Mapper, Reducers customisés avec SQL¶
Ce notebook propose l’utilisation de SQL avec SQLite pour manipuler les données depuis un notebook (avec le module sqlite3).
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.display import Image
Représentation¶
Le module pandas manipule des tables et c’est la façon la plus commune de représenter les données. Lorsque les données sont multidimensionnelles, on distingue les coordonnées des valeurs :
[2]:
Image("cube1.png")
[2]:

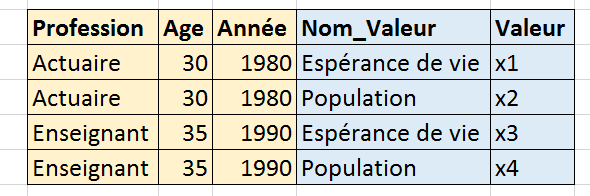
Dans cet exemple, il y a :
3 coordonnées : Age, Profession, Annéee
2 valeurs : Espérance de vie, Population
On peut représenter les donnés également comme ceci :
[3]:
Image("cube2.png")
[3]:
C’est assez simple. Prenons un exemple : Tables de mortalité par génération en Frances qu’on récupère à l’aide de la fonction mortality_table. C’est assez long (4-5 minutes) sur l’ensemble des données car elles doivent être prétraitées (voir la documentation de la fonction). Pour écouter, il faut utiliser le paramètre stop_at.
[4]:
from teachcompute.datasets import mortality_table
filename = mortality_table(verbose=True)
filename
[mortality_table] read
[mortality] step 1, shape is (111456, 63)
[mortality] step 2, shape is (6910272, 1)
[mortality] step 3, shape is (3385344, 3)
[mortality] step 4, shape is (3385344, 8)
[4]:
'./mortality.txt'
[8]:
import os
size = os.stat(filename).st_size
print(f"size={size / 2**20:1.3f} Mb")
size=120.594 Mb
[9]:
import pandas
df = pandas.read_csv(filename, sep="\t", encoding="utf-8", low_memory=False)
df.head()
[9]:
| annee | valeur | age | age_num | indicateur | genre | pays | |
|---|---|---|---|---|---|---|---|
| 0 | 2021 | 0.00015 | Y01 | 1.0 | DEATHRATE | F | AL |
| 1 | 2020 | 0.00052 | Y01 | 1.0 | DEATHRATE | F | AL |
| 2 | 2019 | 0.00021 | Y01 | 1.0 | DEATHRATE | F | AL |
| 3 | 2018 | 0.00067 | Y01 | 1.0 | DEATHRATE | F | AL |
| 4 | 2017 | 0.00046 | Y01 | 1.0 | DEATHRATE | F | AL |
Les indicateurs pour deux âges différents :
[10]:
df[
((df.age == "Y60") | (df.age == "Y61"))
& (df.annee == 2000)
& (df.pays == "FR")
& (df.genre == "F")
]
[10]:
| annee | valeur | age | age_num | indicateur | genre | pays | |
|---|---|---|---|---|---|---|---|
| 105650 | 2000 | 5.020000e-03 | Y60 | 60.0 | DEATHRATE | F | FR |
| 107522 | 2000 | 4.860000e-03 | Y61 | 61.0 | DEATHRATE | F | FR |
| 587296 | 2000 | 2.580000e+01 | Y60 | 60.0 | LIFEXP | F | FR |
| 589157 | 2000 | 2.490000e+01 | Y61 | 61.0 | LIFEXP | F | FR |
| 1087844 | 2000 | 5.010000e-03 | Y60 | 60.0 | PROBDEATH | F | FR |
| 1089716 | 2000 | 4.850000e-03 | Y61 | 61.0 | PROBDEATH | F | FR |
| 1569977 | 2000 | 9.949900e-01 | Y60 | 60.0 | PROBSURV | F | FR |
| 1571849 | 2000 | 9.951500e-01 | Y61 | 61.0 | PROBSURV | F | FR |
| 2051560 | 2000 | 9.307600e+04 | Y60 | 60.0 | PYLIVED | F | FR |
| 2053421 | 2000 | 9.261800e+04 | Y61 | 61.0 | PYLIVED | F | FR |
| 2531170 | 2000 | 9.331000e+04 | Y60 | 60.0 | SURVIVORS | F | FR |
| 2533031 | 2000 | 9.284300e+04 | Y61 | 61.0 | SURVIVORS | F | FR |
| 3010828 | 2000 | 2.405594e+06 | Y60 | 60.0 | TOTPYLIVED | F | FR |
| 3012689 | 2000 | 2.312517e+06 | Y61 | 61.0 | TOTPYLIVED | F | FR |
Données trop grosses pour tenir en mémoire : SQLite¶
On charge une grosse base de données (assez petite pour que la séance ne soit pas trop longue).
[11]:
df.shape
[11]:
(3385344, 7)
Les données sont trop grosses pour tenir dans une feuille Excel et les consulter il n’y a pas d’autres moyens que d’en regarder des extraits. Que passe-t-il quand les données sont encore plus grosses et qu’elles ne tiennent pas en mémoire ? Quelques solutions :
augmenter la mémoire de l’ordinateur, avec 20 Go, on peut faire beaucoup de choses,
stocker les données dans un serveur SQL,
stocker les données sur un système distribué (cloud, Hadoop, …)
La seconde option n’est pas toujours simple, il faut installer un serveur SQL. Pour aller plus vite, on peut simplement utiliser SQLite qui est une façon de faire du SQL sans serveur (cela prend quelques minutes). On utilise la méthode to_sql.
[12]:
import sqlite3
from pandas.io import sql
cnx = sqlite3.connect("mortalite.db3")
try:
df.to_sql(name="mortalite", con=cnx)
except ValueError as e:
if "Table 'mortalite' already exists" not in str(e):
# seulement si l'erreur ne vient pas du fait que cela
# a déjà été fait
raise e
# on peut ajouter d'autres dataframe à la table comme si elle était créée par morceau
# voir le paramètre if_exists de la fonction to_sql
On peut maintenant récupérer un morceau avec la fonction read_sql.
[13]:
import pandas
example = pandas.read_sql("SELECT * FROM mortalite WHERE age_num==50 LIMIT 5", cnx)
example
[13]:
| index | annee | valeur | age | age_num | indicateur | genre | pays | |
|---|---|---|---|---|---|---|---|---|
| 0 | 84185 | 2021 | 0.00234 | Y50 | 50.0 | DEATHRATE | F | AL |
| 1 | 84186 | 2020 | 0.00237 | Y50 | 50.0 | DEATHRATE | F | AL |
| 2 | 84187 | 2019 | 0.00188 | Y50 | 50.0 | DEATHRATE | F | AL |
| 3 | 84188 | 2018 | 0.00195 | Y50 | 50.0 | DEATHRATE | F | AL |
| 4 | 84189 | 2017 | 0.00170 | Y50 | 50.0 | DEATHRATE | F | AL |
L’ensemble des données restent sur le disque, seul le résultat de la requête est chargé en mémoire. Si on ne peut pas faire tenir les données en mémoire, il faut soit en obtenir une vue partielle (un échantillon aléatoire, un vue filtrée), soit une vue agrégrée. Pour finir, il faut fermer la connexion pour laisser d’autres applications ou notebook modifier la base ou tout simplement supprimer le fichier.
[14]:
cnx.close()
Sous Windows, on peut consulter la base avec le logiciel SQLiteSpy.
[15]:
Image("sqlite.png")
[15]:
Sous Linux ou Max, on peut utiliser une extension Firefox SQLite Manager.
Cas 1 : filtrer pour créer un échantillon aléatoire¶
Si on ne peut pas faire tenir les données en mémoire, on peut soit regarder les premières lignes soit prendre un échantillon aléatoire. Deux options :
La première fonction est simple :
[16]:
sample = df.sample(frac=0.1)
sample.shape, df.shape
[16]:
((338534, 7), (3385344, 7))
Je ne sais pas si cela peut être réalisé sans charger les données en mémoire. Si les données pèsent 20 Go, cette méthode n’aboutira pas. Pourtant, on veut juste un échantillon pour commencer à regarder les données. On utilise la seconde option avec create_function et la fonction suivante :
[17]:
import random # loi uniforme
def echantillon(proportion):
return 1 if random.random() < proportion else 0
[18]:
import sqlite3
from pandas.io import sql
cnx = sqlite3.connect("mortalite.db3")
On déclare la fonction à la base de données.
[19]:
cnx.create_function("echantillon", 1, echantillon)
On veut récupérer environ 1% de la table ? On écrit d’abord le filtre.
[20]:
sample = pandas.read_sql("SELECT * FROM mortalite WHERE echantillon(0.01)", cnx)
sample.shape
[20]:
(33977, 8)
[21]:
sample.head()
[21]:
| index | annee | valeur | age | age_num | indicateur | genre | pays | |
|---|---|---|---|---|---|---|---|---|
| 0 | 12 | 2016 | 0.00035 | Y01 | 1.0 | DEATHRATE | F | AM |
| 1 | 24 | 2015 | 0.00017 | Y01 | 1.0 | DEATHRATE | F | AT |
| 2 | 52 | 1987 | 0.00066 | Y01 | 1.0 | DEATHRATE | F | AT |
| 3 | 131 | 1972 | 0.00133 | Y01 | 1.0 | DEATHRATE | F | BE |
| 4 | 427 | 1998 | 0.00043 | Y01 | 1.0 | DEATHRATE | F | DE_TOT |
On ferme la connexion.
[22]:
cnx.close()
Pseudo Map/Reduce avec SQLite¶
La liste des mots-clés du langage SQL utilisés par SQLite n’est pas aussi riche que d’autres solutions de serveurs SQL. La médiane ne semble pas en faire partie. Cependant, pour une année, un genre, un âge donné, on voudrait calculer la médiane de l’espérance de vie sur l’ensembles des pays.
[23]:
import sqlite3, pandas
from pandas.io import sql
cnx = sqlite3.connect("mortalite.db3")
[24]:
pays = pandas.read_sql("SELECT pays, COUNT(*) FROM mortalite GROUP BY pays", cnx)
pays.head()
[24]:
| pays | COUNT(*) | |
|---|---|---|
| 0 | AL | 16758 |
| 1 | AM | 16254 |
| 2 | AT | 94428 |
| 3 | AZ | 21672 |
| 4 | BE | 112488 |
Il n’y a pas le même nombre de données selon les pays, il est probable que le nombre de pays pour lesquels il existe des données varie selon les âges et les années.
[25]:
query = """SELECT nb_country, COUNT(*) AS nb_rows FROM (
SELECT annee,age,age_num, count(*) AS nb_country FROM mortalite
WHERE indicateur=="LIFEXP" AND genre=="F"
GROUP BY annee,age,age_num
) GROUP BY nb_country"""
df = pandas.read_sql(query, cnx)
[26]:
df.sort_values("nb_country", ascending=False).head(n=2)
[26]:
| nb_country | nb_rows | |
|---|---|---|
| 24 | 50 | 860 |
| 23 | 49 | 172 |
[27]:
ax = df.plot(x="nb_country", y="nb_rows")
ax.set_title("Nombre de données par pays");
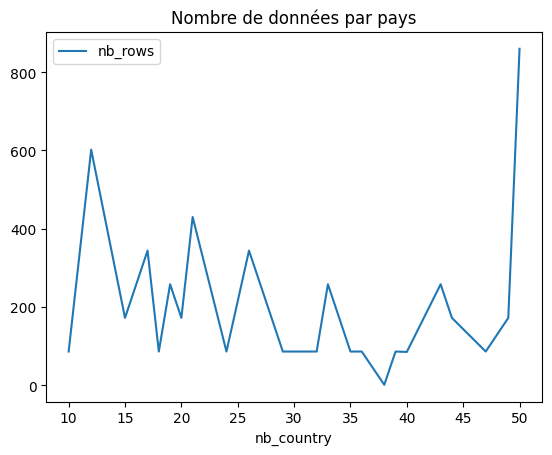
Soit un nombre inconstant de pays. Le fait qu’on est 100 pays suggère qu’on ait une erreur également.
[28]:
query = """SELECT annee,age,age_num, count(*) AS nb_country FROM mortalite
WHERE indicateur=="LIFEXP" AND genre=="F"
GROUP BY annee,age,age_num
HAVING nb_country >= 100"""
df = pandas.read_sql(query, cnx)
[29]:
df.head()
[29]:
| annee | age | age_num | nb_country |
|---|
Ce sont des valeurs manquantes. Le problème pour calculer la médiane pour chaque observation est qu’il faut d’abord regrouper les lignes de la table par indicateur puis choisir la médiane dans chaque de ces petits groupes. On s’inspire pour cela de la logique Map/Reduce et de la fonction create_aggregate.
Cas 2 : reducer customisé avec SQL¶
Le reducer se présente toujours sous la forme suivante :
[30]:
class ReducerMediane:
def __init__(self):
# ???
pass
def step(self, value):
# ???
#
pass
def finalize(self):
# ???
# return ... //2 ]
pass
Qu’on renseigne de la sorte :
[31]:
class ReducerMediane:
def __init__(self):
self.indicateur = []
def step(self, value):
if value >= 0:
self.indicateur.append(value)
def finalize(self):
self.indicateur.sort()
return self.indicateur[len(self.indicateur) // 2]
On le déclare ensuite à sqllite3.
[32]:
cnx.create_aggregate("ReducerMediane", 1, ReducerMediane)
[33]:
query = """SELECT annee,age,age_num, ReducerMediane(valeur) AS mediane FROM mortalite
WHERE indicateur=="LIFEXP" AND genre=="F"
GROUP BY annee,age,age_num"""
df = pandas.read_sql(query, cnx)
[34]:
df.head()
[34]:
| annee | age | age_num | mediane | |
|---|---|---|---|---|
| 0 | 1960 | Y01 | 1.0 | 73.7 |
| 1 | 1960 | Y02 | 2.0 | 72.8 |
| 2 | 1960 | Y03 | 3.0 | 71.9 |
| 3 | 1960 | Y04 | 4.0 | 71.0 |
| 4 | 1960 | Y05 | 5.0 | 70.0 |
Un reducer à deux entrées même si cela n’a pas beaucoup de sens ici :
[35]:
class ReducerMediane2:
def __init__(self):
self.indicateur = []
def step(self, value, value2):
if value >= 0:
self.indicateur.append(value)
if value2 >= 0:
self.indicateur.append(value2)
def finalize(self):
self.indicateur.sort()
return self.indicateur[len(self.indicateur) // 2]
cnx.create_aggregate("ReducerMediane2", 2, ReducerMediane2)
[36]:
query = """SELECT annee,age,age_num, ReducerMediane2(valeur, valeur+1) AS mediane2 FROM mortalite
WHERE indicateur=="LIFEXP" AND genre=="F"
GROUP BY annee,age,age_num"""
df = pandas.read_sql(query, cnx)
df.head()
[36]:
| annee | age | age_num | mediane2 | |
|---|---|---|---|---|
| 0 | 1960 | Y01 | 1.0 | 74.0 |
| 1 | 1960 | Y02 | 2.0 | 73.2 |
| 2 | 1960 | Y03 | 3.0 | 72.3 |
| 3 | 1960 | Y04 | 4.0 | 71.3 |
| 4 | 1960 | Y05 | 5.0 | 70.4 |
Il n’est apparemment pas possible de retourner deux résultats mais on peut utiliser une ruse qui consise à les concaténer dans une chaîne de caracères.
[37]:
class ReducerQuantile:
def __init__(self):
self.indicateur = []
def step(self, value):
if value >= 0:
self.indicateur.append(value)
def finalize(self):
self.indicateur.sort()
q1 = self.indicateur[len(self.indicateur) // 4]
q2 = self.indicateur[3 * len(self.indicateur) // 4]
n = len(self.indicateur)
return "%f;%f;%s" % (q1, q2, n)
cnx.create_aggregate("ReducerQuantile", 1, ReducerQuantile)
[38]:
query = """SELECT annee,age,age_num, ReducerQuantile(valeur) AS quantiles FROM mortalite
WHERE indicateur=="LIFEXP" AND genre=="F"
GROUP BY annee,age,age_num"""
df = pandas.read_sql(query, cnx)
df.head()
[38]:
| annee | age | age_num | quantiles | |
|---|---|---|---|---|
| 0 | 1960 | Y01 | 1.0 | 73.000000;74.000000;10 |
| 1 | 1960 | Y02 | 2.0 | 72.100000;73.200000;10 |
| 2 | 1960 | Y03 | 3.0 | 71.200000;72.300000;10 |
| 3 | 1960 | Y04 | 4.0 | 70.300000;71.300000;10 |
| 4 | 1960 | Y05 | 5.0 | 69.300000;70.400000;10 |
On ferme la connexion.
[39]:
cnx.close()
Notion d’index¶
En SQL et pour de grandes tables, la notion d’index joue un rôle important pour accélérer les opérations de jointures (JOIN) ou de regroupement (GROUP BY). L’article A thorough guide to SQLite database operations in Python montre comment faire les principales opérations.
[ ]:
[ ]: