onnx_diagnostic.helpers.rt_helper¶
- onnx_diagnostic.helpers.rt_helper.generate_and_validate(model, input_ids: Tensor, eos_token_id: int = 2, max_new_tokens: int = 100, session: InferenceSessionForTorch | ModelProto | str | None = None, atol: float = 0.1) Tensor | Tuple[Tensor, List[Dict]][source][source]¶
Implements a simple method
generatefor a torch model. The function does not expect anyposition_idsas input. The function also checks the outputs coming from an onnx model are close to the output the torch model produces.- Parameters:
model_or_path – model or loaded model
input_ids – input tokens
eos_token_ids – token representing the end of an answer
max_new_tokens – stops after this number of generated tokens
session – the onnx model
- Returns:
input tokens concatenated with new tokens, if session is not null, it also returns the maximum differences at every iterations
See example given with function
onnx_generate.
- onnx_diagnostic.helpers.rt_helper.js_profile_to_dataframe(filename: str, as_df: bool = True, first_it_out: bool = False, agg: bool = False, agg_op_name: bool = False, with_shape: bool = False) List | pandas.DataFrame[source][source]¶
Profiles the execution of an onnx graph with onnxruntime.
- Parameters:
filename – filename holding the profiling stored in json format
as_df – returns the
first_it_out – if aggregated, leaves the first iteration out
agg – aggregate by event
agg_op_name – aggregate on operator name or operator index
with_shape – keep the shape before aggregating
- Returns:
DataFrame or dictionary
- onnx_diagnostic.helpers.rt_helper.make_empty_cache(batch: int, onnx_input_names: List[str], onnx_input_shapes: List[Tuple[int | str, ...]], onnx_input_types: List[str]) Dict[str, Tensor][source][source]¶
Creates an empty cache. Example:
make_empty_cache( 1, sess.input_names[2:], [i.shape for i in sess.get_inputs()[2:]], [i.type for i in sess.get_inputs()[2:]], )
- onnx_diagnostic.helpers.rt_helper.make_feeds(proto: ModelProto | List[str], inputs: Any, use_numpy: bool = False, copy: bool = False, check_flatten: bool = True, is_modelbuilder: bool = False) Dict[str, ndarray | Tensor][source][source]¶
Serializes the inputs to produce feeds expected by
onnxruntime.InferenceSession.- Parameters:
proto – onnx model or list of names
inputs – any kind of inputs
use_numpy – if True, converts torch tensors into numpy arrays
copy – a copy is made, this should be the case if the inputs is ingested by
OrtValuecheck_flatten – if True, checks the
torch.utils._pytree.tree_flattenreturns the same number of outputsis_modelbuilder – if True, the exporter is ModelBuilder, and we need to reorder the past_key_values inputs to match the expected order, and get rid of position_ids.
- Returns:
feeds dictionary
- onnx_diagnostic.helpers.rt_helper.onnx_generate(model_or_path: ModelProto | str | InferenceSessionForTorch, input_ids: Tensor, attention_mask: Tensor | None = None, eos_token_id: int = 2, max_new_tokens=100, return_session: bool = False) Tensor | Tuple[Tensor, InferenceSessionForTorch, Dict[str, Any]][source][source]¶
Implements a simple method
generatefor an ONNX model. The function does not expect anyposition_idsas input.- Parameters:
model_or_path – model or loaded model
input_ids – input tokens
eos_token_ids – token representing the end of an answer
max_new_tokens – stops after this number of generated tokens
return_session – returns the instance of class
InferenceSessionForTorchcreated if necessary, the function returns the feeds for the next iteration
- Returns:
input tokens concatenated with new tokens
<<<
import os from onnx_diagnostic.helpers import string_type, string_diff from onnx_diagnostic.helpers.rt_helper import ( onnx_generate, generate_and_validate, onnx_generate_with_genai, ) from onnx_diagnostic.torch_models.hghub import get_untrained_model_with_inputs from onnx_diagnostic.torch_export_patches import torch_export_patches from onnx_diagnostic.export.api import to_onnx mid = "arnir0/Tiny-LLM" print(f"-- get model for {mid!r}") data = get_untrained_model_with_inputs(mid) model, inputs, ds = data["model"], data["inputs"], data["dynamic_shapes"] del inputs["position_ids"] del ds["position_ids"] input_ids = inputs["input_ids"] print(f"-- input_ids={input_ids.shape}") print(f"-- inputs: {string_type(inputs, with_shape=True)}") print(f"-- dynamic_shapes: {string_type(ds)}") folder = "dump_test" os.makedirs(folder, exist_ok=True) model_name = os.path.join(folder, "model.onnx") print("-- test_onnx_generate: export model") with torch_export_patches(patch_transformers=True, patch_torch=False): to_onnx( model, (), kwargs=inputs, dynamic_shapes=ds, filename=model_name, exporter="custom", # custom, dynamo or onnx-dynamo, modelbuilder ) print("-- generate with onnx") onnx_outputs = onnx_generate( model_name, input_ids[:1], eos_token_id=2, max_new_tokens=10 ) print("-- onnx output", onnx_outputs) # The example continues with other functions doing the same. print("-- generate with pytorch") torch_outputs, diffs = generate_and_validate( model, input_ids[:1], 2, max_new_tokens=10, session=model_name ) print("-- torch output", torch_outputs) print("-- differences at each step:") for i, d in enumerate(diffs): print(f"iteration {i}: {string_diff(d)}") print("-- generate with genai") genai_outputs, session = onnx_generate_with_genai( model_name, input_ids[:1], max_new_tokens=10, return_session=True, transformers_config=data["configuration"], ) print("-- genai output", genai_outputs)
>>>
-- get model for 'arnir0/Tiny-LLM' -- input_ids=torch.Size([2, 3]) -- inputs: dict(input_ids:T7s2x3,attention_mask:T7s2x33,past_key_values:DynamicCache(key_cache=#1[T1s2x1x30x96], value_cache=#1[T1s2x1x30x96])) -- dynamic_shapes: dict(input_ids:{0:DYN(batch),1:DYN(seq_length)},attention_mask:{0:DYN(batch),1:DYN(cache+seq)},past_key_values:#2[{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)}]) -- test_onnx_generate: export model -- generate with onnx -- onnx output tensor([[15400, 9965, 29562, 24320, 18225, 4356, 9955, 5702, 13376, 17956, 8767, 21037, 22315]]) -- generate with pytorch -- torch output tensor([[15400, 9965, 29562, 24320, 18225, 4356, 9955, 5702, 13376, 17956, 8767, 21037, 22315]]) -- differences at each step: iteration 0: abs=8.940696716308594e-07, rel=0.0003605732941909325, n=96576.0, dev=0 iteration 1: abs=9.5367431640625e-07, rel=0.00027689513796803845, n=32768.0, dev=0 iteration 2: abs=7.748603820800781e-07, rel=0.00025357956033603726, n=32960.0, dev=0 iteration 3: abs=8.940696716308594e-07, rel=0.0003577691346020538, n=33152.0, dev=0 iteration 4: abs=7.748603820800781e-07, rel=0.00018935395457387303, n=33344.0, dev=0 iteration 5: abs=9.5367431640625e-07, rel=0.00034529287730084197, n=33536.0, dev=0 iteration 6: abs=8.046627044677734e-07, rel=0.0005035887827749254, n=33728.0, dev=0 iteration 7: abs=8.344650268554688e-07, rel=0.00021370744815346596, n=33920.0, dev=0 iteration 8: abs=8.344650268554688e-07, rel=0.00028363345965622117, n=34112.0, dev=0 iteration 9: abs=7.152557373046875e-07, rel=0.00032590925662840357, n=34304.0, dev=0 iteration 10: abs=7.152557373046875e-07, rel=0.00019224814221635795, n=34496.0, dev=0 -- generate with genai -- genai output tensor([[15400, 9965, 29562, 24320, 18225, 4356, 9955, 5702, 13376, 17956, 8767, 21037, 22315]])
- onnx_diagnostic.helpers.rt_helper.onnx_generate_with_genai(model_or_path: ModelProto | str | InferenceSessionForTorch, input_ids: Tensor, max_new_tokens=100, return_session: bool = False, transformers_config: Any | None = None) Tensor | Tuple[Tensor, InferenceSessionForTorch][source][source]¶
Uses onnxruntime-genai to implement a simple method
generatefor an ONNX model. The function does not expect anyposition_idsas input.- Parameters:
model_or_path – model or loaded model
input_ids – input tokens
eos_token_ids – token representing the end of an answer
max_new_tokens – stops after this number of generated tokens
return_session – returns the instance of class
InferenceSessionForTorchcreated if necessarytransformers_config – write configuration if missing and if this configuration is provided
- Returns:
input tokens concatenated with new tokens
See example given with function
onnx_generate.
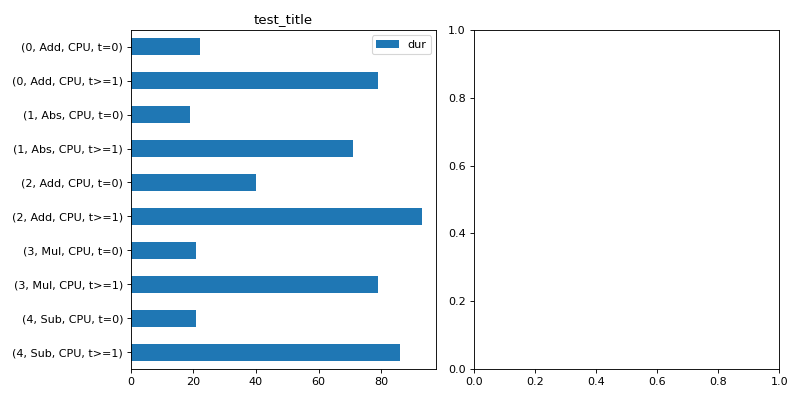
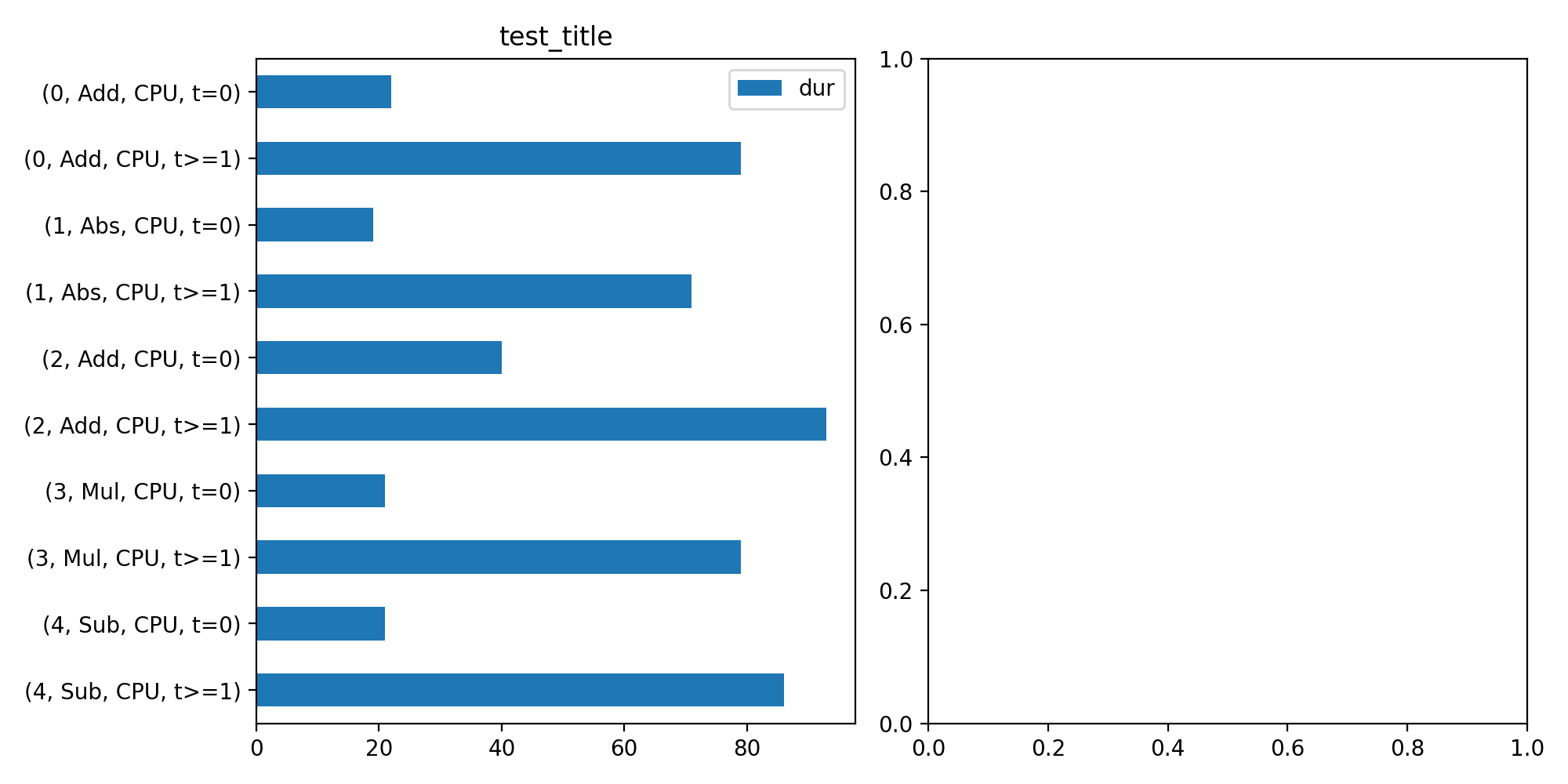
- onnx_diagnostic.helpers.rt_helper.plot_ort_profile(df: pandas.DataFrame, ax0: matplotlib.axes.Axes | None = None, ax1: matplotlib.axes.Axes | None = None, title: str | None = None) matplotlib.axes.Axes[source][source]¶
Plots time spend in computation based on a dataframe produced by function
js_profile_to_dataframe().- Parameters:
df – dataframe
ax0 – first axis to draw time
ax1 – second axis to draw occurrences
title – graph title
- Returns:
the graph
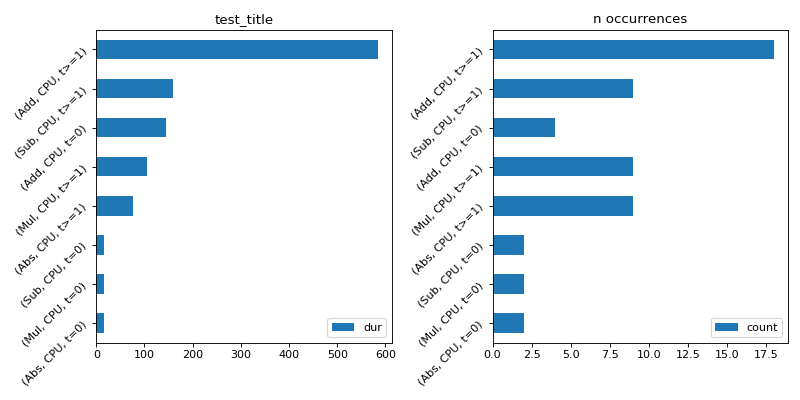
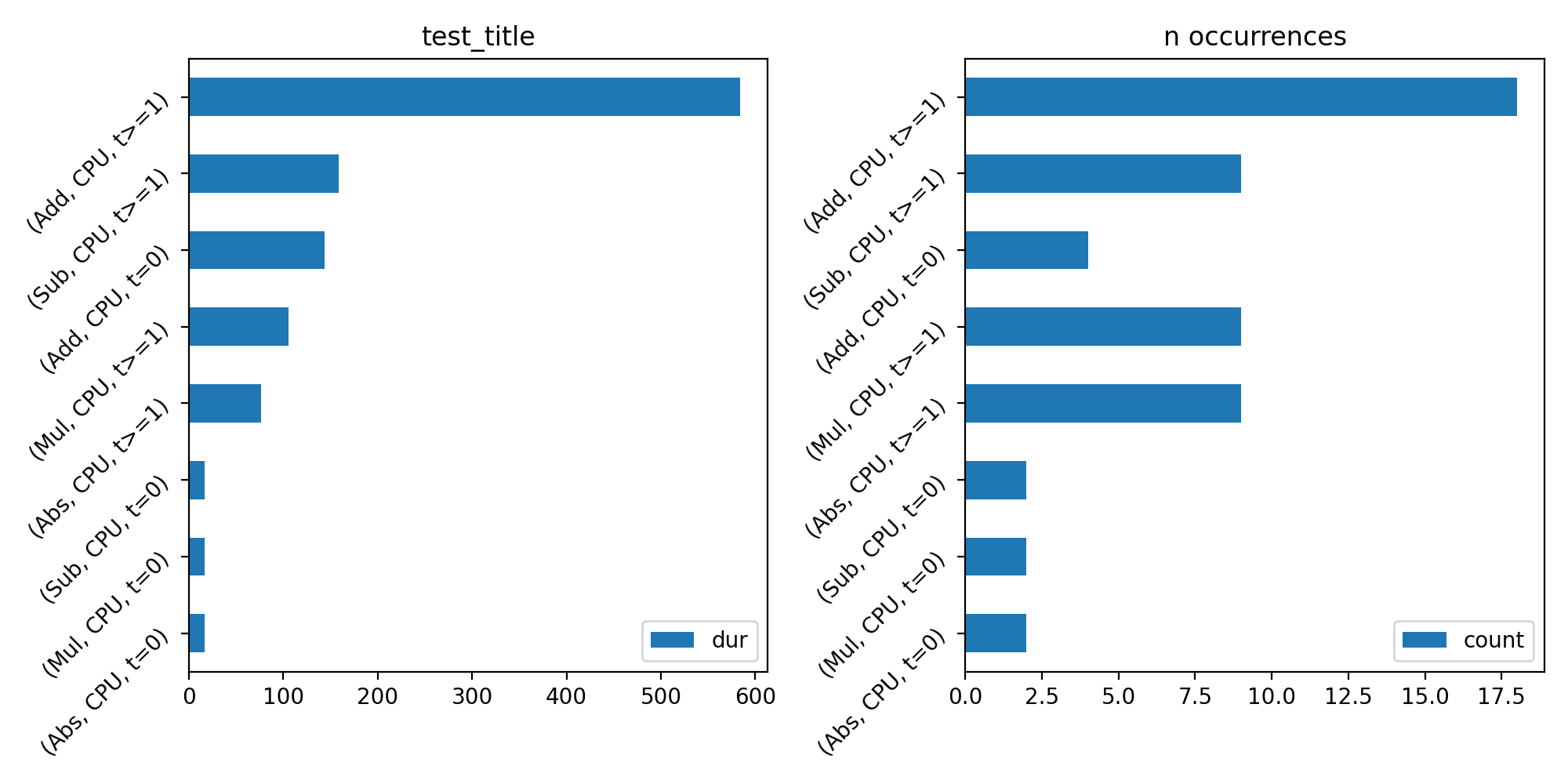
import numpy as np from onnx import TensorProto import onnx.helper as oh from onnx.checker import check_model from onnx.numpy_helper import from_array import matplotlib.pyplot as plt from onnxruntime import InferenceSession, SessionOptions from onnx_diagnostic.helpers.rt_helper import js_profile_to_dataframe, plot_ort_profile def get_model(): model_def0 = oh.make_model( oh.make_graph( [ oh.make_node("Add", ["X", "init1"], ["X1"]), oh.make_node("Abs", ["X"], ["X2"]), oh.make_node("Add", ["X", "init3"], ["inter"]), oh.make_node("Mul", ["X1", "inter"], ["Xm"]), oh.make_node("Sub", ["X2", "Xm"], ["final"]), ], "test", [oh.make_tensor_value_info("X", TensorProto.FLOAT, [None])], [oh.make_tensor_value_info("final", TensorProto.FLOAT, [None])], [ from_array(np.array([1], dtype=np.float32), name="init1"), from_array(np.array([3], dtype=np.float32), name="init3"), ], ), opset_imports=[oh.make_opsetid("", 18)], ir_version=9, ) check_model(model_def0) return model_def0 sess_options = SessionOptions() sess_options.enable_profiling = True sess = InferenceSession( get_model().SerializeToString(), sess_options, providers=["CPUExecutionProvider"] ) for _ in range(11): sess.run(None, dict(X=np.arange(10).astype(np.float32))) prof = sess.end_profiling() df = js_profile_to_dataframe(prof, first_it_out=True) print(df.head()) fig, ax = plt.subplots(1, 2, figsize=(10, 5)) plot_ort_profile(df, ax[0], ax[1], "test_title") fig.tight_layout()
(
Source code,png,hires.png,pdf)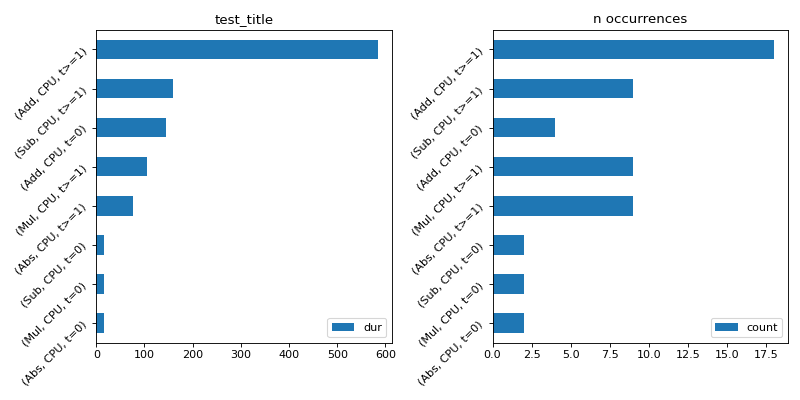
With
agg=True:import numpy as np from onnx import TensorProto import onnx.helper as oh from onnx.checker import check_model from onnx.numpy_helper import from_array import matplotlib.pyplot as plt from onnxruntime import InferenceSession, SessionOptions from onnx_diagnostic.helpers.rt_helper import js_profile_to_dataframe, plot_ort_profile def get_model(): model_def0 = oh.make_model( oh.make_graph( [ oh.make_node("Add", ["X", "init1"], ["X1"]), oh.make_node("Abs", ["X"], ["X2"]), oh.make_node("Add", ["X", "init3"], ["inter"]), oh.make_node("Mul", ["X1", "inter"], ["Xm"]), oh.make_node("Sub", ["X2", "Xm"], ["final"]), ], "test", [oh.make_tensor_value_info("X", TensorProto.FLOAT, [None])], [oh.make_tensor_value_info("final", TensorProto.FLOAT, [None])], [ from_array(np.array([1], dtype=np.float32), name="init1"), from_array(np.array([3], dtype=np.float32), name="init3"), ], ), opset_imports=[oh.make_opsetid("", 18)], ir_version=9, ) check_model(model_def0) return model_def0 sess_options = SessionOptions() sess_options.enable_profiling = True sess = InferenceSession( get_model().SerializeToString(), sess_options, providers=["CPUExecutionProvider"] ) for _ in range(11): sess.run(None, dict(X=np.arange(10).astype(np.float32))) prof = sess.end_profiling() df = js_profile_to_dataframe(prof, first_it_out=True, agg=True) print(df.head()) fig, ax = plt.subplots(1, 2, figsize=(10, 5)) plot_ort_profile(df, ax[0], ax[1], "test_title") fig.tight_layout()
(
Source code,png,hires.png,pdf)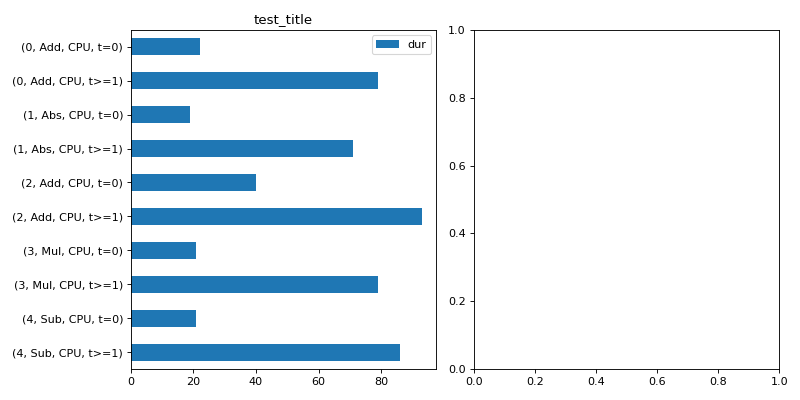
{kind=link}
{kind=link}
{kind=link}
{kind=link}
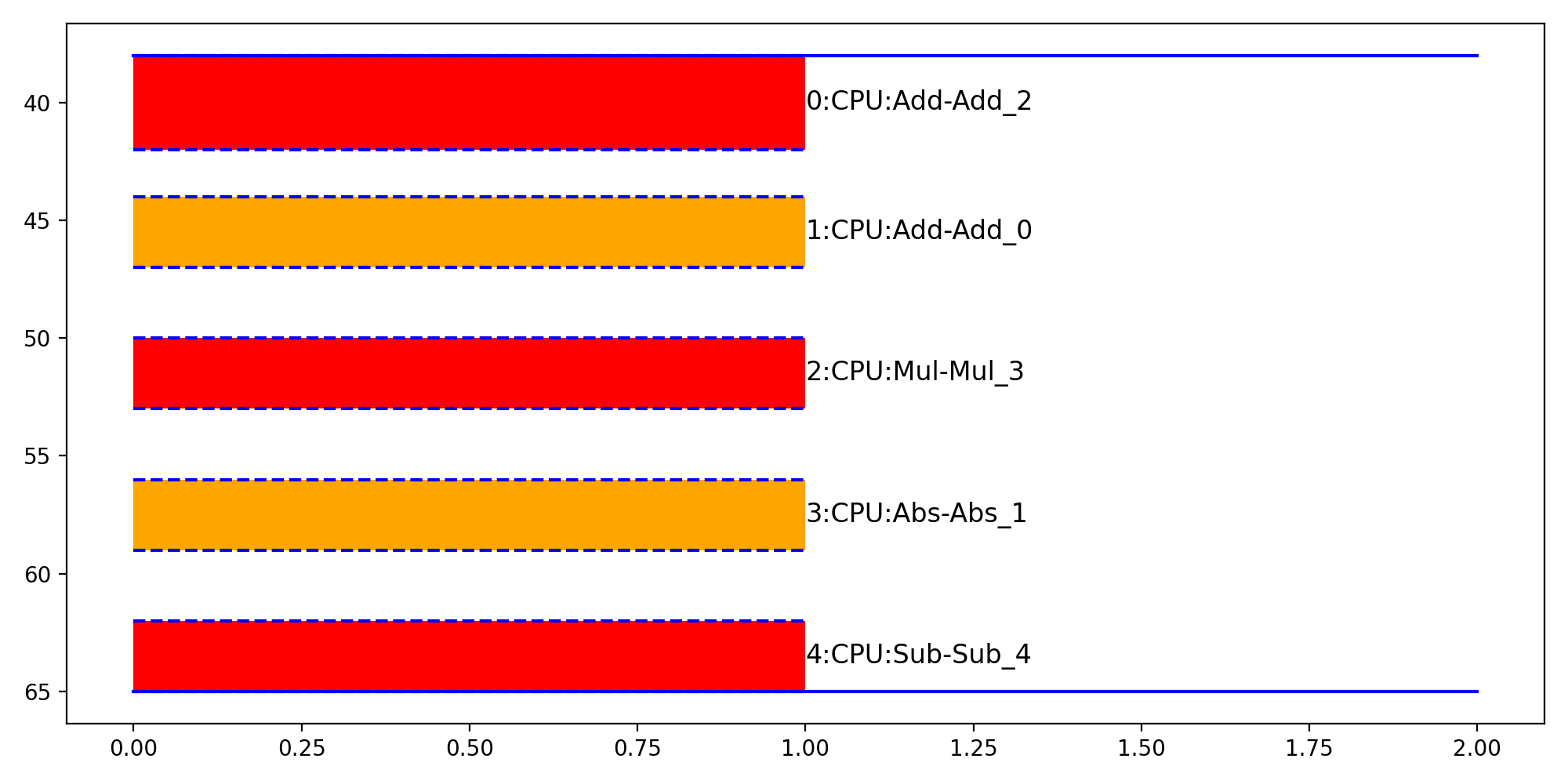
- onnx_diagnostic.helpers.rt_helper.plot_ort_profile_timeline(df: pandas.DataFrame, ax: matplotlib.axes.Axes | None = None, iteration: int = -2, title: str | None = None, quantile: float = 0.5, fontsize: int = 12) matplotlib.axes.Axes[source][source]¶
Creates a timeline based on a dataframe produced by function
js_profile_to_dataframe().- Parameters:
df – dataframe
ax – first axis to draw time
iteration – iteration to plot, negative value to start from the end
title – graph title
quantile – draw the 10% less consuming operators in a different color
fontsize – font size
- Returns:
the graph
import numpy as np from onnx import TensorProto import onnx.helper as oh from onnx.checker import check_model from onnx.numpy_helper import from_array import matplotlib.pyplot as plt from onnxruntime import InferenceSession, SessionOptions from onnx_diagnostic.helpers.rt_helper import ( js_profile_to_dataframe, plot_ort_profile_timeline, ) def get_model(): model_def0 = oh.make_model( oh.make_graph( [ oh.make_node("Add", ["X", "init1"], ["X1"]), oh.make_node("Abs", ["X"], ["X2"]), oh.make_node("Add", ["X", "init3"], ["inter"]), oh.make_node("Mul", ["X1", "inter"], ["Xm"]), oh.make_node("Sub", ["X2", "Xm"], ["final"]), ], "test", [oh.make_tensor_value_info("X", TensorProto.FLOAT, [None])], [oh.make_tensor_value_info("final", TensorProto.FLOAT, [None])], [ from_array(np.array([1], dtype=np.float32), name="init1"), from_array(np.array([3], dtype=np.float32), name="init3"), ], ), opset_imports=[oh.make_opsetid("", 18)], ir_version=9, ) check_model(model_def0) return model_def0 sess_options = SessionOptions() sess_options.enable_profiling = True sess = InferenceSession( get_model().SerializeToString(), sess_options, providers=["CPUExecutionProvider"] ) for _ in range(11): sess.run(None, dict(X=np.arange(10).astype(np.float32))) prof = sess.end_profiling() df = js_profile_to_dataframe(prof, first_it_out=True) print(df.head()) fig, ax = plt.subplots(1, 1, figsize=(10, 5)) plot_ort_profile_timeline(df, ax, title="test_timeline", quantile=0.5) fig.tight_layout()
(
Source code,png,hires.png,pdf)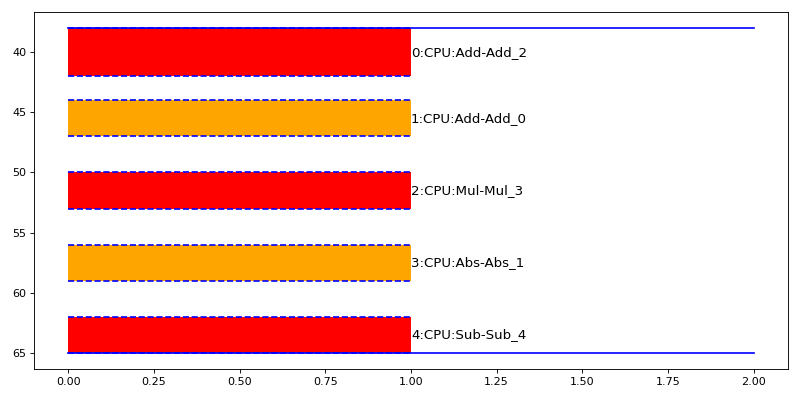
{kind=link}
{kind=link}
- onnx_diagnostic.helpers.rt_helper.post_process_df_profile(df: pandas.DataFrame, first_it_out: bool = False, agg: bool = False, agg_op_name: bool = True, with_shape: bool = False) pandas.DataFrame[source][source]¶
Post-processed a dataframe obtained after profiling onnxruntime. It adds a column for a more explicit event name and adds a column for the iteration number
- Parameters:
agg – aggregate the result
first_it_out – leave the first iteration out of the aggregation
agg_op_name – aggregate on operator name or operator index
with_shape – keep the shape to aggregate
- Returns:
DataFrame