Note
Go to the end to download the full example code.
Comparing the five ONNX translation APIs#
translate converts an
onnx.ModelProto into Python source code that, when executed,
recreates the same model. Five output APIs are available:
"onnx"— usesonnx.helper(oh.make_node,oh.make_graph, …) viaInnerEmitter."onnx-short"— same as"onnx"but replaces large initializers with random values to keep the snippet compact, viaInnerEmitterShortInitializer."onnx-compact"— produces a single nested expression instead of assembling separate lists of nodes/inputs/outputs, viaInnerEmitterCompact."light"— fluentstart(…).vin(…).…chain, viaLightEmitter."builder"—GraphBuilder-based function wrapper, viaBuilderEmitter.
This example builds a small model, translates it with every API, shows the
generated code, and verifies that the "onnx" snippet can be re-executed to
reproduce the original model.
import numpy as np
import onnx
import onnx.helper as oh
import onnx.numpy_helper as onh
from yobx.translate import translate, translate_header
Build the model#
We use Z = Relu(X @ W + b) as a running example:
a single Gemm followed by Relu.
TFLOAT = onnx.TensorProto.FLOAT
INT64 = onnx.TensorProto.INT64
W = onh.from_array(np.random.randn(8, 5).astype(np.float32), name="W")
b = onh.from_array(np.random.randn(5).astype(np.float32), name="b")
model = oh.make_model(
oh.make_graph(
[oh.make_node("Gemm", ["X", "W", "b"], ["T"]), oh.make_node("Relu", ["T"], ["Z"])],
"gemm_relu",
[oh.make_tensor_value_info("X", TFLOAT, [None, 8])],
[oh.make_tensor_value_info("Z", TFLOAT, [None, 5])],
[W, b],
),
opset_imports=[oh.make_opsetid("", 17)],
ir_version=9,
)
print(f"Model: {len(model.graph.node)} node(s), {len(model.graph.initializer)} initializer(s)")
Model: 2 node(s), 2 initializer(s)
1. "onnx" API — full initializer values#
The generated code uses onnx.helper.make_node(),
onnx.helper.make_graph(), and onnx.helper.make_model().
Every initializer is serialised as an exact np.array(…) literal.
=== api='onnx' ===
opset_imports = [
oh.make_opsetid('', 17),
]
inputs = []
outputs = []
nodes = []
initializers = []
sparse_initializers = []
functions = []
initializers.append(
onh.from_array(
np.array([[-0.7919992804527283, 0.8444149494171143, -0.07837424427270889, 0.3516818583011627, 0.5281974077224731], [-0.7377594709396362, -1.1808584928512573, -0.657304048538208, -0.050507061183452606, -0.695027768611908], [-0.614752471446991, -1.373172402381897, -0.022453228011727333, -0.2898128628730774, 0.20103037357330322], [0.2972334921360016, 1.0494059324264526, -0.8632147312164307, 1.1245440244674683, 0.20573727786540985], [0.22696807980537415, 1.8734042644500732, 0.4748353064060211, -0.2102905660867691, -0.2104172706604004], [0.27229437232017517, -0.14323361217975616, 0.9408213496208191, 1.177147388458252, -0.4265669882297516], [-1.0400818586349487, 0.15054301917552948, -1.7188189029693604, -1.7199000120162964, 1.3615162372589111], [-0.2985956072807312, -0.3422270715236664, 0.3362730145454407, 0.815269947052002, -1.5202698707580566]], dtype=np.float32),
name='W'
)
)
initializers.append(
onh.from_array(
np.array([-1.4425833225250244, 0.6801721453666687, 1.6355080604553223, -1.3044668436050415, -1.6487606763839722], dtype=np.float32),
name='b'
)
)
inputs.append(oh.make_tensor_value_info('X', onnx.TensorProto.FLOAT, shape=(None, 8)))
nodes.append(
oh.make_node(
'Gemm',
['X', 'W', 'b'],
['T']
)
)
nodes.append(
oh.make_node(
'Relu',
['T'],
['Z']
)
)
outputs.append(oh.make_tensor_value_info('Z', onnx.TensorProto.FLOAT, shape=(None, 5)))
graph = oh.make_graph(
nodes,
'gemm_relu',
inputs,
outputs,
initializers,
sparse_initializer=sparse_initializers,
)
model = oh.make_model(
graph,
functions=functions,
opset_imports=opset_imports,
ir_version=9,
)
2. "onnx-short" API — large initializers replaced by random values#
Identical to "onnx" except that initializers with more than 16 elements
are replaced by np.random.randn(…) / np.random.randint(…) calls.
This keeps the snippet readable when dealing with large weight tensors.
code_short = translate(model, api="onnx-short")
print("=== api='onnx-short' ===")
print(code_short)
=== api='onnx-short' ===
opset_imports = [
oh.make_opsetid('', 17),
]
inputs = []
outputs = []
nodes = []
initializers = []
sparse_initializers = []
functions = []
value = np.random.randn(8, 5).astype(np.float32)
initializers.append(
onh.from_array(
np.array(value, dtype=np.float32),
name='W'
)
)
initializers.append(
onh.from_array(
np.array([-1.4425833225250244, 0.6801721453666687, 1.6355080604553223, -1.3044668436050415, -1.6487606763839722], dtype=np.float32),
name='b'
)
)
inputs.append(oh.make_tensor_value_info('X', onnx.TensorProto.FLOAT, shape=(None, 8)))
nodes.append(
oh.make_node(
'Gemm',
['X', 'W', 'b'],
['T']
)
)
nodes.append(
oh.make_node(
'Relu',
['T'],
['Z']
)
)
outputs.append(oh.make_tensor_value_info('Z', onnx.TensorProto.FLOAT, shape=(None, 5)))
graph = oh.make_graph(
nodes,
'gemm_relu',
inputs,
outputs,
initializers,
sparse_initializer=sparse_initializers,
)
model = oh.make_model(
graph,
functions=functions,
opset_imports=opset_imports,
ir_version=9,
)
Size comparison between the two onnx variants:
print(f"\nFull code length : {len(code_onnx):>6} characters")
print(f"Short code length : {len(code_short):>6} characters")
Full code length : 1903 characters
Short code length : 1114 characters
3. "onnx-compact" API — single nested expression#
Instead of building separate lists of nodes, inputs, outputs, and initializers
before assembling them, this emitter produces a single nested
oh.make_model(oh.make_graph([…], …), …) expression.
This is often more concise than "onnx" while still being fully readable.
code_compact = translate(model, api="onnx-compact")
print("=== api='onnx-compact' ===")
print(code_compact)
=== api='onnx-compact' ===
model = oh.make_model(
oh.make_graph(
[
oh.make_node('Gemm', ['X', 'W', 'b'], ['T']),
oh.make_node('Relu', ['T'], ['Z']),
],
'gemm_relu',
[
oh.make_tensor_value_info('X', onnx.TensorProto.FLOAT, (None, 8)),
],
[
oh.make_tensor_value_info('Z', onnx.TensorProto.FLOAT, (None, 5)),
],
[
onh.from_array(np.array([[-0.7919992804527283, 0.8444149494171143, -0.07837424427270889, 0.3516818583011627, 0.5281974077224731], [-0.7377594709396362, -1.1808584928512573, -0.657304048538208, -0.050507061183452606, -0.695027768611908], [-0.614752471446991, -1.373172402381897, -0.022453228011727333, -0.2898128628730774, 0.20103037357330322], [0.2972334921360016, 1.0494059324264526, -0.8632147312164307, 1.1245440244674683, 0.20573727786540985], [0.22696807980537415, 1.8734042644500732, 0.4748353064060211, -0.2102905660867691, -0.2104172706604004], [0.27229437232017517, -0.14323361217975616, 0.9408213496208191, 1.177147388458252, -0.4265669882297516], [-1.0400818586349487, 0.15054301917552948, -1.7188189029693604, -1.7199000120162964, 1.3615162372589111], [-0.2985956072807312, -0.3422270715236664, 0.3362730145454407, 0.815269947052002, -1.5202698707580566]], dtype=np.float32), name='W'),
onh.from_array(np.array([-1.4425833225250244, 0.6801721453666687, 1.6355080604553223, -1.3044668436050415, -1.6487606763839722], dtype=np.float32), name='b'),
],
),
functions=[],
opset_imports=[oh.make_opsetid('', 17)],
ir_version=9,
)
4. "light" API — fluent chain#
The output is a single method-chain expression (start(…).vin(…).…).
code_light = translate(model, api="light")
print("=== api='light' ===")
print(code_light)
=== api='light' ===
(
start(opset=17)
.cst(np.array([[-0.7919992804527283, 0.8444149494171143, -0.07837424427270889, 0.3516818583011627, 0.5281974077224731], [-0.7377594709396362, -1.1808584928512573, -0.657304048538208, -0.050507061183452606, -0.695027768611908], [-0.614752471446991, -1.373172402381897, -0.022453228011727333, -0.2898128628730774, 0.20103037357330322], [0.2972334921360016, 1.0494059324264526, -0.8632147312164307, 1.1245440244674683, 0.20573727786540985], [0.22696807980537415, 1.8734042644500732, 0.4748353064060211, -0.2102905660867691, -0.2104172706604004], [0.27229437232017517, -0.14323361217975616, 0.9408213496208191, 1.177147388458252, -0.4265669882297516], [-1.0400818586349487, 0.15054301917552948, -1.7188189029693604, -1.7199000120162964, 1.3615162372589111], [-0.2985956072807312, -0.3422270715236664, 0.3362730145454407, 0.815269947052002, -1.5202698707580566]], dtype=np.float32))
.rename('W')
.cst(np.array([-1.4425833225250244, 0.6801721453666687, 1.6355080604553223, -1.3044668436050415, -1.6487606763839722], dtype=np.float32))
.rename('b')
.vin('X', elem_type=onnx.TensorProto.FLOAT, shape=(None, 8))
.bring('X', 'W', 'b')
.Gemm()
.rename('T')
.bring('T')
.Relu()
.rename('Z')
.bring('Z')
.vout(elem_type=onnx.TensorProto.FLOAT, shape=(None, 5))
.to_onnx()
)
5. "builder" API — GraphBuilder#
The output uses GraphBuilder to wrap the graph nodes in a Python function.
code_builder = translate(model, api="builder")
print("=== api='builder' ===")
print(code_builder)
=== api='builder' ===
def gemm_relu(
op: "GraphBuilder",
X: "FLOAT[None, 8]",
):
W = np.array([[-0.7919992804527283, 0.8444149494171143, -0.07837424427270889, 0.3516818583011627, 0.5281974077224731], [-0.7377594709396362, -1.1808584928512573, -0.657304048538208, -0.050507061183452606, -0.695027768611908], [-0.614752471446991, -1.373172402381897, -0.022453228011727333, -0.2898128628730774, 0.20103037357330322], [0.2972334921360016, 1.0494059324264526, -0.8632147312164307, 1.1245440244674683, 0.20573727786540985], [0.22696807980537415, 1.8734042644500732, 0.4748353064060211, -0.2102905660867691, -0.2104172706604004], [0.27229437232017517, -0.14323361217975616, 0.9408213496208191, 1.177147388458252, -0.4265669882297516], [-1.0400818586349487, 0.15054301917552948, -1.7188189029693604, -1.7199000120162964, 1.3615162372589111], [-0.2985956072807312, -0.3422270715236664, 0.3362730145454407, 0.815269947052002, -1.5202698707580566]], dtype=np.float32)
b = np.array([-1.4425833225250244, 0.6801721453666687, 1.6355080604553223, -1.3044668436050415, -1.6487606763839722], dtype=np.float32)
T = op.Gemm(X, W, b, outputs=['T'])
Z = op.Relu(T, outputs=['Z'])
op.Identity(Z, outputs=["Z"])
return Z
g = GraphBuilder({'': 17}, ir_version=9)
g.make_tensor_input("X", onnx.TensorProto.FLOAT, (None, 8))
gemm_relu(g.op, "X")
g.make_tensor_output("Z", onnx.TensorProto.FLOAT, (None, 5), indexed=False)
model = g.to_onnx()
Round-trip verification#
The "onnx" snippet is fully self-contained and executable.
Running it should recreate a model with the same graph structure.
header = translate_header("onnx")
full_code = header + "\n" + code_onnx
ns: dict = {}
exec(compile(full_code, "<translate>", "exec"), ns) # noqa: S102
recreated = ns["model"]
assert isinstance(recreated, onnx.ModelProto)
assert len(recreated.graph.node) == len(
model.graph.node
), f"Expected {len(model.graph.node)} nodes, got {len(recreated.graph.node)}"
assert len(recreated.graph.initializer) == len(model.graph.initializer), (
f"Expected {len(model.graph.initializer)} initializers, "
f"got {len(recreated.graph.initializer)}"
)
print("\nRound-trip succeeded ✓")
Round-trip succeeded ✓
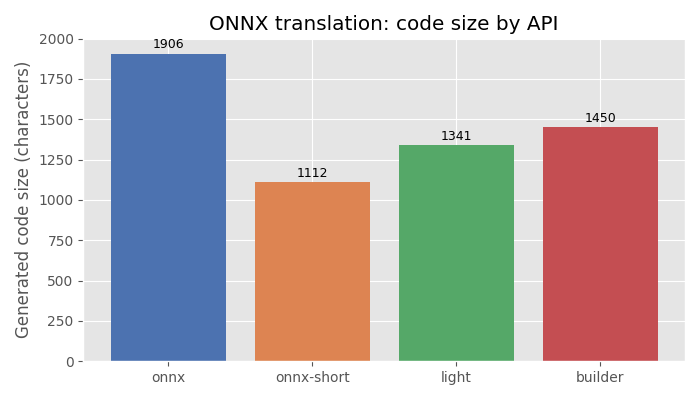
Plot: code size by API#
The bar chart compares the number of characters produced by each API for the
same model. "onnx-short" is always ≤ "onnx" because it compresses
large initializers. "onnx-compact" is typically shorter than "onnx"
because it uses a single nested expression instead of building separate lists.
import matplotlib.pyplot as plt # noqa: E402
api_labels = ["onnx", "onnx-short", "onnx-compact", "light", "builder"]
code_sizes = [
len(code_onnx),
len(code_short),
len(code_compact),
len(code_light),
len(code_builder),
]
fig, ax = plt.subplots(figsize=(8, 4))
bars = ax.bar(
api_labels, code_sizes, color=["#4c72b0", "#dd8452", "#8172b2", "#55a868", "#c44e52"]
)
ax.set_ylabel("Generated code size (characters)")
ax.set_title("ONNX translation: code size by API")
for bar, size in zip(bars, code_sizes):
ax.text(
bar.get_x() + bar.get_width() / 2,
bar.get_height() * 1.01,
str(size),
ha="center",
va="bottom",
fontsize=9,
)
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 0.156 seconds)
Related examples


MiniOnnxBuilder: serialize tensors to an ONNX model
