Note
Go to the end to download the full example code.
LayerNormalization implementation cannot be exchanged¶
This example applies what was illustrated Reproducible Parallelized Reduction is difficult, reduction operations are sensitive to parallelization.
Methodology¶
We consider a simple model with a LayerNormalization followed by a MatMul. Each operator can be run with onnxruntime or pytorch. We compare the four combinations.
The model¶
import itertools
import numpy as np
import pandas
import onnx
import onnx.helper as oh
import onnxruntime
import torch
from onnx_diagnostic.doc import rotate_align, save_fig, plot_histogram, title, plot_dot
from onnx_diagnostic.ext_test_case import unit_test_going
from onnx_diagnostic.helpers import max_diff, string_diff, string_type
from onnx_diagnostic.helpers.onnx_helper import onnx_dtype_name, onnx_dtype_to_np_dtype
from onnx_diagnostic.helpers.torch_helper import onnx_dtype_to_torch_dtype
from onnx_diagnostic.helpers.doc_helper import LayerNormalizationOrt, MatMulOrt
from onnx_diagnostic.reference import TorchOnnxEvaluator
TFLOAT = onnx.TensorProto.FLOAT
TFLOAT16 = onnx.TensorProto.FLOAT16
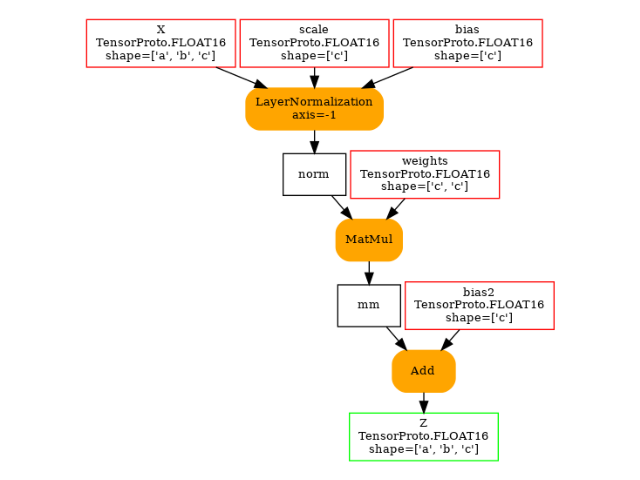
def get_model(itype: int = TFLOAT16):
return oh.make_model(
oh.make_graph(
[
oh.make_node("LayerNormalization", ["X", "scale", "bias"], ["norm"], axis=-1),
oh.make_node("MatMul", ["norm", "weights"], ["mm"]),
oh.make_node("Add", ["mm", "bias2"], ["Z"]),
],
"layer_norm_matmul_add",
[
oh.make_tensor_value_info("X", itype, ["a", "b", "c"]),
oh.make_tensor_value_info("scale", itype, ["c"]),
oh.make_tensor_value_info("bias", itype, ["c"]),
oh.make_tensor_value_info("weights", itype, ["c", "c"]),
oh.make_tensor_value_info("bias2", itype, ["c"]),
],
[oh.make_tensor_value_info("Z", itype, ["a", "b", "c"])],
),
ir_version=9,
opset_imports=[oh.make_opsetid("", 18)],
)
model = get_model()
plot_dot(model)
Let’s compare two runtimes¶
That will be onnxruntime and
onnx_diagnostic.reference.TorchOnnxEvaluator.
last_dim = 64 if unit_test_going() else 1152
def make_feeds(last_dim: int):
return {
"X": (torch.rand((32, 1024, last_dim), dtype=torch.float16) - 0.5) * 120,
"scale": torch.rand((last_dim,), dtype=torch.float16),
"bias": torch.rand((last_dim,), dtype=torch.float16),
"weights": torch.rand((last_dim, last_dim), dtype=torch.float16),
"bias2": torch.rand((last_dim,), dtype=torch.float16),
}
def cast_feeds(itype, provider, feeds):
ttype = onnx_dtype_to_torch_dtype(itype)
np_dtype = onnx_dtype_to_np_dtype(itype)
np_feeds = {k: v.detach().numpy() for k, v in feeds.items()}
if provider == "CUDA":
if not torch.cuda.is_available():
return None, None
tch_feeds = {k: v.to("cuda") for k, v in feeds.items()}
ort_feeds = np_feeds
else:
tch_feeds = feeds.copy()
tch_feeds["X"] = tch_feeds["X"][:2] # too long otherwise
ort_feeds = np_feeds.copy()
ort_feeds["X"] = ort_feeds["X"][:2]
tch_feeds = {k: v.to(ttype) for k, v in tch_feeds.items()}
ort_feeds = {k: v.astype(np_dtype) for k, v in ort_feeds.items()}
return tch_feeds, ort_feeds
feeds = make_feeds(last_dim)
kws = dict(with_shape=True, with_min_max=True, with_device=True)
data = []
baseline = {}
for provider, itype in itertools.product(["CPU", "CUDA"], [TFLOAT, TFLOAT16]):
tch_feeds, ort_feeds = cast_feeds(itype, provider, feeds)
if tch_feeds is None:
continue
model = get_model(itype)
print()
print(f"-- running on {provider} with {onnx_dtype_name(itype)}")
print("-- running with torch")
torch_sess = TorchOnnxEvaluator(model, providers=[f"{provider}ExecutionProvider"])
expected = torch_sess.run(None, tch_feeds)
baseline[itype, provider, "torch"] = expected
print(f"-- torch: {string_type(expected, **kws)}")
print("-- running with ort")
ort_sess = onnxruntime.InferenceSession(
model.SerializeToString(), providers=[f"{provider}ExecutionProvider"]
)
got = ort_sess.run(None, ort_feeds)
baseline[itype, provider, "ort"] = got
print(f"-- ort: {string_type(got, **kws)}")
diff = max_diff(expected, got, hist=True)
print(f"-- diff {string_diff(diff)}")
# memorize the data
diff["dtype"] = onnx_dtype_name(itype)
diff["provider"] = provider
diff.update(diff["rep"])
del diff["rep"]
del diff["dnan"]
del diff[">100.0"]
del diff[">10.0"]
data.append(diff)
-- running on CPU with FLOAT
-- running with torch
-- torch: #1[CT1s2x1024x1152[240.5792236328125,334.54425048828125:A287.8474769835852]]
-- running with ort
-- ort: #1[A1s2x1024x1152[240.57925415039062,334.54425048828125:A287.84747691659464]]
-- diff abs=0.000152587890625, rel=5.781645673859666e-07, n=2359296.0/#1489953>0.0-#2319>0.0001, dev=0
-- running on CPU with FLOAT16
-- running with torch
-- torch: #1[CT10s2x1024x1152[240.625,334.75:A287.8463393847148]]
-- running with ort
-- ort: #1[A10s2x1024x1152[240.625,334.5:A287.8474526935154]]
-- diff abs=0.25, rel=0.0009765586853176355, n=2359296.0/#581974>0.0-#581974>0.0001-#581974>0.001-#581974>0.01-#581974>0.1, dev=0
-- running on CUDA with FLOAT
-- running with torch
-- torch: #1[GT1s32x1024x1152[236.8856964111328,343.1820068359375:A287.7799132295177]]
-- running with ort
-- ort: #1[A1s32x1024x1152[236.87997436523438,343.17724609375:A287.7772252789]]
-- diff abs=0.019378662109375, rel=6.64516856253671e-05, n=37748736.0/#37648526>0.0-#37045065>0.0001-#31240521>0.001-#526480>0.01, dev=1
-- running on CUDA with FLOAT16
-- running with torch
-- torch: #1[GT10s32x1024x1152[236.875,343.25:A287.776573277182]]
-- running with ort
-- ort: #1[A10s32x1024x1152[236.875,343.25:A287.7765724360943]]
-- diff abs=0.5, rel=0.001792108272013362, n=37748736.0/#1645>0.0-#1645>0.0001-#1645>0.001-#1645>0.01-#1645>0.1, dev=1
df = pandas.DataFrame(data).set_index(["provider", "dtype"])
print(df)
abs rel sum n dev >0.0 >0.0001 >0.001 >0.01 >0.1 >1.0
provider dtype
CPU FLOAT 0.000153 5.781646e-07 58.152710 2359296.0 0 1489953 2319 0 0 0 0
FLOAT16 0.250000 9.765587e-04 145475.125000 2359296.0 0 581974 581974 581974 581974 581974 0
CUDA FLOAT 0.019379 6.645169e-05 130695.717133 37748736.0 1 37648526 37045065 31240521 526480 0 0
FLOAT16 0.500000 1.792108e-03 411.750000 37748736.0 1 1645 1645 1645 1645 1645 0
Visually.
save_fig(
rotate_align(
df[["abs"]].plot.bar(title="Discrepancies ORT / torch for LayerNorm(X) @ W + B")
),
"plot_layer_norm_discrepancies_1.png",
)
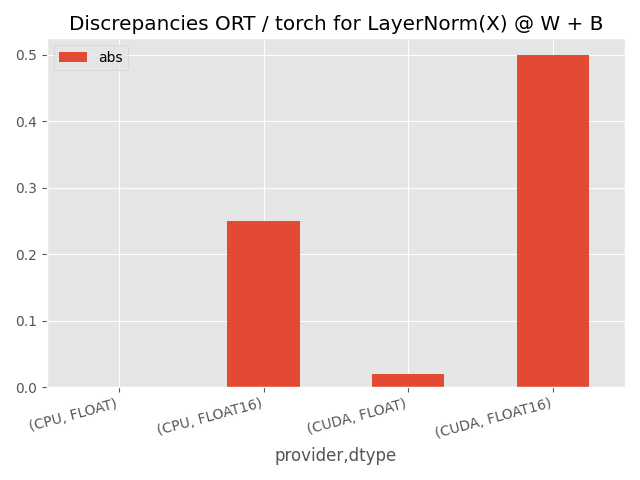
The discrepancies are significant on CUDA, higher for float16. Let’s see which operator is responsible for them, LayerNormalization or MatMul.
Distribution of the results¶
tensor = baseline[TFLOAT16, "CPU", "ort"][0].ravel().astype(np.float32)
print(pandas.DataFrame({"expected": tensor}).describe())
expected
count 2.359296e+06
mean 2.878474e+02
std 9.436957e+00
min 2.406250e+02
25% 2.815000e+02
50% 2.877500e+02
75% 2.942500e+02
max 3.345000e+02
Histogram.
save_fig(
title(plot_histogram(tensor), "Distribution of the computed results"),
"plot_layer_norm_discrepancies_hist.png",
)
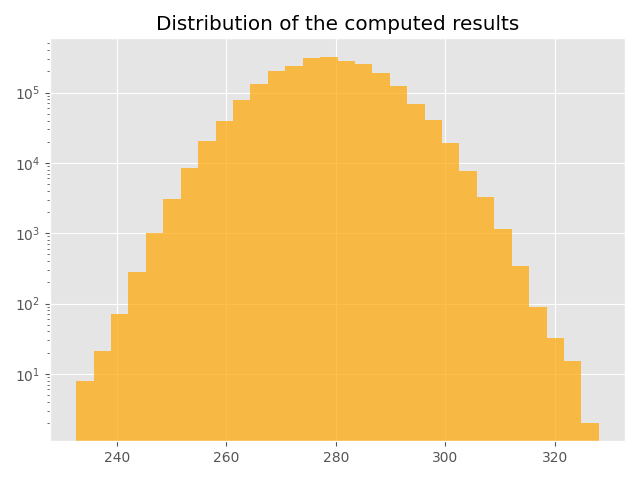
The discrepancies come from?¶
We mix torch and onnxruntime to execute the kernels.
data = []
for mod, provider, itype in itertools.product(
["ORT-ORT", "ORT-TORCH", "TORCH-ORT", "TORCH-TORCH"], ["CPU", "CUDA"], [TFLOAT, TFLOAT16]
):
ttype = onnx_dtype_to_torch_dtype(itype)
np_dtype = onnx_dtype_to_np_dtype(itype)
tch_feeds, _ = cast_feeds(itype, provider, feeds)
if tch_feeds is None:
continue
ker1, ker2 = mod.split("-")
custom_kernels = (
{("", "LayerNormalization"): LayerNormalizationOrt} if ker1 == "ORT" else {}
) | ({("", "MatMul"): MatMulOrt} if ker2 == "ORT" else {})
model = get_model(itype)
print()
print(f"-- {mod} running on {provider} with {onnx_dtype_name(itype)}")
sess = TorchOnnxEvaluator(
model,
custom_kernels=custom_kernels,
providers=[f"{provider}ExecutionProvider"],
)
got = sess.run(None, tch_feeds)
print(f"-- {mod}: {string_type(got, **kws)}")
difft = max_diff(baseline[itype, provider, "torch"], got)
print(f"-- diff with torch {string_diff(difft)}")
diffo = max_diff(baseline[itype, provider, "ort"], got)
print(f"-- diff with ort {string_diff(diffo)}")
data.append(
dict(
model=mod,
dtype=onnx_dtype_name(itype),
provider=provider,
diff_ort=diffo["abs"],
diff_torch=difft["abs"],
)
)
-- ORT-ORT running on CPU with FLOAT
-- ORT-ORT: #1[CT1s2x1024x1152[240.57925415039062,334.54425048828125:A287.84747691659464]]
-- diff with torch abs=0.000152587890625, rel=5.781645673859666e-07, n=2359296.0, dev=0
-- diff with ort abs=0, rel=0, dev=0
-- ORT-ORT running on CPU with FLOAT16
-- ORT-ORT: #1[CT10s2x1024x1152[240.625,334.75:A287.8463324970669]]
-- diff with torch abs=0.25, rel=0.0009596892142448591, n=2359296.0, dev=0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0, dev=0
-- ORT-ORT running on CUDA with FLOAT
-- ORT-ORT: #1[GT1s32x1024x1152[236.87997436523438,343.17724609375:A287.7772252789]]
-- diff with torch abs=0.019378662109375, rel=6.64516856253671e-05, n=37748736.0, dev=0
-- diff with ort abs=0, rel=0, dev=1
-- ORT-ORT running on CUDA with FLOAT16
-- ORT-ORT: #1[GT10s32x1024x1152[236.875,343.25:A287.7765724360943]]
-- diff with torch abs=0.5, rel=0.001792108272013362, n=37748736.0, dev=0
-- diff with ort abs=0, rel=0, dev=1
-- ORT-TORCH running on CPU with FLOAT
-- ORT-TORCH: #1[CT1s2x1024x1152[240.5792236328125,334.54425048828125:A287.84747694850535]]
-- diff with torch abs=0.0001220703125, rel=4.529310760170069e-07, n=2359296.0, dev=0
-- diff with ort abs=0.000152587890625, rel=5.42958038136966e-07, n=2359296.0, dev=0
-- ORT-TORCH running on CPU with FLOAT16
-- ORT-TORCH: #1[CT10s2x1024x1152[240.625,334.75:A287.84633005989923]]
-- diff with torch abs=0.25, rel=0.0009643164346521325, n=2359296.0, dev=0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0, dev=0
-- ORT-TORCH running on CUDA with FLOAT
-- ORT-TORCH: #1[GT1s32x1024x1152[236.8856964111328,343.1820068359375:A287.77991321150245]]
-- diff with torch abs=0.000152587890625, rel=5.428316558500526e-07, n=37748736.0, dev=0
-- diff with ort abs=0.019378662109375, rel=6.645610174534816e-05, n=37748736.0, dev=1
-- ORT-TORCH running on CUDA with FLOAT16
-- ORT-TORCH: #1[GT10s32x1024x1152[236.875,343.25:A287.7765724360943]]
-- diff with torch abs=0.5, rel=0.001792108272013362, n=37748736.0, dev=0
-- diff with ort abs=0, rel=0, dev=1
-- TORCH-ORT running on CPU with FLOAT
-- TORCH-ORT: #1[CT1s2x1024x1152[240.57923889160156,334.5442810058594:A287.84747697504804]]
-- diff with torch abs=0.000152587890625, rel=5.500474556302592e-07, n=2359296.0, dev=0
-- diff with ort abs=0.0001220703125, rel=4.295292434401796e-07, n=2359296.0, dev=0
-- TORCH-ORT running on CPU with FLOAT16
-- TORCH-ORT: #1[CT10s2x1024x1152[240.625,334.75:A287.8463390668233]]
-- diff with torch abs=0.25, rel=0.0009587690938865048, n=2359296.0, dev=0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0, dev=0
-- TORCH-ORT running on CUDA with FLOAT
-- TORCH-ORT: #1[GT1s32x1024x1152[236.87997436523438,343.1772766113281:A287.7772253273001]]
-- diff with torch abs=0.019378662109375, rel=6.64516856253671e-05, n=37748736.0, dev=0
-- diff with ort abs=0.002899169921875, rel=1.0323175408129632e-05, n=37748736.0, dev=1
-- TORCH-ORT running on CUDA with FLOAT16
-- TORCH-ORT: #1[GT10s32x1024x1152[236.875,343.25:A287.776573277182]]
-- diff with torch abs=0, rel=0, dev=0
-- diff with ort abs=0.5, rel=0.001795325690033429, n=37748736.0, dev=1
-- TORCH-TORCH running on CPU with FLOAT
-- TORCH-TORCH: #1[CT1s2x1024x1152[240.5792236328125,334.54425048828125:A287.8474769835852]]
-- diff with torch abs=0, rel=0, dev=0
-- diff with ort abs=0.000152587890625, rel=5.781642331118928e-07, n=2359296.0, dev=0
-- TORCH-TORCH running on CPU with FLOAT16
-- TORCH-TORCH: #1[CT10s2x1024x1152[240.625,334.75:A287.8463393847148]]
-- diff with torch abs=0, rel=0, dev=0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0, dev=0
-- TORCH-TORCH running on CUDA with FLOAT
-- TORCH-TORCH: #1[GT1s32x1024x1152[236.8856964111328,343.1820068359375:A287.7799132295177]]
-- diff with torch abs=0, rel=0, dev=0
-- diff with ort abs=0.019378662109375, rel=6.645610174534816e-05, n=37748736.0, dev=1
-- TORCH-TORCH running on CUDA with FLOAT16
-- TORCH-TORCH: #1[GT10s32x1024x1152[236.875,343.25:A287.776573277182]]
-- diff with torch abs=0, rel=0, dev=0
-- diff with ort abs=0.5, rel=0.001795325690033429, n=37748736.0, dev=1
df = pandas.DataFrame(data).set_index(["dtype", "provider", "model"])
df = df.sort_index()
print(df)
diff_ort diff_torch
dtype provider model
FLOAT CPU ORT-ORT 0.000000 0.000153
ORT-TORCH 0.000153 0.000122
TORCH-ORT 0.000122 0.000153
TORCH-TORCH 0.000153 0.000000
CUDA ORT-ORT 0.000000 0.019379
ORT-TORCH 0.019379 0.000153
TORCH-ORT 0.002899 0.019379
TORCH-TORCH 0.019379 0.000000
FLOAT16 CPU ORT-ORT 0.250000 0.250000
ORT-TORCH 0.250000 0.250000
TORCH-ORT 0.250000 0.250000
TORCH-TORCH 0.250000 0.000000
CUDA ORT-ORT 0.000000 0.500000
ORT-TORCH 0.000000 0.500000
TORCH-ORT 0.500000 0.000000
TORCH-TORCH 0.500000 0.000000
Visually.
save_fig(
rotate_align(
df[["diff_ort", "diff_torch"]].plot.bar(
title="ORT/Torch or Torch/ORT for LayerNorm(X) @ W + B",
figsize=(10, 4),
)
),
"plot_layer_norm_discrepancies_2.png",
)
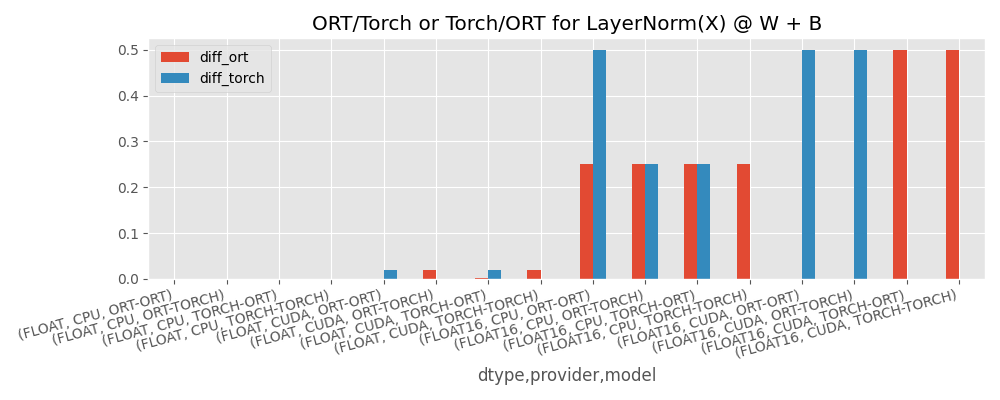
Conclusion¶
torch seems able to replicate the same results if the same computation is run multiple times. onnxruntime is only able to do that on CUDA. With float16 and CUDA, LayerNormalization seems to introduce some discrepancies.
Total running time of the script: (0 minutes 34.421 seconds)
Related examples