Note
Go to the end to download the full example code.
Associativity and matrix multiplication¶
The matrix multiplication m1 @ m2 @ m3 can be done in two different ways: (m1 @ m2) @ m3 or m1 @ (m2 @ m3). Are these two orders equivalent or is there a better order?
import pprint
import numpy
import matplotlib.pyplot as plt
from pandas import DataFrame
from tqdm import tqdm
from teachcompute.ext_test_case import measure_time
First try¶
m1 = numpy.random.rand(100, 100)
m2 = numpy.random.rand(100, 10)
m3 = numpy.random.rand(10, 100)
m = m1 @ m2 @ m3
print(m.shape)
mm1 = (m1 @ m2) @ m3
mm2 = m1 @ (m2 @ m3)
print(mm1.shape, mm2.shape)
t1 = measure_time(lambda: (m1 @ m2) @ m3, context={}, number=50, repeat=50)
pprint.pprint(t1)
t2 = measure_time(lambda: m1 @ (m2 @ m3), context={}, number=50, repeat=50)
pprint.pprint(t2)
(100, 100)
(100, 100) (100, 100)
{'average': np.float64(3.503701720183017e-05),
'context_size': 64,
'deviation': np.float64(6.037630913287454e-06),
'max_exec': np.float64(6.074122000427451e-05),
'min_exec': np.float64(2.5633659970480948e-05),
'number': 50,
'repeat': 50,
'ttime': np.float64(0.0017518508600915083),
'warmup_time': 0.00014419999934034422}
{'average': np.float64(6.91557203987031e-05),
'context_size': 64,
'deviation': np.float64(7.830799947975338e-06),
'max_exec': np.float64(8.901838002202567e-05),
'min_exec': np.float64(5.513349999091588e-05),
'number': 50,
'repeat': 50,
'ttime': np.float64(0.0034577860199351555),
'warmup_time': 0.00013411899999482557}
With different sizes¶
obs = []
for i in tqdm([50, 100, 125, 150, 175, 200]):
m1 = numpy.random.rand(i, i)
m2 = numpy.random.rand(i, 10)
m3 = numpy.random.rand(10, i)
t1 = measure_time(
lambda m1=m1, m2=m2, m3=m3: (m1 @ m2) @ m3, context={}, number=50, repeat=50
)
t1["formula"] = "(m1 @ m2) @ m3"
t1["size"] = i
obs.append(t1)
t2 = measure_time(
lambda m1=m1, m2=m2, m3=m3: m1 @ (m2 @ m3), context={}, number=50, repeat=50
)
t2["formula"] = "m1 @ (m2 @ m3)"
t2["size"] = i
obs.append(t2)
df = DataFrame(obs)
piv = df.pivot(index="size", columns="formula", values="average")
piv
0%| | 0/6 [00:00<?, ?it/s]
33%|███▎ | 2/6 [00:00<00:00, 6.97it/s]
50%|█████ | 3/6 [00:00<00:00, 4.34it/s]
67%|██████▋ | 4/6 [00:01<00:00, 2.80it/s]
83%|████████▎ | 5/6 [00:07<00:02, 2.32s/it]
100%|██████████| 6/6 [00:17<00:00, 5.02s/it]
100%|██████████| 6/6 [00:17<00:00, 2.95s/it]
Graph¶
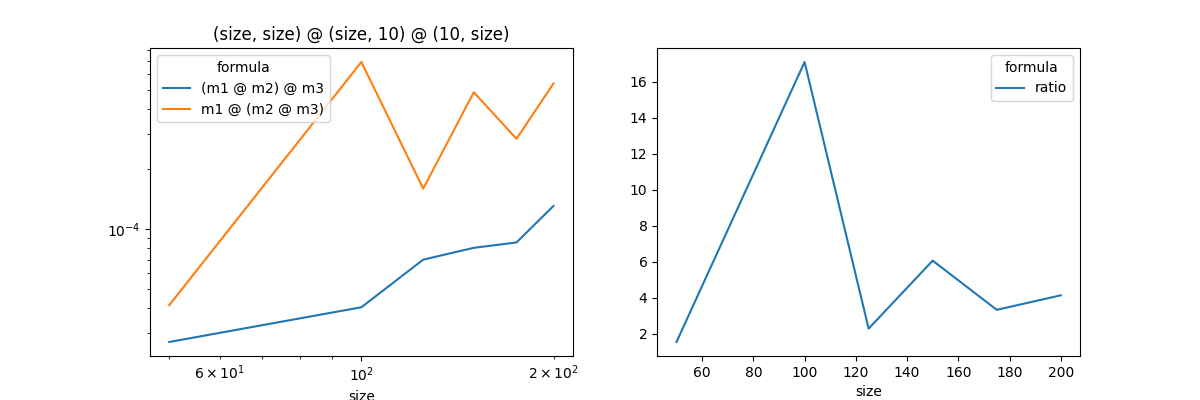
<Axes: xlabel='size'>
Total running time of the script: (0 minutes 18.377 seconds)