2024-05-31: Feuille de route 2023-2024 (3A)¶
Main Web Site : https://sdpython.github.io/
Plan¶
Les cours et séances se déroulent sur 6 séances de 3h au second semeste.
Intervenants¶
Xavier Dupré, Matthieu Durut.
Evaluation¶
Optimize a machine learning model by fusing operations.
pip install -U huggingface_hub
huggingface-cli download alpindale/Llama-2-7b-ONNX --repo-type model --cache-dir cache --local-dir . --local-dir-use-symlinks False
One part of the llama model:
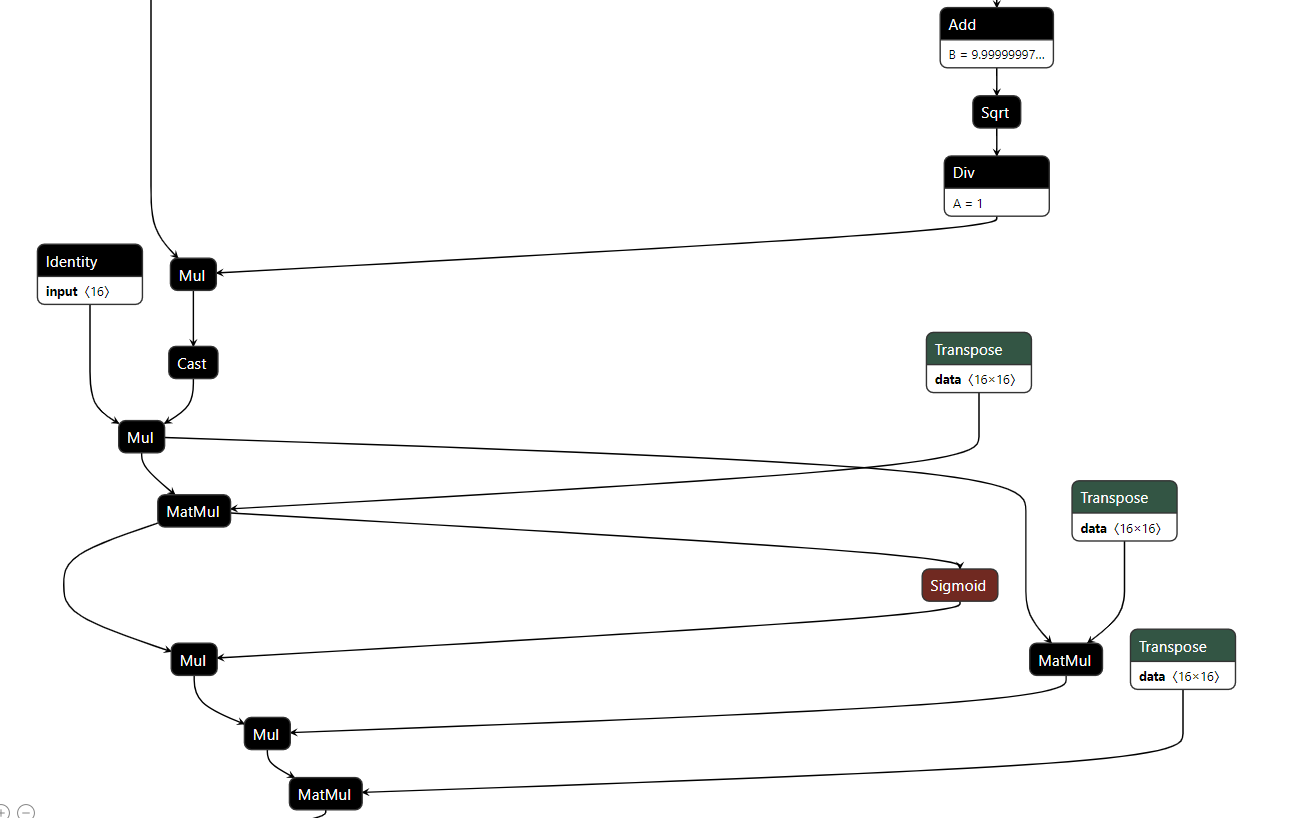
The goal is not to optimize the whole model but to optimize locally one execution path, in CUDA or CPU. To get that model: Export a LLAMA model into ONNX.
Notes¶
Liens, notebooks prévus pour les séances pratiques.
Séance Pratique 1 - 10/04¶
Séance pratique sur CPU.
Environnement
Setup SSP Cloud, présentation d’un package, C++
Outils de développement : cmake, git, pull request
github et intégration continue
Copy/Pasting is your friend.
Examples
Concepts
parallelization, conflicts
thread / process
branching, cache L1, L2, L3
C++ syntax
Technics
Instructions pour démarrer
Aller sur la plate-forme SSPCloud de l’ENSAE.
Se connecter avec son adresse ENSAE
Ouvrir une instance vscode-python
Il ensuite exécuter les instuctions suivantes en ligne de commande.
git clone https://github.com/sdpython/teachcompute.git
cd teachcompute
python setup.py build_ext --inplace
Si ça ne marche, installer cmake: conda install cmake.
Puis :
export PYTHONPATH=<this folder>
python _doc/examples/plot_bench_cpu_vector_sum.py
Séance Pratique 2 - 17/04¶
CUDA
Les séances pratiques s’appuient sur le package teachcompute.
git clone https://github.com/sdpython/teachcompute.git
cd teachcompute
python setup.py build_ext --inplace
CUDA, threads, blocks, parallélisation
gestion de la mémoire, CPU, CUDA
addition de deux vecteurs
code C++, template, macro
gcc, nvcc
extension .c, extension .cu
__device__,__globals__,__inline__, <<< >>>profiling with
nsys profile python <script.py>
somme d’un vecteur
somme des éléments d’un vecteur, réduction
synthreads
mémoire partagée, notion de cache
ScatterND
extension torch
device
A100, H100
float32, float16, float8
multiple nvidia on the same machine
Séance Pratique 3 - 03/05¶
Partie I : ML
Triton, TVM, AITemplate,
notion de déploiement de modèle de machine learning, docker, ONNX, autres…, que veut dire optimiser son code pour l’apprentissage puis déployer ensuite sur une autre machine.
Partie II : cas concret
Comment paralléliser…
Un tri ?
Le calcul de la médiane ? (BJKST) Propriétés statistiques ?
Pourquoi est-ce si difficile de paralléliser un tri ?
scatter_nd, Que faire quand les indices sont dupliqués ?
Paralléliser une forêt aléatoire sur CPU, sur GPU ?
La recherche de doublons dans une liste de coordonnées géographiques (longitude, latitude) ?
An Efficient Matrix Transpose in CUDA C/C++, notion de Bank Conflicts (voir CUDA C++ Programming Guide) CUDA, Cartes graphiques, Warp…
Partie III : modifier un package
Copier/coller, recherche, quelques astuces pour insérer son code dans un package.
Séance Théorique 1 - 12/04¶
hardware
ordinateur
mémoire partagée
ordre de grandeur vitesse CPU, communication
caches
algorithmes répartis
multithread
verrou