Note
Go to the end to download the full example code.
torch.onnx.export and a model with a test¶
Tests cannot be exported into ONNX unless they refactored
to use torch.cond().
A model with a test¶
from onnx.printer import to_text
import torch
We define a model with a control flow (-> graph break)
class ForwardWithControlFlowTest(torch.nn.Module):
def forward(self, x):
if x.sum():
return x * 2
return -x
class ModelWithControlFlowTest(torch.nn.Module):
def __init__(self):
super().__init__()
self.mlp = torch.nn.Sequential(
torch.nn.Linear(3, 2),
torch.nn.Linear(2, 1),
ForwardWithControlFlowTest(),
)
def forward(self, x):
out = self.mlp(x)
return out
model = ModelWithControlFlowTest()
Let’s check it runs.
x = torch.randn(3)
model(x)
tensor([1.3845], grad_fn=<MulBackward0>)
As expected, it does not export.
try:
torch.export.export(model, (x,))
raise AssertionError("This export should failed unless pytorch now supports this model.")
except Exception as e:
print(e)
Dynamic control flow is not supported at the moment. Please use torch.cond to explicitly capture the control flow. For more information about this error, see: https://pytorch.org/docs/main/generated/exportdb/index.html#cond-operands
from user code:
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_oe_cond.py", line 39, in forward
out = self.mlp(x)
File "~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
return forward_call(*args, **kwargs)
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_oe_cond.py", line 24, in forward
if x.sum():
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
It does export with torch.onnx.export() because
it uses JIT to trace the execution.
But the model is not exactly the same as the initial model.
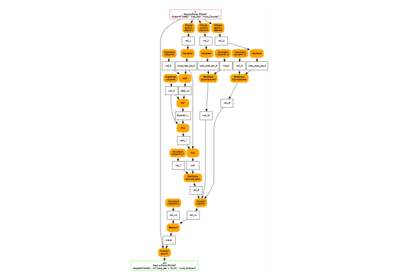
ep = torch.onnx.export(model, (x,), dynamo=True)
print(to_text(ep.model_proto))
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`...
def forward(self, arg0_1: "f32[2, 3]", arg1_1: "f32[2]", arg2_1: "f32[1, 2]", arg3_1: "f32[1]", arg4_1: "f32[3]"):
# File: ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/linear.py:125 in forward, code: return F.linear(input, self.weight, self.bias)
linear: "f32[2]" = torch.ops.aten.linear.default(arg4_1, arg0_1, arg1_1); arg4_1 = arg0_1 = arg1_1 = None
linear_1: "f32[1]" = torch.ops.aten.linear.default(linear, arg2_1, arg3_1); linear = arg2_1 = arg3_1 = None
# File: ~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_oe_cond.py:24 in forward, code: if x.sum():
sum_1: "f32[]" = torch.ops.aten.sum.default(linear_1); linear_1 = None
ne: "b8[]" = torch.ops.aten.ne.Scalar(sum_1, 0); sum_1 = None
item: "Sym(Eq(u0, 1))" = torch.ops.aten.item.default(ne); ne = item = None
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`... ❌
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export`...
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export`... ❌
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with Torch Script...
~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_oe_cond.py:24: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if x.sum():
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with Torch Script... ✅
[torch.onnx] Run decomposition...
~/vv/this312/lib/python3.12/site-packages/torch/export/_unlift.py:81: UserWarning: Attempted to insert a get_attr Node with no underlying reference in the owning GraphModule! Call GraphModule.add_submodule to add the necessary submodule, GraphModule.add_parameter to add the necessary Parameter, or nn.Module.register_buffer to add the necessary buffer
getattr_node = gm.graph.get_attr(lifted_node)
~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1794: UserWarning: Node lifted_tensor_6 target lifted_tensor_6 lifted_tensor_6 of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(
[torch.onnx] Run decomposition... ✅
[torch.onnx] Translate the graph into ONNX...
[torch.onnx] Translate the graph into ONNX... ✅
<
ir_version: 10,
opset_import: ["pkg.onnxscript.torch_lib.common" : 1, "" : 18],
producer_name: "pytorch",
producer_version: "2.7.0.dev20250214+cu126"
>
main_graph (float[3] input_1) => (float[1] mul)
<float[2] "model.mlp.0.bias" = {0.255097,-0.390911}, float[1] "model.mlp.1.bias" = {0.567823}, float[3,2] val_0, float[2] val_1, float[2] linear, float[2,1] val_2, float[1] val_3, float[1] linear_1, float convert_element_type_default>
{
[node_Constant_8] val_0 = Constant <value: tensor = float[3,2] val_0 {0.346779,0.273761,0.311015,-0.344733,0.497203,0.516696}> ()
[node_MatMul_1] val_1 = MatMul (input_1, val_0)
[node_Add_2] linear = Add (val_1, "model.mlp.0.bias")
[node_Constant_9] val_2 = Constant <value: tensor = float[2,1] val_2 {-0.653214,0.462875}> ()
[node_MatMul_4] val_3 = MatMul (linear, val_2)
[node_Add_5] linear_1 = Add (val_3, "model.mlp.1.bias")
[node_Constant_10] convert_element_type_default = Constant <value: tensor = float convert_element_type_default {2}> ()
[node_Mul_7] mul = Mul (linear_1, convert_element_type_default)
}
Suggested Patch¶
Let’s avoid the graph break by replacing the forward.
def new_forward(x):
def identity2(x):
return x * 2
def neg(x):
return -x
return torch.cond(x.sum() > 0, identity2, neg, (x,))
print("the list of submodules")
for name, mod in model.named_modules():
print(name, type(mod))
if isinstance(mod, ForwardWithControlFlowTest):
mod.forward = new_forward
the list of submodules
<class '__main__.ModelWithControlFlowTest'>
mlp <class 'torch.nn.modules.container.Sequential'>
mlp.0 <class 'torch.nn.modules.linear.Linear'>
mlp.1 <class 'torch.nn.modules.linear.Linear'>
mlp.2 <class '__main__.ForwardWithControlFlowTest'>
Let’s see what the fx graph looks like.
print(torch.export.export(model, (x,)).graph)
graph():
%p_mlp_0_weight : [num_users=1] = placeholder[target=p_mlp_0_weight]
%p_mlp_0_bias : [num_users=1] = placeholder[target=p_mlp_0_bias]
%p_mlp_1_weight : [num_users=1] = placeholder[target=p_mlp_1_weight]
%p_mlp_1_bias : [num_users=1] = placeholder[target=p_mlp_1_bias]
%x : [num_users=1] = placeholder[target=x]
%linear : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%x, %p_mlp_0_weight, %p_mlp_0_bias), kwargs = {})
%linear_1 : [num_users=2] = call_function[target=torch.ops.aten.linear.default](args = (%linear, %p_mlp_1_weight, %p_mlp_1_bias), kwargs = {})
%sum_1 : [num_users=1] = call_function[target=torch.ops.aten.sum.default](args = (%linear_1,), kwargs = {})
%gt : [num_users=1] = call_function[target=torch.ops.aten.gt.Scalar](args = (%sum_1, 0), kwargs = {})
%true_graph_0 : [num_users=1] = get_attr[target=true_graph_0]
%false_graph_0 : [num_users=1] = get_attr[target=false_graph_0]
%cond : [num_users=1] = call_function[target=torch.ops.higher_order.cond](args = (%gt, %true_graph_0, %false_graph_0, [%linear_1]), kwargs = {})
%getitem : [num_users=1] = call_function[target=operator.getitem](args = (%cond, 0), kwargs = {})
return (getitem,)
Let’s export again.
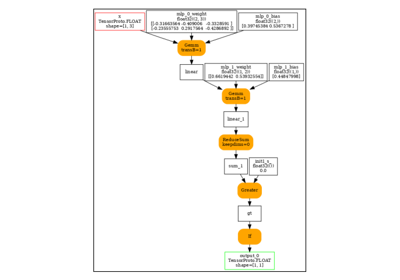
ep = torch.onnx.export(model, (x,), dynamo=True)
print(to_text(ep.model_proto))
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`...
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`... ✅
[torch.onnx] Run decomposition...
[torch.onnx] Run decomposition... ✅
[torch.onnx] Translate the graph into ONNX...
[torch.onnx] Translate the graph into ONNX... ✅
<
ir_version: 10,
opset_import: ["pkg.onnxscript.torch_lib.common" : 1, "" : 18, "pkg.torch.__subgraph__" : 1],
producer_name: "pytorch",
producer_version: "2.7.0.dev20250214+cu126"
>
main_graph (float[3] x) => (float[1] getitem)
<float[2] "mlp.0.bias" = {0.255097,-0.390911}, float[1] "mlp.1.bias" = {0.567823}, float[3,2] val_0, float[2] val_1, float[2] linear, float[2,1] val_2, float[1] val_3, float[1] linear_1, float sum_1, float scalar_tensor_default, bool gt>
{
[node_Constant_11] val_0 = Constant <value: tensor = float[3,2] val_0 {0.346779,0.273761,0.311015,-0.344733,0.497203,0.516696}> ()
[node_MatMul_1] val_1 = MatMul (x, val_0)
[node_Add_2] linear = Add (val_1, "mlp.0.bias")
[node_Constant_12] val_2 = Constant <value: tensor = float[2,1] val_2 {-0.653214,0.462875}> ()
[node_MatMul_4] val_3 = MatMul (linear, val_2)
[node_Add_5] linear_1 = Add (val_3, "mlp.1.bias")
[node_ReduceSum_6] sum_1 = ReduceSum <noop_with_empty_axes: int = 0, keepdims: int = 0> (linear_1)
[node_Constant_13] scalar_tensor_default = Constant <value: tensor = float scalar_tensor_default {0}> ()
[node_Greater_9] gt = Greater (sum_1, scalar_tensor_default)
[node_If_10] getitem = If (gt) <then_branch: graph = true_graph_0 () => (float[1] mul_true_graph_0)
<float scalar_tensor_default_2>
{
[node_Constant_1] scalar_tensor_default_2 = Constant <value: tensor = float scalar_tensor_default_2 {2}> ()
[node_Mul_2] mul_true_graph_0 = Mul (linear_1, scalar_tensor_default_2)
}, else_branch: graph = false_graph_0 () => (float[1] neg_false_graph_0) {
[node_Neg_0] neg_false_graph_0 = Neg (linear_1)
}>
}
Let’s optimize to see a small model.
ep = torch.onnx.export(model, (x,), dynamo=True)
ep.optimize()
print(to_text(ep.model_proto))
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`...
[torch.onnx] Obtain model graph for `ModelWithControlFlowTest([...]` with `torch.export.export(..., strict=False)`... ✅
[torch.onnx] Run decomposition...
[torch.onnx] Run decomposition... ✅
[torch.onnx] Translate the graph into ONNX...
[torch.onnx] Translate the graph into ONNX... ✅
<
ir_version: 10,
opset_import: ["pkg.onnxscript.torch_lib.common" : 1, "" : 18, "pkg.torch.__subgraph__" : 1],
producer_name: "pytorch",
producer_version: "2.7.0.dev20250214+cu126"
>
main_graph (float[3] x) => (float[1] getitem)
<float[2] "mlp.0.bias" = {0.255097,-0.390911}, float[1] "mlp.1.bias" = {0.567823}, float[3,2] val_0, float[2] val_1, float[2] linear, float[2,1] val_2, float[1] val_3, float[1] linear_1, float sum_1, float scalar_tensor_default, bool gt>
{
[node_Constant_11] val_0 = Constant <value: tensor = float[3,2] val_0 {0.346779,0.273761,0.311015,-0.344733,0.497203,0.516696}> ()
[node_MatMul_1] val_1 = MatMul (x, val_0)
[node_Add_2] linear = Add (val_1, "mlp.0.bias")
[node_Constant_12] val_2 = Constant <value: tensor = float[2,1] val_2 {-0.653214,0.462875}> ()
[node_MatMul_4] val_3 = MatMul (linear, val_2)
[node_Add_5] linear_1 = Add (val_3, "mlp.1.bias")
[node_ReduceSum_6] sum_1 = ReduceSum <noop_with_empty_axes: int = 0, keepdims: int = 0> (linear_1)
[node_Constant_13] scalar_tensor_default = Constant <value: tensor = float scalar_tensor_default {0}> ()
[node_Greater_9] gt = Greater (sum_1, scalar_tensor_default)
[node_If_10] getitem = If (gt) <then_branch: graph = true_graph_0 () => (float[1] mul_true_graph_0)
<float scalar_tensor_default_2>
{
[node_Constant_1] scalar_tensor_default_2 = Constant <value: tensor = float scalar_tensor_default_2 {2}> ()
[node_Mul_2] mul_true_graph_0 = Mul (linear_1, scalar_tensor_default_2)
}, else_branch: graph = false_graph_0 () => (float[1] neg_false_graph_0) {
[node_Neg_0] neg_false_graph_0 = Neg (linear_1)
}>
}
Total running time of the script: (0 minutes 3.564 seconds)
Related examples

torch.onnx.export and padding one dimension to a mulitple of a constant
torch.onnx.export and padding one dimension to a mulitple of a constant