Note
Go to the end to download the full example code.
201: Evaluate DORT Training¶
It compares DORT to eager mode and onnxrt backend.
To run the script:
python _doc/examples/plot_torch_aot --help
Some helpers¶
import warnings
try:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
import onnxruntime
has_cuda = "CUDAExecutionProvider" in onnxruntime.get_available_providers()
except ImportError:
print("onnxruntime not available.")
import sys
sys.exit(0)
import torch._dynamo
import contextlib
import itertools
import os
import gc
import platform
# import pickle
import pprint
import multiprocessing
import time
import cProfile
import pstats
import io
import logging
from pstats import SortKey
import numpy as np
import matplotlib.pyplot as plt
import pandas
import onnx
from onnx_array_api.profiling import profile2graph
import torch
from torch import nn
import torch.nn.functional as F
import experimental_experiment
from experimental_experiment.plotting.memory import memory_peak_plot
from experimental_experiment.ext_test_case import measure_time, get_figure
from experimental_experiment.args import get_parsed_args
from experimental_experiment.memory_peak import start_spying_on
from experimental_experiment.torch_models.training_helper import make_aot_ort
from tqdm import tqdm
has_cuda = has_cuda and torch.cuda.device_count() > 0
logging.disable(logging.ERROR)
def system_info():
obs = {}
obs["processor"] = platform.processor()
obs["cores"] = multiprocessing.cpu_count()
try:
obs["cuda"] = 1 if torch.cuda.device_count() > 0 else 0
obs["cuda_count"] = torch.cuda.device_count()
obs["cuda_name"] = torch.cuda.get_device_name()
obs["cuda_capa"] = torch.cuda.get_device_capability()
except (RuntimeError, AssertionError):
# no cuda
pass
return obs
pprint.pprint(system_info())
{'cores': 20,
'cuda': 1,
'cuda_capa': (8, 9),
'cuda_count': 1,
'cuda_name': 'NVIDIA GeForce RTX 4060 Laptop GPU',
'processor': 'x86_64'}
Scripts arguments
script_args = get_parsed_args(
"plot_torch_aot",
description=__doc__,
scenarios={
"small": "small model to test",
"middle": "55Mb model",
"large": "1Gb model",
},
warmup=5,
repeat=5,
repeat1=(1, "repeat for the first iteration"),
maxtime=(
2,
"maximum time to run a model to measure the computation time, "
"it is 0.1 when scenario is small",
),
expose="scenarios,repeat,repeat1,warmup",
)
if script_args.scenario in (None, "small"):
script_args.maxtime = 0.1
print(f"scenario={script_args.scenario or 'small'}")
print(f"warmup={script_args.warmup}")
print(f"repeat={script_args.repeat}")
print(f"repeat1={script_args.repeat1}")
print(f"maxtime={script_args.maxtime}")
scenario=small
warmup=5
repeat=5
repeat1=1
maxtime=0.1
The model¶
A simple model to convert.
class MyModelClass(nn.Module):
def __init__(self, scenario=script_args.scenario):
super().__init__()
if scenario == "middle":
self.large = False
self.conv1 = nn.Conv2d(1, 32, 5)
# self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(30752, 1024)
self.fcs = []
self.fc2 = nn.Linear(1024, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "small"):
self.large = False
self.conv1 = nn.Conv2d(1, 16, 5)
# self.conv2 = nn.Conv2d(16, 16, 5)
self.fc1 = nn.Linear(144, 512)
self.fcs = []
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, 10)
elif scenario in (None, "large"):
self.large = True
self.conv1 = nn.Conv2d(1, 32, 5)
# self.conv2 = nn.Conv2d(128, 16, 5)
self.fc1 = nn.Linear(30752, 4096)
# torch script does not support loops.
self.fca = nn.Linear(4096, 4096)
self.fcb = nn.Linear(4096, 4096)
self.fcc = nn.Linear(4096, 4096)
self.fcd = nn.Linear(4096, 4096)
self.fce = nn.Linear(4096, 4096)
self.fcf = nn.Linear(4096, 4096)
self.fcg = nn.Linear(4096, 4096)
self.fch = nn.Linear(4096, 4096)
self.fci = nn.Linear(4096, 4096)
# end of the unfolded loop.
self.fc2 = nn.Linear(4096, 128)
self.fc3 = nn.Linear(128, 10)
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (4, 4))
# x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
if self.large:
# loop
x = F.relu(self.fca(x))
x = F.relu(self.fcb(x))
x = F.relu(self.fcc(x))
x = F.relu(self.fcd(x))
x = F.relu(self.fce(x))
x = F.relu(self.fcf(x))
x = F.relu(self.fcg(x))
x = F.relu(self.fch(x))
x = F.relu(self.fci(x))
# end of the loop
x = F.relu(self.fc2(x))
y = self.fc3(x)
return y
def create_model_and_input(scenario=script_args.scenario):
if scenario == "middle":
shape = [1, 1, 128, 128]
elif scenario in (None, "small"):
shape = [1, 1, 16, 16]
elif scenario == "large":
shape = [1, 1, 128, 128]
else:
raise ValueError(f"Unsupported scenario={scenario!r}.")
input_tensor = torch.rand(*shape).to(torch.float32)
y = torch.rand((1, 10)).to(torch.float32)
model = MyModelClass(scenario=scenario)
assert model(input_tensor) is not None
return model, (input_tensor, y)
def torch_model_size(model):
size_model = 0
for param in model.parameters():
size = param.numel() * torch.finfo(param.data.dtype).bits / 8
size_model += size
return size_model
model, input_tensors = create_model_and_input()
model_size = torch_model_size(model)
print(f"model size={model_size / 2 ** 20} Mb")
model size=0.5401992797851562 Mb
Backends¶
def run(model, tensor_x, tensor_y):
tensor_x = tensor_x.detach()
tensor_y = tensor_y.detach()
for param in model.parameters():
param.grad = None
try:
output = model(tensor_x)
except Exception as e:
raise AssertionError(f"issue with {type(tensor_x)}") from e
loss = F.mse_loss(output, tensor_y)
# return loss
def _backward_():
loss.backward()
_backward_()
return loss, (param.grad for param in model.parameters())
def get_torch_eager(model, *args):
def my_compiler(gm, example_inputs):
return gm.forward
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
optimized_mod = torch.compile(model, fullgraph=True, backend=my_compiler)
assert run(optimized_mod, *args)
return optimized_mod
def get_torch_default(model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
optimized_mod = torch.compile(model, fullgraph=True, mode="reduce-overhead")
assert run(optimized_mod, *args)
return optimized_mod
def get_torch_dort(model, *args):
with contextlib.redirect_stdout(io.StringIO()):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
local_aot_ort, _ = make_aot_ort(dynamic=True, rewrite=True)
optimized_mod = torch.compile(model, backend=local_aot_ort, fullgraph=True)
run(optimized_mod, *args)
assert run(optimized_mod, *args)
return optimized_mod
Let’s check they are working.
export_functions = [
get_torch_eager,
get_torch_default,
get_torch_dort,
]
exporters = {f.__name__.replace("get_", ""): f for f in export_functions}
supported_exporters = {}
for k, v in exporters.items():
print(f"run function {k}")
filename = f"plot_torch_aot_{k}.onnx"
torch._dynamo.reset()
model, input_tensors = create_model_and_input()
try:
run(model, *input_tensors)
except Exception as e:
print(f"skipped due to {str(e)[:1000]}") # noqa: F821
continue
supported_exporters[k] = v
del model
gc.collect()
time.sleep(1)
run function torch_eager
run function torch_default
run function torch_dort
Compile and Memory¶
def flatten(ps):
obs = ps["cpu"].to_dict(unit=2**20)
if "gpus" in ps:
for i, g in enumerate(ps["gpus"]):
for k, v in g.to_dict(unit=2**20).items():
obs[f"gpu{i}_{k}"] = v
return obs
data = []
for k in supported_exporters:
print(f"run compile for memory {k} on cpu")
filename = f"plot_torch_aot_{k}.onnx"
if has_cuda:
torch.cuda.set_device(0)
torch._dynamo.reset()
# CPU
model, input_tensors = create_model_and_input()
stat = start_spying_on(cuda=1 if has_cuda else 0)
run(model, *input_tensors)
obs = flatten(stat.stop())
print("done.")
obs.update(dict(export=k, p="cpu"))
data.append(obs)
del model
gc.collect()
time.sleep(1)
if not has_cuda:
continue
torch._dynamo.reset()
# CUDA
model, input_tensors = create_model_and_input()
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
print(f"run compile for memory {k} on cuda")
stat = start_spying_on(cuda=1 if has_cuda else 0)
run(model, *input_tensors)
obs = flatten(stat.stop())
print("done.")
obs.update(dict(export=k, p="cuda"))
data.append(obs)
del model
gc.collect()
time.sleep(1)
run compile for memory torch_eager on cpu
done.
run compile for memory torch_eager on cuda
done.
run compile for memory torch_default on cpu
done.
run compile for memory torch_default on cuda
done.
run compile for memory torch_dort on cpu
done.
run compile for memory torch_dort on cuda
done.
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_aot_1_memory.csv", index=False)
df1.to_excel("plot_torch_aot_1_memory.xlsx", index=False)
print(df1)
for p in ["cpu", "cuda"]:
if not has_cuda and p == "cuda":
continue
ax = memory_peak_plot(
df1[df1["p"] == p],
key=("export",),
bars=[model_size * i / 2**20 for i in range(1, 5)],
suptitle=f"Memory Consumption of the Compilation on {p}\n"
f"model size={model_size / 2**20:1.0f} Mb",
)
get_figure(ax).savefig(f"plot_torch_aot_1_memory_{p}.png")
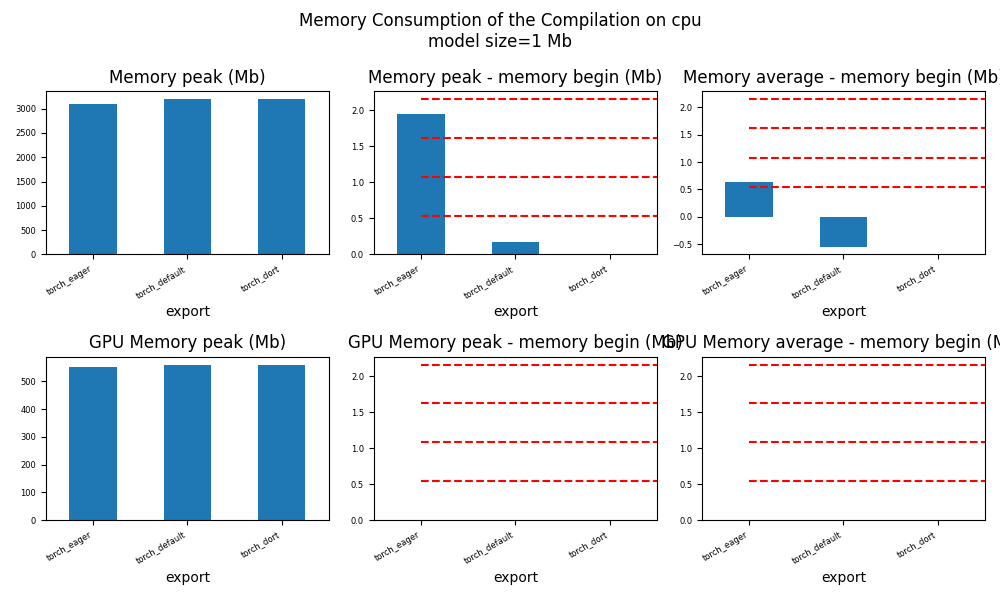
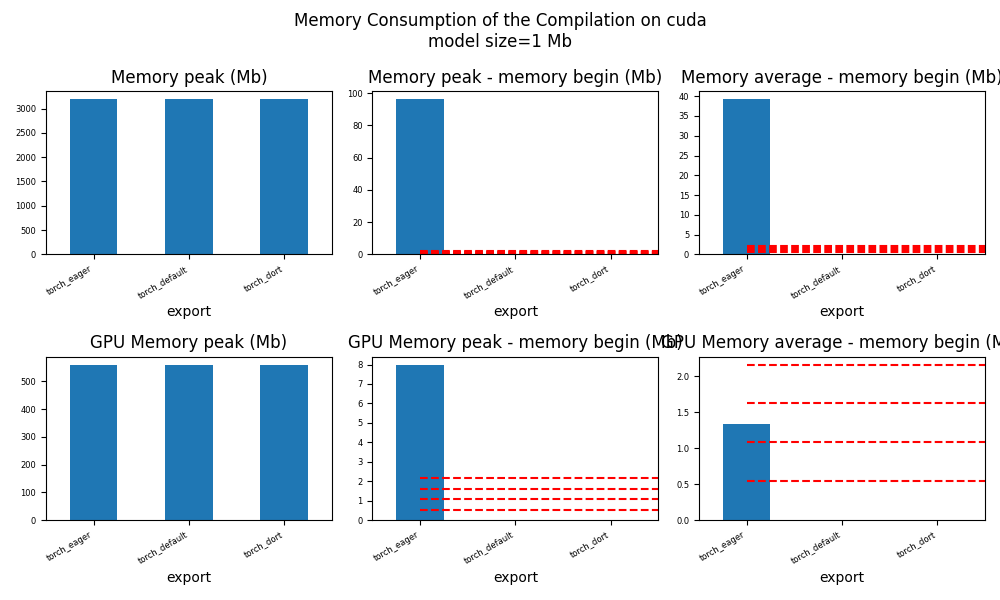
peak mean n begin end gpu0_peak gpu0_mean gpu0_n gpu0_begin gpu0_end export p
0 1875.832031 1873.195312 6 1871.878906 1871.878906 445.617188 445.617188 6 445.617188 445.617188 torch_eager cpu
1 1923.132812 1893.806386 23 1871.882812 1923.132812 475.617188 456.834579 23 445.617188 475.617188 torch_eager cuda
2 1925.109375 1925.109375 3 1925.109375 1925.109375 475.617188 475.617188 3 475.617188 475.617188 torch_default cpu
3 1925.121094 1925.119792 3 1925.117188 1925.121094 475.617188 475.617188 3 475.617188 475.617188 torch_default cuda
4 1925.132812 1924.733594 5 1923.140625 1925.132812 475.617188 475.617188 5 475.617188 475.617188 torch_dort cpu
5 1925.132812 1925.132812 2 1925.132812 1925.132812 475.617188 475.617188 2 475.617188 475.617188 torch_dort cuda
dort first iteration speed¶
data = []
for k in supported_exporters:
print(f"run dort cpu {k}: {script_args.repeat1}")
times = []
for _ in range(int(script_args.repeat1)):
model, input_tensors = create_model_and_input()
torch._dynamo.reset()
begin = time.perf_counter()
run(model, *input_tensors)
duration = time.perf_counter() - begin
times.append(duration)
del model
gc.collect()
time.sleep(1)
print(f"done: {times[-1]}")
data.append(
dict(
export=k,
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
p="cpu",
)
)
if not has_cuda:
continue
print(f"run dort cuda {k}: {script_args.repeat1}")
times = []
for i in range(int(script_args.repeat1)):
model, input_tensors = create_model_and_input()
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
torch._dynamo.reset()
begin = time.perf_counter()
run(model, *input_tensors)
duration = time.perf_counter() - begin
times.append(duration)
del model
gc.collect()
time.sleep(1)
print(f"done: {times[-1]}")
data.append(
dict(
export=k,
time=np.mean(times),
min=min(times),
max=max(times),
first=times[0],
last=times[-1],
std=np.std(times),
p="cuda",
)
)
run dort cpu torch_eager: 1
done: 0.07835148599951935
run dort cuda torch_eager: 1
done: 0.004151818000536878
run dort cpu torch_default: 1
done: 0.11344743500012555
run dort cuda torch_default: 1
done: 0.0038726989996575867
run dort cpu torch_dort: 1
done: 0.0928140660007557
run dort cuda torch_dort: 1
done: 0.003886378999595763
The result.
df1 = pandas.DataFrame(data)
df1.to_csv("plot_torch_aot_1_time.csv", index=False)
df1.to_excel("plot_torch_aot_1_time.xlsx", index=False)
print(df1)
fig, ax = plt.subplots(1, 1)
dfi = df1[["export", "p", "time", "std"]].set_index(["export", "p"])
dfi["time"].plot.bar(ax=ax, title="Compilation time", yerr=dfi["std"], rot=30)
fig.tight_layout()
fig.savefig("plot_torch_aot_1_time.png")
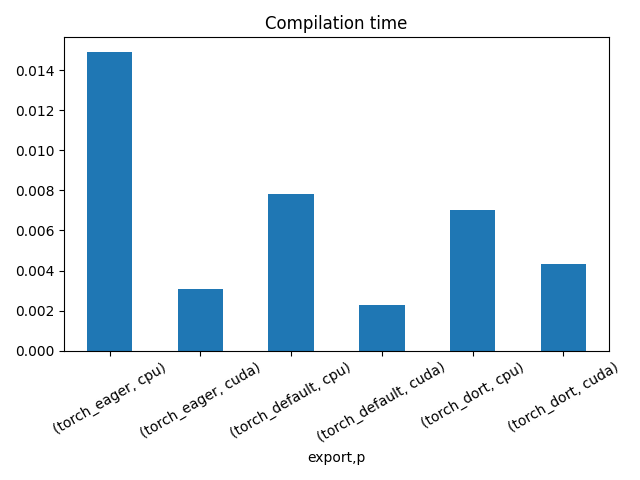
export time min max first last std p
0 torch_eager 0.078351 0.078351 0.078351 0.078351 0.078351 0.0 cpu
1 torch_eager 0.004152 0.004152 0.004152 0.004152 0.004152 0.0 cuda
2 torch_default 0.113447 0.113447 0.113447 0.113447 0.113447 0.0 cpu
3 torch_default 0.003873 0.003873 0.003873 0.003873 0.003873 0.0 cuda
4 torch_dort 0.092814 0.092814 0.092814 0.092814 0.092814 0.0 cpu
5 torch_dort 0.003886 0.003886 0.003886 0.003886 0.003886 0.0 cuda
Compilation Profiling¶
def clean_text(text):
pathes = [
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(torch.__file__), ".."))),
os.path.abspath(os.path.normpath(os.path.join(os.path.dirname(onnx.__file__), ".."))),
os.path.abspath(
os.path.normpath(
os.path.join(os.path.dirname(experimental_experiment.__file__), "..")
)
),
]
for p in pathes:
text = text.replace(p, "")
text = text.replace("experimental_experiment", "experimental_experiment".upper())
return text
def profile_function(name, export_function, with_args=True, verbose=False, suffix="export"):
if verbose:
print(f"profile {name}: {export_function}")
if with_args:
model, input_tensors = create_model_and_input()
export_function(model, input_tensors)
pr = cProfile.Profile()
pr.enable()
for _ in range(int(script_args.repeat1)):
export_function(model, input_tensors)
pr.disable()
else:
pr = cProfile.Profile()
pr.enable()
for _ in range(int(script_args.repeat1)):
export_function()
pr.disable()
s = io.StringIO()
sortby = SortKey.CUMULATIVE
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
# with open(f"plot_torch_aot_profile_{name}_{suffix}.pickle", "wb") as f:
# pickle.dump(ps, f)
raw = s.getvalue()
text = "\n".join(raw.split("\n")[:200])
if verbose:
print(text)
with open(f"plot_torch_aot_profile_{name}_{suffix}.txt", "w") as f:
f.write(raw)
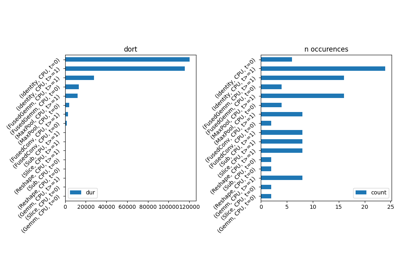
root, nodes = profile2graph(ps, clean_text=clean_text)
text = root.to_text()
with open(f"plot_torch_aot_profile_{name}_{suffix}_h.txt", "w") as f:
f.write(text)
if verbose:
print("done.")
model, input_tensors = create_model_and_input()
def function_to_profile(model=model, input_tensors=input_tensors):
return get_torch_dort(model, *input_tensors)
profile_function("dort", function_to_profile, verbose=True, suffix="1")
profile dort: <function function_to_profile at 0x7f5219f214e0>
1779362 function calls (1741080 primitive calls) in 2.502 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
13/8 0.000 0.000 1.109 0.139 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2447(_call)
13/8 0.000 0.000 1.109 0.139 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:966(call_function)
16/5 0.000 0.000 1.101 0.220 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:197(realize_and_forward)
1 0.000 0.000 0.968 0.968 ~/github/experimental-experiment/experimental_experiment/torch_models/training_helper.py:6(make_aot_ort)
1 0.000 0.000 0.968 0.968 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/onnxruntime.py:751(__init__)
1 0.000 0.000 0.688 0.688 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:98(__init__)
1 0.001 0.001 0.688 0.688 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:122(_initiate_registry_from_torchlib)
1 0.014 0.014 0.683 0.683 ~/github/onnxscript/onnxscript/_framework_apis/torch_2_5.py:82(get_torchlib_ops)
443 0.005 0.000 0.667 0.002 ~/github/onnxscript/onnxscript/values.py:640(function_ir)
593/496 0.001 0.000 0.289 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:755(__call__)
443 0.004 0.000 0.270 0.001 ~/github/onnxscript/onnxscript/_internal/ast_utils.py:16(get_src_and_ast)
128 0.039 0.000 0.263 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/functional_tensor.py:352(__torch_dispatch__)
443 0.001 0.000 0.209 0.000 ~/github/onnxscript/onnxscript/converter.py:1466(translate_function_signature)
443 0.014 0.000 0.207 0.000 ~/github/onnxscript/onnxscript/converter.py:1381(_translate_function_signature_common)
1 0.000 0.000 0.202 0.202 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:316(__init__)
443 0.001 0.000 0.191 0.000 /usr/lib/python3.12/inspect.py:1279(getsource)
443 0.019 0.000 0.190 0.000 /usr/lib/python3.12/inspect.py:1258(getsourcelines)
443 0.014 0.000 0.173 0.000 /usr/lib/python3.12/inspect.py:1606(getclosurevars)
297/276 0.002 0.000 0.166 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1327(__torch_dispatch__)
591/586 0.008 0.000 0.163 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1782(dispatch)
82 0.000 0.000 0.162 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:296(call_function)
2 0.030 0.015 0.156 0.078 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/decomposition_table.py:14(_create_onnx_supports_op_overload_table)
69/54 0.007 0.000 0.152 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:760(proxy_call)
212 0.003 0.000 0.151 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1342(_cached_dispatch_impl)
13183 0.059 0.000 0.147 0.000 /usr/lib/python3.12/dis.py:434(_get_instructions_bytes)
8 0.000 0.000 0.140 0.017 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/_pass.py:240(run)
4 0.000 0.000 0.137 0.034 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1691(_run)
443 0.040 0.000 0.137 0.000 /usr/lib/python3.12/inspect.py:1239(getblock)
2 0.000 0.000 0.134 0.067 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/onnxruntime.py:1073(compile)
2 0.000 0.000 0.134 0.067 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/infra/partitioner.py:385(partition_and_fuse)
2 0.000 0.000 0.129 0.064 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/infra/partitioner.py:298(fuse_partitions)
2 0.000 0.000 0.129 0.064 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/fuser_utils.py:250(fuse_by_partitions)
15033/3102 0.026 0.000 0.128 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:131(is_value_type)
1 0.000 0.000 0.119 0.119 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/backends/common.py:70(_wrapped_bw_compiler)
1 0.000 0.000 0.118 0.118 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/decomposition_table.py:73(create_onnx_friendly_decomposition_table)
1 0.000 0.000 0.117 0.117 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:125(items)
1 0.000 0.000 0.116 0.116 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:142(_materialize_if_needed)
1 0.003 0.003 0.116 0.116 ~/vv/this312/lib/python3.12/site-packages/torch/export/decomp_utils.py:129(materialize)
229353/224071 0.061 0.000 0.116 0.000 {built-in method builtins.isinstance}
26 0.001 0.000 0.112 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1117(_collect_all_valid_cia_ops_for_namespace)
1 0.000 0.000 0.105 0.105 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:1736(min_cut_rematerialization_partition)
26 0.040 0.002 0.101 0.004 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1052(_materialize_cpp_cia_ops)
2659 0.098 0.000 0.098 0.000 {built-in method builtins.compile}
86 0.001 0.000 0.096 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/passes/type_promotion.py:1596(run_node)
103/35 0.001 0.000 0.088 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1034(step)
45623 0.045 0.000 0.085 0.000 /usr/lib/python3.12/tokenize.py:569(_generate_tokens_from_c_tokenizer)
4 0.000 0.000 0.085 0.021 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/fuser_utils.py:95(fuse_as_graphmodule)
44987/44547 0.018 0.000 0.083 0.000 {built-in method builtins.next}
1796 0.001 0.000 0.083 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:172(is_valid_type)
12/6 0.000 0.000 0.079 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:741(wrapper)
198 0.002 0.000 0.079 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1716(_output_from_cache_entry)
12/6 0.000 0.000 0.078 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:2488(CALL)
202 0.007 0.000 0.077 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1650(_get_output_tensor_from_cache_entry)
11 0.000 0.000 0.077 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1562(python_code)
438/398 0.001 0.000 0.073 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:1229(__torch_function__)
16796 0.009 0.000 0.072 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:207(is_registered_op)
6208 0.013 0.000 0.071 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:873(__setattr__)
8 0.000 0.000 0.070 0.009 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:800(recompile)
143/114 0.001 0.000 0.069 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py:1944(__setattr__)
6/2 0.000 0.000 0.069 0.034 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/fx_onnx_interpreter.py:398(run_node)
3/2 0.000 0.000 0.069 0.034 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/fx_onnx_interpreter.py:561(placeholder)
3/2 0.000 0.000 0.069 0.034 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:613(add_input)
13 0.000 0.000 0.067 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:556(graph)
10 0.000 0.000 0.066 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:443(__init__)
4/2 0.000 0.000 0.065 0.033 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:270(_wrap_torch_value_to_tensor)
4/2 0.277 0.069 0.065 0.033 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:199(dtype)
4/2 0.277 0.069 0.065 0.033 ~/github/onnxscript/onnxscript/function_libs/torch_lib/graph_building/_graph_building_torch.py:170(shape)
16855 0.014 0.000 0.064 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/_exporter_legacy.py:185(get_op_functions)
443 0.002 0.000 0.062 0.000 /usr/lib/python3.12/ast.py:34(parse)
11524/5330 0.042 0.000 0.061 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:903(map_aggregate)
397 0.015 0.000 0.061 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1493(node_copy)
4 0.000 0.000 0.058 0.015 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/nn_module.py:880(call_function)
590 0.004 0.000 0.058 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1104(create_node)
11 0.000 0.000 0.058 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1639(_python_code)
11 0.017 0.002 0.057 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:397(_gen_python_code)
28 0.000 0.000 0.057 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1934(LOAD_ATTR)
28 0.000 0.000 0.057 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:1927(_load_attr)
13 0.000 0.000 0.057 0.004 {built-in method torch._to_functional_tensor}
5/4 0.000 0.000 0.056 0.014 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/functions.py:359(call_function)
5/4 0.000 0.000 0.056 0.014 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/functions.py:179(call_function)
15033 0.014 0.000 0.053 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:123(_is_tensor_type)
5/4 0.000 0.000 0.052 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:996(inline_user_function_return)
5/4 0.000 0.000 0.052 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:3235(inline_call)
5/4 0.000 0.000 0.051 0.013 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/symbolic_convert.py:3367(inline_call_)
212 0.002 0.000 0.051 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1385(_cache_key)
314 0.002 0.000 0.050 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1267(tree_map_only)
103555 0.045 0.000 0.048 0.000 {built-in method builtins.getattr}
1306 0.001 0.000 0.047 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:168(is_attr_type)
4 0.000 0.000 0.047 0.012 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/common.py:26(lift_subgraph_as_module)
12/9 0.000 0.000 0.047 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/nn/functional.py:1693(relu)
3697 0.004 0.000 0.046 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:894(map_arg)
804/219 0.006 0.000 0.046 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1461(_prep_args_for_hash)
9 0.000 0.000 0.046 0.005 {built-in method torch.relu}
14 0.000 0.000 0.043 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:2597(from_tensor)
2208 0.006 0.000 0.041 0.000 ~/github/onnxscript/onnxscript/converter.py:451(_eval_constant_expr)
4 0.002 0.000 0.041 0.010 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:160(_extract_graph_with_inputs_outputs)
2874/2655 0.003 0.000 0.041 0.000 /usr/lib/python3.12/contextlib.py:132(__enter__)
45181 0.022 0.000 0.040 0.000 /usr/lib/python3.12/collections/__init__.py:447(_make)
27/14 0.001 0.000 0.040 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:323(from_real_tensor)
12/9 0.001 0.000 0.038 0.004 {built-in method torch._C._nn.linear}
44547 0.022 0.000 0.037 0.000 {method 'get' of 'dict' objects}
15608 0.011 0.000 0.036 0.000 ~/github/onnxscript/onnxscript/type_annotation.py:70(_remove_annotation)
31/29 0.000 0.000 0.036 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:1064(call_function)
4 0.000 0.000 0.036 0.009 ~/vv/this312/lib/python3.12/site-packages/torch/overrides.py:1670(handle_torch_function)
112 0.001 0.000 0.036 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:211(create_proxy)
142 0.000 0.000 0.035 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:64(realize)
29 0.000 0.000 0.035 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:917(builtin_dispatch)
28 0.000 0.000 0.035 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:837(call_self_handler)
75 0.000 0.000 0.035 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/base.py:484(build)
28 0.000 0.000 0.035 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builtin.py:1731(call_getattr)
1 0.000 0.000 0.035 0.035 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:292(_extract_fwd_bwd_modules)
2874/2655 0.003 0.000 0.035 0.000 /usr/lib/python3.12/contextlib.py:141(__exit__)
1588/1396 0.001 0.000 0.035 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/base.py:199(__instancecheck__)
75 0.000 0.000 0.034 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:397(__call__)
1 0.000 0.000 0.034 0.034 ~/vv/this312/lib/python3.12/site-packages/torch/_export/utils.py:1134(_collect_all_valid_cia_ops)
51/35 0.000 0.000 0.033 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/nn_module.py:1044(var_getattr)
26483 0.028 0.000 0.033 0.000 /usr/lib/python3.12/dis.py:623(_unpack_opargs)
40 0.001 0.000 0.033 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:534(_wrap)
35/19 0.001 0.000 0.032 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/user_defined.py:1073(var_getattr)
31 0.001 0.000 0.032 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:1809(__call__)
632 0.002 0.000 0.032 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:985(tree_flatten)
61 0.000 0.000 0.032 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:592(track_tensor_tree)
6 0.000 0.000 0.032 0.005 ~/vv/this312/lib/python3.12/site-packages/tqdm/std.py:952(__init__)
36 0.000 0.000 0.032 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/lazy.py:22(realize)
10079 0.015 0.000 0.031 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/registration.py:55(from_qualified_name)
13 0.000 0.000 0.031 0.002 ~/vv/this312/lib/python3.12/site-packages/tqdm/std.py:113(__exit__)
13 0.000 0.000 0.031 0.002 ~/vv/this312/lib/python3.12/site-packages/tqdm/std.py:106(release)
13 0.031 0.002 0.031 0.002 {method 'release' of '_multiprocessing.SemLock' objects}
31 0.001 0.000 0.030 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/meta_utils.py:847(meta_tensor)
1973/632 0.009 0.000 0.030 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:993(helper)
443 0.005 0.000 0.030 0.000 /usr/lib/python3.12/inspect.py:1070(findsource)
76/61 0.001 0.000 0.029 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:614(wrap_with_proxy)
15 0.003 0.000 0.029 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1699(lint)
99 0.001 0.000 0.029 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1174(erase_node)
69/54 0.001 0.000 0.028 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:2246(maybe_handle_decomp)
216/2 0.006 0.000 0.028 0.014 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/diagnostics/infra/decorator.py:66(wrapper)
444 0.009 0.000 0.028 0.000 /usr/lib/python3.12/dis.py:647(findlabels)
5 0.000 0.000 0.027 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_prims_common/wrappers.py:287(_fn)
3 0.000 0.000 0.027 0.009 ~/vv/this312/lib/python3.12/site-packages/torch/_decomp/__init__.py:155(_fn)
614 0.004 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:377(prepend)
3 0.000 0.000 0.027 0.009 ~/vv/this312/lib/python3.12/site-packages/torch/_decomp/decompositions.py:221(threshold_backward)
59 0.000 0.000 0.027 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/onnxfunction_dispatcher.py:98(dispatch)
317 0.008 0.000 0.026 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:671(__new__)
19325 0.015 0.000 0.026 0.000 /usr/lib/python3.12/typing.py:2340(get_origin)
370 0.004 0.000 0.026 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:627(emit_node)
114 0.002 0.000 0.026 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/proxy.py:145(create_node)
4 0.000 0.000 0.026 0.006 ~/vv/this312/lib/python3.12/site-packages/torch/fx/passes/utils/fuser_utils.py:243(erase_nodes)
18 0.000 0.000 0.025 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:2578(wrap_fake_exception)
9 0.000 0.000 0.025 0.003 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:1593(wrap_tensor)
6865 0.019 0.000 0.025 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:907(__contains__)
16855 0.010 0.000 0.024 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/onnx/_internal/fx/registration.py:45(from_name_parts)
836 0.004 0.000 0.024 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:573(__update_args_kwargs)
31 0.001 0.000 0.023 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/autograd/grad_mode.py:273(__exit__)
70663 0.022 0.000 0.022 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.022 0.022 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:548(reordering_to_mimic_autograd_engine)
9 0.000 0.000 0.021 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/torch.py:970(call_function)
713 0.001 0.000 0.021 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:437(_remove_from_list)
261 0.007 0.000 0.021 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:948(_flatten_into)
1 0.000 0.000 0.020 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:1497(choose_saved_values_set)
1 0.001 0.001 0.020 0.020 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/partitioners.py:817(solve_min_cut)
71521 0.020 0.000 0.020 0.000 {built-in method __new__ of type object at 0xa20960}
233 0.020 0.000 0.020 0.000 {built-in method torch.empty_strided}
129/120 0.001 0.000 0.019 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_ops.py:790(decompose)
74 0.002 0.000 0.019 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:485(set_meta)
3 0.000 0.000 0.019 0.006 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:920(print_readable)
3 0.000 0.000 0.019 0.006 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph_module.py:303(_print_readable)
448 0.001 0.000 0.019 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/utils/_pytree.py:1212(wrapped)
4 0.000 0.000 0.019 0.005 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/aot_autograd.py:490(convert)
22 0.001 0.000 0.018 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1616(override_node_repr)
3 0.000 0.000 0.018 0.006 {built-in method torch.where}
261 0.005 0.000 0.018 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:968(extract_tensor_metadata)
125830/125711 0.018 0.000 0.018 0.000 {built-in method builtins.len}
604 0.005 0.000 0.017 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/node.py:240(__init__)
45659 0.016 0.000 0.017 0.000 {built-in method builtins.hasattr}
7 0.001 0.000 0.017 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:1808(eliminate_dead_code)
9 0.000 0.000 0.017 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2876(wrap_to_fake_tensor_and_record)
14 0.000 0.000 0.017 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_subclasses/fake_tensor.py:1968(_dispatch_impl)
2865 0.015 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:910(insert)
813/669 0.006 0.000 0.016 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/recording.py:238(wrapper)
13155 0.007 0.000 0.016 0.000 {built-in method builtins.issubclass}
9 0.000 0.000 0.016 0.002 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2913(<lambda>)
1 0.001 0.001 0.015 0.015 ~/vv/this312/lib/python3.12/site-packages/torch/_functorch/compile_utils.py:42(fx_graph_cse)
432 0.001 0.000 0.015 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/interpreter.py:211(_set_current_node)
1 0.000 0.000 0.015 0.015 <class 'networkx.utils.decorators.argmap'> compilation 4:1(argmap_minimum_cut_1)
6/1 0.000 0.000 0.014 0.014 ~/vv/this312/lib/python3.12/site-packages/networkx/utils/backends.py:959(__call__)
1 0.000 0.000 0.014 0.014 ~/vv/this312/lib/python3.12/site-packages/networkx/algorithms/flow/maxflow.py:307(minimum_cut)
85/80 0.000 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:385(extract_val)
18 0.000 0.000 0.014 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2209(wrap_fx_proxy)
18 0.000 0.000 0.014 0.001 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/variables/builder.py:2282(wrap_fx_proxy_cls)
358/272 0.006 0.000 0.014 0.000 {built-in method torch._ops.prim.}
2 0.000 0.000 0.014 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/metrics_context.py:52(__exit__)
2 0.000 0.000 0.014 0.007 ~/vv/this312/lib/python3.12/site-packages/torch/_dynamo/utils.py:1425(record_compilation_metrics)
82 0.000 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/experimental/proxy_tensor.py:359(snapshot_fake)
26 0.014 0.001 0.014 0.001 {built-in method torch._C._dispatch_get_registrations_for_dispatch_key}
1774 0.007 0.000 0.014 0.000 ~/vv/this312/lib/python3.12/site-packages/torch/fx/graph.py:144(create_name)
done.
Benchmark exported models with ORT¶
def benchmark(shape):
data = []
data_mem_first_run = []
data_mem_run = []
confs = list(
itertools.product(
export_functions,
["CPU", "CUDA"],
)
)
loop = tqdm(confs)
print(f"number of experiments: {len(loop)}")
for export_fct, p in loop:
name = export_fct.__name__.replace("get_torch_", "")
obs = {} # system_info()
obs["name"] = name
obs["compute"] = p
obs["export"] = name
model, input_tensors = create_model_and_input()
if p == "CUDA":
if not has_cuda:
continue
model = model.cuda()
input_tensors = [i.cuda() for i in input_tensors]
try:
exported_model = export_fct(model, *input_tensors)
except Exception as e:
obs["error"] = str(e)
data.append(obs)
continue
def call_model(
export_fct=export_fct,
exported_model=exported_model,
input_tensors=input_tensors,
):
res = run(exported_model, *input_tensors)
return res
stat = start_spying_on(cuda=1 if has_cuda else 0)
try:
call_model()
except Exception as e:
loop.set_description(f"ERROR-run: {name} {e}")
obs.update({"error": e, "step": "load"})
data.append(obs)
stat.stop()
continue
memobs = flatten(stat.stop())
memobs.update(obs)
data_mem_first_run.append(memobs)
# memory consumption
stat = start_spying_on(cuda=1 if has_cuda else 0)
for _ in range(0, script_args.warmup):
call_model()
memobs = flatten(stat.stop())
memobs.update(obs)
data_mem_run.append(memobs)
obs.update(
measure_time(
call_model,
max_time=script_args.maxtime,
repeat=script_args.repeat,
number=1,
)
)
profile_function(name, call_model, with_args=False, suffix=f"run_{p}")
loop.set_description(f"{obs['average']} {name} {p}")
data.append(obs)
del model
del exported_model
gc.collect()
time.sleep(1)
df = pandas.DataFrame(data)
df.to_csv("plot_torch_aot_ort_time.csv", index=False)
df.to_excel("plot_torch_aot_ort_time.xlsx", index=False)
dfmemr = pandas.DataFrame(data_mem_run)
dfmemr.to_csv("plot_torch_aot_ort_run_mem.csv", index=False)
dfmemr.to_excel("plot_torch_aot_ort_run_mem.xlsx", index=False)
dfmemfr = pandas.DataFrame(data_mem_first_run)
dfmemfr.to_csv("plot_torch_aot_ort_first_run_mem.csv", index=False)
dfmemfr.to_excel("plot_torch_aot_ort_first_run_mem.xlsx", index=False)
return df, dfmemfr, dfmemr
df, dfmemfr, dfmemr = benchmark(list(input_tensors[0].shape))
print(df)
0%| | 0/6 [00:00<?, ?it/s]number of experiments: 6
0.003078366866672392 eager CPU: 0%| | 0/6 [00:00<?, ?it/s]
0.003078366866672392 eager CPU: 17%|█▋ | 1/6 [00:02<00:10, 2.16s/it]
0.003959071259251451 eager CUDA: 17%|█▋ | 1/6 [00:02<00:10, 2.16s/it]
0.003959071259251451 eager CUDA: 33%|███▎ | 2/6 [00:04<00:08, 2.11s/it]
0.009052411583449308 default CPU: 33%|███▎ | 2/6 [00:14<00:08, 2.11s/it]
0.009052411583449308 default CPU: 50%|█████ | 3/6 [00:16<00:19, 6.55s/it]
0.0016016218507583792 default CUDA: 50%|█████ | 3/6 [00:22<00:19, 6.55s/it]
0.0016016218507583792 default CUDA: 67%|██████▋ | 4/6 [00:23<00:13, 6.89s/it]~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/utils.py:130: UserWarning: Your compiler for AOTAutograd is returning a function that doesn't take boxed arguments. Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale.
warnings.warn(
0.0030333529743634593 dort CPU: 67%|██████▋ | 4/6 [00:25<00:13, 6.89s/it]
0.0030333529743634593 dort CPU: 83%|████████▎ | 5/6 [00:26<00:05, 5.63s/it]~/vv/this312/lib/python3.12/site-packages/torch/_functorch/_aot_autograd/utils.py:130: UserWarning: Your compiler for AOTAutograd is returning a function that doesn't take boxed arguments. Please wrap it with functorch.compile.make_boxed_func or handle the boxed arguments yourself. See https://github.com/pytorch/pytorch/pull/83137#issuecomment-1211320670 for rationale.
warnings.warn(
0.0050069761428815016 dort CUDA: 83%|████████▎ | 5/6 [00:28<00:05, 5.63s/it]
0.0050069761428815016 dort CUDA: 100%|██████████| 6/6 [00:30<00:00, 4.84s/it]
0.0050069761428815016 dort CUDA: 100%|██████████| 6/6 [00:30<00:00, 5.03s/it]
name compute export average deviation min_exec max_exec repeat number ttime context_size warmup_time
0 eager CPU eager 0.003078 0.000427 0.002890 0.005783 1 45.0 0.138527 64 0.008740
1 eager CUDA eager 0.003959 0.001647 0.002006 0.006539 1 27.0 0.106895 64 0.005126
2 default CPU default 0.009052 0.002762 0.005510 0.015722 1 12.0 0.108629 64 0.008452
3 default CUDA default 0.001602 0.000072 0.001573 0.001989 1 67.0 0.107309 64 0.002281
4 dort CPU dort 0.003033 0.000175 0.002896 0.003352 1 39.0 0.118301 64 0.011005
5 dort CUDA dort 0.005007 0.001195 0.003679 0.007981 1 21.0 0.105146 64 0.009875
Other view
def view_time(df, title, suffix="time"):
piv = pandas.pivot_table(df, index="export", columns=["compute"], values="average")
print(piv)
piv.to_csv(f"plot_torch_aot_{suffix}_compute.csv")
piv.to_excel(f"plot_torch_aot_{suffix}_compute.xlsx")
piv_cpu = pandas.pivot_table(
df[df.compute == "CPU"],
index="export",
columns=["compute"],
values="average",
)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
fig.suptitle(title)
piv_cpu.plot.barh(ax=ax[0], title="CPU", logx=True)
if has_cuda:
piv_gpu = pandas.pivot_table(
df[df.compute == "CUDA"],
index="export",
columns=["compute"],
values="average",
)
piv_gpu.plot.barh(ax=ax[1], title="CUDA", logx=True)
fig.tight_layout()
fig.savefig(f"plot_torch_aot_{suffix}.png")
return ax
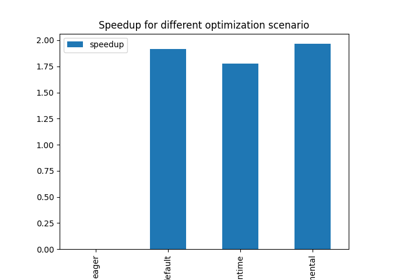
view_time(df, "Compares processing time on backends")
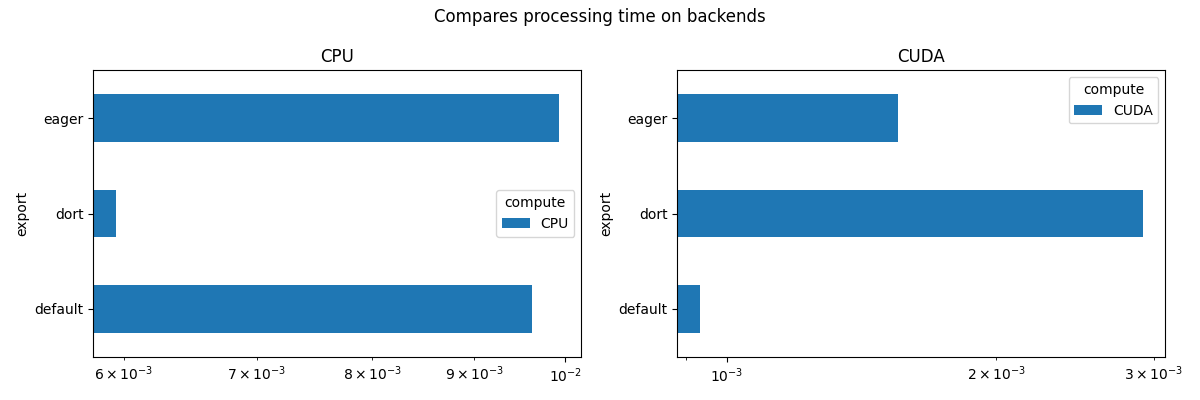
compute CPU CUDA
export
default 0.009052 0.001602
dort 0.003033 0.005007
eager 0.003078 0.003959
array([<Axes: title={'center': 'CPU'}, ylabel='export'>,
<Axes: title={'center': 'CUDA'}, ylabel='export'>], dtype=object)
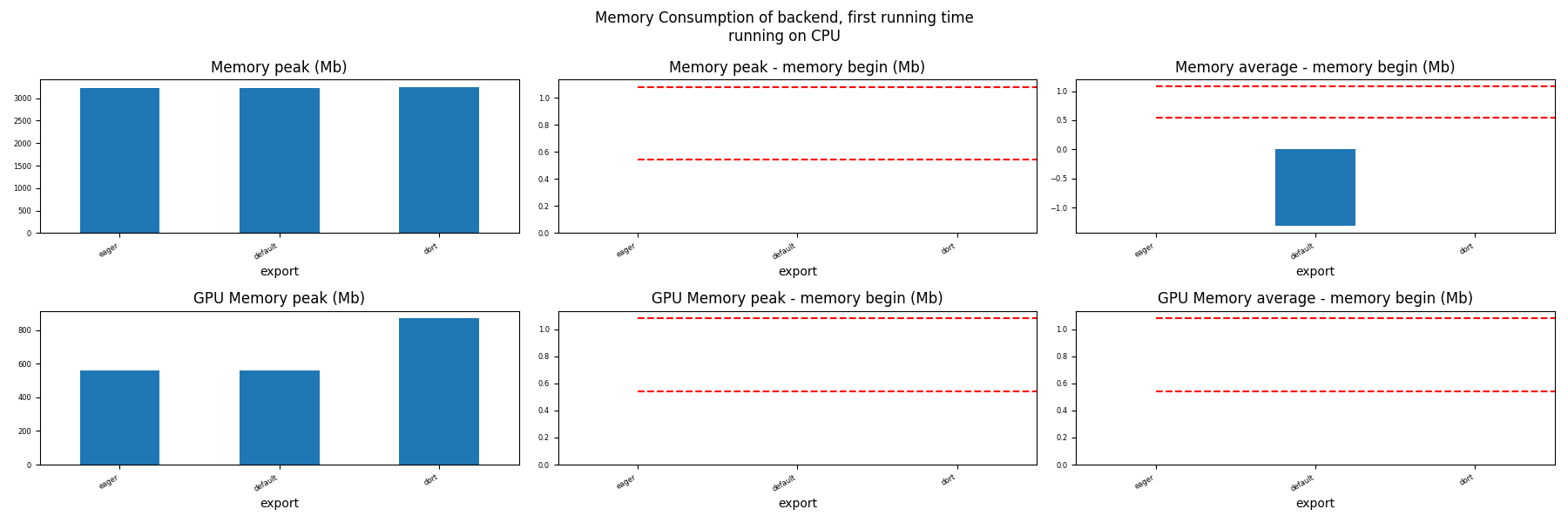
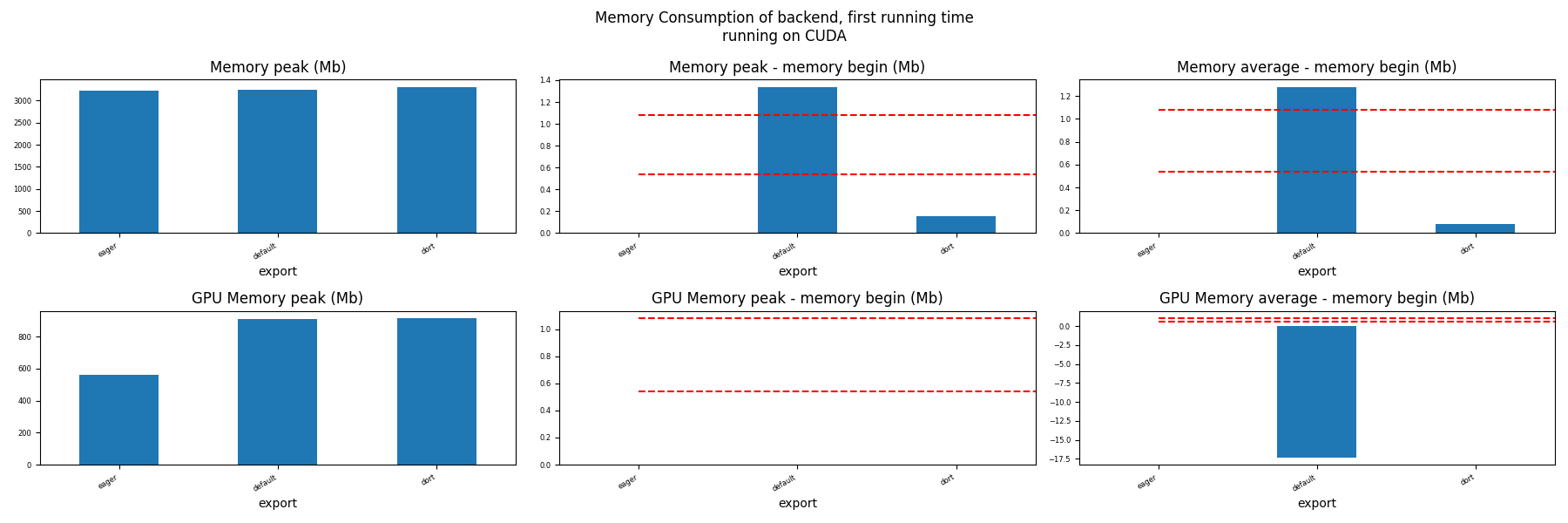
Memory First Running Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemfr[dfmemfr.compute == compute],
("export",),
suptitle=f"Memory Consumption of backend, first running time"
f"\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_aot_first_run_mem_{compute}.png")
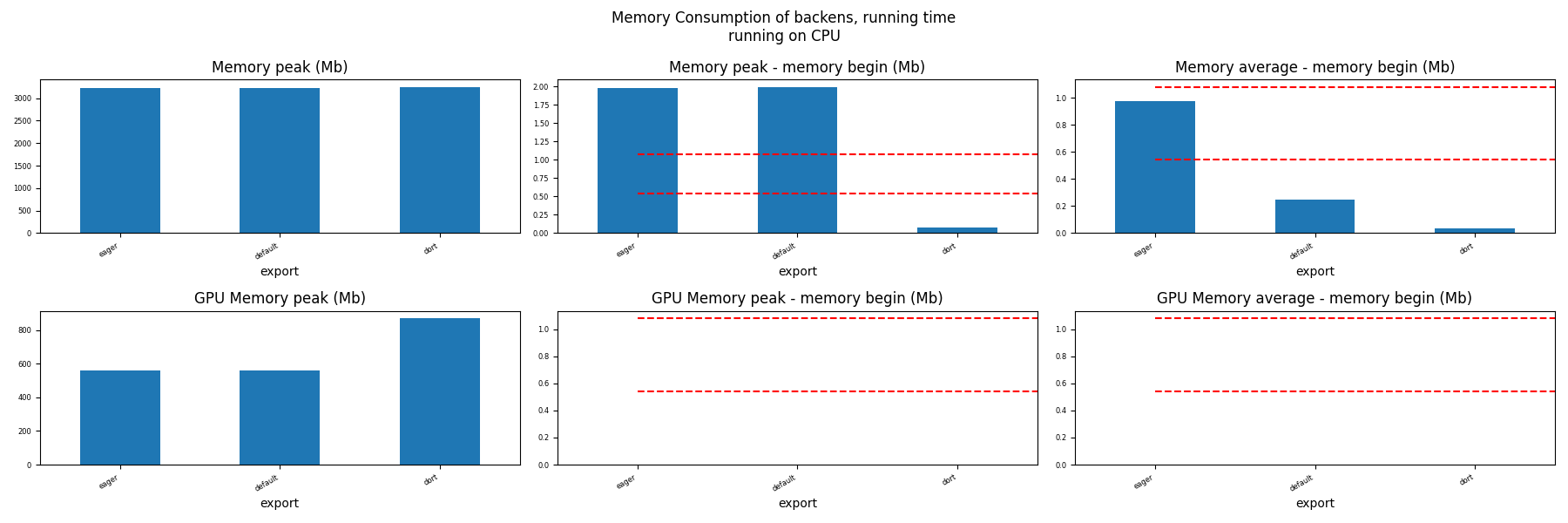
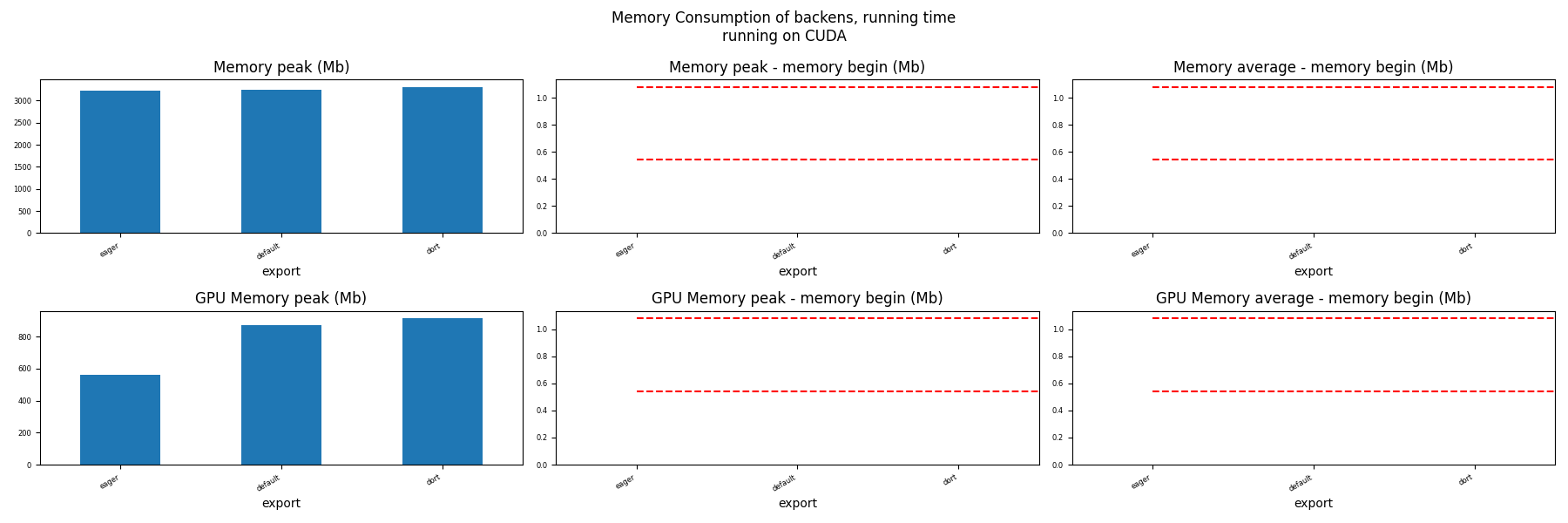
Memory Running Time (ORT)¶
for compute in ["CPU", "CUDA"]:
if not has_cuda and compute == "CUDA":
continue
ax = memory_peak_plot(
dfmemr[dfmemr.compute == compute],
("export",),
suptitle=f"Memory Consumption of backens, running time\nrunning on {compute}",
bars=[model_size * i / 2**20 for i in range(1, 3)],
figsize=(18, 6),
)
get_figure(ax).savefig(f"plot_torch_aot_run_mem_{compute}.png")
Total running time of the script: (1 minutes 7.393 seconds)
Related examples
201: Evaluate different ways to export a torch model to ONNX
201: Evaluate different ways to export a torch model to ONNX