Note
Go to the end to download the full example code.
to_onnx and a model with a test¶
Control flow cannot be exported with a change.
The code of the model can be changed or patched
to introduce function torch.cond().
A model with a test¶
import torch
from onnx_array_api.plotting.graphviz_helper import plot_dot
from experimental_experiment.helpers import pretty_onnx
from experimental_experiment.torch_interpreter import to_onnx
We define a model with a control flow (-> graph break)
class ForwardWithControlFlowTest(torch.nn.Module):
def forward(self, x):
if x.sum():
return x * 2
return -x
class ModelWithControlFlow(torch.nn.Module):
def __init__(self):
super().__init__()
self.mlp = torch.nn.Sequential(
torch.nn.Linear(3, 2),
torch.nn.Linear(2, 1),
ForwardWithControlFlowTest(),
)
def forward(self, x):
out = self.mlp(x)
return out
model = ModelWithControlFlow()
Let’s check it runs.
x = torch.randn(1, 3)
model(x)
tensor([[-0.7766]], grad_fn=<MulBackward0>)
As expected, it does not export.
try:
torch.export.export(model, (x,))
raise AssertionError("This export should failed unless pytorch now supports this model.")
except Exception as e:
print(e)
Dynamic control flow is not supported at the moment. Please use torch.cond to explicitly capture the control flow. For more information about this error, see: https://pytorch.org/docs/main/generated/exportdb/index.html#cond-operands
from user code:
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_c_cond.py", line 42, in forward
out = self.mlp(x)
File "~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
return forward_call(*args, **kwargs)
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_c_cond.py", line 27, in forward
if x.sum():
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
The exporter fails with the same eror as it expects torch.export.export to work.
Dynamic control flow is not supported at the moment. Please use torch.cond to explicitly capture the control flow. For more information about this error, see: https://pytorch.org/docs/main/generated/exportdb/index.html#cond-operands
from user code:
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_c_cond.py", line 42, in forward
out = self.mlp(x)
File "~/vv/this312/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
return forward_call(*args, **kwargs)
File "~/github/experimental-experiment/_doc/recipes/plot_exporter_recipes_c_cond.py", line 27, in forward
if x.sum():
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
Suggested Patch¶
Let’s avoid the graph break by replacing the forward.
def new_forward(x):
def identity2(x):
return x * 2
def neg(x):
return -x
return torch.cond(x.sum() > 0, identity2, neg, (x,))
print("the list of submodules")
for name, mod in model.named_modules():
print(name, type(mod))
if isinstance(mod, ForwardWithControlFlowTest):
mod.forward = new_forward
the list of submodules
<class '__main__.ModelWithControlFlow'>
mlp <class 'torch.nn.modules.container.Sequential'>
mlp.0 <class 'torch.nn.modules.linear.Linear'>
mlp.1 <class 'torch.nn.modules.linear.Linear'>
mlp.2 <class '__main__.ForwardWithControlFlowTest'>
Let’s see what the fx graph looks like.
print(torch.export.export(model, (x,)).graph)
graph():
%p_mlp_0_weight : [num_users=1] = placeholder[target=p_mlp_0_weight]
%p_mlp_0_bias : [num_users=1] = placeholder[target=p_mlp_0_bias]
%p_mlp_1_weight : [num_users=1] = placeholder[target=p_mlp_1_weight]
%p_mlp_1_bias : [num_users=1] = placeholder[target=p_mlp_1_bias]
%x : [num_users=1] = placeholder[target=x]
%linear : [num_users=1] = call_function[target=torch.ops.aten.linear.default](args = (%x, %p_mlp_0_weight, %p_mlp_0_bias), kwargs = {})
%linear_1 : [num_users=2] = call_function[target=torch.ops.aten.linear.default](args = (%linear, %p_mlp_1_weight, %p_mlp_1_bias), kwargs = {})
%sum_1 : [num_users=1] = call_function[target=torch.ops.aten.sum.default](args = (%linear_1,), kwargs = {})
%gt : [num_users=1] = call_function[target=torch.ops.aten.gt.Scalar](args = (%sum_1, 0), kwargs = {})
%true_graph_0 : [num_users=1] = get_attr[target=true_graph_0]
%false_graph_0 : [num_users=1] = get_attr[target=false_graph_0]
%cond : [num_users=1] = call_function[target=torch.ops.higher_order.cond](args = (%gt, %true_graph_0, %false_graph_0, [%linear_1]), kwargs = {})
%getitem : [num_users=1] = call_function[target=operator.getitem](args = (%cond, 0), kwargs = {})
return (getitem,)
Let’s export again.
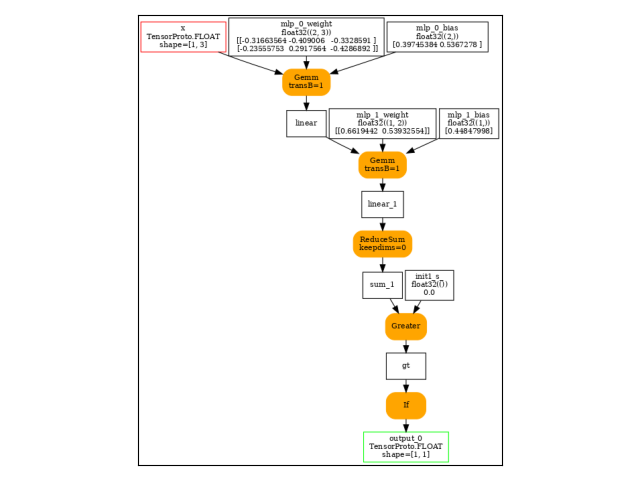
onx = to_onnx(model, (x,))
print(pretty_onnx(onx))
opset: domain='' version=18
opset: domain='local_functions' version=1
input: name='x' type=dtype('float32') shape=[1, 3]
init: name='init1_s_' type=float32 shape=() -- array([0.], dtype=float32)-- shape_type_compute._cast_inputs.1(gt_Scalar)
init: name='init7_s2_-1_1' type=int64 shape=(2,) -- array([-1, 1]) -- TransposeEqualReshapePattern.apply.new_shape
init: name='init7_s2_1_-1' type=int64 shape=(2,) -- array([ 1, -1]) -- TransposeEqualReshapePattern.apply.new_shape
init: name='mlp.0.weight' type=float32 shape=(2, 3) -- DynamoInterpret.placeholder.1/P(mlp.0.weight)
init: name='mlp.0.bias' type=float32 shape=(2,) -- array([-0.42619753, 0.14323725], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.0.bias)
init: name='mlp.1.weight' type=float32 shape=(1, 2) -- array([0.1824264 , 0.20393367], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.1.weight)
init: name='mlp.1.bias' type=float32 shape=(1,) -- array([-0.39891502], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.1.bias)
Gemm(x, mlp.0.weight, mlp.0.bias, transB=1) -> linear
Reshape(mlp.1.weight, init7_s2_-1_1) -> _onx_transpose_p_mlp_1_weight0
Reshape(_onx_transpose_p_mlp_1_weight0, init7_s2_1_-1) -> GemmTransposePattern--_onx_transpose_p_mlp_1_weight0
Gemm(linear, GemmTransposePattern--_onx_transpose_p_mlp_1_weight0, mlp.1.bias, transB=1) -> linear_1
ReduceSum(linear_1, keepdims=0) -> sum_1
Greater(sum_1, init1_s_) -> gt
If(gt, else_branch=G1, then_branch=G2) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 1]
----- subgraph ---- If - cond - att.else_branch=G1 -- level=1 -- -> cond#0
false_graph_0[local_functions](linear_1) -> cond#0
output: name='cond#0' type='NOTENSOR' shape=None
----- subgraph ---- If - cond - att.then_branch=G2 -- level=1 -- -> cond#0
true_graph_0[local_functions](linear_1) -> cond#0
output: name='cond#0' type='NOTENSOR' shape=None
----- function name=true_graph_0 domain=local_functions
----- doc_string: -- function_options=FunctionOptions(export_as_function=...
opset: domain='' version=18
input: 'linear_1'
Constant(value=2.0) -> init1_s_
Constant(value=[1]) -> init7_s1_1
Reshape(init1_s_, init7_s1_1) -> _reshape_init1_s_0
Mul(linear_1, _reshape_init1_s_0) -> output_0
output: name='output_0' type=? shape=?
----- function name=false_graph_0 domain=local_functions
----- doc_string: -- function_options=FunctionOptions(export_as_function=...
opset: domain='' version=18
opset: domain='local_functions' version=1
input: 'linear_1'
Neg(linear_1) -> output_0
output: name='output_0' type=? shape=?
We can also inline the local function.
onx = to_onnx(model, (x,), inline=True)
print(pretty_onnx(onx))
opset: domain='' version=18
opset: domain='local_functions' version=1
input: name='x' type=dtype('float32') shape=[1, 3]
init: name='init1_s_' type=float32 shape=() -- array([0.], dtype=float32)-- shape_type_compute._cast_inputs.1(gt_Scalar)
init: name='init7_s2_-1_1' type=int64 shape=(2,) -- array([-1, 1]) -- TransposeEqualReshapePattern.apply.new_shape
init: name='init7_s2_1_-1' type=int64 shape=(2,) -- array([ 1, -1]) -- TransposeEqualReshapePattern.apply.new_shape
init: name='mlp.0.weight' type=float32 shape=(2, 3) -- DynamoInterpret.placeholder.1/P(mlp.0.weight)
init: name='mlp.0.bias' type=float32 shape=(2,) -- array([-0.42619753, 0.14323725], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.0.bias)
init: name='mlp.1.weight' type=float32 shape=(1, 2) -- array([0.1824264 , 0.20393367], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.1.weight)
init: name='mlp.1.bias' type=float32 shape=(1,) -- array([-0.39891502], dtype=float32)-- DynamoInterpret.placeholder.1/P(mlp.1.bias)
Gemm(x, mlp.0.weight, mlp.0.bias, transB=1) -> linear
Reshape(mlp.1.weight, init7_s2_-1_1) -> _onx_transpose_p_mlp_1_weight0
Reshape(_onx_transpose_p_mlp_1_weight0, init7_s2_1_-1) -> GemmTransposePattern--_onx_transpose_p_mlp_1_weight0
Gemm(linear, GemmTransposePattern--_onx_transpose_p_mlp_1_weight0, mlp.1.bias, transB=1) -> linear_1
ReduceSum(linear_1, keepdims=0) -> sum_1
Greater(sum_1, init1_s_) -> gt
If(gt, else_branch=G1, then_branch=G2) -> output_0
output: name='output_0' type=dtype('float32') shape=[1, 1]
----- subgraph ---- If - cond - att.else_branch=G1 -- level=1 -- -> cond#0
Neg(linear_1) -> cond#0
output: name='cond#0' type='NOTENSOR' shape=None
----- subgraph ---- If - cond - att.then_branch=G2 -- level=1 -- -> cond#0
Constant(value=[1]) -> init7_s1_122
Constant(value=2.0) -> init1_s_22
Reshape(init1_s_22, init7_s1_122) -> _reshape_init1_s_022
Mul(linear_1, _reshape_init1_s_022) -> cond#0
output: name='cond#0' type='NOTENSOR' shape=None
And visually.
Total running time of the script: (0 minutes 1.228 seconds)
Related examples


to_onnx and a custom operator registered with a function
to_onnx and a custom operator registered with a function
torch.onnx.export and padding one dimension to a mulitple of a constant
torch.onnx.export and padding one dimension to a mulitple of a constant