Note
Go to the end to download the full example code.
InputObserver with Transformers Cache#
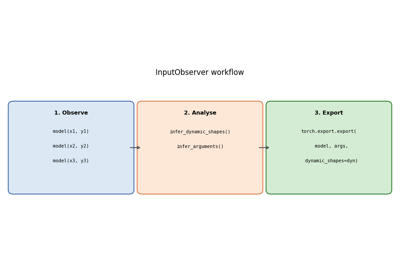
InputObserver is a context manager
that steals a model’s forward method during inference to record every set of inputs
and outputs. After the context exits, the collected data can be used to:
infer which tensor dimensions are dynamic across the observed calls, and
build a representative set of export arguments (with empty tensors for optional inputs that were missing in some calls).
These two pieces of information are exactly what torch.export.export() and
torch.onnx.export() need.
The example below shows three progressively richer scenarios:
Simple model — two plain-tensor inputs with varying batch and sequence lengths.
LLM-like model — inputs that include a
transformers.cache_utils.DynamicCache(key-value cache), which requires registering custom pytree flattening rules viaregister_flattening_functions.Multimodal model — a model that receives
pixel_valuesonly on the very first call (the prefill step). Thevalue_if_missingargument tells the observer what to substitute when the input is absent, so that the dynamic shape analysis remains possible.
Imports#
import torch
from yobx.helpers import string_type
from yobx.torch import register_flattening_functions
from yobx.torch.input_observer import InputObserver
from yobx.torch.in_transformers.cache_helper import make_dynamic_cache
1. Simple model - two tensor inputs#
We start with the most basic case: a model that takes two float tensors and returns their sum. We run it with three different shapes so that the observer can detect that both the batch and the sequence dimension are dynamic.
class AddModel(torch.nn.Module):
"""Adds two tensors element-wise (broadcasting on the batch dimension)."""
def forward(self, x, y):
return x + y
model_add = AddModel()
inputs_add = [
(torch.randn(2, 6), torch.randn(1, 6)),
(torch.randn(3, 7), torch.randn(1, 7)),
(torch.randn(4, 8), torch.randn(1, 8)),
]
observer_add = InputObserver()
with observer_add(model_add):
for x, y in inputs_add:
model_add(x, y)
# InputObserver captures at most 3 calls by default (store_n_calls=3).
print("Observations stored:", observer_add.num_obs())
assert observer_add.num_obs() == 3
Observations stored: 3
infer_dynamic_shapes returns a tuple of per-argument shape specs, using
torch.export.Dim.DYNAMIC as a placeholder wherever a dimension varies.
Dynamic shapes (add model): ({0: DimHint(DYNAMIC), 1: DimHint(DYNAMIC)}, {1: DimHint(DYNAMIC)})
infer_arguments returns one representative set of inputs with empty tensors
substituted for any optional argument that was missing in some calls.
Inferred arguments: (T1s2x6,T1s1x6)
2. LLM-like model - inputs with a DynamicCache#
Transformer language models store previously computed key/value pairs in a
transformers.cache_utils.DynamicCache. Because DynamicCache is a custom
class (not a plain Python container), we must register it as a pytree node before
torch.utils._pytree.tree_flatten can decompose it.
register_flattening_functions() is a context manager that registers all
supported cache types (DynamicCache, EncoderDecoderCache …) on entry and
unregisters them on exit.
We simulate two decoding steps: one with a short sequence in the cache and one with a slightly longer sequence.
class LLMLikeModel(torch.nn.Module):
"""Minimal stand-in for a causal LM forward pass."""
def forward(self, input_ids, attention_mask=None, past_key_values=None):
# A real model would compute hidden states here.
# We just return the inputs unchanged so the example is self-contained.
return input_ids, past_key_values
n_layers = 2
n_heads = 4
head_dim = 32
# Prefill step: the KV-cache holds 10 tokens.
cache_prefill = make_dynamic_cache(
[
(torch.rand(1, n_heads, 10, head_dim), torch.rand(1, n_heads, 10, head_dim))
for _ in range(n_layers)
]
)
# First decode step: the KV-cache now holds 11 tokens.
cache_decode = make_dynamic_cache(
[
(torch.rand(1, n_heads, 11, head_dim), torch.rand(1, n_heads, 11, head_dim))
for _ in range(n_layers)
]
)
llm_inputs = [
dict(
input_ids=torch.randint(0, 1000, (1, 10)),
attention_mask=torch.ones(1, 10, dtype=torch.int64),
past_key_values=cache_prefill,
),
dict(
input_ids=torch.randint(0, 1000, (1, 1)),
attention_mask=torch.ones(1, 11, dtype=torch.int64),
past_key_values=cache_decode,
),
]
model_llm = LLMLikeModel()
observer_llm = InputObserver()
# The `register_flattening_functions` context manager must wrap *both* the
# inference calls and the subsequent shape / argument inference.
with register_flattening_functions(patch_transformers=True), observer_llm(model_llm):
for kwargs in llm_inputs:
model_llm(**kwargs)
print("\nObservations stored (LLM):", observer_llm.num_obs())
Observations stored (LLM): 2
Retrieve dynamic shapes. We pass set_batch_dimension_for=True to mark the
first dimension of every tensor as dynamic even though both calls used batch=1.
with register_flattening_functions(patch_transformers=True):
dyn_llm = observer_llm.infer_dynamic_shapes(set_batch_dimension_for=True)
kwargs_llm = observer_llm.infer_arguments()
print("Dynamic shapes (LLM):", dyn_llm)
print("Inferred kwargs:", string_type(kwargs_llm, with_shape=True))
Dynamic shapes (LLM): {'input_ids': {0: DimHint(DYNAMIC), 1: DimHint(DYNAMIC)}, 'attention_mask': {0: DimHint(DYNAMIC), 1: DimHint(DYNAMIC)}, 'past_key_values': [{0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}]}
Inferred kwargs: dict(input_ids:T7s1x10,attention_mask:T7s1x10,past_key_values:DynamicCache(key_cache=#2[T1s1x4x10x32,T1s1x4x10x32], value_cache=#2[T1s1x4x10x32,T1s1x4x10x32]))
The shapes for past_key_values are expressed as a flat list (one entry per
key or value tensor across all layers). Both dimension 0 (batch) and dimension 2
(sequence length) are marked dynamic, while dimension 1 (heads) and dimension 3
(head dimension) are static.
3. Multimodal model - pixel_values present only on the first call#
Vision-language models like Gemma3 or LLaVA receive pixel_values only during
the prefill step. Subsequent decode steps omit that argument and introduce
past_key_values instead.
Without extra information the observer cannot infer an empty tensor for
pixel_values (it was never seen as an empty tensor). The value_if_missing
argument provides this information explicitly.
class MultimodalModel(torch.nn.Module):
"""Minimal stand-in for a vision-language model forward pass."""
def forward(self, input_ids, pixel_values=None, attention_mask=None, past_key_values=None):
return input_ids, past_key_values
image_h, image_w = 224, 224
cache_mm_step1 = make_dynamic_cache(
[
(torch.rand(1, n_heads, 20, head_dim), torch.rand(1, n_heads, 20, head_dim))
for _ in range(n_layers)
]
)
cache_mm_step2 = make_dynamic_cache(
[
(torch.rand(1, n_heads, 21, head_dim), torch.rand(1, n_heads, 21, head_dim))
for _ in range(n_layers)
]
)
mm_inputs = [
# Prefill: image + text, no past cache yet.
dict(
input_ids=torch.randint(0, 1000, (1, 20)),
pixel_values=torch.rand(1, 3, image_h, image_w),
attention_mask=torch.ones(1, 20, dtype=torch.int64),
),
# Decode step 1: no image, but a growing KV-cache.
dict(
input_ids=torch.randint(0, 1000, (1, 1)),
attention_mask=torch.ones(1, 21, dtype=torch.int64),
past_key_values=cache_mm_step1,
),
# Decode step 2.
dict(
input_ids=torch.randint(0, 1000, (1, 1)),
attention_mask=torch.ones(1, 22, dtype=torch.int64),
past_key_values=cache_mm_step2,
),
]
model_mm = MultimodalModel()
# Provide an empty tensor (batch=0) for pixel_values so the observer knows its
# shape and dtype when it is absent. The zero batch dimension signals
# "optional but with this shape when present".
observer_mm = InputObserver(
value_if_missing=dict(pixel_values=torch.empty((0, 3, image_h, image_w), dtype=torch.float32))
)
with register_flattening_functions(patch_transformers=True), observer_mm(model_mm):
for kwargs in mm_inputs:
model_mm(**kwargs)
print("\nObservations stored (multimodal):", observer_mm.num_obs())
with register_flattening_functions(patch_transformers=True):
dyn_mm = observer_mm.infer_dynamic_shapes(set_batch_dimension_for=True)
kwargs_mm = observer_mm.infer_arguments()
print("Dynamic shapes (multimodal):", dyn_mm)
print("Inferred kwargs:", string_type(kwargs_mm, with_shape=True))
Observations stored (multimodal): 3
Dynamic shapes (multimodal): {'input_ids': {0: DimHint(DYNAMIC), 1: DimHint(DYNAMIC)}, 'pixel_values': {0: DimHint(DYNAMIC)}, 'attention_mask': {0: DimHint(DYNAMIC), 1: DimHint(DYNAMIC)}, 'past_key_values': [{0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}, {0: DimHint(DYNAMIC), 2: DimHint(DYNAMIC)}]}
Inferred kwargs: dict(input_ids:T7s1x1,pixel_values:T1s0x3x224x224,attention_mask:T7s1x21,past_key_values:DynamicCache(key_cache=#2[T1s1x4x20x32,T1s1x4x20x32], value_cache=#2[T1s1x4x20x32,T1s1x4x20x32]))
Note that pixel_values now appears in the inferred arguments with an empty
first dimension (batch=0) even though it was absent in two of the three calls.
The spatial dimensions 2 and 3 (height and width) are not dynamic because they
were always 224x224.
These shapes and arguments can be passed directly to
torch.export.export() or torch.onnx.export():
import torch
ep = torch.export.export(
model_mm,
(),
kwargs=kwargs_mm,
dynamic_shapes=dyn_mm,
)
Total running time of the script: (0 minutes 0.016 seconds)
Related examples
Applying patches to a model and displaying the diff