Note
Go to the end to download the full example code.
Gemm or Matmul + Add¶
Order of computation matters. 1 + 1e-20 - 1 != 1 - 1 + 1e-20 if the
precision of the computation is taken into account.
What an operator Gemm in onnxruntime, the most simple
way to represent a linear neural layer.
A model with many choices¶
import cpuinfo
import numpy as np
import pandas
import matplotlib.pyplot as plt
import onnx
import onnx.helper as oh
import torch
from onnx_diagnostic.helpers import max_diff
from onnx_diagnostic.helpers.onnx_helper import pretty_onnx
from onnx_diagnostic.reference import OnnxruntimeEvaluator
from onnxruntime import (
InferenceSession,
SessionOptions,
__version__ as version_onnxruntime,
GraphOptimizationLevel,
)
print(f"onnxruntime version = {version_onnxruntime}")
print(f"cpu name = {cpuinfo.get_cpu_info()['brand_raw']}")
if torch.cuda.is_available():
print(f"gpu name = {torch.cuda.get_device_name(0)}")
print(f"cuda version = {torch.version.cuda}")
onnxruntime version = 1.23.2
cpu name = 13th Gen Intel(R) Core(TM) i7-13800H
gpu name = NVIDIA GeForce RTX 4060 Laptop GPU
cuda version = 13.0
The version is important. Numerical differences are observed with onnxruntime<=1.22. Let’s see how to make them happen.
def make_model_gemm(itype: int) -> onnx.ModelProto:
return oh.make_model(
oh.make_graph(
[
oh.make_node("Gemm", ["A", "X", "B"], ["GemmOnly"]),
oh.make_node("Gemm", ["A", "X"], ["gmm"]),
oh.make_node("Add", ["gmm", "B"], ["GemmAdd"]),
oh.make_node("MatMul", ["A", "X"], ["mm"]),
oh.make_node("Add", ["mm", "B"], ["MatMulAdd"]),
oh.make_node("FusedMatMul", ["A", "X"], ["fmm"], domain="com.microsoft"),
oh.make_node("Add", ["fmm", "B"], ["FusedMatMulAdd"]),
oh.make_node("Cast", ["A"], ["Afloat"], to=onnx.TensorProto.FLOAT),
oh.make_node("Cast", ["B"], ["Bfloat"], to=onnx.TensorProto.FLOAT),
oh.make_node("Cast", ["X"], ["Xfloat"], to=onnx.TensorProto.FLOAT),
oh.make_node("Gemm", ["Afloat", "Xfloat"], ["gmmfloat"]),
oh.make_node("Add", ["gmmfloat", "Bfloat"], ["gemmaddfloat"]),
oh.make_node("Cast", ["gemmaddfloat"], ["CastGemmAddCast"], to=itype),
oh.make_node("Gemm", ["Afloat", "Xfloat", "Bfloat"], ["GemmOnlyfloat"]),
oh.make_node("Cast", ["GemmOnlyfloat"], ["CastGemmOnlyCast"], to=itype),
],
"test",
[
oh.make_tensor_value_info("A", itype, ["a", "b"]),
oh.make_tensor_value_info("X", itype, ["b", "c"]),
oh.make_tensor_value_info("B", itype, ["c"]),
],
[
oh.make_tensor_value_info("GemmOnly", itype, ["a", "c"]),
oh.make_tensor_value_info("GemmAdd", itype, ["a", "c"]),
oh.make_tensor_value_info("FusedMatMulAdd", itype, ["a", "c"]),
oh.make_tensor_value_info("MatMulAdd", itype, ["a", "c"]),
oh.make_tensor_value_info("CastGemmAddCast", itype, ["a", "c"]),
oh.make_tensor_value_info("CastGemmOnlyCast", itype, ["a", "c"]),
],
),
opset_imports=[oh.make_opsetid("", 22)],
ir_version=10,
)
def matrix_diff(tensors):
mat = np.zeros((len(tensors), len(tensors)), dtype=np.float32)
for i, t in enumerate(tensors):
for j in range(i + 1, len(tensors)):
mat[i, j] = max_diff(t, tensors[j])["abs"]
mat[j, i] = mat[i, j]
return mat
itype = onnx.TensorProto.FLOAT16
dtype = np.float16
model = make_model_gemm(itype)
A = np.random.randn(1280, 256).astype(dtype)
X = np.random.randn(256, 256).astype(dtype)
B = np.random.randn(256).astype(dtype)
feeds = dict(A=A, X=X, B=B)
We disable all the optimization made by onnxruntime to make the computation follows what we want to verify.
opts = SessionOptions()
opts.graph_optimization_level = GraphOptimizationLevel.ORT_DISABLE_ALL
opts.optimized_model_filepath = "plot_gemm_or_matmul.optimized.onnx"
sess = InferenceSession(model.SerializeToString(), opts, providers=["CPUExecutionProvider"])
results = [A @ X + B, *sess.run(None, feeds)]
diffs = matrix_diff(results)
print(diffs)
[[0. 0.0625 0.0625 0.0625 0.0625 0.0625 0.0625 ]
[0.0625 0. 0.015625 0.015625 0.015625 0.015625 0. ]
[0.0625 0.015625 0. 0. 0. 0. 0.015625]
[0.0625 0.015625 0. 0. 0. 0. 0.015625]
[0.0625 0.015625 0. 0. 0. 0. 0.015625]
[0.0625 0.015625 0. 0. 0. 0. 0.015625]
[0.0625 0. 0.015625 0.015625 0.015625 0.015625 0. ]]
onx = onnx.load(opts.optimized_model_filepath)
print(pretty_onnx(onx))
opset: domain='' version=22
opset: domain='ai.onnx.ml' version=5
opset: domain='ai.onnx.training' version=1
opset: domain='ai.onnx.preview.training' version=1
opset: domain='com.microsoft' version=1
opset: domain='com.microsoft.experimental' version=1
opset: domain='com.microsoft.nchwc' version=1
opset: domain='org.pytorch.aten' version=1
input: name='A' type=dtype('float16') shape=['a', 'b']
input: name='X' type=dtype('float16') shape=['b', 'c']
input: name='B' type=dtype('float16') shape=['c']
Cast(X, saturate=1, to=1) -> Xfloat
Cast(B, saturate=1, to=1) -> InsertedPrecisionFreeCast_B
Cast(X, saturate=1, to=1) -> InsertedPrecisionFreeCast_X
Cast(A, saturate=1, to=1) -> InsertedPrecisionFreeCast_A
Gemm(InsertedPrecisionFreeCast_A, InsertedPrecisionFreeCast_X, InsertedPrecisionFreeCast_B, transA=0, alpha=1.00, beta=1.00, transB=0) -> InsertedPrecisionFreeCast_GemmOnly
Cast(InsertedPrecisionFreeCast_GemmOnly, saturate=1, to=10) -> GemmOnly
Gemm(InsertedPrecisionFreeCast_A, InsertedPrecisionFreeCast_X, transA=0, alpha=1.00, beta=1.00, transB=0) -> InsertedPrecisionFreeCast_gmm
Add(InsertedPrecisionFreeCast_gmm, InsertedPrecisionFreeCast_B) -> InsertedPrecisionFreeCast_GemmAdd
Cast(InsertedPrecisionFreeCast_GemmAdd, saturate=1, to=10) -> GemmAdd
MatMul(InsertedPrecisionFreeCast_A, InsertedPrecisionFreeCast_X) -> InsertedPrecisionFreeCast_mm
Add(InsertedPrecisionFreeCast_mm, InsertedPrecisionFreeCast_B) -> InsertedPrecisionFreeCast_MatMulAdd
Cast(InsertedPrecisionFreeCast_MatMulAdd, saturate=1, to=10) -> MatMulAdd
FusedMatMul[com.microsoft](InsertedPrecisionFreeCast_A, InsertedPrecisionFreeCast_X, transA=0, transB=0, alpha=1.00, transBatchB=0, transBatchA=0) -> InsertedPrecisionFreeCast_fmm
Add(InsertedPrecisionFreeCast_fmm, InsertedPrecisionFreeCast_B) -> InsertedPrecisionFreeCast_FusedMatMulAdd
Cast(InsertedPrecisionFreeCast_FusedMatMulAdd, saturate=1, to=10) -> FusedMatMulAdd
Cast(B, saturate=1, to=1) -> Bfloat
Cast(A, saturate=1, to=1) -> Afloat
Gemm(Afloat, Xfloat, Bfloat, transA=0, alpha=1.00, beta=1.00, transB=0) -> GemmOnlyfloat
Cast(GemmOnlyfloat, saturate=1, to=10) -> CastGemmOnlyCast
Gemm(Afloat, Xfloat, transA=0, alpha=1.00, beta=1.00, transB=0) -> gmmfloat
Add(gmmfloat, Bfloat) -> gemmaddfloat
Cast(gemmaddfloat, saturate=1, to=10) -> CastGemmAddCast
output: name='GemmOnly' type=dtype('float16') shape=['a', 'c']
output: name='GemmAdd' type=dtype('float16') shape=['a', 'c']
output: name='FusedMatMulAdd' type=dtype('float16') shape=['a', 'c']
output: name='MatMulAdd' type=dtype('float16') shape=['a', 'c']
output: name='CastGemmAddCast' type=dtype('float16') shape=['a', 'c']
output: name='CastGemmOnlyCast' type=dtype('float16') shape=['a', 'c']
It seems some cast were still inserted.
Let’s try with CUDA and float32 if it is available.
A = torch.randn((1280, 1280), dtype=torch.float32)
X = torch.randn((1280, 1280), dtype=torch.float32)
B = torch.randn((1280), dtype=torch.float32)
for itype, dtype, device in [
(onnx.TensorProto.FLOAT16, torch.float16, "cpu"),
(onnx.TensorProto.FLOAT, torch.float32, "cpu"),
(onnx.TensorProto.FLOAT16, torch.float16, "cuda"),
(onnx.TensorProto.FLOAT, torch.float32, "cuda"),
]:
if device == "cuda" and not torch.cuda.is_available():
continue
a = A.to(dtype).to(device)
x = X.to(dtype).to(device)
b = B.to(dtype).to(device)
feeds = dict(A=a, X=x, B=b)
model = make_model_gemm(itype)
sess = OnnxruntimeEvaluator(model, whole=True)
results = sess.run(None, feeds)
diffs = matrix_diff(results)
print(f"------ dtype={dtype}, device={device!r}")
print(diffs)
------ dtype=torch.float16, device='cpu'
[[0. 0.03125 0.03125 0. 0.03125 0. ]
[0.03125 0. 0. 0.03125 0. 0.03125]
[0.03125 0. 0. 0.03125 0. 0.03125]
[0. 0.03125 0.03125 0. 0.03125 0. ]
[0.03125 0. 0. 0.03125 0. 0.03125]
[0. 0.03125 0.03125 0. 0.03125 0. ]]
------ dtype=torch.float32, device='cpu'
[[0.0000000e+00 3.0517578e-05 3.0517578e-05 0.0000000e+00 3.0517578e-05
0.0000000e+00]
[3.0517578e-05 0.0000000e+00 0.0000000e+00 3.0517578e-05 0.0000000e+00
3.0517578e-05]
[3.0517578e-05 0.0000000e+00 0.0000000e+00 3.0517578e-05 0.0000000e+00
3.0517578e-05]
[0.0000000e+00 3.0517578e-05 3.0517578e-05 0.0000000e+00 3.0517578e-05
0.0000000e+00]
[3.0517578e-05 0.0000000e+00 0.0000000e+00 3.0517578e-05 0.0000000e+00
3.0517578e-05]
[0.0000000e+00 3.0517578e-05 3.0517578e-05 0.0000000e+00 3.0517578e-05
0.0000000e+00]]
------ dtype=torch.float16, device='cuda'
[[0. 0.125 0.125 0. 0.125 0.125]
[0.125 0. 0. 0.125 0.125 0.125]
[0.125 0. 0. 0.125 0.125 0.125]
[0. 0.125 0.125 0. 0.125 0.125]
[0.125 0.125 0.125 0.125 0. 0. ]
[0.125 0.125 0.125 0.125 0. 0. ]]
------ dtype=torch.float32, device='cuda'
[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
A weird bias¶
In the previous example, the coefficients of the bias are similar to the others coefficients. What if we make them a lot higher.
A = A / A.max()
X = X / X.max()
B = (torch.arange(1280, dtype=torch.float32) + 1) / 1280 * 16
labels = ["F.linear", *[o.name for o in model.graph.output], "a @ x + b"]
all_results = {}
for itype, dtype, device in [
(onnx.TensorProto.FLOAT, torch.float32, "cpu"),
(onnx.TensorProto.FLOAT16, torch.float16, "cpu"),
# missing implementation in onnxruntime
# (onnx.TensorProto.BFLOAT16, torch.bfloat16, "cpu"),
(onnx.TensorProto.FLOAT, torch.float32, "cuda"),
(onnx.TensorProto.FLOAT16, torch.float16, "cuda"),
(onnx.TensorProto.BFLOAT16, torch.bfloat16, "cuda"),
]:
if device == "cuda" and not torch.cuda.is_available():
continue
a = A.to(dtype).to(device)
x = X.to(dtype).to(device)
b = B.to(dtype).to(device)
feeds = dict(A=a, X=x, B=b)
model = make_model_gemm(itype)
filename = f"plot_gemm_or_matmul.{itype}.{device}.onnx"
sess = OnnxruntimeEvaluator(
model,
whole=True,
graph_optimization_level=GraphOptimizationLevel.ORT_DISABLE_ALL,
optimized_model_filepath=filename,
)
results = [torch.nn.functional.linear(a, x.T, b), *sess.run(None, feeds), a @ x + b]
all_results[device, dtype] = results
has_cast = "Cast" in [n.op_type for n in onnx.load(filename).graph.node]
diffs = matrix_diff(results)
df = pandas.DataFrame(diffs, columns=labels, index=labels)
print(f"------ has_cast={has_cast}, dtype={dtype}, device={device!r}, max(b)={b.max()}")
print(df)
------ has_cast=True, dtype=torch.float32, device='cpu', max(b)=16.0
F.linear GemmOnly GemmAdd FusedMatMulAdd MatMulAdd CastGemmAddCast CastGemmOnlyCast a @ x + b
F.linear 0.000000 0.000008 0.000006 0.000006 0.000006 0.000006 0.000008 0.000006
GemmOnly 0.000008 0.000000 0.000007 0.000007 0.000007 0.000007 0.000000 0.000006
GemmAdd 0.000006 0.000007 0.000000 0.000000 0.000000 0.000000 0.000007 0.000004
FusedMatMulAdd 0.000006 0.000007 0.000000 0.000000 0.000000 0.000000 0.000007 0.000004
MatMulAdd 0.000006 0.000007 0.000000 0.000000 0.000000 0.000000 0.000007 0.000004
CastGemmAddCast 0.000006 0.000007 0.000000 0.000000 0.000000 0.000000 0.000007 0.000004
CastGemmOnlyCast 0.000008 0.000000 0.000007 0.000007 0.000007 0.000007 0.000000 0.000006
a @ x + b 0.000006 0.000006 0.000004 0.000004 0.000004 0.000004 0.000006 0.000000
------ has_cast=True, dtype=torch.float16, device='cpu', max(b)=16.0
F.linear GemmOnly GemmAdd FusedMatMulAdd MatMulAdd CastGemmAddCast CastGemmOnlyCast a @ x + b
F.linear 0.000000 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625
GemmOnly 0.015625 0.000000 0.015625 0.015625 0.015625 0.015625 0.000000 0.015625
GemmAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.000000 0.015625 0.015625
FusedMatMulAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.000000 0.015625 0.015625
MatMulAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.000000 0.015625 0.015625
CastGemmAddCast 0.015625 0.015625 0.000000 0.000000 0.000000 0.000000 0.015625 0.015625
CastGemmOnlyCast 0.015625 0.000000 0.015625 0.015625 0.015625 0.015625 0.000000 0.015625
a @ x + b 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625 0.000000
------ has_cast=True, dtype=torch.float32, device='cuda', max(b)=16.0
F.linear GemmOnly GemmAdd FusedMatMulAdd MatMulAdd CastGemmAddCast CastGemmOnlyCast a @ x + b
F.linear 0.000000 0.002401 0.002401 0.002401 0.002401 0.002401 0.002401 0.000006
GemmOnly 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
GemmAdd 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
FusedMatMulAdd 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
MatMulAdd 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
CastGemmAddCast 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
CastGemmOnlyCast 0.002401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.002401
a @ x + b 0.000006 0.002401 0.002401 0.002401 0.002401 0.002401 0.002401 0.000000
------ has_cast=True, dtype=torch.float16, device='cuda', max(b)=16.0
F.linear GemmOnly GemmAdd FusedMatMulAdd MatMulAdd CastGemmAddCast CastGemmOnlyCast a @ x + b
F.linear 0.000000 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625
GemmOnly 0.015625 0.000000 0.015625 0.015625 0.015625 0.015625 0.015625 0.015625
GemmAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.015625 0.015625 0.000000
FusedMatMulAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.015625 0.015625 0.000000
MatMulAdd 0.015625 0.015625 0.000000 0.000000 0.000000 0.015625 0.015625 0.000000
CastGemmAddCast 0.015625 0.015625 0.015625 0.015625 0.015625 0.000000 0.000000 0.015625
CastGemmOnlyCast 0.015625 0.015625 0.015625 0.015625 0.015625 0.000000 0.000000 0.015625
a @ x + b 0.015625 0.015625 0.000000 0.000000 0.000000 0.015625 0.015625 0.000000
------ has_cast=True, dtype=torch.bfloat16, device='cuda', max(b)=16.0
F.linear GemmOnly GemmAdd FusedMatMulAdd MatMulAdd CastGemmAddCast CastGemmOnlyCast a @ x + b
F.linear 0.000 0.125 0.125 0.125 0.125 0.125 0.125 0.125
GemmOnly 0.125 0.000 0.125 0.125 0.125 0.125 0.125 0.125
GemmAdd 0.125 0.125 0.000 0.000 0.000 0.125 0.125 0.000
FusedMatMulAdd 0.125 0.125 0.000 0.000 0.000 0.125 0.125 0.000
MatMulAdd 0.125 0.125 0.000 0.000 0.000 0.125 0.125 0.000
CastGemmAddCast 0.125 0.125 0.125 0.125 0.125 0.000 0.000 0.125
CastGemmOnlyCast 0.125 0.125 0.125 0.125 0.125 0.000 0.000 0.125
a @ x + b 0.125 0.125 0.000 0.000 0.000 0.125 0.125 0.000
Cast is inserted on CPU because some kernel are not available for float16. Even though, we can see huge discrepancies happening.
bias value vs discrepancies¶
Let’s compare torch linear with GemmOnly.
def make_figure_axis(all_results, i, j):
labs = labels[i], labels[j]
fig, ax = plt.subplots(len(all_results), 2, figsize=(12, 4 * len(all_results)))
for pos, ((device, dtype), results) in enumerate(all_results.items()):
m1, m2 = results[i], results[j]
diff = torch.abs(m1.to(torch.float32) - m2.to(torch.float32)).max(dim=0)[0]
print(f"labels={labs}, {device}/{dtype}: max(diff)={diff.max()}")
expand = 0.5 if diff.max() >= 1 else diff.max().detach().cpu() / 2
ax[pos, 0].plot(
B.tolist(), (diff.detach().cpu() + torch.rand(1280) * expand).tolist(), "."
)
ax[pos, 0].set_title(f"{labs[0]}-{labs[1]} {device}/{dtype}", fontsize=10)
corr = matrix_diff(results)
ax[pos, 1].imshow(corr, cmap="Wistia", vmin=0, vmax=corr.max())
# ax[pos,1].colorbar(label=f'Discrepancies {device}/{dtype}')
ax[pos, 1].set_xticks(range(len(labels)), labels, rotation=45, ha="right", fontsize=10)
ax[pos, 1].set_yticks(range(len(labels)), labels, fontsize=10)
ax[pos, 1].set_title(f"max={diff.max():1.2g}", fontsize=10)
for _i in range(corr.shape[0]):
for _j in range(corr.shape[1]):
ax[pos, 1].text(
_j,
_i,
f"{corr[_i, _j]:1.1g}",
ha="center",
va="center",
color="black",
fontsize=8,
)
fig.suptitle(
f"Left column: discrepancies {labs[0]} VS {labs[1]}\n"
f"Right column: max absolute error, across all configuration\n"
f"white is good, orange is not"
)
return fig, ax
fig, ax = make_figure_axis(all_results, 0, 1)
fig.tight_layout()
fig.savefig("plot_gemm_or_matmul_add1.png")
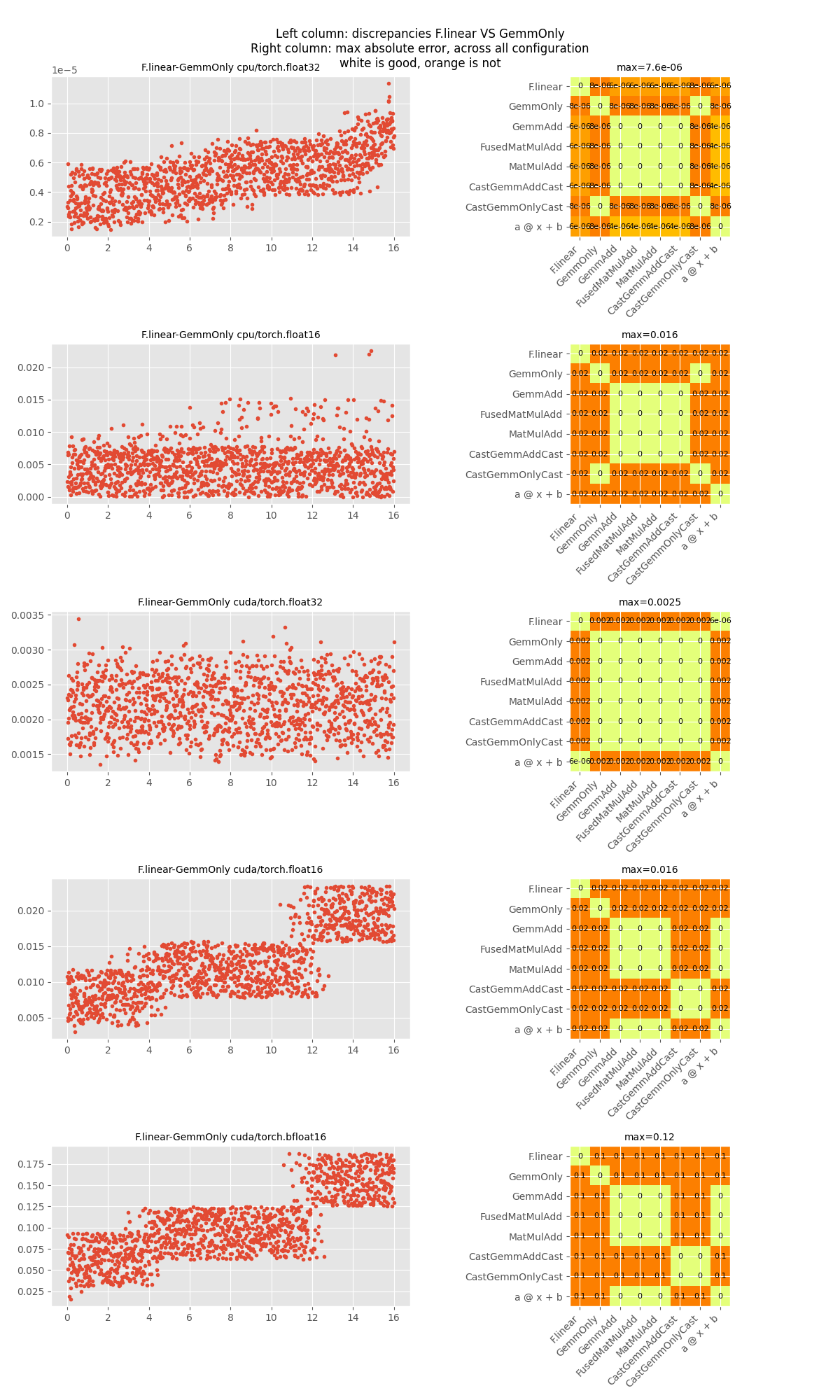
labels=('F.linear', 'GemmOnly'), cpu/torch.float32: max(diff)=7.62939453125e-06
labels=('F.linear', 'GemmOnly'), cpu/torch.float16: max(diff)=0.015625
labels=('F.linear', 'GemmOnly'), cuda/torch.float32: max(diff)=0.002401113510131836
labels=('F.linear', 'GemmOnly'), cuda/torch.float16: max(diff)=0.015625
labels=('F.linear', 'GemmOnly'), cuda/torch.bfloat16: max(diff)=0.125
Let’s compare with A @ X + B.
fig, ax = make_figure_axis(all_results, -1, 1)
fig.tight_layout()
fig.savefig("plot_gemm_or_matmul_add2.png")
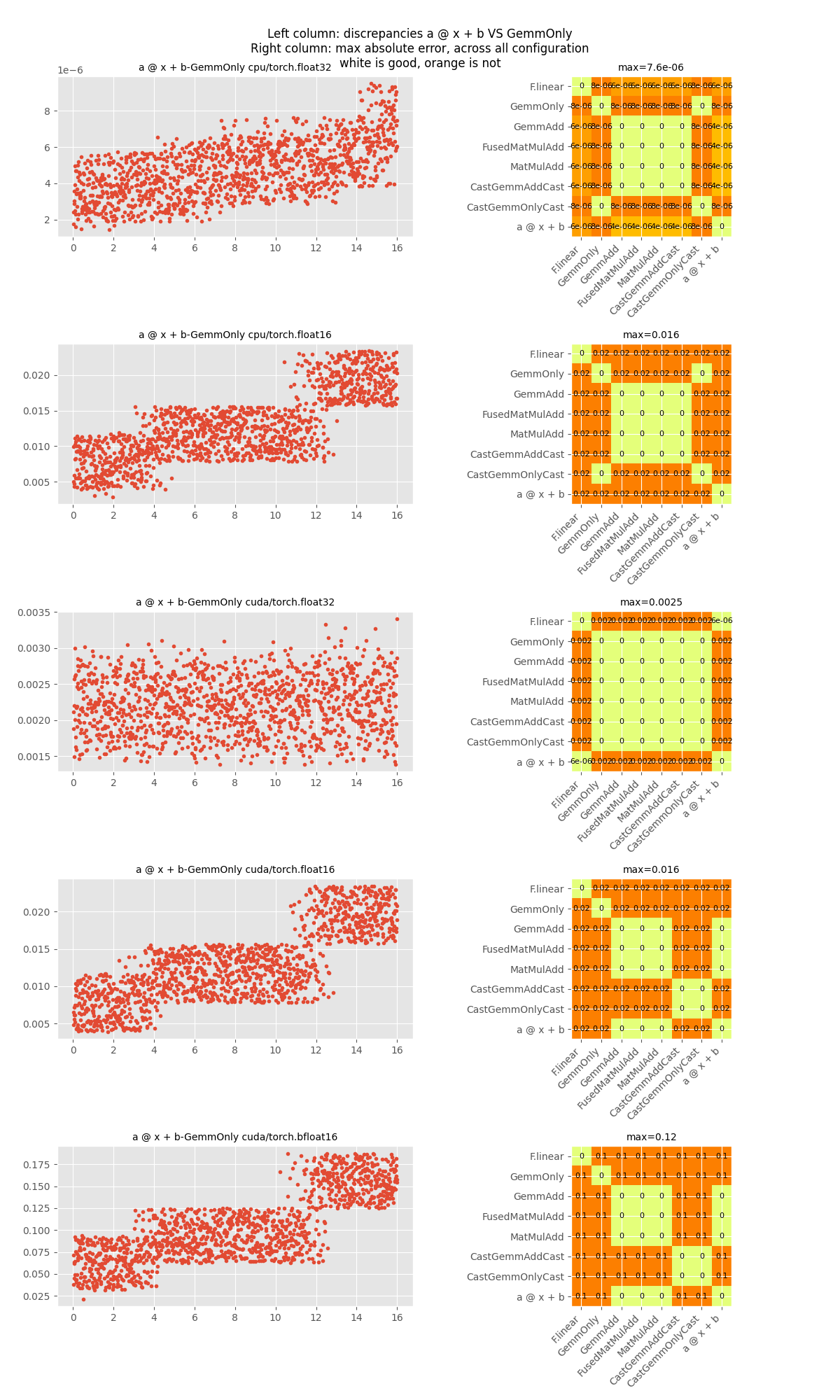
labels=('a @ x + b', 'GemmOnly'), cpu/torch.float32: max(diff)=5.7220458984375e-06
labels=('a @ x + b', 'GemmOnly'), cpu/torch.float16: max(diff)=0.015625
labels=('a @ x + b', 'GemmOnly'), cuda/torch.float32: max(diff)=0.0024013519287109375
labels=('a @ x + b', 'GemmOnly'), cuda/torch.float16: max(diff)=0.015625
labels=('a @ x + b', 'GemmOnly'), cuda/torch.bfloat16: max(diff)=0.125
Discrepancies do not happen all the time but it is very likely to happen. The use of Gemm with a bias not null should be used when torch is doing the same and it seems to depend on the type as well. The difference is even higher for bfloat16.
Total running time of the script: (0 minutes 20.267 seconds)
Related examples
LayerNormalization implementation cannot be exchanged