Note
Go to the end to download the full example code.
Converting a scikit-learn Pipeline to ONNX#
yobx.sklearn.to_onnx() converts fitted
scikit-learn estimators and pipelines into
onnx.ModelProto objects that can be executed with any
ONNX-compatible runtime.
The converter covers the following estimators (see
yobx.sklearn for the full registry):
sklearn.linear_model.LogisticRegression/LogisticRegressionCVsklearn.pipeline.Pipeline— chains the above step-by-step
The workflow is:
Train a scikit-learn estimator (or pipeline) as usual.
Call
yobx.sklearn.to_onnx()with a representative dummy input to convert the fitted model into an ONNX graph.Run the ONNX model with any ONNX runtime — this example uses onnxruntime.
Verify that the ONNX outputs match scikit-learn’s predictions.
import numpy as np
import onnxruntime
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from yobx.doc import plot_dot
from yobx.sklearn import to_onnx
1. Train a scikit-learn pipeline#
We train a simple two-step pipeline:
StandardScaler followed by LogisticRegression.
The dataset has eighty samples and four features with two classes.
rng = np.random.default_rng(0)
X_train = rng.standard_normal((80, 4)).astype(np.float32)
y_train = (X_train[:, 0] + X_train[:, 1] > 0).astype(int)
pipe = Pipeline([("scaler", StandardScaler()), ("clf", LogisticRegression())])
pipe.fit(X_train, y_train)
print("Pipeline steps:")
for name, step in pipe.steps:
print(f" {name}: {step}")
Pipeline steps:
scaler: StandardScaler()
clf: LogisticRegression()
2. Convert to ONNX#
yobx.sklearn.to_onnx() requires a representative dummy input
(a NumPy array) so it can infer the input dtype and shape.
The first axis is automatically treated as the batch dimension.
onx = to_onnx(pipe, (X_train[:1],))
print(f"\nONNX model opset : {onx.opset_import[0].version}")
print(f"Number of nodes : {len(onx.graph.node)}")
print("Node op-types :", [n.op_type for n in onx.graph.node])
print(
"Graph inputs :", [(inp.name, inp.type.tensor_type.elem_type) for inp in onx.graph.input]
)
print("Graph outputs :", [out.name for out in onx.graph.output])
ONNX model opset : 21
Number of nodes : 8
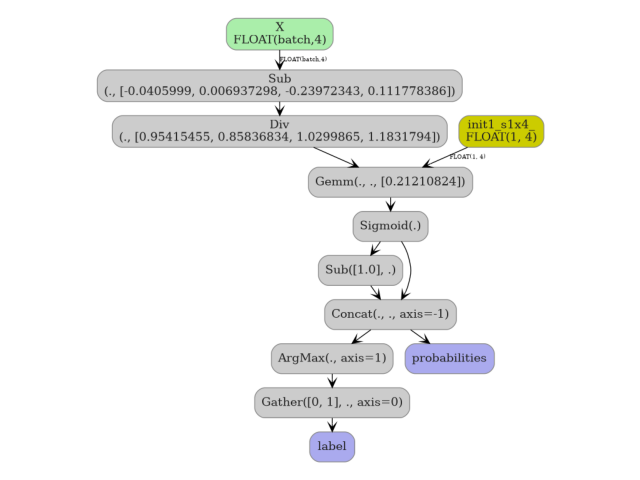
Node op-types : ['Sub', 'Div', 'Gemm', 'Sigmoid', 'Sub', 'Concat', 'ArgMax', 'Gather']
Graph inputs : [('X', 1)]
Graph outputs : ['label', 'probabilities']
3. Run the ONNX model and compare outputs#
We run the converted model on a held-out test set and verify that the ONNX predictions match those produced by scikit-learn.
X_test = rng.standard_normal((20, 4)).astype(np.float32)
y_test = (X_test[:, 0] + X_test[:, 1] > 0).astype(int)
ref = onnxruntime.InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
label_onnx, proba_onnx = ref.run(None, {"X": X_test})
label_sk = pipe.predict(X_test)
proba_sk = pipe.predict_proba(X_test).astype(np.float32)
print("\nFirst 5 labels (sklearn):", label_sk[:5])
print("First 5 labels (ONNX) :", label_onnx[:5])
print("First 5 probas (sklearn):", proba_sk[:5])
print("First 5 probas (ONNX) :", proba_onnx[:5])
assert np.array_equal(label_sk, label_onnx), "Label mismatch!"
assert np.allclose(proba_sk, proba_onnx, atol=1e-5), "Probability mismatch!"
print("\nAll predictions match ✓")
First 5 labels (sklearn): [0 1 1 1 0]
First 5 labels (ONNX) : [0 1 1 1 0]
First 5 probas (sklearn): [[0.6968902 0.30310982]
[0.06376062 0.93623936]
[0.38313922 0.6168608 ]
[0.16703625 0.83296376]
[0.63305384 0.36694616]]
First 5 probas (ONNX) : [[0.6968902 0.30310982]
[0.06376064 0.93623936]
[0.3831392 0.6168608 ]
[0.16703618 0.8329638 ]
[0.63305384 0.36694616]]
All predictions match ✓
4. Multiclass pipeline#
The same API works transparently for multiclass problems.
The LogisticRegression converter automatically switches from
a sigmoid-based binary graph to a softmax-based multiclass graph.
X_mc = rng.standard_normal((120, 4)).astype(np.float32)
y_mc = rng.integers(0, 3, size=120)
pipe_mc = Pipeline([("scaler", StandardScaler()), ("clf", LogisticRegression(max_iter=500))])
pipe_mc.fit(X_mc, y_mc)
X_test_mc = rng.standard_normal((30, 4)).astype(np.float32)
onx_mc = to_onnx(pipe_mc, (X_test_mc[:1],))
ref_mc = onnxruntime.InferenceSession(
onx_mc.SerializeToString(), providers=["CPUExecutionProvider"]
)
label_mc_onnx, proba_mc_onnx = ref_mc.run(None, {"X": X_test_mc})
label_mc_sk = pipe_mc.predict(X_test_mc)
proba_mc_sk = pipe_mc.predict_proba(X_test_mc).astype(np.float32)
assert np.array_equal(label_mc_sk, label_mc_onnx), "Multiclass label mismatch!"
assert np.allclose(proba_mc_sk, proba_mc_onnx, atol=1e-5), "Multiclass proba mismatch!"
print("Multiclass predictions match ✓")
Multiclass predictions match ✓
5. Visualize the ONNX graph#
plot_dot(onx)
Total running time of the script: (0 minutes 0.314 seconds)
Related examples
DataFrame input to a Pipeline with ColumnTransformer