Note
Go to the end to download the full example code.
Comparing GEMM implementation¶
It is not exactly GEMM but MatMul with transpose attributes.
nsys profile python _doc/examples/plot_bench_cuda_gemm.py
Vector Add¶
import itertools
import numpy
from tqdm import tqdm
import matplotlib.pyplot as plt
from pandas import DataFrame
from teachcompute.ext_test_case import measure_time, unit_test_going
import torch
has_cuda = torch.cuda.is_available()
try:
from teachcompute.validation.cuda.cuda_gemm import (
matmul_v1_cuda,
matmul_v2_cuda,
matmul_v3_cuda,
)
except ImportError:
has_cuda = False
def torch_matmul(m1, m2, r, trans_a, trans_b):
torch.cuda.nvtx.range_push(
f"torch_matmul, tA={1 if trans_a else 0}, tB={1 if trans_b else 0}"
)
if trans_a:
if trans_b:
r += m1.T @ m2.T
else:
r += m1.T @ m2
elif trans_b:
r += m1 @ m2.T
else:
r += m1 @ m2
torch.cuda.nvtx.range_pop()
def matmul_v1(t1, t2, r, trans_a, trans_b):
torch.cuda.nvtx.range_push(
f"matmul_v1, tA={1 if trans_a else 0}, tB={1 if trans_b else 0}"
)
matmul_v1_cuda(
*t1.shape, t1.data_ptr(), *t2.shape, t2.data_ptr(), r.data_ptr(), True, True
)
torch.cuda.nvtx.range_pop()
def matmul_v2(t1, t2, r, trans_a, trans_b):
torch.cuda.nvtx.range_push(
f"matmul_v2, tA={1 if trans_a else 0}, tB={1 if trans_b else 0}"
)
matmul_v2_cuda(
*t1.shape, t1.data_ptr(), *t2.shape, t2.data_ptr(), r.data_ptr(), True, True
)
torch.cuda.nvtx.range_pop()
def matmul_v3(t1, t2, r, trans_a, trans_b):
torch.cuda.nvtx.range_push(
f"matmul_v3, tA={1 if trans_a else 0}, tB={1 if trans_b else 0}"
)
matmul_v3_cuda(
*t1.shape, t1.data_ptr(), *t2.shape, t2.data_ptr(), r.data_ptr(), True, True
)
torch.cuda.nvtx.range_pop()
fcts = [torch_matmul, matmul_v1, matmul_v2, matmul_v3]
obs = []
dims = [2**9, 2**10] # , 2**11]
if unit_test_going():
dims = [16, 32, 64]
for trans_a, trans_b, dim, fct in tqdm(
list(itertools.product([False, True], [False, True], dims, fcts))
):
repeat, number = (10, 10) if dim <= 2**10 else (5, 5)
values = numpy.ones((dim, dim), dtype=numpy.float32) / (dim * repeat * number)
t1 = torch.Tensor(values).to("cuda:0")
t2 = torch.Tensor(values).to("cuda:0")
r = torch.zeros(t1.shape).to("cuda:0")
if has_cuda:
# warmup
for _ in range(3):
fct(t1, t2, r, trans_a=trans_a, trans_b=trans_b)
r = torch.zeros(t1.shape).to("cuda:0")
res = measure_time(
lambda fct=fct, t1=t1, t2=t2, r=r, trans_a=trans_a, trans_b=trans_b: fct(
t1, t2, r, trans_a=trans_a, trans_b=trans_b
),
repeat=repeat,
number=number,
div_by_number=True,
)
res.update(
dict(
dim=dim,
shape=tuple(values.shape),
fct=fct.__name__,
tA=trans_a,
tB=trans_b,
tt=f"tt{1 if trans_a else 0}{1 if trans_b else 0}",
)
)
obs.append(res)
if has_cuda:
df = DataFrame(obs)
df.to_csv("plot_bench_cuda_gemm.csv", index=False)
df.to_excel("plot_bench_cuda_gemm.xlsx", index=False)
print(df.head())
0%| | 0/32 [00:00<?, ?it/s]
3%|▎ | 1/32 [00:00<00:10, 2.97it/s]
6%|▋ | 2/32 [00:00<00:08, 3.68it/s]
12%|█▎ | 4/32 [00:00<00:03, 7.06it/s]
19%|█▉ | 6/32 [00:01<00:04, 6.27it/s]
22%|██▏ | 7/32 [00:01<00:05, 5.00it/s]
25%|██▌ | 8/32 [00:01<00:05, 4.32it/s]
34%|███▍ | 11/32 [00:01<00:02, 7.65it/s]
44%|████▍ | 14/32 [00:02<00:02, 7.34it/s]
47%|████▋ | 15/32 [00:02<00:02, 6.01it/s]
50%|█████ | 16/32 [00:02<00:03, 5.12it/s]
59%|█████▉ | 19/32 [00:03<00:01, 7.94it/s]
69%|██████▉ | 22/32 [00:03<00:01, 7.66it/s]
75%|███████▌ | 24/32 [00:04<00:01, 5.47it/s]
84%|████████▍ | 27/32 [00:04<00:00, 7.67it/s]
94%|█████████▍| 30/32 [00:04<00:00, 7.58it/s]
100%|██████████| 32/32 [00:05<00:00, 5.60it/s]
100%|██████████| 32/32 [00:05<00:00, 6.12it/s]
average deviation min_exec max_exec repeat number ttime context_size warmup_time dim shape fct tA tB tt
0 0.000263 0.000085 0.000177 0.000489 10 10 0.002628 64 0.000887 512 (512, 512) torch_matmul False False tt00
1 0.001775 0.001525 0.000597 0.004098 10 10 0.017745 64 0.004337 512 (512, 512) matmul_v1 False False tt00
2 0.000543 0.000045 0.000496 0.000609 10 10 0.005426 64 0.000524 512 (512, 512) matmul_v2 False False tt00
3 0.000519 0.000026 0.000490 0.000575 10 10 0.005193 64 0.000530 512 (512, 512) matmul_v3 False False tt00
4 0.000201 0.000085 0.000100 0.000337 10 10 0.002005 64 0.002509 1024 (1024, 1024) torch_matmul False False tt00
Plots¶
if has_cuda:
fig, ax = plt.subplots(2, 2, figsize=(12, 6))
for tt in ["tt00", "tt01", "tt10", "tt11"]:
piv_time = df[df.tt == tt].pivot(index="dim", columns="fct", values="average")
a = ax[int(tt[2]), int(tt[3])]
piv_time.plot(ax=a, logx=True, title=f"tA,tB={tt}")
cb = piv_time["torch_matmul"].astype(float).copy()
for c in piv_time.columns:
piv_time[c] = cb / piv_time[c].astype(float)
print(f"speed up for tt={tt}")
print(piv_time)
print()
fig.suptitle("greater is better")
fig.tight_layout()
fig.savefig("plot_bench_cuda_gemm.png")
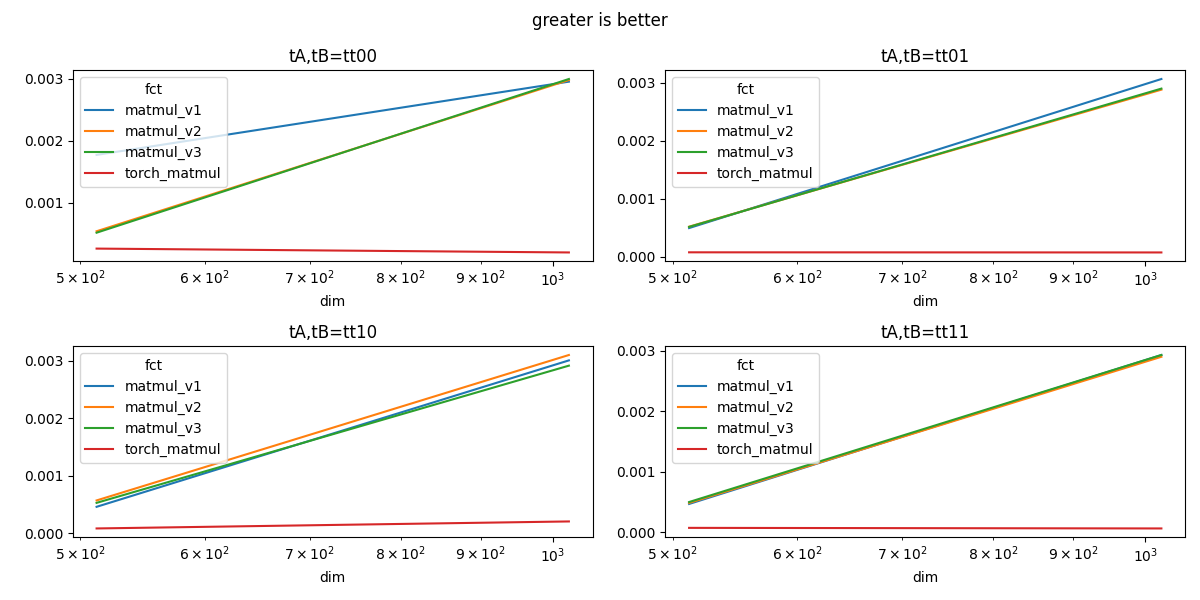
speed up for tt=tt00
fct matmul_v1 matmul_v2 matmul_v3 torch_matmul
dim
512 0.148072 0.484215 0.505981 1.0
1024 0.067825 0.067225 0.066859 1.0
speed up for tt=tt01
fct matmul_v1 matmul_v2 matmul_v3 torch_matmul
dim
512 0.153651 0.146507 0.147706 1.0
1024 0.024025 0.025558 0.025398 1.0
speed up for tt=tt10
fct matmul_v1 matmul_v2 matmul_v3 torch_matmul
dim
512 0.175468 0.141157 0.152491 1.0
1024 0.067243 0.065210 0.069358 1.0
speed up for tt=tt11
fct matmul_v1 matmul_v2 matmul_v3 torch_matmul
dim
512 0.148255 0.143111 0.138775 1.0
1024 0.020209 0.020413 0.020210 1.0
Total running time of the script: (0 minutes 6.391 seconds)