Note
Go to the end to download the full example code.
Profiles a simple onnx graph including a singleGemm¶
The benchmark profiles the execution of Gemm for different types and configuration. That includes a custom operator only available on CUDA calling function cublasLtMatmul.
import pprint
from itertools import product
import numpy
from tqdm import tqdm
import matplotlib.pyplot as plt
from pandas import pivot_table, concat
from onnx import TensorProto
from onnx.helper import (
make_model,
make_node,
make_graph,
make_tensor_value_info,
make_opsetid,
)
from onnx.checker import check_model
from onnx.numpy_helper import from_array
from onnx.reference import ReferenceEvaluator
from onnxruntime import InferenceSession, SessionOptions, get_available_providers
from onnxruntime.capi._pybind_state import (
OrtValue as C_OrtValue,
OrtDevice as C_OrtDevice,
)
from onnxruntime.capi.onnxruntime_pybind11_state import (
NotImplemented,
InvalidGraph,
InvalidArgument,
)
try:
from onnx_array_api.plotting.text_plot import onnx_simple_text_plot
from onnx_array_api.ort.ort_profile import ort_profile
except ImportError:
onnx_simple_text_plot = str
ort_profile = None
try:
from onnx_extended.reference import CReferenceEvaluator
except ImportError:
CReferenceEvaluator = ReferenceEvaluator
from onnx_extended.args import get_parsed_args
from onnx_extended.ext_test_case import unit_test_going
try:
from onnx_extended.validation.cuda.cuda_example_py import get_device_prop
from onnx_extended.ortops.tutorial.cuda import get_ort_ext_libs
except ImportError:
def get_device_prop():
return {"name": "CPU"}
def get_ort_ext_libs():
return None
properties = get_device_prop()
if unit_test_going():
default_dims = "32,32,32;64,64,64"
elif properties.get("major", 0) < 7:
default_dims = "256,256,256;512,512,512"
else:
default_dims = "2048,2048,2048;4096,4096,4096"
script_args = get_parsed_args(
"plot_profile_gemm_ort",
description=__doc__,
dims=(default_dims, "dimensions to try for dims"),
repeat_profile=(17, "number of time to call ORT for profiling"),
)
Device properties¶
{'clockRate': 0,
'computeMode': 0,
'concurrentKernels': 1,
'isMultiGpuBoard': 0,
'major': 8,
'maxThreadsPerBlock': 1024,
'minor': 9,
'multiProcessorCount': 24,
'name': 'NVIDIA GeForce RTX 4060 Laptop GPU',
'sharedMemPerBlock': 49152,
'totalConstMem': 65536,
'totalGlobalMem': 8585281536}
Model to benchmark¶
It includes one Gemm. The operator changes. It can the regular Gemm, a custom Gemm from domain com.microsoft or a custom implementation from domain onnx_extended.ortops.tutorial.cuda.
def create_model(
mat_type=TensorProto.FLOAT, provider="CUDAExecutionProvider", domain="com.microsoft"
):
A = make_tensor_value_info("A", mat_type, [None, None])
B = make_tensor_value_info("B", mat_type, [None, None])
outputs = [make_tensor_value_info("C", mat_type, [None, None])]
inits = []
if domain != "":
if provider != "CUDAExecutionProvider":
return None
f8 = False
if domain == "com.microsoft":
op_name = "GemmFloat8"
computeType = "CUBLAS_COMPUTE_32F"
node_output = ["C"]
elif mat_type == TensorProto.FLOAT:
op_name = "CustomGemmFloat"
computeType = "CUBLAS_COMPUTE_32F_FAST_TF32"
node_output = ["C"]
elif mat_type == TensorProto.FLOAT16:
op_name = "CustomGemmFloat16"
computeType = "CUBLAS_COMPUTE_32F"
node_output = ["C"]
elif mat_type in (TensorProto.FLOAT8E4M3FN, TensorProto.FLOAT8E5M2):
f8 = True
op_name = "CustomGemmFloat8E4M3FN"
computeType = "CUBLAS_COMPUTE_32F"
node_output = ["C"]
outputs = [
make_tensor_value_info("C", TensorProto.FLOAT16, [None, None]),
]
inits.append(from_array(numpy.array([1], dtype=numpy.float32), name="I"))
else:
return None
node_kw = dict(
alpha=1.0,
transA=1,
domain=domain,
computeType=computeType,
fastAccumulationMode=1,
rowMajor=0 if op_name == "CustomGemmFloat8E4M3FN" else 1,
)
node_kw["name"] = (
f"{mat_type}.{len(node_output)}.{len(outputs)}."
f"{domain}..{node_kw['rowMajor']}.."
f"{node_kw['fastAccumulationMode']}..{node_kw['computeType']}.."
f"{f8}"
)
node_inputs = ["A", "B"]
if f8:
node_inputs.append("")
node_inputs.extend(["I"] * 3)
nodes = [make_node(op_name, node_inputs, node_output, **node_kw)]
else:
nodes = [
make_node("Gemm", ["A", "B"], ["C"], transA=1, beta=0.0),
]
graph = make_graph(nodes, "a", [A, B], outputs, inits)
if mat_type < 16:
# regular type
opset, ir = 18, 8
else:
opset, ir = 19, 9
onnx_model = make_model(
graph,
opset_imports=[
make_opsetid("", opset),
make_opsetid("com.microsoft", 1),
make_opsetid("onnx_extended.ortops.tutorial.cuda", 1),
],
ir_version=ir,
)
check_model(onnx_model)
return onnx_model
print(onnx_simple_text_plot(create_model()))
opset: domain='' version=18
opset: domain='com.microsoft' version=1
opset: domain='onnx_extended.ortops.tutorial.cuda' version=1
input: name='A' type=dtype('float32') shape=['', '']
input: name='B' type=dtype('float32') shape=['', '']
GemmFloat8[com.microsoft](A, B, alpha=1.00, computeType=b'CUBLAS_COMPUTE_32F', fastAccumulationMode=1, rowMajor=1, transA=1) -> C
output: name='C' type=dtype('float32') shape=['', '']
A model to cast into anytype. numpy does not support float 8. onnxruntime is used to cast a float array into any type. It must be called with tensor of type OrtValue.
def create_cast(to, cuda=False):
A = make_tensor_value_info("A", TensorProto.FLOAT, [None, None])
C = make_tensor_value_info("C", to, [None, None])
if cuda:
nodes = [
make_node("Cast", ["A"], ["Cc"], to=to),
make_node("MemcpyFromHost", ["Cc"], ["C"]),
]
else:
nodes = [make_node("Cast", ["A"], ["C"], to=to)]
graph = make_graph(nodes, "a", [A], [C])
if to < 16:
# regular type
opset, ir = 18, 8
else:
opset, ir = 19, 9
onnx_model = make_model(
graph, opset_imports=[make_opsetid("", opset)], ir_version=ir
)
if not cuda:
# OpType: MemcpyFromHost
check_model(onnx_model)
return onnx_model
print(onnx_simple_text_plot(create_cast(TensorProto.FLOAT16)))
opset: domain='' version=18
input: name='A' type=dtype('float32') shape=['', '']
Cast(A, to=10) -> C
output: name='C' type=dtype('float16') shape=['', '']
Profiling¶
The benchmark will run the following configurations.
types = [
TensorProto.FLOAT8E4M3FN,
TensorProto.FLOAT,
TensorProto.FLOAT16,
TensorProto.BFLOAT16,
# TensorProto.UINT32,
# TensorProto.INT32,
# TensorProto.INT16,
# TensorProto.INT8,
]
engine = [InferenceSession]
providers = [
["CUDAExecutionProvider", "CPUExecutionProvider"],
]
# M, N, K
# we use multiple of 8, otherwise, float8 does not work.
dims = [tuple(int(i) for i in line.split(",")) for line in script_args.dims.split(";")]
domains = ["onnx_extended.ortops.tutorial.cuda", "", "com.microsoft"]
Let’s cache the matrices involved.
def to_ort_value(m):
device = C_OrtDevice(C_OrtDevice.cpu(), C_OrtDevice.default_memory(), 0)
ort_value = C_OrtValue.ortvalue_from_numpy(m, device)
return ort_value
def cached_inputs(dims, types):
matrices = {}
matrices_cuda = {}
for m, n, k in dims:
for tt in types:
for i, j in [(m, k), (k, n), (k, m)]:
if (tt, i, j) in matrices:
continue
# CPU
try:
sess = InferenceSession(
create_cast(tt).SerializeToString(),
providers=["CPUExecutionProvider"],
)
cpu = True
except (InvalidGraph, InvalidArgument, NotImplemented):
# not support by this version of onnxruntime
cpu = False
if cpu:
vect = (numpy.random.randn(i, j) * 10).astype(numpy.float32)
ov = to_ort_value(vect)
ovtt = sess._sess.run_with_ort_values({"A": ov}, ["C"], None)[0]
matrices[tt, i, j] = ovtt
else:
continue
# CUDA
if "CUDAExecutionProvider" not in get_available_providers():
# No CUDA
continue
sess = InferenceSession(
create_cast(tt, cuda=True).SerializeToString(),
providers=["CUDAExecutionProvider", "CPUExecutionProvider"],
)
vect = (numpy.random.randn(i, j) * 10).astype(numpy.float32)
ov = to_ort_value(vect)
ovtt = sess._sess.run_with_ort_values({"A": ov}, ["C"], None)[0]
matrices_cuda[tt, i, j] = ovtt
return matrices, matrices_cuda
matrices, matrices_cuda = cached_inputs(dims, types)
print(f"{len(matrices)} matrices were created.")
8 matrices were created.
Let’s run the profiles
opts = SessionOptions()
r = get_ort_ext_libs()
if r is not None:
opts.register_custom_ops_library(r[0])
data = []
pbar = tqdm(list(product(types, engine, providers, dims, domains)))
for tt, engine, provider, dim, domain in pbar:
if "CUDAExecutionProvider" not in get_available_providers():
# No CUDA.
continue
if (
tt in {TensorProto.FLOAT8E4M3FN, TensorProto.FLOAT8E5M2}
and properties.get("major", 0) < 9
):
# f8 not available
continue
onx = create_model(tt, provider=provider[0], domain=domain)
if onx is None:
# Not available on this machine
continue
with open(f"plot_bench_gemm_profile_{tt}_{domain}.onnx", "wb") as f:
f.write(onx.SerializeToString())
k1 = (tt, dim[2], dim[0])
k2 = (tt, dim[2], dim[1])
pbar.set_description(f"t={tt} e={engine.__name__} p={provider[0][:4]} dim={dim}")
try:
sess = engine(onx.SerializeToString(), opts, providers=provider)
except Exception:
# Seomthing went wrong.
continue
the_feeds = {"A": matrices_cuda[k1], "B": matrices_cuda[k2]}
out_names = ["C"]
if ort_profile is None:
raise ImportError("Could not import ort_profile from onnx-array-api.")
df = ort_profile(
onx,
the_feeds,
sess_options=opts,
repeat=script_args.repeat_profile,
as_df=True,
providers=provider,
first_it_out=True,
agg=True,
).reset_index(drop=False)
columns = ["xdim", "xdomain", "xdtype", *df.columns]
df["xdim"] = "x".join(map(str, dim))
df["xdomain"] = {
"onnx_extended.ortops.tutorial.cuda": "EXT",
"": "ORT",
"com.microsoft": "COM",
}[domain]
df["args_op_name"] = {
"onnx_extended.ortops.tutorial.cuda": "CG",
"": "Gemm",
"com.microsoft": "G8",
}[domain]
df["xdtype"] = {1: "f32", 10: "f16", 16: "bf16", 17: "e4m3fn", 18: "e5m2"}[tt]
df = df[columns]
data.append(df)
if unit_test_going() and len(data) >= 2:
break
0%| | 0/24 [00:00<?, ?it/s]
t=1 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 0%| | 0/24 [00:00<?, ?it/s]
t=1 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 29%|██▉ | 7/24 [00:00<00:01, 8.85it/s]
t=1 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 29%|██▉ | 7/24 [00:00<00:01, 8.85it/s]
t=1 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 33%|███▎ | 8/24 [00:01<00:02, 6.66it/s]
t=1 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 33%|███▎ | 8/24 [00:01<00:02, 6.66it/s]
t=1 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 33%|███▎ | 8/24 [00:01<00:02, 6.66it/s]
t=1 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 42%|████▏ | 10/24 [00:02<00:03, 3.51it/s]
t=1 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 42%|████▏ | 10/24 [00:02<00:03, 3.51it/s]
t=1 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 46%|████▌ | 11/24 [00:03<00:05, 2.56it/s]
t=1 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 46%|████▌ | 11/24 [00:03<00:05, 2.56it/s]
t=10 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 46%|████▌ | 11/24 [00:03<00:05, 2.56it/s]
t=10 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 54%|█████▍ | 13/24 [00:03<00:03, 2.90it/s]
t=10 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 54%|█████▍ | 13/24 [00:03<00:03, 2.90it/s]
t=10 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 58%|█████▊ | 14/24 [00:04<00:03, 2.74it/s]
t=10 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 58%|█████▊ | 14/24 [00:04<00:03, 2.74it/s]
t=10 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 58%|█████▊ | 14/24 [00:04<00:03, 2.74it/s]
t=10 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 67%|██████▋ | 16/24 [00:04<00:02, 3.06it/s]
t=10 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 67%|██████▋ | 16/24 [00:04<00:02, 3.06it/s]
t=10 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 71%|███████ | 17/24 [00:04<00:02, 2.90it/s]
t=10 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 71%|███████ | 17/24 [00:04<00:02, 2.90it/s]
t=16 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 71%|███████ | 17/24 [00:04<00:02, 2.90it/s]
t=16 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 83%|████████▎ | 20/24 [00:05<00:01, 3.97it/s]
t=16 e=InferenceSession p=CUDA dim=(2048, 2048, 2048): 83%|████████▎ | 20/24 [00:05<00:01, 3.97it/s]
t=16 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 83%|████████▎ | 20/24 [00:05<00:01, 3.97it/s]
t=16 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 96%|█████████▌| 23/24 [00:05<00:00, 4.80it/s]
t=16 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 96%|█████████▌| 23/24 [00:05<00:00, 4.80it/s]
t=16 e=InferenceSession p=CUDA dim=(4096, 4096, 4096): 100%|██████████| 24/24 [00:05<00:00, 4.09it/s]
Results¶
0 1 2 3 4
xdim 2048x2048x2048 2048x2048x2048 2048x2048x2048 2048x2048x2048 2048x2048x2048
xdomain EXT EXT EXT EXT EXT
xdtype f32 f32 f32 f32 f32
it==0 0 0 0 1 1
cat Node Session Session Node Session
args_node_index 0 0
args_op_name CG CG CG CG CG
args_provider CUDAExecutionProvider CUDAExecutionProvider
event_name kernel_time SequentialExecutor::Execute model_run kernel_time SequentialExecutor::Execute
dur 222680 245992 665746 38932 16645
Summary¶
if data:
piv = pivot_table(
df[df["it==0"] == 0],
index=["xdim", "cat", "event_name"],
columns=["xdtype", "xdomain", "args_op_name"],
values=["dur"],
)
piv.reset_index(drop=False).to_excel("plot_profile_gemm_ort_summary.xlsx")
piv.reset_index(drop=False).to_csv("plot_profile_gemm_ort_summary.csv")
print()
print("summary")
print(piv)
summary
dur
xdtype bf16 f16 f32
xdomain ORT EXT ORT EXT ORT
args_op_name Gemm CG Gemm CG Gemm
xdim cat event_name
2048x2048x2048 Node kernel_time 2251.0 73791.0 1740.0 222680.0 2912.0
Session SequentialExecutor::Execute 3261.0 80898.0 2461.0 245992.0 4195.0
model_run 72060.0 165337.0 63880.0 665746.0 239724.0
4096x4096x4096 Node kernel_time 2548.0 117611.0 2511.0 280699.0 2735.0
Session SequentialExecutor::Execute 3605.0 132877.0 3631.0 307363.0 3863.0
model_run 313400.0 379083.0 316285.0 924328.0 611902.0
plot
if data:
print()
print("compact")
pivi = pivot_table(
df[(df["it==0"] == 0) & (df["event_name"] == "kernel_time")],
index=["xdim"],
columns=["xdtype", "xdomain", "args_op_name"],
values="dur",
)
print(pivi)
print()
print("not operator")
pivinot = pivot_table(
df[df["cat"] != "Node"],
index=["xdim", "event_name"],
columns=["xdtype", "xdomain"],
values="dur",
)
print(pivinot)
if data:
fig, ax = plt.subplots(2, 2, figsize=(12, 8))
pivi.T.plot(
ax=ax[0, 0],
title="kernel time",
kind="barh",
logx=True,
)
pivinot.T.plot(
ax=ax[1, 0],
title="Global times",
kind="barh",
logx=True,
)
for i, name in enumerate(["kernel_time"]):
pivi = pivot_table(
df[(df["it==0"] == 0) & (df["event_name"] == name)],
index=["xdim"],
columns=["xdtype", "xdomain", "args_op_name"],
values="dur",
)
if pivi.shape[0]:
pivi.T.plot(
ax=ax[i, 1],
title=f"{name}",
kind="barh",
logx=True,
)
fig.tight_layout()
fig.savefig("plot_bench_gemm_ort.png")
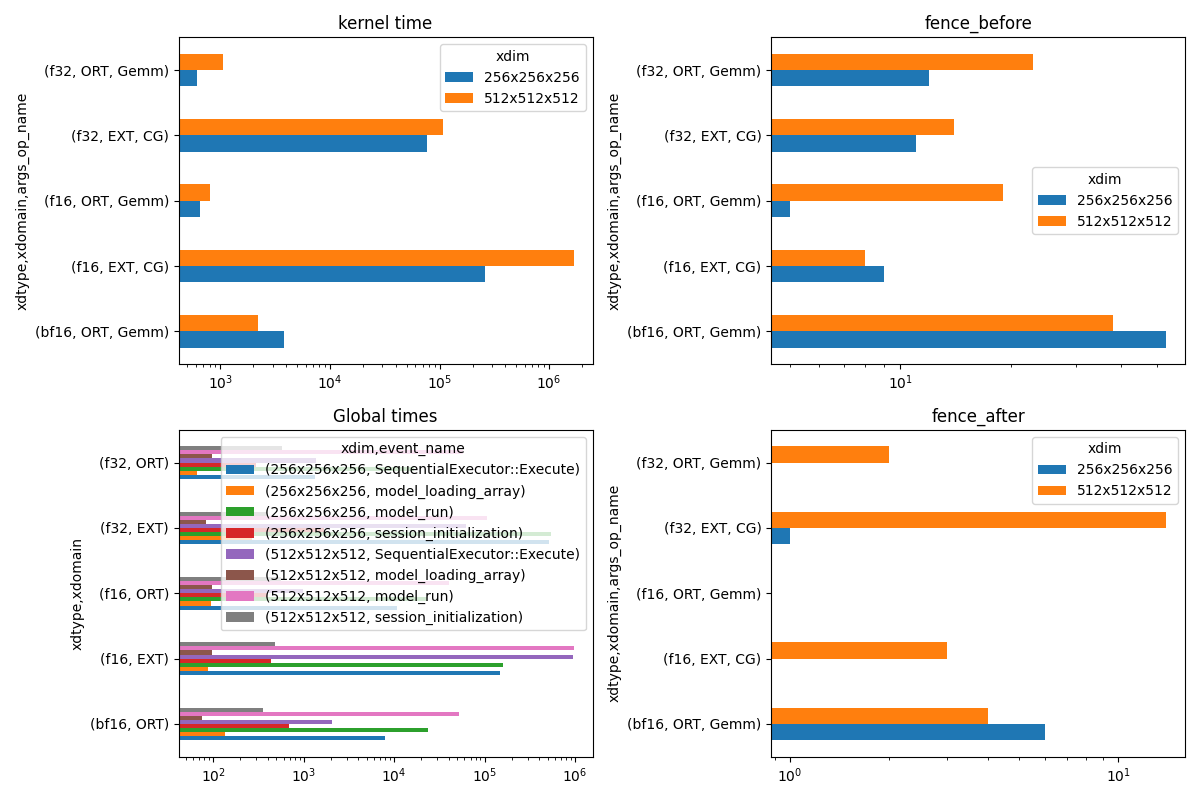
compact
xdtype bf16 f16 f32
xdomain ORT EXT ORT EXT ORT
args_op_name Gemm CG Gemm CG Gemm
xdim
2048x2048x2048 2251.0 73791.0 1740.0 222680.0 2912.0
4096x4096x4096 2548.0 117611.0 2511.0 280699.0 2735.0
not operator
xdtype bf16 f16 f32
xdomain ORT EXT ORT EXT ORT
xdim event_name
2048x2048x2048 SequentialExecutor::Execute 151004.5 165921.0 161843.0 131318.5 5607.5
model_loading_array 128.0 189.0 138.0 160.0 136.0
model_run 193785.5 217350.5 202304.0 374313.5 135542.0
session_initialization 1400.0 9215.0 1433.0 1545.0 7391.0
4096x4096x4096 SequentialExecutor::Execute 3269.5 73417.0 2452.5 168649.0 10459.0
model_loading_array 164.0 114.0 134.0 167.0 254.0
model_run 188953.5 224904.0 182077.0 517684.5 378720.0
session_initialization 1243.0 1165.0 1174.0 7772.0 4051.0
Total running time of the script: (0 minutes 12.150 seconds)