Note
Go to the end to download the full example code.
201: Evaluate different ways to export a torch model to ONNX¶
The example evaluates the performance of onnxruntime of a simple torch model after it was converted into ONNX through different processes:
TorchScript-based ONNX Exporter, let’s call it script
TorchDynamo-based ONNX Exporter, let’s call it dynamo
if available, the previous model but optimized, dynopt
a custom exporter cus_p0, this exporter supports a very limited set of models, as dynamo, it relies on torch.fx but the design is closer to what tensorflow-onnx does.
the same exporter but unused nodes were removed and constants were folded, cus_p2
To run the script:
python _doc/examples/plot_torch_export --help
The script takes around 12 minutes with a larger models.
Some helpers¶
from experimental_experiment.args import get_parsed_args
script_args = get_parsed_args(
"plot_torch_export",
description=__doc__,
scenarios={
"small": "small model to test",
"middle": "55Mb model",
"large": "1Gb model",
},
warmup=5,
repeat=5,
maxtime=(
2,
"maximum time to run a model to measure the computation time, "
"it is 0.1 when scenario is small",
),
expose="scenarios,repeat,warmup",
)
import contextlib
import itertools
import os
import platform
import pprint
import multiprocessing
import time
import cProfile
import pstats
import io
import warnings
import logging
from pstats import SortKey
try:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
import onnxruntime
has_cuda = "CUDAExecutionProvider" in onnxruntime.get_available_providers()
except ImportError:
print("onnxruntime not available.")
import sys
sys.exit(0)
import numpy as np
import matplotlib.pyplot as plt
import pandas
import onnx
from onnx_array_api.profiling import profile2graph
import torch
from torch import nn
import torch.nn.functional as F
import experimental_experiment
from experimental_experiment.torch_interpreter import to_onnx
from experimental_experiment.xbuilder import OptimizationOptions
from experimental_experiment.plotting.memory import memory_peak_plot
from experimental_experiment.ext_test_case import measure_time, get_figure
from experimental_experiment.memory_peak import start_spying_on
from experimental_experiment.ext_test_case import unit_test_going
from experimental_experiment.helpers import pretty_onnx
from tqdm import tqdm
has_cuda = has_cuda and torch.cuda.device_count() > 0
logging.disable(logging.ERROR)
def system_info():
obs = {}
obs["processor"] = platform.processor()
obs["cores"] = multiprocessing.cpu_count()
try:
obs["cuda"] = 1 if torch.cuda.device_count() > 0 else 0
obs["cuda_count"] = torch.cuda.device_count()
obs["cuda_name"] = torch.cuda.get_device_name()
obs["cuda_capa"] = torch.cuda.get_device_capability()
except (RuntimeError, AssertionError):
# no cuda
pass
return obs
pprint.pprint(system_info())
{'cores': 20,
'cuda': 1,
'cuda_capa': (8, 9),
'cuda_count': 1,
'cuda_name': 'NVIDIA GeForce RTX 4060 Laptop GPU',
'processor': 'x86_64'}
Scripts arguments
if script_args.scenario in (None, "small"):
script_args.maxtime = 0.1
if unit_test_going():
script_args.warmup = 1
script_args.repeat = 1
script_args.maxtime = 0.1
script_args.scenario = "small"
print(f"scenario={script_args.scenario or 'small'}")
print(f"warmup={script_args.warmup}")
print(f"repeat={script_args.repeat}")
print(f"maxtime={script_args.maxtime}")
scenario=small
warmup=5
repeat=5
maxtime=0.1
The model¶
A simple model to convert.
class MyModelClass(nn.Module):
def __init__(self, scenario=script_args.scenario):
super().__init__()
if scenario == "middle":
self.large = False
self.conv1 = nn.Conv2d(1, 128, 5)
self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(13456, 1024)
self.fcs = []
self.fc2 = nn.Linear(1024, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "small"):
self.large = False
self.conv1 = nn.Conv2d(1, 16, 5)
self.conv2 = nn.Conv2d(16, 16, 5)
self.fc1 = nn.Linear(16, 512)
self.fcs = []
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "large"):
self.large = True
self.conv1 = nn.Conv2d(1, 128, 5)
self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(13456, 4096)
# torch script does not support loops.
self.fca = nn.Linear(4096, 4096)
self.fcb = nn.Linear(4096, 4096)
self.fcc = nn.Linear(4096, 4096)
self.fcd = nn.Linear(4096, 4096)
self.fce = nn.Linear(4096, 4096)
self.fcf = nn.Linear(4096, 4096)
self.fcg = nn.Linear(4096, 4096)
self.fch = nn.Linear(4096, 4096)
self.fci = nn.Linear(4096, 4096)
self.fck = nn.Linear(4096, 4096)
self.fcl = nn.Linear(4096, 4096)
self.fcm = nn.Linear(4096, 4096)
self.fcn = nn.Linear(4096, 4096)
# end of the unfolded loop.
self.fc2 = nn.Linear(4096, 128)
self.fc3 = nn.Linear(128, 10)
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
if self.large:
# loop
x = F.relu(self.fca(x))
x = F.relu(self.fcb(x))
x = F.relu(self.fcc(x))
x = F.relu(self.fcd(x))
x = F.relu(self.fce(x))
x = F.relu(self.fcf(x))
x = F.relu(self.fcg(x))
x = F.relu(self.fch(x))
x = F.relu(self.fci(x))
x = F.relu(self.fck(x))
x = F.relu(self.fcl(x))
x = F.relu(self.fcm(x))
x = F.relu(self.fcn(x))
# end of the loop
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def create_model_and_input(scenario=script_args.scenario):
if scenario == "middle":
shape = [1, 1, 128, 128]
elif scenario in (None, "small"):
shape = [1, 1, 16, 16]
elif scenario == "large":
shape = [1, 1, 128, 128]
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
input_tensor = torch.rand(*shape).to(torch.float32)
model = MyModelClass(scenario=scenario)
assert model(input_tensor) is not None
return model, input_tensor
def torch_model_size(model):
size_model = 0
for param in model.parameters():
size = param.numel() * torch.finfo(param.data.dtype).bits / 8
size_model += size
return size_model
model, input_tensor = create_model_and_input()
model_size = torch_model_size(model)
print(f"model size={model_size / 2 ** 20} Mb")
model size=0.31467437744140625 Mb
The exporters¶
def export_script(filename, model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
torch.onnx.export(model, *args, filename, input_names=["input"], dynamo=False)
def export_dynamo(filename, model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
export_output = torch.onnx.export(model, args, dynamo=True)
export_output.save(filename)
def export_dynopt(filename, model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
export_output = torch.onnx.export(model, args, dynamo=True)
model_onnx = export_output.model_proto
from experimental_experiment.convert.convert_helper import (
optimize_model_proto_oxs,
)
optimized_model = optimize_model_proto_oxs(model_onnx)
with open(filename, "wb") as f:
f.write(optimized_model.SerializeToString())
def export_cus_p0(filename, model, *args):
onx = to_onnx(model, tuple(args), input_names=["input"])
with open(filename, "wb") as f:
f.write(onx.SerializeToString())
def export_cus_p2(filename, model, *args):
onx = to_onnx(
model,
tuple(args),
input_names=["input"],
options=OptimizationOptions(
remove_unused=True,
constant_folding=True,
),
)
with open(filename, "wb") as f:
f.write(onx.SerializeToString())
Let’s check they are working.
export_functions = [
export_script,
export_dynamo,
export_dynopt,
export_cus_p0,
export_cus_p2,
]
exporters = {f.__name__.replace("export_", ""): f for f in export_functions}
supported_exporters = {}
for k, v in exporters.items():
print(f"run exporter {k}")
filename = f"plot_torch_export_{k}.onnx"
try:
v(filename, model, input_tensor)
except Exception as e:
print(f"skipped due to {str(e)[:1000]}")
continue
supported_exporters[k] = v
print(f"done. size={os.stat(filename).st_size / 2 ** 20:1.0f} Mb")
run exporter script
done. size=0 Mb
run exporter dynamo
done. size=0 Mb
run exporter dynopt
done. size=0 Mb
run exporter cus_p0
done. size=0 Mb
run exporter cus_p2
done. size=0 Mb
Exporter memory¶
def flatten(ps):
obs = ps["cpu"].to_dict(unit=2**20)
if "gpus" in ps:
for i, g in enumerate(ps["gpus"]):
for k, v in g.to_dict(unit=2**20).items():
obs[f"gpu{i}_{k}"] = v
return obs
data = []
for k, v in supported_exporters.items():
print(f"run exporter for memory {k}")
filename = f"plot_torch_export_{k}.onnx"
if has_cuda:
torch.cuda.set_device(0)
stat = start_spying_on(cuda=1 if has_cuda else 0)
v(filename, model, input_tensor)
obs = flatten(stat.stop())
print("done.")
onx = onnx.load(filename)
obs.update(dict(nodes=len(onx.graph.node), export=k))
data.append(obs)
stat = start_spying_on(cuda=1 if has_cuda else 0)
exported_mod = torch.export.export(model, (input_tensor,))
obs = flatten(stat.stop())
obs.update(dict(export="torch.fx"))
data.append(obs)
run exporter for memory script
done.
run exporter for memory dynamo
done.
run exporter for memory dynopt
done.
run exporter for memory cus_p0
done.
run exporter for memory cus_p2
done.
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_export_memory.csv", index=False)
df1.to_excel("plot_torch_export_memory.xlsx", index=False)
print(df1)
ax = memory_peak_plot(
data,
bars=[model_size * i / 2**20 for i in range(1, 5)],
suptitle=f"Memory Consumption of the Export\nmodel size={model_size / 2**20:1.0f} Mb",
)
get_figure(ax).savefig("plot_torch_export_memory.png")
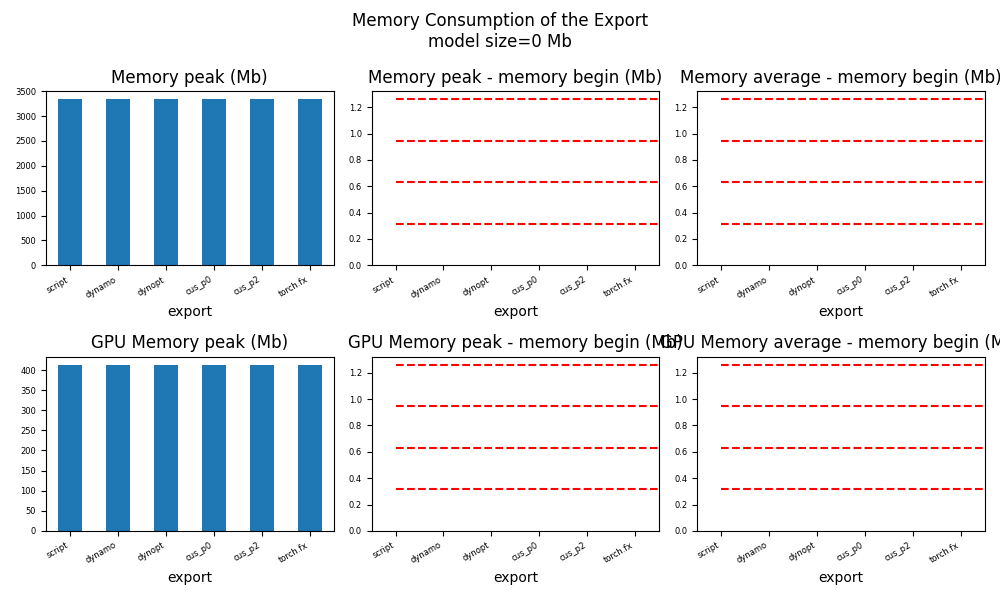
peak mean n begin end gpu0_peak gpu0_mean gpu0_n gpu0_begin gpu0_end nodes export
0 1404.710938 1404.710938 7 1404.710938 1404.710938 228.0 228.0 7 228.0 228.0 12.0 script
1 1404.867188 1404.789485 185 1404.710938 1404.867188 228.0 228.0 185 228.0 228.0 12.0 dynamo
2 1405.804688 1404.884389 109 1404.867188 1405.804688 228.0 228.0 109 228.0 228.0 12.0 dynopt
3 1405.804688 1405.804688 16 1405.804688 1405.804688 228.0 228.0 16 228.0 228.0 12.0 cus_p0
4 1405.804688 1398.350694 18 1405.804688 1384.328125 228.0 228.0 18 228.0 228.0 12.0 cus_p2
5 1384.484375 1384.484375 14 1384.484375 1384.484375 228.0 228.0 14 228.0 228.0 NaN torch.fx
Exporter speed¶
data = []
for k, v in supported_exporters.items():
print(f"run exporter {k}")
filename = f"plot_torch_export_{k}.onnx"
times = []
for _ in range(script_args.repeat):
begin = time.perf_counter()
v(filename, model, input_tensor)
duration = time.perf_counter() - begin
times.append(duration)
onx = onnx.load(filename)
print("done.")
data.append(
dict(
export=k,
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
nodes=len(onx.graph.node),
)
)
run exporter script
done.
run exporter dynamo
done.
run exporter dynopt
done.
run exporter cus_p0
done.
run exporter cus_p2
done.
The last export to measure time torch spends in export the model before any other export can begin the translation except the first one.
times = []
for _ in range(script_args.repeat):
begin = time.perf_counter()
exported_mod = torch.export.export(model, (input_tensor,))
duration = time.perf_counter() - begin
times.append(duration)
data.append(
dict(
export="torch.fx",
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
nodes=len(onx.graph.node),
)
)
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_export_time.csv", index=False)
df1.to_excel("plot_torch_export_time.xlsx", index=False)
print(df1)
fig, ax = plt.subplots(1, 1)
dfi = df1[["export", "time", "std"]].set_index("export")
dfi["time"].plot.bar(ax=ax, title="Export time", yerr=dfi["std"], rot=30)
fig.tight_layout()
fig.savefig("plot_torch_export_time.png")
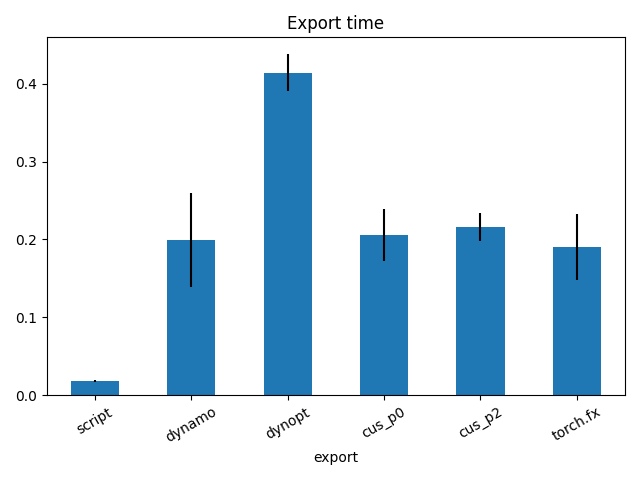
export time min max first last std nodes
0 script 0.048709 0.022770 0.070625 0.062456 0.022770 0.019654 12
1 dynamo 1.004575 0.862002 1.362329 0.935856 0.955861 0.181640 12
2 dynopt 1.036326 0.914716 1.383026 0.943404 0.982683 0.174739 12
3 cus_p0 0.094062 0.083099 0.100522 0.097758 0.083099 0.007024 12
4 cus_p2 0.091958 0.086763 0.098305 0.092338 0.088716 0.004021 12
5 torch.fx 0.059650 0.050677 0.068394 0.056890 0.062858 0.005915 12
Exporter Profiling¶
def clean_text(text):
pathes = [
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(torch.__file__), ".."))),
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(onnx.__file__), ".."))),
os.path.abspath(
os.path.normpath(
os.path.join(os.path.dirname(experimental_experiment.__file__), "..")
)
),
]
for p in pathes:
text = text.replace(p, "")
text = text.replace("experimental_experiment", "experimental_experiment".upper())
return text
def profile_function(name, export_function, verbose=False):
print(f"profile {name}: {export_function}")
pr = cProfile.Profile()
pr.enable()
for _ in range(script_args.repeat):
export_function("dummyc.onnx", model, input_tensor)
pr.disable()
s = io.StringIO()
sortby = SortKey.CUMULATIVE
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
raw = s.getvalue()
text = "\n".join(raw.split("\n")[:200])
if verbose:
print(text)
with open(f"plot_torch_export_profile_{name}.txt", "w") as f:
f.write(raw)
root, _nodes = profile2graph(ps, clean_text=clean_text)
text = root.to_text()
with open(f"plot_torch_export_profile_{name}_h.txt", "w") as f:
f.write(text)
print("done.")
profile_function("custom0", export_cus_p0, True)
profile_function("custom2", export_cus_p2)
profile custom0: <function export_cus_p0 at 0x7fc369213380>
798025 function calls (784962 primitive calls) in 0.969 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
80/20 0.001 0.000 0.590 0.029 ~/vv/this312/lib/python3.12/site-packages/torch/nn/functional.py:1712(relu)
35/5 0.001 0.000 0.369 0.074 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1783(_call_impl)
5 0.000 0.000 0.366 0.073 ~/vv/this312/lib/python3.12/site-packages/torch/export/_trace.py:2096(forward)
5 0.000 0.000 0.348 0.070 ~/github/experimental-experiment/_doc/examples/plot_torch_export_201.py:190(forward)
5 0.001 0.000 0.293 0.059 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:5769(to_onnx)
5 0.000 0.000 0.255 0.051 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6555(optimize)
1425 0.005 0.000 0.254 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1643(__torch_function__)
65 0.001 0.000 0.253 0.004 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6649(optimize_pass)
1425 0.005 0.000 0.243 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1673(__torch_function__)
2300 0.009 0.000 0.238 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:1141(__torch_function__)
5 0.000 0.000 0.225 0.045 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6838(optimize_with_patterns)
5 0.002 0.000 0.224 0.045 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:1546(optimize)
60 0.002 0.000 0.212 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:978(handler)
60 0.010 0.000 0.207 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_library/utils.py:307(handle_dispatch_mode)
365/125 0.001 0.000 0.194 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_stats.py:24(wrapper)
60 0.001 0.000 0.193 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1771(__torch_dispatch__)
60 0.003 0.000 0.192 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1079(proxy_call)
40/10 0.001 0.000 0.182 0.018 ~/vv/this312/lib/python3.12/site-packages/torch/_jit_internal.py:626(fn)
30 0.014 0.000 0.178 0.006 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:1348(_optimize_matching_step)
2505 0.048 0.000 0.159 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns_api.py:146(enumerate_matches)
20/5 0.000 0.000 0.136 0.027 {built-in method torch.flatten}
390/130 0.003 0.000 0.122 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/overrides.py:1690(handle_torch_function)
115 0.001 0.000 0.107 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:320(create_proxy)
120 0.001 0.000 0.100 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:2367(create_node)
120 0.001 0.000 0.099 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1397(create_node)
120 0.003 0.000 0.095 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:201(create_node)
340/175 0.000 0.000 0.089 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:864(__call__)
65 0.000 0.000 0.082 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:847(track_tensor_tree)
120/65 0.001 0.000 0.081 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:869(wrap_with_proxy)
5 0.000 0.000 0.073 0.015 ~/vv/this312/lib/python3.12/site-packages/torch/export/_trace.py:590(_produce_aten_artifact)
120 0.001 0.000 0.070 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_traceback.py:173(summary)
240 0.001 0.000 0.068 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1413(__torch_dispatch__)
1685/265 0.006 0.000 0.068 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1278(unflatten)
20 0.000 0.000 0.068 0.003 {built-in method torch.relu}
240 0.003 0.000 0.067 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2178(dispatch)
115 0.001 0.000 0.065 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:737(set_meta)
3520/3500 0.006 0.000 0.064 0.000 {built-in method builtins.next}
30 0.001 0.000 0.064 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:868(recompile)
95 0.001 0.000 0.063 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1505(_cached_dispatch_impl)
5 0.001 0.000 0.059 0.012 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:5423(process)
120 0.002 0.000 0.057 0.000 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/interpreter.py:187(run_node)
15 0.000 0.000 0.056 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/linear.py:130(forward)
60/15 0.001 0.000 0.056 0.004 {built-in method torch._C._nn.linear}
185 0.001 0.000 0.055 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1498(tree_map)
30 0.000 0.000 0.049 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1891(python_code)
120 0.010 0.000 0.044 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_traceback.py:252(_extract_symbolized_tb)
5 0.000 0.000 0.041 0.008 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:648(create_args_for_root)
55 0.001 0.000 0.041 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:892(meta_tensor)
10 0.000 0.000 0.040 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/conv.py:552(forward)
10 0.000 0.000 0.040 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/conv.py:534(_conv_forward)
40/10 0.000 0.000 0.040 0.004 {built-in method torch.conv2d}
495 0.000 0.000 0.039 0.000 {method 'extend' of 'list' objects}
870 0.001 0.000 0.039 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns_api.py:1001(match)
60 0.000 0.000 0.039 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:714(<genexpr>)
55 0.000 0.000 0.039 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:711(proxy_placeholder)
60 0.001 0.000 0.039 0.001 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/interpreter.py:1546(call_function)
115 0.002 0.000 0.039 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/shape_prop.py:40(_extract_tensor_metadata)
55 0.000 0.000 0.039 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:924(_proxy_placeholder)
1670/1660 0.002 0.000 0.038 0.000 /usr/lib/python3.12/contextlib.py:132(__enter__)
870 0.001 0.000 0.037 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns_api.py:390(_get_match_pattern)
55 0.000 0.000 0.037 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:928(replace_ph)
30 0.000 0.000 0.037 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1974(_python_code)
30 0.004 0.000 0.037 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:451(_gen_python_code)
55 0.002 0.000 0.036 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:293(__exit__)
40/10 0.000 0.000 0.035 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/nn/functional.py:812(_max_pool2d)
10 0.001 0.000 0.035 0.004 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns_api.py:333(_build_pattern)
205 0.005 0.000 0.035 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:4304(make_node)
10 0.000 0.000 0.033 0.003 {built-in method torch.max_pool2d}
185 0.001 0.000 0.033 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder_opset.py:116(make_node)
30/6 0.001 0.000 0.032 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:362(from_real_tensor)
8860 0.004 0.000 0.031 0.000 /usr/lib/python3.12/traceback.py:265(__init__)
108220/106960 0.027 0.000 0.031 0.000 {built-in method builtins.isinstance}
95 0.001 0.000 0.030 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1601(_cache_key)
95 0.001 0.000 0.030 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2101(_output_from_cache_entry)
105 0.003 0.000 0.030 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2016(_get_output_tensor_from_cache_entry)
1670/1660 0.002 0.000 0.029 0.000 /usr/lib/python3.12/contextlib.py:141(__exit__)
9200 0.007 0.000 0.028 0.000 /usr/lib/python3.12/traceback.py:318(line)
30/6 0.001 0.000 0.028 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:2046(__call__)
440/95 0.006 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1726(_prep_args_for_hash)
115 0.000 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/__init__.py:434(is_contiguous_for_memory_format_or_false)
115 0.000 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/__init__.py:397(is_contiguous_for_memory_format)
15 0.003 0.000 0.026 0.002 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns/__init__.py:151(get_default_patterns)
120 0.025 0.000 0.025 0.000 {built-in method torch._C._profiler.symbolize_tracebacks}
115 0.001 0.000 0.025 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/__init__.py:300(is_contiguous)
10 0.000 0.000 0.025 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:2175(tree_map_with_path)
10 0.000 0.000 0.025 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:498(__init__)
215/175 0.001 0.000 0.025 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1972(__setattr__)
5 0.000 0.000 0.024 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:391(make_fake_inputs)
25/5 0.000 0.000 0.024 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:3132(from_tensor)
115 0.000 0.000 0.023 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:635(extract_val)
115 0.000 0.000 0.023 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:609(snapshot_fake)
10 0.000 0.000 0.023 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:623(graph)
375 0.001 0.000 0.023 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1424(tree_flatten)
115 0.003 0.000 0.022 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_impls.py:1663(fast_detach)
10 0.000 0.000 0.022 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_export/passes/replace_with_hop_pass_util.py:172(_replace_with_hop_pass_helper)
1380 0.007 0.000 0.022 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns_api.py:124(__init__)
2345/375 0.005 0.000 0.022 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1432(helper)
55 0.003 0.000 0.021 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:289(__enter__)
20 0.000 0.000 0.021 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:2207(<genexpr>)
115 0.002 0.000 0.021 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/__init__.py:254(check_contiguous_sizes_strides)
5 0.001 0.000 0.021 0.004 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:4948(_build_initializers)
5 0.000 0.000 0.021 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:724(apply_runtime_assertion_pass)
720 0.003 0.000 0.021 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:706(emit_node)
5 0.001 0.000 0.021 0.004 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/onnx_export.py:873(build_source_lines)
275 0.006 0.000 0.020 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:735(__new__)
5795 0.019 0.000 0.019 0.000 {built-in method builtins.setattr}
510/210 0.006 0.000 0.018 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/__init__.py:888(sym_max)
15 0.000 0.000 0.018 0.001 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:69(__init__)
8860 0.008 0.000 0.018 0.000 /usr/lib/python3.12/linecache.py:26(getline)
50 0.002 0.000 0.018 0.000 ~/github/onnx-diagnostic/onnx_diagnostic/helpers/mini_onnx_builder.py:12(proto_from_array)
135 0.000 0.000 0.017 0.000 /usr/lib/python3.12/inspect.py:3308(signature)
135 0.000 0.000 0.017 0.000 /usr/lib/python3.12/inspect.py:3050(from_callable)
60 0.001 0.000 0.016 0.000 /usr/lib/python3.12/inspect.py:1251(getsourcelines)
265/135 0.003 0.000 0.016 0.000 /usr/lib/python3.12/inspect.py:2470(_signature_from_callable)
55 0.004 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:283(describe_tensor)
30 0.001 0.000 0.016 0.001 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:1451(_optimize_apply_step)
115 0.002 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:765(track_tensor)
55 0.007 0.000 0.015 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6964(remove_unused)
1350 0.002 0.000 0.015 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:199(is_sparse_any)
4660 0.004 0.000 0.015 0.000 <frozen _collections_abc>:804(get)
5 0.000 0.000 0.014 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:1090(__init__)
5 0.000 0.000 0.014 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_lazy_graph_module.py:57(_make_graph_module)
145 0.003 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1084(_flatten_into)
5 0.000 0.000 0.014 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1032(placeholder_naming_pass)
240 0.001 0.000 0.013 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:8116(_make_node_set_type_shape)
5 0.000 0.000 0.013 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/export/_trace.py:550(_replace_unbacked_bindings)
60 0.003 0.000 0.012 0.000 /usr/lib/python3.12/inspect.py:1232(getblock)
30 0.000 0.000 0.012 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:109(_forward_from_src)
30 0.000 0.000 0.012 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:115(_method_from_src)
30 0.000 0.000 0.012 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:104(_exec_with_source)
1050/115 0.004 0.000 0.012 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/symbolic_shapes.py:1177(_free_unbacked_symbols_with_path)
1675 0.004 0.000 0.012 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:868(__setattr__)
240 0.001 0.000 0.012 0.000 ~/github/experimental-experiment/experimental_experiment/xshape/shape_type_compute.py:1475(set_shape_type_op_any)
10 0.001 0.000 0.012 0.001 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:7028(constant_folding)
5 0.000 0.000 0.012 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_export/passes/replace_set_grad_with_hop_pass.py:120(replace_set_grad_with_hop_pass)
30 0.001 0.000 0.012 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:818(apply_match)
30 0.012 0.000 0.012 0.000 {built-in method builtins.compile}
115 0.002 0.000 0.011 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/symbolic_shapes.py:1222(match_tensor)
5 0.000 0.000 0.011 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:1728(_create_graph_module_for_export)
15 0.000 0.000 0.011 0.001 ~/github/experimental-experiment/experimental_experiment/xbuilder/optimization_options.py:65(__init__)
4660 0.006 0.000 0.011 0.000 <frozen os>:680(__getitem__)
5 0.000 0.000 0.011 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:475(<lambda>)
5 0.000 0.000 0.011 0.002 ~/github/experimental-experiment/experimental_experiment/xoptim/__init__.py:101(get_pattern_list)
5 0.000 0.000 0.011 0.002 ~/github/experimental-experiment/experimental_experiment/xoptim/__init__.py:14(get_pattern)
10 0.002 0.000 0.011 0.001 {built-in method torch._ops.aten.}
60 0.001 0.000 0.010 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1948(override_node_repr)
155 0.001 0.000 0.010 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:1269(_check_graph)
50 0.010 0.000 0.010 0.000 {method 'clone' of 'torch._C.TensorBase' objects}
5 0.000 0.000 0.010 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_export/passes/replace_autocast_with_hop_pass.py:201(replace_autocast_with_hop_pass)
420 0.003 0.000 0.010 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:1986(set_shape)
5 0.000 0.000 0.010 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:168(fakify)
135 0.004 0.000 0.010 0.000 /usr/lib/python3.12/inspect.py:2366(_signature_from_function)
50/40 0.000 0.000 0.010 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:1264(compute_constant)
50/40 0.002 0.000 0.010 0.000 ~/github/experimental-experiment/experimental_experiment/xshape/_inference_runtime.py:306(compute_constant)
45 0.004 0.000 0.010 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:7298(remove_identity_nodes)
385/235 0.001 0.000 0.010 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1360(create_arg)
5 0.000 0.000 0.010 0.002 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/_aten_functions.py:3733(aten_flatten_using_ints)
5 0.000 0.000 0.009 0.002 ~/github/experimental-experiment/experimental_experiment/xoptim/patterns/onnx_functions.py:509(match_pattern)
35310 0.009 0.000 0.009 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:217(is_used)
55 0.001 0.000 0.009 0.000 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/interpreter.py:596(placeholder)
49140/49090 0.009 0.000 0.009 0.000 {built-in method builtins.len}
145 0.003 0.000 0.009 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1106(extract_tensor_metadata)
1735/1650 0.002 0.000 0.009 0.000 {built-in method builtins.all}
125 0.007 0.000 0.009 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:1195(_check_graph_nodes)
15 0.000 0.000 0.009 0.001 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/_aten_functions.py:6832(aten_linear)
1375 0.003 0.000 0.008 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:643(__set__)
8920 0.006 0.000 0.008 0.000 /usr/lib/python3.12/linecache.py:36(getlines)
5 0.002 0.000 0.008 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/runtime_assert.py:54(insert_deferred_runtime_asserts)
10 0.000 0.000 0.008 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/frontend_utils.py:219(_detect_attribute_assignment)
10 0.000 0.000 0.008 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:1185(_new_patcher)
5 0.000 0.000 0.008 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:1153(revert_all_patches)
3545 0.003 0.000 0.008 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1049(_get_node_type)
31250 0.008 0.000 0.008 0.000 {method 'append' of 'list' objects}
4485 0.005 0.000 0.008 0.000 /usr/lib/python3.12/tokenize.py:569(_generate_tokens_from_c_tokenizer)
2570 0.002 0.000 0.008 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1061(tree_is_leaf)
10 0.000 0.000 0.008 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:1097(revert)
385/235 0.002 0.000 0.008 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:367(create_arg)
365/295 0.002 0.000 0.008 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/recording.py:258(wrapper)
55 0.005 0.000 0.008 0.000 ~/github/experimental-experiment/experimental_experiment/xoptim/graph_builder_optim.py:156(_build)
90 0.001 0.000 0.008 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:2958(add_initializer)
10 0.000 0.000 0.008 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:1132(patch_method)
1570 0.003 0.000 0.007 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:194(is_sparse_compressed)
10 0.000 0.000 0.007 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:1100(patch)
5 0.000 0.000 0.007 0.001 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:5711(_update_metadata_props)
85 0.001 0.000 0.007 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6433(_check)
12920 0.005 0.000 0.007 0.000 {method 'get' of 'dict' objects}
55 0.001 0.000 0.007 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:403(mk_fake_tensor)
60 0.000 0.000 0.007 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:382(_call_method_with_signature_check)
250 0.001 0.000 0.007 0.000 ~/github/experimental-experiment/experimental_experiment/xshape/_inference_runtime.py:86(_make_node_set_type_shape_constant)
4220 0.003 0.000 0.007 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:6947(_enumerate_inputs_with_subgraph_plus_hidden)
250 0.002 0.000 0.007 0.000 ~/github/onnx/onnx/helper.py:133(make_node)
110 0.001 0.000 0.007 0.000 ~/github/experimental-experiment/experimental_experiment/xbuilder/graph_builder.py:7187(_refresh_values_cache)
60 0.002 0.000 0.007 0.000 ~/github/experimental-experiment/experimental_experiment/torch_interpreter/interpreter.py:1995(_set_shape_and_type)
1350 0.003 0.000 0.006 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:180(is_sparse_coo)
2300 0.005 0.000 0.006 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:1041(_override)
done.
profile custom2: <function export_cus_p2 at 0x7fc369213f60>
done.
Same with dynamo-exporter.
profile_function("dynamo", export_dynamo, verbose=True)
if "dynopt" in supported_exporters:
profile_function("dynopt", export_dynopt)
profile dynamo: <function export_dynamo at 0x7fc3692111c0>
11584626 function calls (11398216 primitive calls) in 10.626 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.012 0.002 4.222 0.844 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_registration.py:159(from_torchlib)
5 0.078 0.016 3.577 0.715 ~/github/onnxscript/onnxscript/_framework_apis/torch_2_5.py:111(get_torchlib_ops)
2395 0.029 0.000 3.483 0.001 ~/github/onnxscript/onnxscript/_internal/values.py:481(function_ir)
2395 0.017 0.000 1.772 0.001 ~/github/onnxscript/onnxscript/_internal/ast_utils.py:13(get_src_and_ast)
10 0.003 0.000 1.737 0.174 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1361(_collect_all_valid_cia_ops)
340 0.017 0.000 1.733 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1344(_collect_all_valid_cia_ops_for_namespace)
340 0.536 0.002 1.588 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1278(_materialize_cpp_cia_ops)
2395 0.008 0.000 1.586 0.001 ~/github/onnxscript/onnxscript/_internal/converter.py:1476(translate_function_signature)
11240/10180 0.012 0.000 1.539 0.000 {built-in method builtins.next}
4975/4450 0.015 0.000 1.459 0.000 /usr/lib/python3.12/contextlib.py:132(__enter__)
5 0.009 0.002 1.417 0.283 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_decomp.py:40(create_onnx_friendly_decomposition_table)
2395 0.078 0.000 1.394 0.001 ~/github/onnxscript/onnxscript/_internal/converter.py:1400(_translate_function_signature_common)
2720 0.028 0.000 1.317 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_registration.py:61(__post_init__)
10 0.177 0.018 1.299 0.130 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:191(_override_composite_implicit_decomp)
2720 0.103 0.000 1.274 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_schemas.py:193(op_signature_from_function)
2395 0.005 0.000 1.228 0.001 /usr/lib/python3.12/inspect.py:1272(getsource)
2395 0.113 0.000 1.220 0.001 /usr/lib/python3.12/inspect.py:1251(getsourcelines)
105/6 0.003 0.000 0.993 0.166 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:362(from_real_tensor)
110/6 0.003 0.000 0.989 0.165 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:2046(__call__)
36/5 0.002 0.000 0.987 0.197 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:3132(from_tensor)
5 0.009 0.002 0.980 0.196 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:275(_split_decomp_table_to_cia_and_python_decomp)
2395 0.258 0.000 0.916 0.000 /usr/lib/python3.12/inspect.py:1232(getblock)
5 0.000 0.000 0.858 0.172 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:141(items)
5 0.000 0.000 0.858 0.172 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:158(_materialize_if_needed)
5 0.002 0.000 0.858 0.172 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:145(materialize)
94365/17045 0.166 0.000 0.773 0.000 ~/github/onnxscript/onnxscript/_internal/type_annotation.py:112(is_value_type)
25175 0.748 0.000 0.748 0.000 {built-in method builtins.compile}
80/20 0.001 0.000 0.696 0.035 ~/vv/this312/lib/python3.12/site-packages/torch/nn/functional.py:1712(relu)
64195 0.095 0.000 0.673 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:117(py_impl)
1156505 0.591 0.000 0.597 0.000 {built-in method builtins.getattr}
129410 0.212 0.000 0.583 0.000 <frozen _collections_abc>:469(__new__)
303545 0.336 0.000 0.581 0.000 /usr/lib/python3.12/tokenize.py:569(_generate_tokens_from_c_tokenizer)
1818095/1810145 0.414 0.000 0.542 0.000 {built-in method builtins.isinstance}
5 0.000 0.000 0.535 0.107 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:322(default_decompositions)
5 0.004 0.001 0.535 0.107 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:48(__init__)
1170/760 0.007 0.000 0.524 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_stats.py:24(wrapper)
5850 0.506 0.000 0.507 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1392(_get_decomp_for_cia)
7190 0.010 0.000 0.500 0.000 ~/github/onnxscript/onnxscript/_internal/converter.py:496(_get_type_annotation)
9855 0.008 0.000 0.499 0.000 ~/github/onnxscript/onnxscript/_internal/type_annotation.py:153(is_valid_type)
29630/4545 0.164 0.000 0.495 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_schemas.py:133(_get_allowed_types_from_type_annotation)
3550 0.011 0.000 0.493 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1643(__torch_function__)
2415 0.029 0.000 0.455 0.000 /usr/lib/python3.12/ast.py:34(parse)
45/15 0.002 0.000 0.424 0.028 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1783(_call_impl)
5 0.000 0.000 0.419 0.084 ~/vv/this312/lib/python3.12/site-packages/torch/export/_trace.py:2096(forward)
5 0.000 0.000 0.394 0.079 ~/github/experimental-experiment/_doc/examples/plot_torch_export_201.py:190(forward)
110 0.001 0.000 0.387 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/functional_utils.py:32(to_fun)
64195 0.308 0.000 0.387 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:121(inner)
2720 0.051 0.000 0.379 0.000 /usr/lib/python3.12/typing.py:2186(get_type_hints)
230 0.002 0.000 0.350 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1771(__torch_dispatch__)
120 0.008 0.000 0.337 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1079(proxy_call)
94365 0.081 0.000 0.313 0.000 ~/github/onnxscript/onnxscript/_internal/type_annotation.py:104(_is_tensor_type)
940 0.002 0.000 0.294 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1413(__torch_dispatch__)
1425 0.007 0.000 0.293 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1673(__torch_function__)
940 0.011 0.000 0.290 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2178(dispatch)
7190 0.005 0.000 0.287 0.000 ~/github/onnxscript/onnxscript/_internal/type_annotation.py:149(is_attr_type)
2300 0.007 0.000 0.286 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/non_strict_utils.py:1141(__torch_function__)
140/10 0.001 0.000 0.277 0.028 ~/github/ir-py/src/onnx_ir/passes/_pass_infra.py:112(__call__)
340 0.276 0.001 0.276 0.001 {built-in method torch._C._dispatch_get_registrations_for_dispatch_key}
430 0.005 0.000 0.275 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1505(_cached_dispatch_impl)
20/10 0.000 0.000 0.268 0.027 ~/github/ir-py/src/onnx_ir/passes/_pass_infra.py:245(call)
60 0.002 0.000 0.265 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:978(handler)
5 0.000 0.000 0.264 0.053 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_onnx_program.py:317(optimize)
5 0.000 0.000 0.264 0.053 ~/github/onnxscript/onnxscript/_framework_apis/torch_2_8.py:27(optimize)
5 0.000 0.000 0.263 0.053 ~/github/onnxscript/onnxscript/optimizer/_optimizer.py:17(optimize_ir)
128390 0.149 0.000 0.262 0.000 <frozen _collections_abc>:511(_is_param_expr)
230 0.073 0.000 0.261 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/functional_tensor.py:400(__torch_dispatch__)
60 0.013 0.000 0.259 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_library/utils.py:307(handle_dispatch_mode)
5 0.000 0.000 0.249 0.050 ~/github/ir-py/src/onnx_ir/passes/_pass_infra.py:311(call)
301150 0.132 0.000 0.245 0.000 /usr/lib/python3.12/collections/__init__.py:447(_make)
95 0.004 0.000 0.237 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:868(recompile)
12140 0.029 0.000 0.234 0.000 ~/github/onnxscript/onnxscript/_internal/converter.py:472(_eval_constant_expr)
97855 0.065 0.000 0.219 0.000 ~/github/onnxscript/onnxscript/_internal/type_annotation.py:71(_remove_annotation)
40/10 0.001 0.000 0.200 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_jit_internal.py:626(fn)
2960 0.003 0.000 0.193 0.000 /usr/lib/python3.12/inspect.py:3308(signature)
7685 0.006 0.000 0.192 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1264(_is_preservable_cia_op)
2960 0.004 0.000 0.189 0.000 /usr/lib/python3.12/inspect.py:3050(from_callable)
140550 0.104 0.000 0.187 0.000 /usr/lib/python3.12/typing.py:2310(get_origin)
628210 0.186 0.000 0.186 0.000 {method 'split' of 'str' objects}
3190/2960 0.029 0.000 0.185 0.000 /usr/lib/python3.12/inspect.py:2470(_signature_from_callable)
2395 0.014 0.000 0.184 0.000 ~/github/onnxscript/onnxscript/_internal/irbuilder.py:22(__init__)
95 0.001 0.000 0.177 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1891(python_code)
2395 0.028 0.000 0.173 0.000 /usr/lib/python3.12/inspect.py:1063(findsource)
10 0.000 0.000 0.169 0.017 ~/github/onnxscript/onnxscript/rewriter/__init__.py:82(call)
10 0.000 0.000 0.169 0.017 ~/github/onnxscript/onnxscript/rewriter/_rewrite_rule.py:779(apply_to_model)
230 0.001 0.000 0.165 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:320(create_proxy)
10 0.004 0.000 0.162 0.016 ~/github/onnxscript/onnxscript/rewriter/_rewrite_rule.py:641(_apply_to_graph_or_function)
7685 0.092 0.000 0.162 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1313(_check_valid_to_preserve)
1153585/1153065 0.159 0.000 0.159 0.000 {built-in method builtins.len}
70 0.001 0.000 0.158 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_higher_order_ops/utils.py:38(autograd_not_implemented_inner)
52780/52730 0.030 0.000 0.157 0.000 {built-in method builtins.repr}
5850 0.007 0.000 0.157 0.000 ~/github/onnxscript/onnxscript/rewriter/_rewrite_rule.py:302(try_rewrite)
20/5 0.000 0.000 0.154 0.031 {built-in method torch.flatten}
41095 0.028 0.000 0.154 0.000 ~/github/ir-py/src/onnx_ir/_core.py:2417(__hash__)
240 0.002 0.000 0.152 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:2367(create_node)
240 0.001 0.000 0.149 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1397(create_node)
2400 0.024 0.000 0.148 0.000 ~/github/ir-py/src/onnx_ir/_core.py:3159(__init__)
5850 0.008 0.000 0.145 0.000 ~/github/onnxscript/onnxscript/rewriter/_rewrite_rule.py:100(match)
510/250 0.003 0.000 0.144 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/overrides.py:1690(handle_torch_function)
23950/10525 0.024 0.000 0.143 0.000 /usr/lib/python3.12/typing.py:406(_eval_type)
10525 0.016 0.000 0.141 0.000 /usr/lib/python3.12/typing.py:885(__init__)
240 0.006 0.000 0.141 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:201(create_node)
95 0.001 0.000 0.138 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1974(_python_code)
95 0.014 0.000 0.136 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:451(_gen_python_code)
10525 0.027 0.000 0.132 0.000 /usr/lib/python3.12/typing.py:909(_evaluate)
5 0.000 0.000 0.129 0.026 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_fx_passes.py:22(insert_type_promotion_nodes)
2960 0.046 0.000 0.126 0.000 /usr/lib/python3.12/inspect.py:2366(_signature_from_function)
5850 0.013 0.000 0.124 0.000 ~/github/onnxscript/onnxscript/rewriter/_matcher.py:347(match)
135605/135590 0.056 0.000 0.124 0.000 {built-in method builtins.any}
5 0.000 0.000 0.124 0.025 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/_pass.py:227(run)
5 0.000 0.000 0.124 0.025 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1660(_run)
130 0.000 0.000 0.122 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:847(track_tensor_tree)
120 0.001 0.000 0.121 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1580(run_node)
240/130 0.001 0.000 0.119 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:869(wrap_with_proxy)
435765 0.117 0.000 0.117 0.000 {built-in method __new__ of type object at 0xa43b40}
430 0.005 0.000 0.110 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1601(_cache_key)
10 0.001 0.000 0.108 0.011 ~/vv/this312/lib/python3.12/site-packages/torch/export/_trace.py:590(_produce_aten_artifact)
5 0.000 0.000 0.105 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/export/exported_program.py:1432(module)
5 0.001 0.000 0.104 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/export/_unlift.py:754(_unlift_exported_program_lifted_states)
4010 0.016 0.000 0.104 0.000 ~/github/onnxscript/onnxscript/_internal/converter.py:134(make_value)
365 0.002 0.000 0.102 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2101(_output_from_cache_entry)
385 0.011 0.000 0.101 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2016(_get_output_tensor_from_cache_entry)
45490 0.045 0.000 0.100 0.000 ~/github/ir-py/src/onnx_ir/_core.py:2425(__repr__)
170 0.004 0.000 0.100 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:892(meta_tensor)
17055/540 0.034 0.000 0.098 0.000 /usr/lib/python3.12/copy.py:118(deepcopy)
1700/430 0.020 0.000 0.097 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1726(_prep_args_for_hash)
180 0.001 0.000 0.097 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_traceback.py:173(summary)
665 0.004 0.000 0.096 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/traceback.py:97(__init__)
980 0.002 0.000 0.094 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:269(_set_current_node)
116955 0.043 0.000 0.093 0.000 <frozen abc>:117(__instancecheck__)
230 0.002 0.000 0.092 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:737(set_meta)
91345 0.041 0.000 0.090 0.000 {built-in method builtins.issubclass}
4975/4450 0.005 0.000 0.090 0.000 /usr/lib/python3.12/contextlib.py:141(__exit__)
980 0.003 0.000 0.089 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/traceback.py:433(set_current_meta)
5720 0.007 0.000 0.089 0.000 ~/github/onnxscript/onnxscript/rewriter/_matcher.py:288(_match_single_output_node)
1925/535 0.003 0.000 0.089 0.000 /usr/lib/python3.12/copy.py:191(_deepcopy_list)
30 0.001 0.000 0.086 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:498(__init__)
20 0.000 0.000 0.085 0.004 {built-in method torch.relu}
835/705 0.004 0.000 0.084 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1972(__setattr__)
226511 0.066 0.000 0.084 0.000 {built-in method builtins.hasattr}
1565/735 0.016 0.000 0.083 0.000 /usr/lib/python3.12/copy.py:247(_reconstruct)
22690 0.062 0.000 0.083 0.000 {built-in method builtins.eval}
15 0.000 0.000 0.081 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/linear.py:130(forward)
60/15 0.001 0.000 0.080 0.005 {built-in method torch._C._nn.linear}
165745 0.052 0.000 0.080 0.000 /usr/lib/python3.12/inspect.py:295(isclass)
2295 0.014 0.000 0.079 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:706(emit_node)
510 0.002 0.000 0.079 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1708(tree_map_only)
301150 0.076 0.000 0.076 0.000 /usr/lib/python3.12/inspect.py:1189(tokeneater)
5850/5720 0.013 0.000 0.076 0.000 ~/github/onnxscript/onnxscript/rewriter/_matcher.py:134(_match_node)
30 0.000 0.000 0.076 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:623(graph)
170 0.005 0.000 0.076 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:293(__exit__)
7210 0.015 0.000 0.073 0.000 ~/github/onnxscript/onnxscript/_internal/irbuilder.py:68(append_parameter)
10 0.000 0.000 0.071 0.007 ~/github/onnxscript/onnxscript/optimizer/_constant_folding.py:1388(call)
10 0.000 0.000 0.071 0.007 ~/github/onnxscript/onnxscript/optimizer/_constant_folding.py:1364(visit_graph)
135 0.001 0.000 0.070 0.001 ~/github/onnxscript/onnxscript/optimizer/_constant_folding.py:1353(visit_node)
2395 0.014 0.000 0.070 0.000 /usr/lib/python3.12/textwrap.py:419(dedent)
1975 0.001 0.000 0.069 0.000 {method 'extend' of 'list' objects}
5 0.001 0.000 0.067 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_core.py:1044(_exported_program_to_onnx_program)
135220 0.041 0.000 0.067 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_lazy_import.py:19(__getattr__)
10 0.000 0.000 0.066 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:648(create_args_for_root)
135 0.003 0.000 0.065 0.000 ~/github/onnxscript/onnxscript/optimizer/_constant_folding.py:1143(process_node)
120 0.000 0.000 0.063 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:714(<genexpr>)
110 0.000 0.000 0.063 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:711(proxy_placeholder)
110 0.000 0.000 0.063 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:924(_proxy_placeholder)
1370/560 0.008 0.000 0.062 0.000 /usr/lib/python3.12/copy.py:217(_deepcopy_dict)
4800 0.022 0.000 0.062 0.000 ~/github/ir-py/src/onnx_ir/_graph_containers.py:30(__init__)
110 0.001 0.000 0.061 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/_symbolic_trace.py:928(replace_ph)
5 0.000 0.000 0.061 0.012 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_core.py:766(_translate_fx_graph)
180 0.013 0.000 0.060 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_traceback.py:252(_extract_symbolized_tb)
2395 0.014 0.000 0.058 0.000 /usr/lib/python3.12/inspect.py:944(getsourcefile)
1295 0.003 0.000 0.058 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1424(tree_flatten)
60 0.002 0.000 0.058 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/exporter/_core.py:511(_handle_call_function_node_with_lowering)
4685/1920 0.005 0.000 0.057 0.000 ~/github/ir-py/src/onnx_ir/serde.py:97(wrapper)
65 0.000 0.000 0.056 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2400(_dispatch_impl)
92245 0.034 0.000 0.055 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:874(__hash__)
5850/1295 0.015 0.000 0.055 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1432(helper)
110 0.001 0.000 0.051 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/functional_tensor.py:232(to_functional)
125 0.005 0.000 0.050 0.000 ~/github/onnxscript/onnxscript/optimizer/_constant_folding.py:1005(_do_inference)
116955 0.050 0.000 0.050 0.000 {built-in method _abc._abc_instancecheck}
78310 0.025 0.000 0.050 0.000 <frozen abc>:121(__subclasscheck__)
785 0.015 0.000 0.050 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:735(__new__)
95 0.000 0.000 0.049 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:109(_forward_from_src)
565 0.013 0.000 0.049 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1084(_flatten_into)
95 0.000 0.000 0.049 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:115(_method_from_src)
45490 0.021 0.000 0.049 0.000 ~/github/ir-py/src/onnx_ir/_enums.py:375(__repr__)
3990 0.017 0.000 0.049 0.000 ~/github/onnxscript/onnxscript/_internal/converter.py:122(set_type_info)
95 0.000 0.000 0.049 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:104(_exec_with_source)
230 0.004 0.000 0.048 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/shape_prop.py:40(_extract_tensor_metadata)
128390 0.047 0.000 0.047 0.000 <frozen _collections_abc>:521(<genexpr>)
10555 0.029 0.000 0.047 0.000 /usr/lib/python3.12/typing.py:175(_type_check)
10 0.000 0.000 0.046 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/conv.py:552(forward)
10 0.000 0.000 0.046 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/conv.py:534(_conv_forward)
40/10 0.001 0.000 0.046 0.005 {built-in method torch.conv2d}
12180 0.006 0.000 0.044 0.000 /usr/lib/python3.12/traceback.py:265(__init__)
2395 0.033 0.000 0.044 0.000 /usr/lib/python3.12/inspect.py:1599(getclosurevars)
170 0.008 0.000 0.043 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:289(__enter__)
done.
profile dynopt: <function export_dynopt at 0x7fc369211080>
done.
Benchmark exported models with ORT¶
def benchmark(shape):
from onnxruntime import InferenceSession, SessionOptions, GraphOptimizationLevel
providers = [["CPUExecutionProvider"]]
if has_cuda:
providers.append(["CUDAExecutionProvider", "CPUExecutionProvider"])
data = []
data1 = []
data_mem_load = []
data_mem_first_run = []
data_mem_run = []
confs = list(
itertools.product(
[_ for _ in os.listdir(".") if ".onnx" in _ and _.startswith("plot_torch")],
providers,
["0", "1"],
)
)
loop = tqdm(confs)
print(f"number of experiments: {len(loop)}")
for name, ps, aot in loop:
root = os.path.split(name)[-1]
_, ext = os.path.splitext(root)
if ext != ".onnx":
continue
obs = {} # system_info()
obs["name"] = name
obs["providers"] = ",".join(ps)
p = "CUDA" if "CUDA" in obs["providers"] else "CPU"
obs["compute"] = p
obs["aot"] = 1 if aot == "0" else 0
obs["export"] = name.replace("plot_torch_export_", "").replace(".onnx", "")
if not has_cuda and p == "CUDA":
continue
onx = onnx.load(name)
obs["n_nodes"] = len(onx.graph.node)
obs["n_function"] = len(onx.functions or [])
obs["n_sub"] = len([n for n in onx.graph.node if n.op_type == "Sub"])
obs1 = obs.copy()
short_obs = dict(
name=obs["name"],
aot=obs["aot"],
providers=obs["providers"],
export=obs["export"],
compute=obs["compute"],
)
opts = SessionOptions()
opts.add_session_config_entry("session.disable_aot_function_inlining", aot)
opts.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
opts.optimized_model_filepath = (
f"ort-{name.replace('.onnx', '')}-{p.lower()}-aot{1 if aot == '0' else 0}.onnx"
)
try:
InferenceSession(name, opts, providers=ps)
except Exception as e:
loop.set_description(f"ERROR-load: {name} {e}")
obs.update({"error": e, "step": "run"})
data.append(obs)
continue
opts = SessionOptions()
opts.add_session_config_entry("session.disable_aot_function_inlining", aot)
opts.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
stat = start_spying_on(cuda=1 if has_cuda else 0)
sess = InferenceSession(name, opts, providers=ps)
memobs = flatten(stat.stop())
memobs.update(short_obs)
data_mem_load.append(memobs)
input_name = sess.get_inputs()[0].name
feeds = {input_name: np.random.rand(*shape).astype(np.float32)}
stat = start_spying_on(cuda=1 if has_cuda else 0)
try:
sess.run(None, feeds)
except Exception as e:
loop.set_description(f"ERROR-run: {name} {e}")
obs.update({"error": e, "step": "load"})
data.append(obs)
stat.stop()
continue
memobs = flatten(stat.stop())
memobs.update(short_obs)
data_mem_first_run.append(memobs)
# memory consumption
stat = start_spying_on(cuda=1 if has_cuda else 0)
for _ in range(0, script_args.warmup):
sess.run(None, feeds)
memobs = flatten(stat.stop())
memobs.update(short_obs)
data_mem_run.append(memobs)
obs.update(
measure_time(
lambda sess=sess, feeds=feeds: sess.run(None, feeds),
max_time=script_args.maxtime,
repeat=script_args.repeat,
number=1,
)
)
loop.set_description(f"{obs['average']} {name} {ps}")
data.append(obs)
# check first run
obs1.update(
measure_time(
lambda name=name, opts=opts, ps=ps, feeds=feeds: InferenceSession(
name, opts, providers=ps
).run(None, feeds),
max_time=script_args.maxtime,
repeat=max(1, script_args.repeat // 2),
number=1,
)
)
data1.append(obs1)
df = pandas.DataFrame(data)
df.to_csv("plot_torch_export_ort_time.csv", index=False)
df.to_excel("plot_torch_export_ort_time.xlsx", index=False)
df1 = pandas.DataFrame(data1)
df1.to_csv("plot_torch_export_ort_time1_init.csv", index=False)
df1.to_excel("plot_torch_export_ort_time1_init.xlsx", index=False)
dfmem = pandas.DataFrame(data_mem_load)
dfmem.to_csv("plot_torch_export_ort_load_mem.csv", index=False)
dfmem.to_excel("plot_torch_export_ort_load_mem.xlsx", index=False)
dfmemr = pandas.DataFrame(data_mem_run)
dfmemr.to_csv("plot_torch_export_ort_run_mem.csv", index=False)
dfmemr.to_excel("plot_torch_export_ort_run_mem.xlsx", index=False)
dfmemfr = pandas.DataFrame(data_mem_first_run)
dfmemfr.to_csv("plot_torch_export_ort_first_run_mem.csv", index=False)
dfmemfr.to_excel("plot_torch_export_ort_first_run_mem.xlsx", index=False)
return df, df1, dfmem, dfmemfr, dfmemr
df, df_init, dfmem, dfmemfr, dfmemr = benchmark(list(input_tensor.shape))
print(df)
0%| | 0/20 [00:00<?, ?it/s]number of experiments: 20
5.196440707559396e-05 plot_torch_export_dynamo.onnx ['CPUExecutionProvider']: 0%| | 0/20 [00:01<?, ?it/s]
5.196440707559396e-05 plot_torch_export_dynamo.onnx ['CPUExecutionProvider']: 5%|▌ | 1/20 [00:01<00:30, 1.58s/it]
5.053627429977076e-05 plot_torch_export_dynamo.onnx ['CPUExecutionProvider']: 5%|▌ | 1/20 [00:02<00:30, 1.58s/it]
5.053627429977076e-05 plot_torch_export_dynamo.onnx ['CPUExecutionProvider']: 10%|█ | 2/20 [00:02<00:17, 1.01it/s]
0.0013196850374697533 plot_torch_export_dynamo.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 10%|█ | 2/20 [00:03<00:17, 1.01it/s]
0.0013196850374697533 plot_torch_export_dynamo.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 15%|█▌ | 3/20 [00:04<00:24, 1.46s/it]
0.0007776961069822797 plot_torch_export_dynamo.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 15%|█▌ | 3/20 [00:04<00:24, 1.46s/it]
0.0007776961069822797 plot_torch_export_dynamo.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 20%|██ | 4/20 [00:05<00:19, 1.21s/it]
6.436455284409006e-05 plot_torch_export_cus_p0.onnx ['CPUExecutionProvider']: 20%|██ | 4/20 [00:05<00:19, 1.21s/it]
6.436455284409006e-05 plot_torch_export_cus_p0.onnx ['CPUExecutionProvider']: 25%|██▌ | 5/20 [00:05<00:15, 1.06s/it]
6.348425179674001e-05 plot_torch_export_cus_p0.onnx ['CPUExecutionProvider']: 25%|██▌ | 5/20 [00:06<00:15, 1.06s/it]
6.348425179674001e-05 plot_torch_export_cus_p0.onnx ['CPUExecutionProvider']: 30%|███ | 6/20 [00:06<00:12, 1.11it/s]
0.0008477141745970584 plot_torch_export_cus_p0.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 30%|███ | 6/20 [00:06<00:12, 1.11it/s]
0.0008477141745970584 plot_torch_export_cus_p0.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 35%|███▌ | 7/20 [00:07<00:10, 1.19it/s]
0.0007154740203887883 plot_torch_export_cus_p0.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 35%|███▌ | 7/20 [00:07<00:10, 1.19it/s]
0.0007154740203887883 plot_torch_export_cus_p0.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 40%|████ | 8/20 [00:07<00:10, 1.19it/s]
6.23697390871889e-05 plot_torch_export_script.onnx ['CPUExecutionProvider']: 40%|████ | 8/20 [00:08<00:10, 1.19it/s]
6.23697390871889e-05 plot_torch_export_script.onnx ['CPUExecutionProvider']: 45%|████▌ | 9/20 [00:08<00:08, 1.23it/s]
5.571763742161256e-05 plot_torch_export_script.onnx ['CPUExecutionProvider']: 45%|████▌ | 9/20 [00:09<00:08, 1.23it/s]
5.571763742161256e-05 plot_torch_export_script.onnx ['CPUExecutionProvider']: 50%|█████ | 10/20 [00:09<00:07, 1.34it/s]
0.0009944041713467976 plot_torch_export_script.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 50%|█████ | 10/20 [00:09<00:07, 1.34it/s]
0.0009944041713467976 plot_torch_export_script.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 55%|█████▌ | 11/20 [00:10<00:06, 1.36it/s]
0.000837844577312708 plot_torch_export_script.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 55%|█████▌ | 11/20 [00:10<00:06, 1.36it/s]
0.000837844577312708 plot_torch_export_script.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 60%|██████ | 12/20 [00:10<00:05, 1.35it/s]
5.374119440659195e-05 plot_torch_export_dynopt.onnx ['CPUExecutionProvider']: 60%|██████ | 12/20 [00:11<00:05, 1.35it/s]
5.374119440659195e-05 plot_torch_export_dynopt.onnx ['CPUExecutionProvider']: 65%|██████▌ | 13/20 [00:11<00:05, 1.36it/s]
5.13675154305629e-05 plot_torch_export_dynopt.onnx ['CPUExecutionProvider']: 65%|██████▌ | 13/20 [00:11<00:05, 1.36it/s]
5.13675154305629e-05 plot_torch_export_dynopt.onnx ['CPUExecutionProvider']: 70%|███████ | 14/20 [00:12<00:04, 1.43it/s]
0.0007943697628200961 plot_torch_export_dynopt.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 70%|███████ | 14/20 [00:12<00:04, 1.43it/s]
0.0007943697628200961 plot_torch_export_dynopt.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 75%|███████▌ | 15/20 [00:12<00:03, 1.41it/s]
0.0008465271097168537 plot_torch_export_dynopt.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 75%|███████▌ | 15/20 [00:12<00:03, 1.41it/s]
0.0008465271097168537 plot_torch_export_dynopt.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 80%|████████ | 16/20 [00:12<00:02, 1.87it/s]
5.404545977769311e-05 plot_torch_export_cus_p2.onnx ['CPUExecutionProvider']: 80%|████████ | 16/20 [00:13<00:02, 1.87it/s]
5.404545977769311e-05 plot_torch_export_cus_p2.onnx ['CPUExecutionProvider']: 85%|████████▌ | 17/20 [00:13<00:01, 1.74it/s]
5.436445345249805e-05 plot_torch_export_cus_p2.onnx ['CPUExecutionProvider']: 85%|████████▌ | 17/20 [00:14<00:01, 1.74it/s]
5.436445345249805e-05 plot_torch_export_cus_p2.onnx ['CPUExecutionProvider']: 90%|█████████ | 18/20 [00:14<00:01, 1.71it/s]
0.000796550877566915 plot_torch_export_cus_p2.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 90%|█████████ | 18/20 [00:14<00:01, 1.71it/s]
0.000796550877566915 plot_torch_export_cus_p2.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 95%|█████████▌| 19/20 [00:14<00:00, 1.65it/s]
0.0007828382893982373 plot_torch_export_cus_p2.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 95%|█████████▌| 19/20 [00:15<00:00, 1.65it/s]
0.0007828382893982373 plot_torch_export_cus_p2.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 100%|██████████| 20/20 [00:15<00:00, 1.51it/s]
0.0007828382893982373 plot_torch_export_cus_p2.onnx ['CUDAExecutionProvider', 'CPUExecutionProvider']: 100%|██████████| 20/20 [00:15<00:00, 1.27it/s]
name providers compute aot export n_nodes ... max_exec repeat number ttime context_size warmup_time
0 plot_torch_export_dynamo.onnx CPUExecutionProvider CPU 1 dynamo 12 ... 0.000291 1 1980.0 0.102890 64 0.000313
1 plot_torch_export_dynamo.onnx CPUExecutionProvider CPU 0 dynamo 12 ... 0.000099 1 2202.0 0.111281 64 0.000368
2 plot_torch_export_dynamo.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 1 dynamo 12 ... 0.003420 1 80.0 0.105575 64 0.002313
3 plot_torch_export_dynamo.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 0 dynamo 12 ... 0.000966 1 159.0 0.123654 64 0.001939
4 plot_torch_export_cus_p0.onnx CPUExecutionProvider CPU 1 cus_p0 12 ... 0.000098 1 2583.0 0.166254 64 0.000329
5 plot_torch_export_cus_p0.onnx CPUExecutionProvider CPU 0 cus_p0 12 ... 0.000250 1 1668.0 0.105892 64 0.000408
6 plot_torch_export_cus_p0.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 1 cus_p0 12 ... 0.000963 1 126.0 0.106812 64 0.001706
7 plot_torch_export_cus_p0.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 0 cus_p0 12 ... 0.000969 1 147.0 0.105175 64 0.001779
8 plot_torch_export_script.onnx CPUExecutionProvider CPU 1 script 12 ... 0.000077 1 2039.0 0.127172 64 0.000278
9 plot_torch_export_script.onnx CPUExecutionProvider CPU 0 script 12 ... 0.000159 1 2154.0 0.120016 64 0.000367
10 plot_torch_export_script.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 1 script 12 ... 0.001143 1 105.0 0.104412 64 0.001871
11 plot_torch_export_script.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 0 script 12 ... 0.001680 1 123.0 0.103055 64 0.001771
12 plot_torch_export_dynopt.onnx CPUExecutionProvider CPU 1 dynopt 12 ... 0.000113 1 2361.0 0.126883 64 0.000442
13 plot_torch_export_dynopt.onnx CPUExecutionProvider CPU 0 dynopt 12 ... 0.000127 1 2301.0 0.118197 64 0.000307
14 plot_torch_export_dynopt.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 1 dynopt 12 ... 0.000826 1 156.0 0.123922 64 0.001774
15 plot_torch_export_dynopt.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 0 dynopt 12 ... 0.001020 1 155.0 0.131212 64 0.001636
16 plot_torch_export_cus_p2.onnx CPUExecutionProvider CPU 1 cus_p2 12 ... 0.000095 1 1927.0 0.104146 64 0.000271
17 plot_torch_export_cus_p2.onnx CPUExecutionProvider CPU 0 cus_p2 12 ... 0.000069 1 2331.0 0.126724 64 0.000245
18 plot_torch_export_cus_p2.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 1 cus_p2 12 ... 0.000912 1 147.0 0.117093 64 0.001420
19 plot_torch_export_cus_p2.onnx CUDAExecutionProvider,CPUExecutionProvider CUDA 0 cus_p2 12 ... 0.000873 1 159.0 0.124471 64 0.001856
[20 rows x 17 columns]
Other view
def view_time(df, title, suffix="time"):
piv = pandas.pivot_table(df, index="export", columns=["compute", "aot"], values="average")
print(piv)
piv.to_csv(f"plot_torch_export_ort_{suffix}_compute.csv")
piv.to_excel(f"plot_torch_export_ort_{suffix}_compute.xlsx")
piv_cpu = pandas.pivot_table(
df[df.compute == "CPU"],
index="export",
columns=["compute", "aot"],
values="average",
)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
fig.suptitle(title)
piv_cpu.plot.barh(ax=ax[0], title="CPU")
if has_cuda:
piv_gpu = pandas.pivot_table(
df[df.compute == "CUDA"],
index="export",
columns=["compute", "aot"],
values="average",
)
piv_gpu.plot.barh(ax=ax[1], title="CUDA")
fig.tight_layout()
fig.savefig(f"plot_torch_export_ort_{suffix}.png")
return ax
view_time(df, "Compares onnxruntime time on exported models")
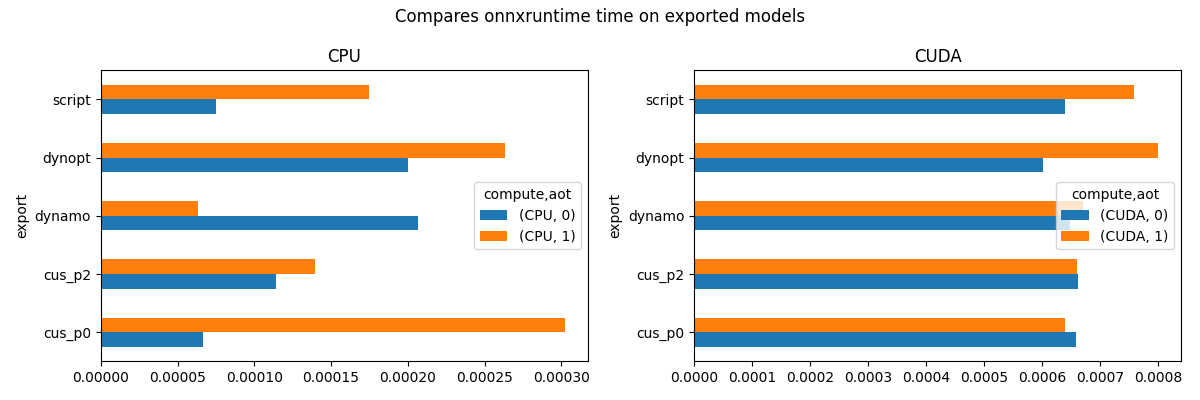
compute CPU CUDA
aot 0 1 0 1
export
cus_p0 0.000063 0.000064 0.000715 0.000848
cus_p2 0.000054 0.000054 0.000783 0.000797
dynamo 0.000051 0.000052 0.000778 0.001320
dynopt 0.000051 0.000054 0.000847 0.000794
script 0.000056 0.000062 0.000838 0.000994
array([<Axes: title={'center': 'CPU'}, ylabel='export'>,
<Axes: title={'center': 'CUDA'}, ylabel='export'>], dtype=object)
New graph without the very long times.
piv_cpu = pandas.pivot_table(
df[
(df.compute == "CPU")
& ((df.aot == 1) | ((df.export != "dynamo") & (df.export != "dynopt")))
],
index="export",
columns=["compute", "aot"],
values="average",
)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
fig.suptitle("Compares onnxruntime time on exported models\nHide dynamo without AOT")
piv_cpu.plot.barh(ax=ax[0], title="CPU")
if has_cuda:
piv_gpu = pandas.pivot_table(
df[df.compute == "CUDA"],
index="export",
columns=["compute", "aot"],
values="average",
)
piv_gpu.plot.barh(ax=ax[1], title="CUDA")
fig.tight_layout()
fig.savefig("plot_torch_export_ort_time_2.png")
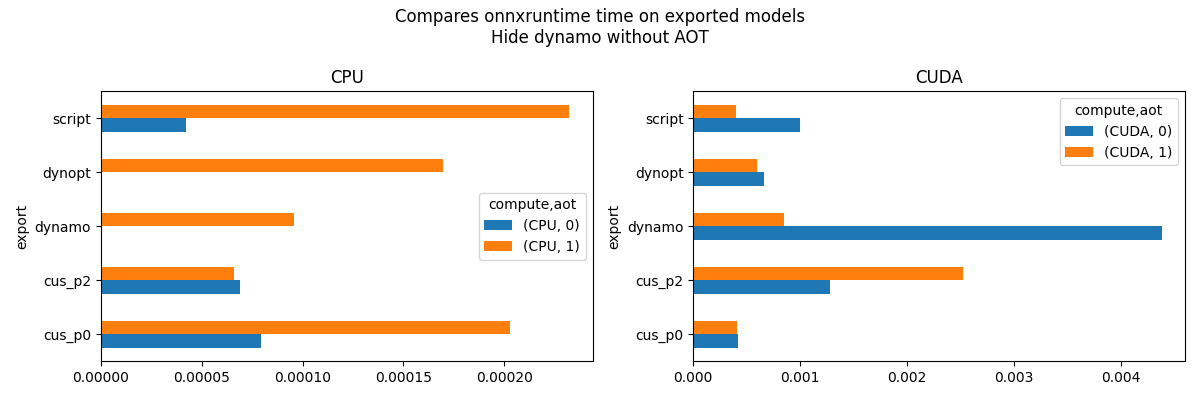
Let’s do the same with the loading time + the first run.
view_time(
df_init,
"Compares onnxruntime loading time and first run on exported models",
suffix="time1_init",
)
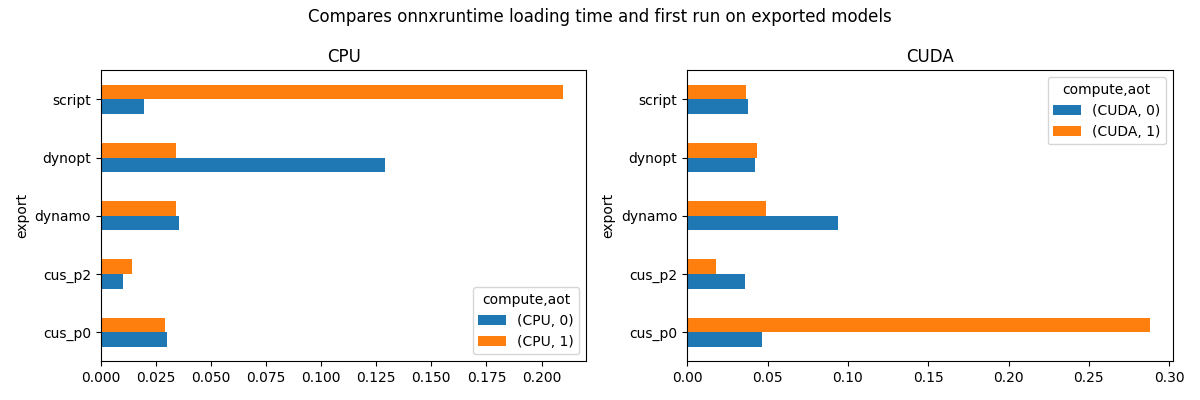
compute CPU CUDA
aot 0 1 0 1
export
cus_p0 0.005286 0.005893 0.029163 0.025077
cus_p2 0.004541 0.004890 0.024594 0.021803
dynamo 0.006686 0.004742 0.024105 0.037000
dynopt 0.004909 0.005128 0.024729 0.024557
script 0.004419 0.005550 0.026196 0.020388
array([<Axes: title={'center': 'CPU'}, ylabel='export'>,
<Axes: title={'center': 'CUDA'}, ylabel='export'>], dtype=object)
Memory Loading Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmem[dfmem.compute == compute],
("export", "aot"),
suptitle=f"Memory Consumption of onnxruntime loading time\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_export_ort_load_mem_{compute}.png")
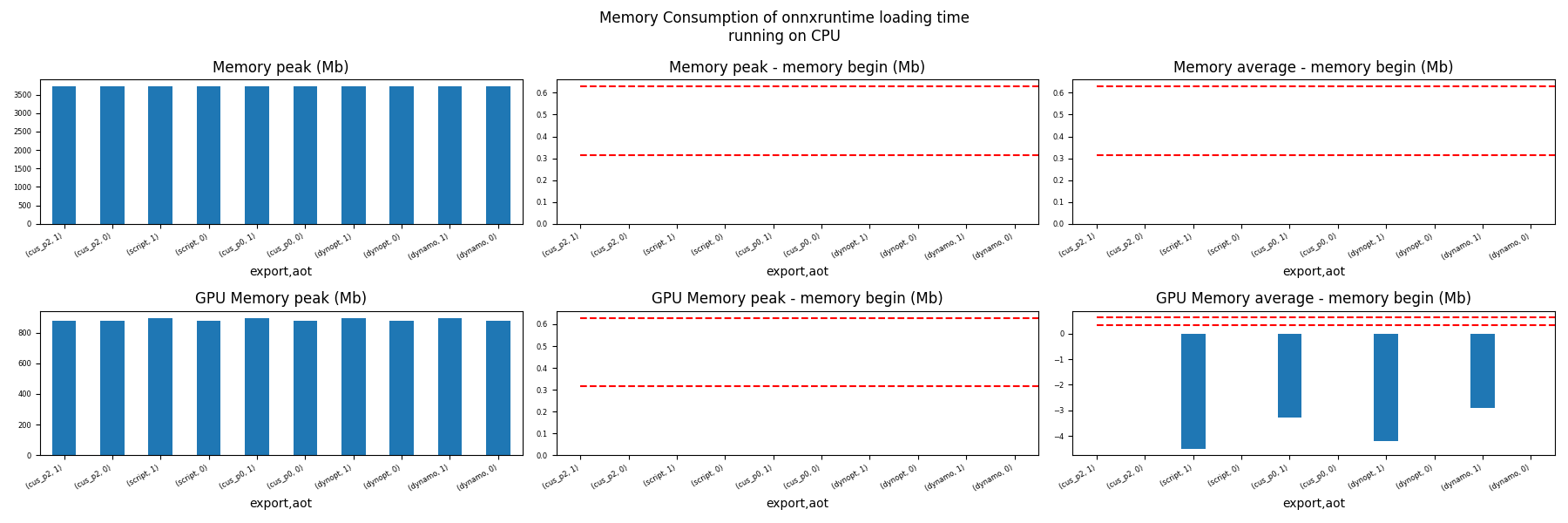
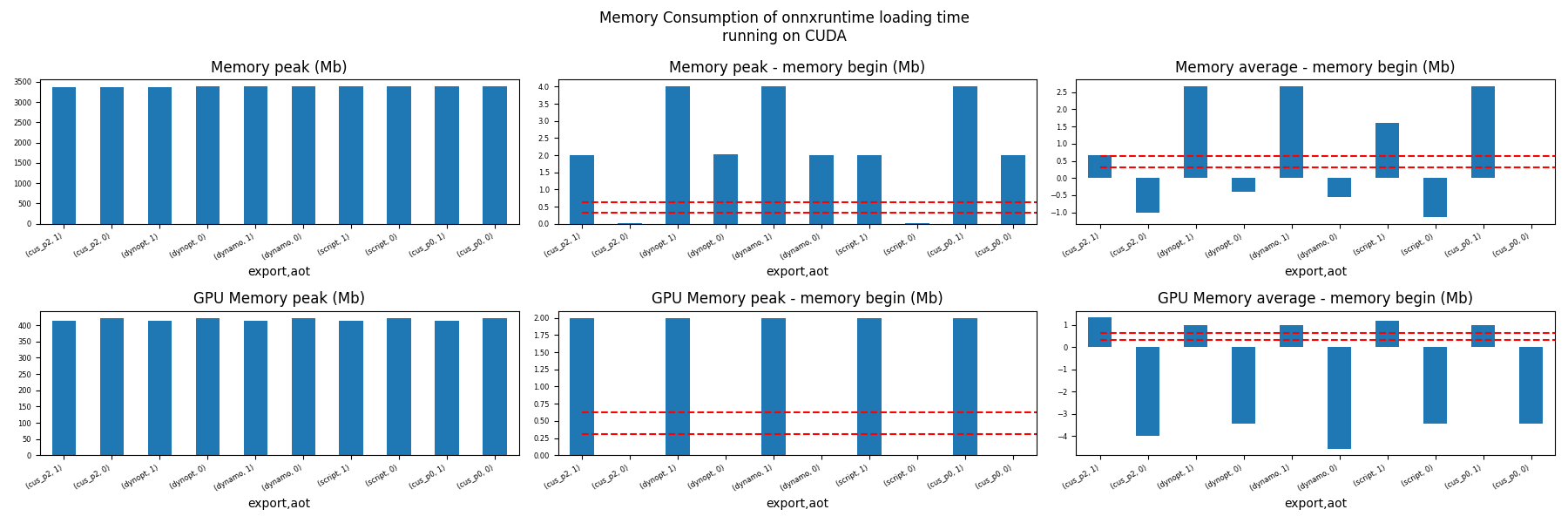
Memory First Running Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemfr[dfmemfr.compute == compute],
("export", "aot"),
suptitle=f"Memory Consumption of onnxruntime first running time"
f"\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_export_ort_first_run_mem_{compute}.png")
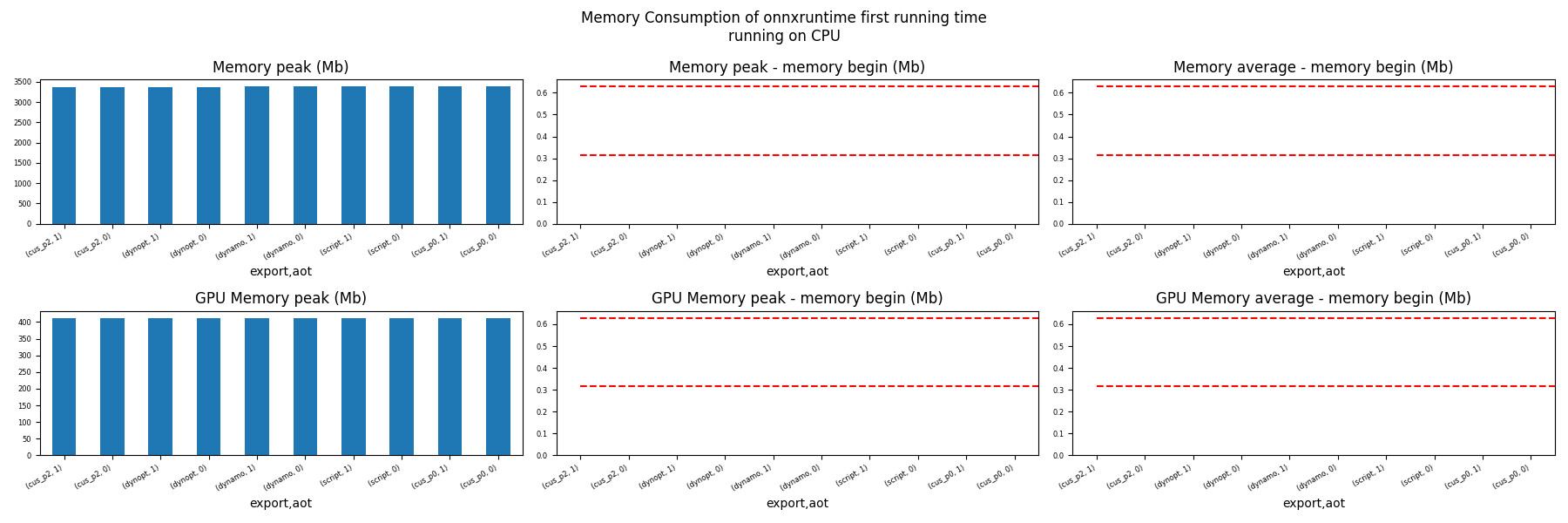
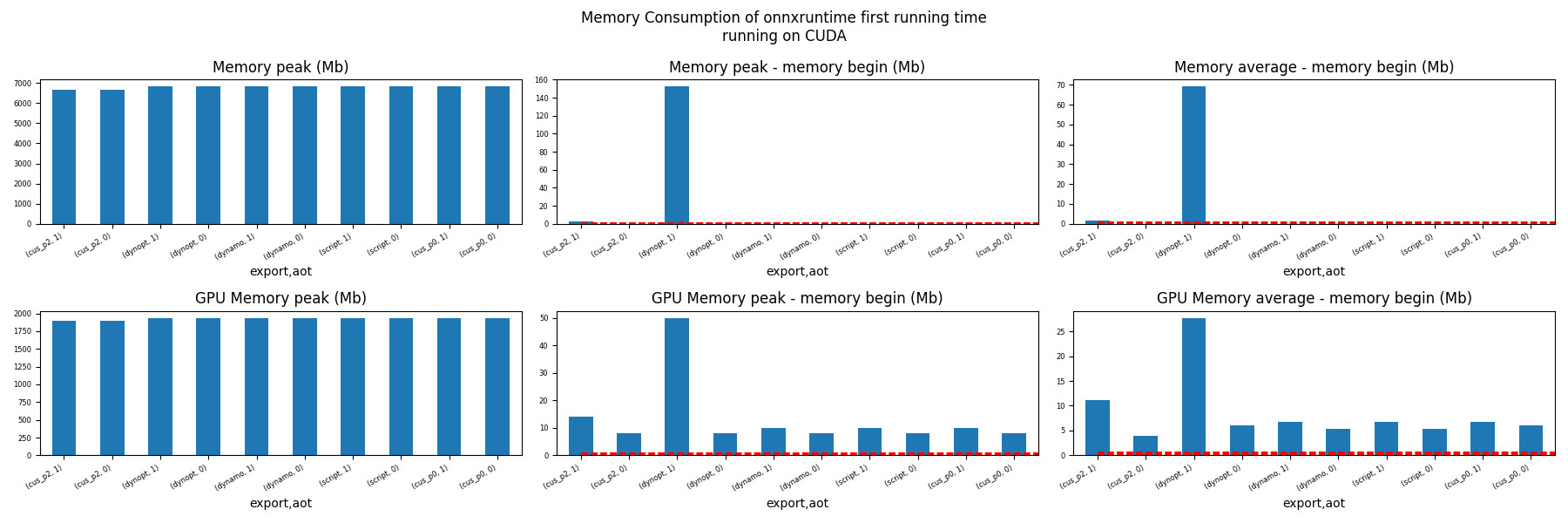
Memory Running Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemr[dfmemr.compute == compute],
("export", "aot"),
suptitle=f"Memory Consumption of onnxruntime running time\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_export_ort_run_mem_{compute}.png")
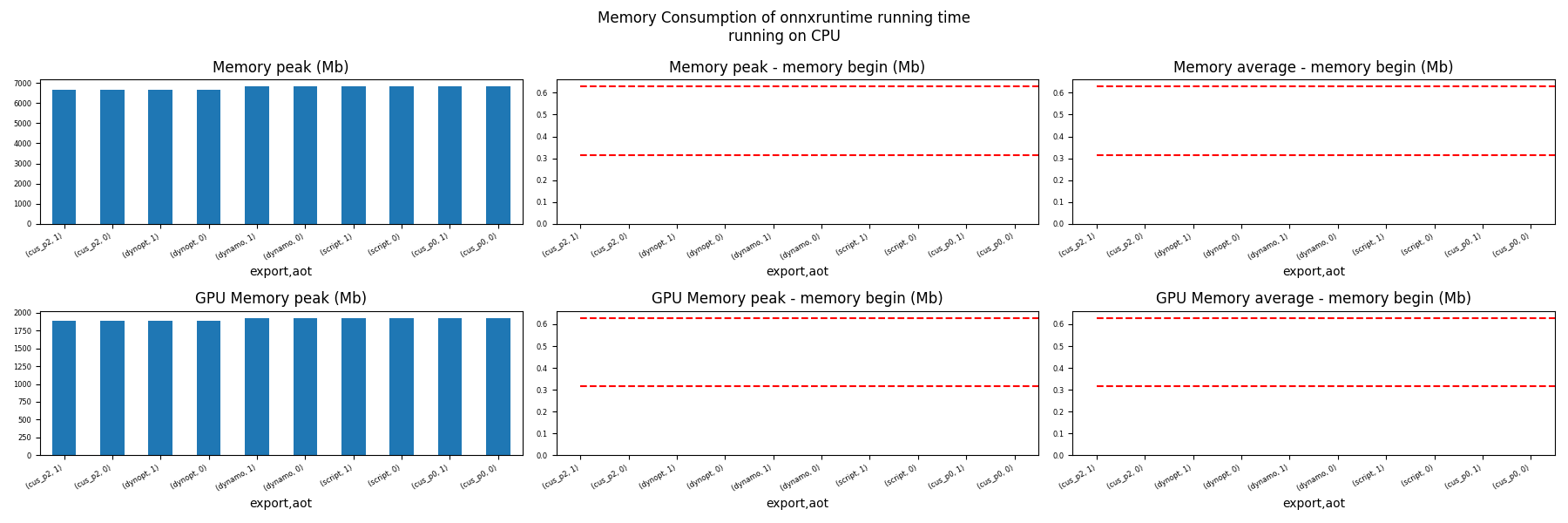
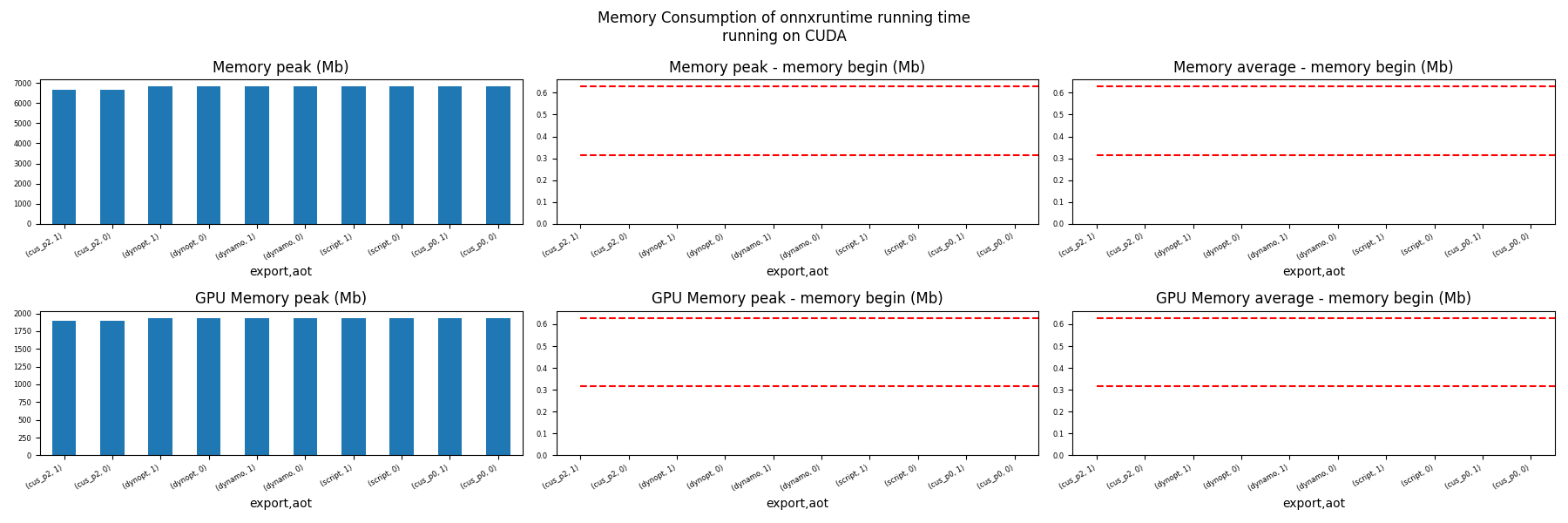
Show the interesting models for CPU¶
script¶
model = "ort-plot_torch_export_cus_p2-cpu-aot0.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=18
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='input' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='_onx_concat_max_pool2d_1::Shape:1' type=int64 shape=(2,) -- array([ 1, -1])-- GraphBuilder.constant_folding.from/fold(init7_s1_-1,max_pool2d_1::Shape:1)##max_pool2d_1::Shape:1/##init7_s1_-1/Opset.make_node.1/Shape
init: name='GemmTransposePattern--p_fc1_weight::T10' type=float32 shape=(512, 16)
init: name='GemmTransposePattern--p_fc2_weight::T10' type=float32 shape=(128, 512)
init: name='GemmTransposePattern--p_fc3_weight::T10' type=float32 shape=(10, 128)
init: name='reorder' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv1.bias)
init: name='reorder_token_2' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv2.bias)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.bias' type=float32 shape=(10,) -- DynamoInterpret.placeholder.1/P(fc3.bias)
Conv[com.microsoft.nchwc](input, reorder, conv1.bias, activation=b'Relu', dilations=[1,1], group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET') -> reorder_token_0
MaxPool[com.microsoft.nchwc](reorder_token_0, auto_pad=b'NOTSET', storage_order=0, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> reorder_token_1
Conv[com.microsoft.nchwc](reorder_token_1, reorder_token_2, conv2.bias, activation=b'Relu', dilations=[1,1], group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET') -> reorder_token_3
MaxPool[com.microsoft.nchwc](reorder_token_3, auto_pad=b'NOTSET', storage_order=0, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> reorder_token_4
ReorderOutput[com.microsoft.nchwc](reorder_token_4, channels_last=0, channels=16) -> max_pool2d_1
Reshape(max_pool2d_1, _onx_concat_max_pool2d_1::Shape:1, allowzero=0) -> flatten
FusedGemm[com.microsoft](flatten, GemmTransposePattern--p_fc1_weight::T10, fc1.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_2
FusedGemm[com.microsoft](relu_2, GemmTransposePattern--p_fc2_weight::T10, fc2.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_3
Gemm(relu_3, GemmTransposePattern--p_fc3_weight::T10, fc3.bias, transA=0, alpha=1.00, transB=1, beta=1.00) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 10]
cus_p2¶
model = "ort-plot_torch_export_cus_p2-cpu-aot0.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=18
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='input' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='_onx_concat_max_pool2d_1::Shape:1' type=int64 shape=(2,) -- array([ 1, -1])-- GraphBuilder.constant_folding.from/fold(init7_s1_-1,max_pool2d_1::Shape:1)##max_pool2d_1::Shape:1/##init7_s1_-1/Opset.make_node.1/Shape
init: name='GemmTransposePattern--p_fc1_weight::T10' type=float32 shape=(512, 16)
init: name='GemmTransposePattern--p_fc2_weight::T10' type=float32 shape=(128, 512)
init: name='GemmTransposePattern--p_fc3_weight::T10' type=float32 shape=(10, 128)
init: name='reorder' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv1.bias)
init: name='reorder_token_2' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv2.bias)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.bias' type=float32 shape=(10,) -- DynamoInterpret.placeholder.1/P(fc3.bias)
Conv[com.microsoft.nchwc](input, reorder, conv1.bias, activation=b'Relu', dilations=[1,1], group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET') -> reorder_token_0
MaxPool[com.microsoft.nchwc](reorder_token_0, auto_pad=b'NOTSET', storage_order=0, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> reorder_token_1
Conv[com.microsoft.nchwc](reorder_token_1, reorder_token_2, conv2.bias, activation=b'Relu', dilations=[1,1], group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET') -> reorder_token_3
MaxPool[com.microsoft.nchwc](reorder_token_3, auto_pad=b'NOTSET', storage_order=0, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> reorder_token_4
ReorderOutput[com.microsoft.nchwc](reorder_token_4, channels_last=0, channels=16) -> max_pool2d_1
Reshape(max_pool2d_1, _onx_concat_max_pool2d_1::Shape:1, allowzero=0) -> flatten
FusedGemm[com.microsoft](flatten, GemmTransposePattern--p_fc1_weight::T10, fc1.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_2
FusedGemm[com.microsoft](relu_2, GemmTransposePattern--p_fc2_weight::T10, fc2.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_3
Gemm(relu_3, GemmTransposePattern--p_fc3_weight::T10, fc3.bias, transA=0, alpha=1.00, transB=1, beta=1.00) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 10]
dynopt¶
model = "ort-plot_torch_export_dynopt-cpu-aot1.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=20
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='x' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='reorder' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,)
init: name='reorder_token_2' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,)
init: name='fc1.weight' type=float32 shape=(512, 16)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.weight' type=float32 shape=(128, 512)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.weight' type=float32 shape=(10, 128)
init: name='fc3.bias' type=float32 shape=(10,)
init: name='val_5' type=int64 shape=(2,) -- array([ 1, 16])
Conv[com.microsoft.nchwc](x, reorder, conv1.bias, activation=b'Relu', group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET', dilations=[1,1]) -> reorder_token_0
MaxPool[com.microsoft.nchwc](reorder_token_0, pads=[0,0,0,0], kernel_shape=[2,2], ceil_mode=0, auto_pad=b'NOTSET', dilations=[1,1], strides=[2,2], storage_order=0) -> reorder_token_1
Conv[com.microsoft.nchwc](reorder_token_1, reorder_token_2, conv2.bias, activation=b'Relu', group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET', dilations=[1,1]) -> reorder_token_3
MaxPool[com.microsoft.nchwc](reorder_token_3, pads=[0,0,0,0], kernel_shape=[2,2], ceil_mode=0, auto_pad=b'NOTSET', dilations=[1,1], strides=[2,2], storage_order=0) -> reorder_token_4
ReorderOutput[com.microsoft.nchwc](reorder_token_4, channels_last=0, channels=16) -> max_pool2d_1
Reshape(max_pool2d_1, val_5, allowzero=1) -> view
FusedGemm[com.microsoft](view, fc1.weight, fc1.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_2
FusedGemm[com.microsoft](relu_2, fc2.weight, fc2.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_3
Gemm(relu_3, fc3.weight, fc3.bias, transA=0, alpha=1.00, transB=1, beta=1.00) -> linear_2
output: name='linear_2' type=dtype('float32') shape=[1, 10]
dynamo¶
model = "ort-plot_torch_export_dynamo-cpu-aot1.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=20
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='x' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='reorder' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,)
init: name='reorder_token_2' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,)
init: name='fc1.weight' type=float32 shape=(512, 16)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.weight' type=float32 shape=(128, 512)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.weight' type=float32 shape=(10, 128)
init: name='fc3.bias' type=float32 shape=(10,)
init: name='val_5' type=int64 shape=(2,) -- array([ 1, 16])
Conv[com.microsoft.nchwc](x, reorder, conv1.bias, activation=b'Relu', group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET', dilations=[1,1]) -> reorder_token_0
MaxPool[com.microsoft.nchwc](reorder_token_0, pads=[0,0,0,0], kernel_shape=[2,2], ceil_mode=0, auto_pad=b'NOTSET', dilations=[1,1], strides=[2,2], storage_order=0) -> reorder_token_1
Conv[com.microsoft.nchwc](reorder_token_1, reorder_token_2, conv2.bias, activation=b'Relu', group=1, strides=[1,1], pads=[0,0,0,0], auto_pad=b'NOTSET', dilations=[1,1]) -> reorder_token_3
MaxPool[com.microsoft.nchwc](reorder_token_3, pads=[0,0,0,0], kernel_shape=[2,2], ceil_mode=0, auto_pad=b'NOTSET', dilations=[1,1], strides=[2,2], storage_order=0) -> reorder_token_4
ReorderOutput[com.microsoft.nchwc](reorder_token_4, channels_last=0, channels=16) -> max_pool2d_1
Reshape(max_pool2d_1, val_5, allowzero=1) -> view
FusedGemm[com.microsoft](view, fc1.weight, fc1.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_2
FusedGemm[com.microsoft](relu_2, fc2.weight, fc2.bias, transA=0, alpha=1.00, activation=b'Relu', transB=1, beta=1.00) -> relu_3
Gemm(relu_3, fc3.weight, fc3.bias, transA=0, alpha=1.00, transB=1, beta=1.00) -> linear_2
output: name='linear_2' type=dtype('float32') shape=[1, 10]
Show the interesting models for CUDA¶
script¶
model = "ort-plot_torch_export_cus_p2-cuda-aot0.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=18
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='input' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='_onx_concat_max_pool2d_1::Shape:1' type=int64 shape=(2,) -- array([ 1, -1])-- GraphBuilder.constant_folding.from/fold(init7_s1_-1,max_pool2d_1::Shape:1)##max_pool2d_1::Shape:1/##init7_s1_-1/Opset.make_node.1/Shape
init: name='GemmTransposePattern--p_fc1_weight::T10' type=float32 shape=(512, 16)
init: name='GemmTransposePattern--p_fc2_weight::T10' type=float32 shape=(128, 512)
init: name='GemmTransposePattern--p_fc3_weight::T10' type=float32 shape=(10, 128)
init: name='conv1.weight' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv1.bias)
init: name='conv2.weight' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv2.bias)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.bias' type=float32 shape=(10,) -- DynamoInterpret.placeholder.1/P(fc3.bias)
Conv(input, conv1.weight, conv1.bias, dilations=[1,1], group=1, pads=[0,0,0,0], strides=[1,1]) -> conv2d
Relu(conv2d) -> relu
MaxPool(relu, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> max_pool2d
Conv(max_pool2d, conv2.weight, conv2.bias, dilations=[1,1], group=1, pads=[0,0,0,0], strides=[1,1]) -> conv2d_1
Relu(conv2d_1) -> relu_1
MaxPool(relu_1, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> max_pool2d_1
Reshape(max_pool2d_1, _onx_concat_max_pool2d_1::Shape:1) -> flatten
Gemm(flatten, GemmTransposePattern--p_fc1_weight::T10, fc1.bias, transB=1) -> linear
Relu(linear) -> relu_2
Gemm(relu_2, GemmTransposePattern--p_fc2_weight::T10, fc2.bias, transB=1) -> linear_1
Relu(linear_1) -> relu_3
Gemm(relu_3, GemmTransposePattern--p_fc3_weight::T10, fc3.bias, transB=1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 10]
cus_p2¶
model = "ort-plot_torch_export_cus_p2-cuda-aot0.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=18
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='input' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='_onx_concat_max_pool2d_1::Shape:1' type=int64 shape=(2,) -- array([ 1, -1])-- GraphBuilder.constant_folding.from/fold(init7_s1_-1,max_pool2d_1::Shape:1)##max_pool2d_1::Shape:1/##init7_s1_-1/Opset.make_node.1/Shape
init: name='GemmTransposePattern--p_fc1_weight::T10' type=float32 shape=(512, 16)
init: name='GemmTransposePattern--p_fc2_weight::T10' type=float32 shape=(128, 512)
init: name='GemmTransposePattern--p_fc3_weight::T10' type=float32 shape=(10, 128)
init: name='conv1.weight' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv1.bias)
init: name='conv2.weight' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,) -- DynamoInterpret.placeholder.1/P(conv2.bias)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.bias' type=float32 shape=(10,) -- DynamoInterpret.placeholder.1/P(fc3.bias)
Conv(input, conv1.weight, conv1.bias, dilations=[1,1], group=1, pads=[0,0,0,0], strides=[1,1]) -> conv2d
Relu(conv2d) -> relu
MaxPool(relu, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> max_pool2d
Conv(max_pool2d, conv2.weight, conv2.bias, dilations=[1,1], group=1, pads=[0,0,0,0], strides=[1,1]) -> conv2d_1
Relu(conv2d_1) -> relu_1
MaxPool(relu_1, ceil_mode=0, dilations=[1,1], kernel_shape=[2,2], pads=[0,0,0,0], strides=[2,2]) -> max_pool2d_1
Reshape(max_pool2d_1, _onx_concat_max_pool2d_1::Shape:1) -> flatten
Gemm(flatten, GemmTransposePattern--p_fc1_weight::T10, fc1.bias, transB=1) -> linear
Relu(linear) -> relu_2
Gemm(relu_2, GemmTransposePattern--p_fc2_weight::T10, fc2.bias, transB=1) -> linear_1
Relu(linear_1) -> relu_3
Gemm(relu_3, GemmTransposePattern--p_fc3_weight::T10, fc3.bias, transB=1) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 10]
dynopt¶
model = "ort-plot_torch_export_dynopt-cuda-aot1.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=20
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='x' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='conv1.weight' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,)
init: name='conv2.weight' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,)
init: name='fc1.weight' type=float32 shape=(512, 16)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.weight' type=float32 shape=(128, 512)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.weight' type=float32 shape=(10, 128)
init: name='fc3.bias' type=float32 shape=(10,)
init: name='val_5' type=int64 shape=(2,) -- array([ 1, 16])
Conv(x, conv1.weight, conv1.bias, group=1, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[1,1], dilations=[1,1]) -> conv2d
Relu(conv2d) -> relu
MaxPool(relu, storage_order=0, dilations=[1,1], ceil_mode=0, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[2,2], kernel_shape=[2,2]) -> max_pool2d
Conv(max_pool2d, conv2.weight, conv2.bias, group=1, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[1,1], dilations=[1,1]) -> conv2d_1
Relu(conv2d_1) -> relu_1
MaxPool(relu_1, storage_order=0, dilations=[1,1], ceil_mode=0, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[2,2], kernel_shape=[2,2]) -> max_pool2d_1
Reshape(max_pool2d_1, val_5, allowzero=1) -> view
Gemm(view, fc1.weight, fc1.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear
Relu(linear) -> relu_2
Gemm(relu_2, fc2.weight, fc2.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear_1
Relu(linear_1) -> relu_3
Gemm(relu_3, fc3.weight, fc3.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear_2
output: name='linear_2' type=dtype('float32') shape=[1, 10]
dynamo¶
model = "ort-plot_torch_export_dynamo-cuda-aot1.onnx"
if os.path.exists(model):
print(pretty_onnx(onnx.load(model)))
opset: domain='' version=20
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='x' type=dtype('float32') shape=[1, 1, 16, 16]
init: name='conv1.weight' type=float32 shape=(16, 1, 5, 5)
init: name='conv1.bias' type=float32 shape=(16,)
init: name='conv2.weight' type=float32 shape=(16, 16, 5, 5)
init: name='conv2.bias' type=float32 shape=(16,)
init: name='fc1.weight' type=float32 shape=(512, 16)
init: name='fc1.bias' type=float32 shape=(512,)
init: name='fc2.weight' type=float32 shape=(128, 512)
init: name='fc2.bias' type=float32 shape=(128,)
init: name='fc3.weight' type=float32 shape=(10, 128)
init: name='fc3.bias' type=float32 shape=(10,)
init: name='val_5' type=int64 shape=(2,) -- array([ 1, 16])
Conv(x, conv1.weight, conv1.bias, group=1, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[1,1], dilations=[1,1]) -> conv2d
Relu(conv2d) -> relu
MaxPool(relu, storage_order=0, dilations=[1,1], ceil_mode=0, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[2,2], kernel_shape=[2,2]) -> max_pool2d
Conv(max_pool2d, conv2.weight, conv2.bias, group=1, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[1,1], dilations=[1,1]) -> conv2d_1
Relu(conv2d_1) -> relu_1
MaxPool(relu_1, storage_order=0, dilations=[1,1], ceil_mode=0, pads=[0,0,0,0], auto_pad=b'NOTSET', strides=[2,2], kernel_shape=[2,2]) -> max_pool2d_1
Reshape(max_pool2d_1, val_5, allowzero=1) -> view
Gemm(view, fc1.weight, fc1.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear
Relu(linear) -> relu_2
Gemm(relu_2, fc2.weight, fc2.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear_1
Relu(linear_1) -> relu_3
Gemm(relu_3, fc3.weight, fc3.bias, beta=1.00, transB=1, alpha=1.00, transA=0) -> linear_2
output: name='linear_2' type=dtype('float32') shape=[1, 10]
Total running time of the script: (1 minutes 9.559 seconds)
Related examples
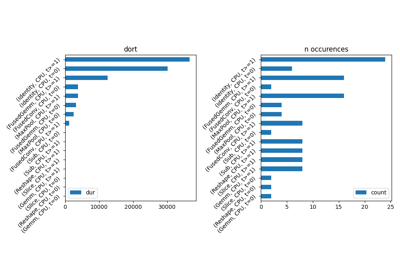
101: Onnx Model Optimization based on Pattern Rewriting

201: Use torch to export a scikit-learn model into ONNX