Note
Go to the end to download the full example code.
Measures loading, saving time for an onnx model in python¶
The script creates an ONNX model and measures the time to load and save it with onnx and onnx2. This only compares the python bindings.
import os
import time
import numpy as np
import pandas
import onnx
import onnx_extended.onnx2 as onnx2
model_id = (
"microsoft/Phi-3.5-mini-instruct" # "microsoft/Phi-4-mini-reasoning", (too big)
)
model_idf = model_id.replace("/", "_")
exporter = "custom" # or onnx-dynamo to use torch.onnx.export
optimization = "default" # or ir for onnx-dynamo
data = []
onnx_files_ = [
f"dump_test/{model_idf}/"
f"onnx-dynamo/ir/{model_idf}-{exporter}-{optimization}.onnx",
f"dump_test/{model_idf}/{exporter}/{optimization}/"
f"{model_idf}-{exporter}-{optimization}.onnx",
]
onnx_files = [f for f in onnx_files_ if os.path.exists(f)]
if not onnx_files:
print("Creates the model, starts with importing transformers...")
import torch # noqa: F401
import transformers # noqa: F401
print("Imports onnx-diagnostic...")
from onnx_diagnostic.torch_models.validate import validate_model
print("Starts creating the model...")
validate_model(
model_id,
do_run=True,
verbose=2,
exporter=exporter,
do_same=True,
patch=True,
rewrite=True,
optimization=optimization,
dump_folder="dump_test",
model_options=dict(num_hidden_layers=2),
)
print("done.")
onnx_files = [f for f in onnx_files_ if os.path.exists(f)]
assert onnx_files, f"Unable to find a file in {onnx_files}"
onnx_file = onnx_files[0]
onnx_data = onnx_file + ".data"
Creates the model, starts with importing transformers...
Imports onnx-diagnostic...
use_kernel_func_from_hub is not available in the installed kernels version. Please upgrade kernels to use this feature.
Starts creating the model...
[validate_model] dump into 'microsoft_Phi-3.5-mini-instruct/custom/default'
[validate_model] validate model id 'microsoft/Phi-3.5-mini-instruct'
[validate_model] patch=True
[validate_model] model_options={'num_hidden_layers': 2}
[validate_model] get dummy inputs with input_options=None...
[validate_model] rewrite=True, patch_kwargs={'patch_transformers': True, 'patch_diffusers': True, 'patch': True}, stop_if_static=1
[validate_model] exporter='custom', optimization='default'
[validate_model] dump_folder='dump_test/microsoft_Phi-3.5-mini-instruct/custom/default'
[validate_model] output_names=None
[get_untrained_model_with_inputs] model_id='microsoft/Phi-3.5-mini-instruct', subfolder=None
[get_untrained_model_with_inputs] use preinstalled 'microsoft/Phi-3.5-mini-instruct'
This model config has set a `rope_parameters['original_max_position_embeddings']` field, to be used together with `max_position_embeddings` to determine a scaling factor. Please set the `factor` field of `rope_parameters`with this ratio instead -- we recommend the use of this field over `original_max_position_embeddings`, as it is compatible with most model architectures.
[get_untrained_model_with_inputs] architecture='Phi3ForCausalLM'
[get_untrained_model_with_inputs] cls='Phi3Config'
[get_untrained_model_with_inputs] task='text-generation'
[get_untrained_model_with_inputs] -- updated config
{'head_dim': '+96'}
[get_untrained_model_with_inputs] --
[get_untrained_model_with_inputs] default config._attn_implementation=None
[get_untrained_model_with_inputs] package_source=transformers from ~/github/transformers/src/transformers/__init__.py
[get_untrained_model_with_inputs] instantiate model_id 'microsoft/Phi-3.5-mini-instruct', subfolder=None
[get_untrained_model_with_inputs] -- done(2) in 2.9874998290324584e-05s
[get_untrained_model_with_inputs] instantiate_specific_model <class 'transformers.models.phi3.modeling_phi3.Phi3ForCausalLM'>
[get_untrained_model_with_inputs] -- done(3) in 6.239899994398002e-05s (model is <class 'NoneType'>)
[get_untrained_model_with_inputs] instantiate_specific_model(2) <class 'transformers.models.phi3.modeling_phi3.Phi3ForCausalLM'>
[get_untrained_model_with_inputs] -- done(4) in 3.8228192509996006s (model is <class 'transformers.models.phi3.modeling_phi3.Phi3ForCausalLM'>)
[get_untrained_model_with_inputs] use fct=<function get_inputs at 0x7134243a2c00>
[get_untrained_model_with_inputs] model class='Phi3ForCausalLM'
[validate_model] --
[validate_model] task=text-generation
[validate_model] size=1615.55859375 Mb
[validate_model] n_weights=423.508992 millions parameters
[validate_model] +INPUT input_ids=T7s2x3
[validate_model] +INPUT attention_mask=T7s2x33
[validate_model] +INPUT position_ids=T7s2x3
[validate_model] +INPUT past_key_values=DynamicCache(key_cache=#2[T1s2x32x30x96,T1s2x32x30x96], value_cache=#2[T1s2x32x30x96,T1s2x32x30x96])
[validate_model] +SHAPE input_ids={0:DYN(batch),1:DYN(seq_length)}
[validate_model] +SHAPE attention_mask={0:DYN(batch),1:DYN(cache+seq)}
[validate_model] +SHAPE position_ids={0:DYN(batch),1:DYN(seq_length)}
[validate_model] +SHAPE past_key_values=#4[{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)}]
[validate_model] second_input_keys=['inputs_prompt', 'inputs2', 'inputs_empty_cache', 'inputs_batch1']
[validate_model] --
[validate_model] -- run the model inputs='inputs'...
[validate_model] inputs=dict(input_ids:T7s2x3,attention_mask:T7s2x33,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x96,T1s2x32x30x96], value_cache=#2[T1s2x32x30x96,T1s2x32x30x96]))
[validate_model] done ([run]) - CausalLMOutputWithPast(logits:T1s2x3x32064,past_key_values:DynamicCache(key_cache=#2[T1s2x32x33x96,T1s2x32x33x96], value_cache=#2[T1s2x32x33x96,T1s2x32x33x96]))
[validate_model] -- run the model inputs='inputs_prompt'...
[validate_model] inputs_prompt=dict(input_ids:T7s1x11)
[validate_model] done ([run2_prompt]) - CausalLMOutputWithPast(logits:T1s1x11x32064,past_key_values:DynamicCache(DynamicSlidingWindowLayer(T1s1x32x11x96, T1s1x32x11x96), DynamicSlidingWindowLayer(T1s1x32x11x96, T1s1x32x11x96)))
[validate_model] -- run the model inputs='inputs2'...
[validate_model] inputs2=dict(input_ids:T7s3x4,attention_mask:T7s3x35,position_ids:T7s3x4,past_key_values:DynamicCache(key_cache=#2[T1s3x32x31x96,T1s3x32x31x96], value_cache=#2[T1s3x32x31x96,T1s3x32x31x96]))
[validate_model] done ([run22]) - CausalLMOutputWithPast(logits:T1s3x4x32064,past_key_values:DynamicCache(key_cache=#2[T1s3x32x35x96,T1s3x32x35x96], value_cache=#2[T1s3x32x35x96,T1s3x32x35x96]))
[validate_model] -- run the model inputs='inputs_empty_cache'...
[validate_model] inputs_empty_cache=dict(input_ids:T7s2x3,attention_mask:T7s2x3,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x0x96,T1s2x32x0x96], value_cache=#2[T1s2x32x0x96,T1s2x32x0x96]))
[validate_model] done ([run2_empty_cache]) - CausalLMOutputWithPast(logits:T1s2x3x32064,past_key_values:DynamicCache(key_cache=#2[T1s2x32x3x96,T1s2x32x3x96], value_cache=#2[T1s2x32x3x96,T1s2x32x3x96]))
[validate_model] -- run the model inputs='inputs_batch1'...
[validate_model] inputs_batch1=dict(input_ids:T7s1x3,attention_mask:T7s1x33,position_ids:T7s1x3,past_key_values:DynamicCache(key_cache=#2[T1s1x32x30x96,T1s1x32x30x96], value_cache=#2[T1s1x32x30x96,T1s1x32x30x96]))
[validate_model] done ([run2_batch1]) - CausalLMOutputWithPast(logits:T1s1x3x32064,past_key_values:DynamicCache(key_cache=#2[T1s1x32x33x96,T1s1x32x33x96], value_cache=#2[T1s1x32x33x96,T1s1x32x33x96]))
[validate_model] -- export the model with 'custom', optimization='default'
[validate_model] applies patches before exporting stop_if_static=1
[torch_export_patches] patch_sympy=True
. patch_torch=True
. patch_transformers=True
. patch_diffusers=True
. catch_constraints=True
. stop_if_static=1
. patch=True
. custom_patches=None
[torch_export_patches] dump_rewriting='dump_test/microsoft_Phi-3.5-mini-instruct/custom/default/rewrite'
[torch_export_patches] replace torch.jit.isinstance, torch._dynamo.mark_static_address
[_fix_registration] BaseModelOutput is unregistered and registered first
[unregister_cache_serialization] unregistered BaseModelOutput
[register_class_serialization] ---------- register BaseModelOutput
[_fix_registration] BaseModelOutput done.
[_fix_registration] UNet2DConditionOutput is unregistered and registered first
[unregister_cache_serialization] unregistered UNet2DConditionOutput
[register_class_serialization] ---------- register UNet2DConditionOutput
[_fix_registration] UNet2DConditionOutput done.
[register_class_serialization] ---------- register DynamicCache
[register_class_serialization] ---------- register EncoderDecoderCache
[register_class_serialization] ---------- register StaticCache
[register_class_serialization] ---------- register MambaCache
[register_class_serialization] already registered UNet2DConditionOutput
[register_class_serialization] already registered BaseModelOutput
[torch_export_patches] sympy.__version__='1.14.0'
[torch_export_patches] patch sympy
[torch_export_patches] torch.__version__='2.11.0.dev20260211+cu130'
[torch_export_patches] stop_if_static=1
[torch_export_patches] patch pytorch
[torch_export_patches] modifies shape constraints
[torch_export_patches] assert when a dynamic dimension turns static
[torch_export_patches] replaces ShapeEnv._set_replacement
[torch_export_patches] replaces ShapeEnv._log_guard
[torch_export_patches] transformers.__version__='5.2.0.dev0'
[torch_export_patches] patches transformers.masking_utils.sdpa_mask (3)
[torch_export_patches] patches transformers.masking_utils.eager_mask
[torch_export_patches] patches transformers.masking_utils.eager_mask in ALL_MASK_ATTENTION_FUNCTIONS
[torch_export_patches] patches transformers.masking_utils.sdpa_mask in ALL_MASK_ATTENTION_FUNCTIONS
[torch_export_patches] patches transformers.integrations.sdpa_attention.sdpa_attention_forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_AttentionMaskConverter:
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_CompileableContextVar: set
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_DynamicLayer: lazy_initialization
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_FunnelAttentionStructure: relative_pos
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_FunnelRelMultiheadAttention: relative_positional_attention
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma2RotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma3Model: get_placeholder_mask
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma3RotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GemmaRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GenerationMixin: _cache_dependant_input_preparation, _cache_dependant_input_preparation_exporting
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_IdeficsAttention: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_IdeficsEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_LlamaRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_MistralRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_MixtralRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Phi3RotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Phi4MultimodalRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_PhiRotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLForConditionalGeneration: prepare_inputs_for_generation
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLModel: get_placeholder_mask
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLVisionAttention: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VisionTransformerPretrainedModel: get_window_index, forward, rot_pos_emb
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen3MoeSparseMoeBlock: forward, _forward_expert_loop
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_SamMaskDecoder: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_SmolLM3RotaryEmbedding: forward
[patch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_VisionAttention: forward
[patch_module_or_classes] function: transformers.models.bart.modeling_bart.eager_attention_forward
[patch_module_or_classes] function: transformers.models.marian.modeling_marian.eager_attention_forward
[torch_export_patches] done patching
[validate_model] run patched model...
[validate_model] patched inputs=dict(input_ids:T7s2x3,attention_mask:T7s2x33,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x96,T1s2x32x30x96], value_cache=#2[T1s2x32x30x96,T1s2x32x30x96]))
[validate_model] done (patched run)
[validate_model] patched discrepancies=abs=0, rel=0, dev=0
[call_torch_export_custom] exporter='custom', optimization='default'
[call_torch_export_custom] args=()
[call_torch_export_custom] kwargs=dict(input_ids:T7s2x3,attention_mask:T7s2x33,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x96,T1s2x32x30x96], value_cache=#2[T1s2x32x30x96,T1s2x32x30x96]))
[call_torch_export_custom] dynamic_shapes=dict(input_ids:{0:DYN(batch),1:DYN(seq_length)},attention_mask:{0:DYN(batch),1:DYN(cache+seq)},position_ids:{0:DYN(batch),1:DYN(seq_length)},past_key_values:#4[{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)},{0:DYN(batch),2:DYN(cache_length)}])
[call_torch_export_custom] export...
`loss_type=None` was set in the config but it is unrecognized. Using the default loss: `ForCausalLMLoss`.
[call_torch_export_custom] done (export)
[torch_export_patches] remove patches
[torch_export_patches] restored sympy functions
[torch_export_patches] restored pytorch functions
[torch_export_patches] restored ShapeEnv._set_replacement
[torch_export_patches] restored ShapeEnv._log_guard
[torch_export_patches] restored shape constraints
[torch_export_patches] unpatches transformers
[torch_export_patches] restored transformers.masking_utils.sdpa_mask
[torch_export_patches] restored transformers.masking_utils.eager_mask
[torch_export_patches] restored transformers.masking_utils.eager_mask in ALL_MASK_ATTENTION_FUNCTIONS
[torch_export_patches] restored transformers.masking_utils.sdpa_mask in ALL_MASK_ATTENTION_FUNCTIONS
[torch_export_patches] restored transformers.integrations.sdpa_attention.sdpa_attention_forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_AttentionMaskConverter:
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_CompileableContextVar: set
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_DynamicLayer: lazy_initialization
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_FunnelAttentionStructure: relative_pos
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_FunnelRelMultiheadAttention: relative_positional_attention
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma2RotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma3Model: get_placeholder_mask
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Gemma3RotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GemmaRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_GenerationMixin: _cache_dependant_input_preparation, _cache_dependant_input_preparation_exporting
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_IdeficsAttention: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_IdeficsEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_LlamaRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_MistralRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_MixtralRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Phi3RotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Phi4MultimodalRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_PhiRotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLForConditionalGeneration: prepare_inputs_for_generation
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLModel: get_placeholder_mask
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VLVisionAttention: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen2_5_VisionTransformerPretrainedModel: get_window_index, forward, rot_pos_emb
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_Qwen3MoeSparseMoeBlock: forward, _forward_expert_loop
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_SamMaskDecoder: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_SmolLM3RotaryEmbedding: forward
[unpatch_module_or_classes] onnx_diagnostic.torch_export_patches.patches.patch_transformers.patched_VisionAttention: forward
[unpatch_module_or_classes] function transformers.models.bart.modeling_bart.eager_attention_forward
[unpatch_module_or_classes] function transformers.models.marian.modeling_marian.eager_attention_forward
[validate_model] dumps onnx program in 'dump_test/microsoft_Phi-3.5-mini-instruct/custom/default'...
[validate_model] done (dump onnx) in 5.0669004499995935
[validate_model] dumps statistics in 'dump_test/microsoft_Phi-3.5-mini-instruct/custom/default'...
[validate_model] done (dump)
[validate_onnx_model] verify onnx model with providers ['CPUExecutionProvider']..., flavour=None
[validate_onnx_model] runtime is onnxruntime
[validate_onnx_model] done (ort_session) flavour=None
[validate_onnx_model] -- keys=[('inputs', 'run_expected', ''), ('inputs_prompt', 'run_expected2_prompt', '2_prompt'), ('inputs2', 'run_expected22', '22'), ('inputs_empty_cache', 'run_expected2_empty_cache', '2_empty_cache'), ('inputs_batch1', 'run_expected2_batch1', '2_batch1')]
[validate_onnx_model] -- make_feeds for 'inputs'...
[validate_onnx_model] inputs=dict(input_ids:T7s2x3,attention_mask:T7s2x33,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x30x96,T1s2x32x30x96], value_cache=#2[T1s2x32x30x96,T1s2x32x30x96]))
[validate_onnx_model] ort inputs=dict(input_ids:A7s2x3,attention_mask:A7s2x33,position_ids:A7s2x3,past_key_values_key_0:A1s2x32x30x96,past_key_values_value_0:A1s2x32x30x96,past_key_values_key_1:A1s2x32x30x96,past_key_values_value_1:A1s2x32x30x96)
[validate_onnx_model] done (make_feeds)
[validate_onnx_model] run session on inputs 'inputs'...
[validate_onnx_model] done (run)
[validate_onnx_model] got=#5[A1s2x3x32064,A1s2x32x33x96,A1s2x32x33x96,A1s2x32x33x96,A1s2x32x33x96]
[validate_onnx_model] discrepancies=abs=7.450580596923828e-06, rel=0.0032285076546217277, n=1003392.0, dev=0
[validate_onnx_model] -- make_feeds for 'inputs2'...
[validate_onnx_model] inputs=dict(input_ids:T7s3x4,attention_mask:T7s3x35,position_ids:T7s3x4,past_key_values:DynamicCache(key_cache=#2[T1s3x32x31x96,T1s3x32x31x96], value_cache=#2[T1s3x32x31x96,T1s3x32x31x96]))
[validate_onnx_model] ort inputs=dict(input_ids:A7s3x4,attention_mask:A7s3x35,position_ids:A7s3x4,past_key_values_key_0:A1s3x32x31x96,past_key_values_value_0:A1s3x32x31x96,past_key_values_key_1:A1s3x32x31x96,past_key_values_value_1:A1s3x32x31x96)
[validate_onnx_model] done (make_feeds)
[validate_onnx_model] run session on inputs 'inputs22'...
[validate_onnx_model] done (run)
[validate_onnx_model] got=#5[A1s3x4x32064,A1s3x32x35x96,A1s3x32x35x96,A1s3x32x35x96,A1s3x32x35x96]
[validate_onnx_model] discrepancies=abs=7.152557373046875e-06, rel=0.0037974022675994357, n=1675008.0, dev=0
[validate_onnx_model] -- make_feeds for 'inputs_empty_cache'...
[validate_onnx_model] inputs=dict(input_ids:T7s2x3,attention_mask:T7s2x3,position_ids:T7s2x3,past_key_values:DynamicCache(key_cache=#2[T1s2x32x0x96,T1s2x32x0x96], value_cache=#2[T1s2x32x0x96,T1s2x32x0x96]))
[validate_onnx_model] ort inputs=dict(input_ids:A7s2x3,attention_mask:A7s2x3,position_ids:A7s2x3,past_key_values_key_0:A1s2x32x0x96,past_key_values_value_0:A1s2x32x0x96,past_key_values_key_1:A1s2x32x0x96,past_key_values_value_1:A1s2x32x0x96)
[validate_onnx_model] done (make_feeds)
[validate_onnx_model] run session on inputs 'inputs2_empty_cache'...
[validate_onnx_model] done (run)
[validate_onnx_model] got=#5[A1s2x3x32064,A1s2x32x3x96,A1s2x32x3x96,A1s2x32x3x96,A1s2x32x3x96]
[validate_onnx_model] discrepancies=abs=5.543231964111328e-06, rel=0.002622831859259997, n=266112.0, dev=0
[validate_onnx_model] -- make_feeds for 'inputs_batch1'...
[validate_onnx_model] inputs=dict(input_ids:T7s1x3,attention_mask:T7s1x33,position_ids:T7s1x3,past_key_values:DynamicCache(key_cache=#2[T1s1x32x30x96,T1s1x32x30x96], value_cache=#2[T1s1x32x30x96,T1s1x32x30x96]))
[validate_onnx_model] ort inputs=dict(input_ids:A7s1x3,attention_mask:A7s1x33,position_ids:A7s1x3,past_key_values_key_0:A1s1x32x30x96,past_key_values_value_0:A1s1x32x30x96,past_key_values_key_1:A1s1x32x30x96,past_key_values_value_1:A1s1x32x30x96)
[validate_onnx_model] done (make_feeds)
[validate_onnx_model] run session on inputs 'inputs2_batch1'...
[validate_onnx_model] done (run)
[validate_onnx_model] got=#5[A1s1x3x32064,A1s1x32x33x96,A1s1x32x33x96,A1s1x32x33x96,A1s1x32x33x96]
[validate_onnx_model] discrepancies=abs=8.106231689453125e-06, rel=0.0033585737972102896, n=501696.0, dev=0
[validate_model] -- done (final)
done.
Let’s load and save the model to get one unique file.
Loads the model and saves it as one unique file.
Let’s get the size.
model size 1615.690 Mb
Measures the loading time¶
def measure(step_name, f, N=3):
times = []
for _ in range(N):
begin = time.perf_counter()
onx = f()
end = time.perf_counter()
times.append(end - begin)
res = {"avg": np.mean(times), "times": times}
data.append(
dict(name=step_name, avg=res["avg"], min=np.min(times), max=np.max(times))
)
return onx, res
Let’s do it with onnx2.
Loading time with onnx2.
{'avg': np.float64(1.1668975313326275), 'times': [1.087328854999214, 1.1952274369996303, 1.2181363019990386]}
Then with onnx.
Loading time with onnx.
{'avg': np.float64(2.2833432009999037), 'times': [2.4991323850008484, 2.43141621399991, 1.9194810039989534]}
Let’s do it with onnx2 but the loading of the tensors is parallelized.
Loading time with onnx2 and 4 threads, it has 31 initializers
{'avg': np.float64(0.8285266990005766), 'times': [0.8034588680002344, 0.8723995010004728, 0.8097217280010227]}
It looks much faster.
Let’s load it with onnxruntime.
import onnxruntime # noqa: E402
so = onnxruntime.SessionOptions()
so.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_DISABLE_ALL
print("Loading time with onnxruntime")
_, times = measure(
"load/ort",
lambda: onnxruntime.InferenceSession(
full_name, so, providers=["CPUExecutionProvider"]
),
)
print(times)
Loading time with onnxruntime
{'avg': np.float64(4.514909101667096), 'times': [4.417811330000404, 4.836813040999914, 4.29010293400097]}
Measure the saving time¶
Let’s do it with onnx2.
Saving time with onnx2.
{'avg': np.float64(1.3292721793325957), 'times': [1.2013734449992626, 1.2893029209990345, 1.4971401719994901]}
Then with onnx.
Saving time with onnx.
{'avg': np.float64(4.567380289000236), 'times': [5.383769752001172, 4.255533997999009, 4.062837117000527]}
Measure the saving time with external weights¶
Let’s do it with onnx2.
full_name = onnx_file.replace(".onnx", ".ext.onnx")
full_weight = full_name.replace(".onnx", ".data")
print("Saving time with onnx2 and external weights.")
_, times = measure(
"save/onnx2/ext", lambda: onnx2.save(onx2, full_name, location=full_weight)
)
print(times)
Saving time with onnx2 and external weights.
{'avg': np.float64(1.3383463006660652), 'times': [0.9166128229990136, 1.4534017949990812, 1.645024284000101]}
Then with onnx. We can only do that once, the function modifies the model inplace to add information about external data. The second run does not follow the same steps.
print("Saving time with onnx and external weights.")
full_name_onnx = full_name.replace(".onnx", ".0.onnx")
full_weight_onnx = full_name.replace(".data", ".0.data")
_, times = measure(
"save/onnx/ext",
lambda: onnx.save(
onx,
full_name_onnx,
location=os.path.split(full_weight_onnx)[-1],
save_as_external_data=True,
all_tensors_to_one_file=True,
),
N=1,
)
print(times)
Saving time with onnx and external weights.
{'avg': np.float64(3.2594214170003397), 'times': [3.2594214170003397]}
Measure the load time with external weights¶
Let’s do it with onnx2.
Loading time with onnx2 and external weights.
{'avg': np.float64(1.3416392190004747), 'times': [1.4545661570009543, 1.5503373610008566, 1.0200141389996134]}
Same measure but parallelized.
print("Loading time with onnx2 parallelized and external weights.")
_, times = measure(
"load/onnx2/ext/x4",
lambda: onnx2.load(onnx_file, location=onnx_data, parallel=True, num_threads=4),
)
print(times)
# Let's do it with onnx2.
print("Saving time with onnx and external weights.")
_, times = measure("load/onnx/ext", lambda: onnx.load(onnx_file))
print(times)
Loading time with onnx2 parallelized and external weights.
{'avg': np.float64(1.0276490683336306), 'times': [0.7483181970001169, 1.5185829100009869, 0.8160460979997879]}
Saving time with onnx and external weights.
{'avg': np.float64(1.8603766983336147), 'times': [1.6823405060004006, 2.033854469000289, 1.8649351200001547]}
Plots¶
df = pandas.DataFrame(data).sort_values("name").set_index("name")
print(df)
avg min max
name
load/onnx 2.283343 1.919481 2.499132
load/onnx/ext 1.860377 1.682341 2.033854
load/onnx2 1.166898 1.087329 1.218136
load/onnx2/ext 1.341639 1.020014 1.550337
load/onnx2/ext/x4 1.027649 0.748318 1.518583
load/onnx2/x4 0.828527 0.803459 0.872400
load/ort 4.514909 4.290103 4.836813
save/onnx 4.567380 4.062837 5.383770
save/onnx/ext 3.259421 3.259421 3.259421
save/onnx2 1.329272 1.201373 1.497140
save/onnx2/ext 1.338346 0.916613 1.645024
Visually.
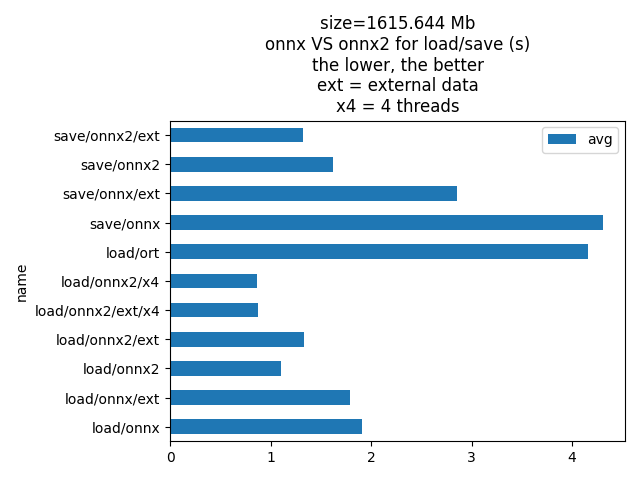
Total running time of the script: (1 minutes 47.045 seconds)