> cat_1
Mul(cat_1, unsqueeze_11) -> mul_230
Add(mul_213, mul_230) -> add_290
Concat(add_290, slice_27, axis=-1) -> cat_3
Constant(value=[0]) -> val_332
Constant(value=[16]) -> val_335
Constant(value=[3]) -> val_338
Constant(value_ints=[1]) -> val_339
Slice(slice_28, val_332, val_335, val_338, val_339) -> slice_32
Constant(value=[16]) -> val_342
Constant(value=[922337203...) -> val_345
Constant(value=[3]) -> val_348
Constant(value_ints=[1]) -> val_349
Slice(slice_28, val_342, val_345, val_348, val_349) -> slice_33
Neg(slice_33) -> neg_1
Concat(neg_1, slice_32, axis=-1) -> cat_2
Mul(cat_2, unsqueeze_11) -> mul_255
Add(mul_238, mul_255) -> add_326
Concat(add_326, slice_29, axis=-1) -> cat_4
Concat(past_key_values_key_cache_0, cat_4, axis=-2) -> cat_5
Shape(cat_5, start=0) -> val_378
Constant(value_ints=[0]) -> val_368
Constant(value_ints=[-1]) -> val_370
Reshape(add_4, val_370, allowzero=0) -> val_371
Constant(value=[3]) -> val_374
Constant(value_ints=[1]) -> val_375
Slice(slice_scatter_2, val_368, val_371, val_374, val_375) -> slice_41
Constant(value_ints=[9223372036854775807]) -> val_379
Slice(val_378, val_46, val_379) -> val_380
Constant(value=[-2]) -> val_381
Slice(val_378, val_381, val_46) -> val_382
Constant(value_ints=[-9223372036854775808]) -> val_383
Slice(val_378, val_383, val_381) -> val_384
Concat(val_384, val_380, val_382, axis=0) -> val_389
Constant(value_ints=[-1]) -> val_385
Concat(val_385, val_382, val_380, axis=0) -> val_386
Reshape(cat_5, val_386, allowzero=0) -> val_387
Transpose(val_387, perm=[0,2,1]) -> val_388
Reshape(val_388, val_389, allowzero=0) -> val_390
Constant(value=0.33437013...) -> val_391
Mul(cat_3, val_391) -> val_392
Constant(value=0.33437013...) -> val_393
Mul(val_390, val_393) -> val_394
MatMul(val_392, val_394) -> val_395
Add(val_395, slice_41) -> val_396
Softmax(val_396, axis=-1) -> val_397
MatMul(val_397, cat_6) -> scaled_dot_product_attention
Transpose(scaled_dot_product_attention, perm=[0,2,1,3]) -> transpose_4
Concat(val_0, val_1, val_46, axis=0) -> val_404
Reshape(transpose_4, val_404, allowzero=0) -> view_4
Transpose(model.layers.0.self_attn.dense.weight, perm=[1,0]) -> val_406
MatMul(view_4, val_406) -> val_407
Add(val_407, model.layers.0.self_attn.dense.bias) -> linear_3
Transpose(model.layers.0.mlp.fc1.weight, perm=[1,0]) -> val_408
MatMul(layer_norm, val_408) -> val_409
Add(val_409, model.layers.0.mlp.fc1.bias) -> linear_4
Constant(value=0.5) -> val_410
Mul(linear_4, val_410) -> mul_326
Constant(value=3.0) -> val_411
Pow(linear_4, val_411) -> pow_1
Constant(value=0.04471499...) -> val_412
Mul(pow_1, val_412) -> mul_333
Add(linear_4, mul_333) -> add_415
Constant(value=0.79788458...) -> val_413
Mul(add_415, val_413) -> mul_340
Tanh(mul_340) -> tanh
Add(tanh, val_3) -> add_428
Mul(mul_326, add_428) -> mul_350
Transpose(model.layers.0.mlp.fc2.weight, perm=[1,0]) -> val_414
MatMul(mul_350, val_414) -> val_415
Add(val_415, model.layers.0.mlp.fc2.bias) -> linear_5
Add(linear_3, linear_5) -> add_445
Add(add_445, embedding) -> add_450
LayerNormalization(add_450, model.layers.1.input_layernorm.weight, model.layers.1.input_layernorm.bias, stash_type=1, epsilon=0.00, axis=-1) -> layer_norm_1
Transpose(model.layers.1.self_attn.q_proj.weight, perm=[1,0]) -> val_418
MatMul(layer_norm_1, val_418) -> val_419
Add(val_419, model.layers.1.self_attn.q_proj.bias) -> linear_6
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_424
Reshape(linear_6, val_424, allowzero=0) -> view_5
Transpose(view_5, perm=[0,2,1,3]) -> transpose_5
Transpose(model.layers.1.self_attn.k_proj.weight, perm=[1,0]) -> val_426
MatMul(layer_norm_1, val_426) -> val_427
Add(val_427, model.layers.1.self_attn.k_proj.bias) -> linear_7
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_432
Reshape(linear_7, val_432, allowzero=0) -> view_6
Transpose(view_6, perm=[0,2,1,3]) -> transpose_6
Transpose(model.layers.1.self_attn.v_proj.weight, perm=[1,0]) -> val_434
MatMul(layer_norm_1, val_434) -> val_435
Add(val_435, model.layers.1.self_attn.v_proj.bias) -> linear_8
Concat(val_0, val_1, val_46, val_249, axis=0) -> val_440
Reshape(linear_8, val_440, allowzero=0) -> view_7
Transpose(view_7, perm=[0,2,1,3]) -> transpose_7
Concat(past_key_values_value_cache_1, transpose_7, axis=-2) -> cat_12
Constant(value=[0]) -> val_444
Constant(value=[32]) -> val_447
Constant(value=[3]) -> val_450
Constant(value_ints=[1]) -> val_451
Slice(transpose_5, val_444, val_447, val_450, val_451) -> slice_42
Constant(value=[32]) -> val_454
Constant(value=[922337203...) -> val_457
Constant(value=[3]) -> val_460
Constant(value_ints=[1]) -> val_461
Slice(transpose_5, val_454, val_457, val_460, val_461) -> slice_43
Constant(value=[0]) -> val_464
Constant(value=[32]) -> val_467
Constant(value=[3]) -> val_470
Constant(value_ints=[1]) -> val_471
Slice(transpose_6, val_464, val_467, val_470, val_471) -> slice_44
Constant(value=[32]) -> val_474
Constant(value=[922337203...) -> val_477
Constant(value=[3]) -> val_480
Constant(value_ints=[1]) -> val_481
Slice(transpose_6, val_474, val_477, val_480, val_481) -> slice_45
Unsqueeze(cos, val_19) -> unsqueeze_12
Mul(slice_42, unsqueeze_12) -> mul_416
Unsqueeze(sin, val_19) -> unsqueeze_13
Constant(value=[0]) -> val_484
Constant(value=[16]) -> val_487
Constant(value=[3]) -> val_490
Constant(value_ints=[1]) -> val_491
Slice(slice_42, val_484, val_487, val_490, val_491) -> slice_46
Constant(value=[16]) -> val_494
Constant(value=[922337203...) -> val_497
Constant(value=[3]) -> val_500
Constant(value_ints=[1]) -> val_501
Slice(slice_42, val_494, val_497, val_500, val_501) -> slice_47
Neg(slice_47) -> neg_2
Concat(neg_2, slice_46, axis=-1) -> cat_7
Mul(cat_7, unsqueeze_13) -> mul_433
Add(mul_416, mul_433) -> add_557
Concat(add_557, slice_43, axis=-1) -> cat_9
Mul(slice_44, unsqueeze_12) -> mul_441
Constant(value=[0]) -> val_504
Constant(value=[16]) -> val_507
Constant(value=[3]) -> val_510
Constant(value_ints=[1]) -> val_511
Slice(slice_44, val_504, val_507, val_510, val_511) -> slice_48
Constant(value=[16]) -> val_514
Constant(value=[922337203...) -> val_517
Constant(value=[3]) -> val_520
Constant(value_ints=[1]) -> val_521
Slice(slice_44, val_514, val_517, val_520, val_521) -> slice_49
Neg(slice_49) -> neg_3
Concat(neg_3, slice_48, axis=-1) -> cat_8
Mul(cat_8, unsqueeze_13) -> mul_458
Add(mul_441, mul_458) -> add_593
Concat(add_593, slice_45, axis=-1) -> cat_10
Concat(past_key_values_key_cache_1, cat_10, axis=-2) -> cat_11
Shape(cat_11, start=0) -> val_549
Slice(val_549, val_381, val_46) -> val_552
Constant(value_ints=[0]) -> val_540
Constant(value_ints=[-1]) -> val_542
Reshape(add_4, val_542, allowzero=0) -> val_543
Constant(value=[3]) -> val_546
Constant(value_ints=[1]) -> val_547
Slice(slice_scatter_2, val_540, val_543, val_546, val_547) -> slice_57
Constant(value_ints=[9223372036854775807]) -> val_550
Slice(val_549, val_46, val_550) -> val_551
Constant(value_ints=[-9223372036854775808]) -> val_553
Slice(val_549, val_553, val_381) -> val_554
Concat(val_554, val_551, val_552, axis=0) -> val_559
Constant(value_ints=[-1]) -> val_555
Concat(val_555, val_552, val_551, axis=0) -> val_556
Reshape(cat_11, val_556, allowzero=0) -> val_557
Transpose(val_557, perm=[0,2,1]) -> val_558
Reshape(val_558, val_559, allowzero=0) -> val_560
Constant(value=0.33437013...) -> val_561
Mul(cat_9, val_561) -> val_562
Constant(value=0.33437013...) -> val_563
Mul(val_560, val_563) -> val_564
MatMul(val_562, val_564) -> val_565
Add(val_565, slice_57) -> val_566
Softmax(val_566, axis=-1) -> val_567
MatMul(val_567, cat_12) -> scaled_dot_product_attention_1
Transpose(scaled_dot_product_attention_1, perm=[0,2,1,3]) -> transpose_8
Concat(val_0, val_1, val_46, axis=0) -> val_574
Reshape(transpose_8, val_574, allowzero=0) -> view_8
Transpose(model.layers.1.self_attn.dense.weight, perm=[1,0]) -> val_576
MatMul(view_8, val_576) -> val_577
Add(val_577, model.layers.1.self_attn.dense.bias) -> linear_9
Transpose(model.layers.1.mlp.fc1.weight, perm=[1,0]) -> val_578
MatMul(layer_norm_1, val_578) -> val_579
Add(val_579, model.layers.1.mlp.fc1.bias) -> linear_10
Mul(linear_10, val_410) -> mul_529
Pow(linear_10, val_411) -> pow_2
Mul(pow_2, val_412) -> mul_536
Add(linear_10, mul_536) -> add_682
Mul(add_682, val_413) -> mul_543
Tanh(mul_543) -> tanh_1
Add(tanh_1, val_3) -> add_695
Mul(mul_529, add_695) -> mul_553
Transpose(model.layers.1.mlp.fc2.weight, perm=[1,0]) -> val_580
MatMul(mul_553, val_580) -> val_581
Add(val_581, model.layers.1.mlp.fc2.bias) -> linear_11
Add(linear_9, linear_11) -> add_712
Add(add_712, add_450) -> add_717
LayerNormalization(add_717, model.final_layernorm.weight, model.final_layernorm.bias, stash_type=1, epsilon=0.00, axis=-1) -> layer_norm_2
Transpose(lm_head.weight, perm=[1,0]) -> val_604
MatMul(layer_norm_2, val_604) -> val_605
Add(val_605, lm_head.bias) -> linear_12
output: name='linear_12' type=dtype('float32') shape=['batch', 'seq_length', 51200]
output: name='cat_5' type=dtype('float32') shape=['batch', 32, 'seq_length + cache_length', 80]
output: name='cat_11' type=dtype('float32') shape=['batch', 32, 'seq_length + cache_length', 80]
output: name='cat_6' type=dtype('float32') shape=['batch', 32, 'seq_length + cache_length', 80]
output: name='cat_12' type=dtype('float32') shape=['batch', 32, 'seq_length + cache_length', 80]
Visually.
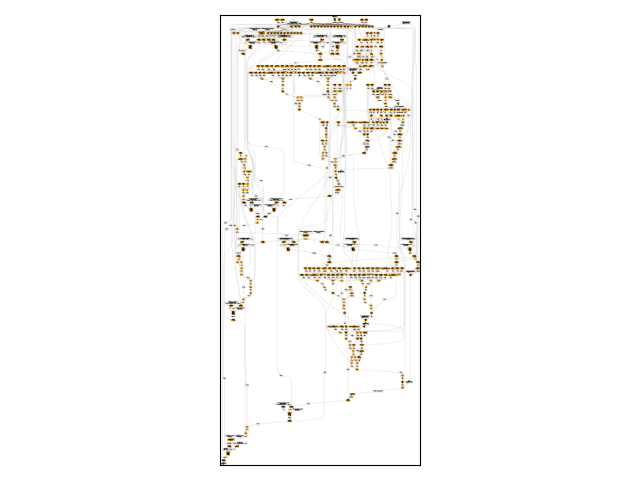
Total running time of the script: (0 minutes 19.737 seconds)
Related examples




Export Phi-3.5-mini-instruct with report_exportability