Note
Go to the end to download the full example code.
Parallelization of a dot product with processes (joblib)¶
Uses processes to parallelize a dot product is not a very solution because processes do not share memory, they need to exchange data. This parallelisation is efficient if the ratio exchanged data / computation time is low. joblib is used by scikit-learn. The cost of creating new processes is also significant.
import numpy
from tqdm import tqdm
from pandas import DataFrame
import matplotlib.pyplot as plt
from joblib import Parallel, delayed
from teachcompute.ext_test_case import measure_time, unit_test_going
def parallel_dot_joblib(va, vb, max_workers=2):
dh = va.shape[0] // max_workers
k = 2
dhk = dh // k
if dh != float(va.shape[0]) / max_workers:
raise RuntimeError("size must be a multiple of max_workers.")
r = Parallel(n_jobs=max_workers, backend="loky")(
delayed(numpy.dot)(va[i * dhk : i * dhk + dhk], vb[i * dhk : i * dhk + dhk])
for i in range(max_workers * k)
)
return sum(r)
We check that it returns the same values.
va = numpy.random.randn(100).astype(numpy.float64)
vb = numpy.random.randn(100).astype(numpy.float64)
print(parallel_dot_joblib(va, vb), numpy.dot(va, vb))
-6.80852588166648 -6.80852588166648
Let’s benchmark.
if unit_test_going():
tries = [10, 20]
else:
tries = [1000, 2000]
res = []
for n in tqdm(tries):
va = numpy.random.randn(n).astype(numpy.float64)
vb = numpy.random.randn(n).astype(numpy.float64)
m1 = measure_time(
"dot(va, vb, 2)", dict(va=va, vb=vb, dot=parallel_dot_joblib), repeat=1
)
m2 = measure_time("dot(va, vb)", dict(va=va, vb=vb, dot=numpy.dot))
res.append({"N": n, "numpy.dot": m2["average"], "joblib": m1["average"]})
df = DataFrame(res).set_index("N")
print(df)
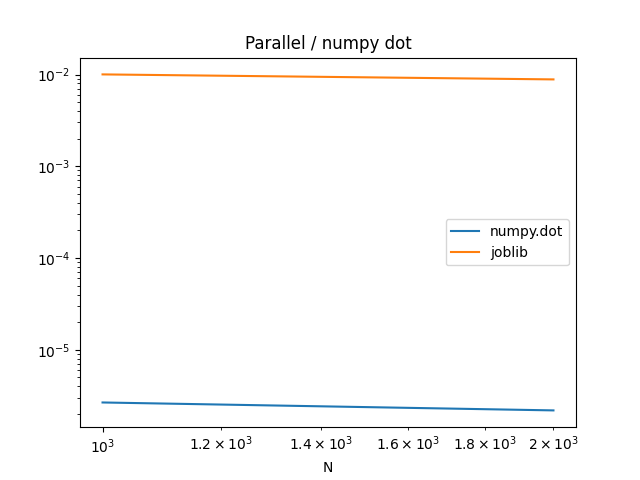
df.plot(logy=True, logx=True)
plt.title("Parallel / numpy dot")
0%| | 0/2 [00:00<?, ?it/s]
50%|█████ | 1/2 [00:00<00:00, 1.60it/s]
100%|██████████| 2/2 [00:01<00:00, 1.62it/s]
100%|██████████| 2/2 [00:01<00:00, 1.62it/s]
numpy.dot joblib
N
1000 0.000002 0.012166
2000 0.000001 0.011954
Text(0.5, 1.0, 'Parallel / numpy dot')
The parallelisation is inefficient.
Total running time of the script: (0 minutes 2.996 seconds)