Note
Go to the end to download the full example code.
Fuse Tranpose and Cast on CUDA¶
This configuration happens in a Llama model.
output = Cast(Transpose(X), to=FLOAT16)
Where the shapes are:
X: 4096,4096
Transpose + Cast¶
from onnx_extended.args import get_parsed_args
script_args = get_parsed_args(
"plot_op_transpose_2d_cast",
description=__doc__,
config=(
"small",
"small, short optimization (default), "
"medium for medium sizes, "
"large for big sizes",
"llama for a specific case on llama",
),
warmup=3,
repeat=5,
itype=(10, "1 or 10 for float or float16"),
expose="config,itype,warmup,repeat",
)
import time
import numpy as np
from numpy.testing import assert_almost_equal
from pandas import DataFrame
from tqdm import tqdm
import onnx.helper as oh
from onnx import TensorProto
from onnx_array_api.plotting.text_plot import onnx_simple_text_plot
itype = script_args.itype
dtype = np.float32 if itype == TensorProto.FLOAT else np.float16
config = script_args.config
print(f"config={config}")
print(f"itype={itype}, dtype={dtype}")
if config == "small":
sizes = (256, 512, 1024)
elif config == "medium":
sizes = (512, 1024, 2048)
elif config == "large":
sizes = (1024, 2048, 4096, 8192)
elif config == "llama":
sizes = (2048, 4096, 8192)
else:
try:
sizes = list(map(int, config.split(",")))
except (ValueError, TypeError) as e:
raise AssertionError(f"Unexpected config value {config!r}.") from e
def get_model(fused=False, itype=TensorProto.FLOAT):
iitype = TensorProto.FLOAT if itype == TensorProto.FLOAT16 else TensorProto.FLOAT16
suffix = "32" if itype == TensorProto.FLOAT else "16"
if fused:
nodes = [
oh.make_node(
f"Transpose2DCastFP{suffix}",
["X"],
["Y"],
domain="onnx_extended.ortops.optim.cuda",
)
]
else:
nodes = [
oh.make_node("Transpose", ["X"], ["xt"], perm=[1, 0]),
oh.make_node("Cast", ["xt"], ["Y"], to=itype),
]
model = oh.make_model(
oh.make_graph(
nodes,
"g",
[oh.make_tensor_value_info("X", iitype, ["a", "b"])],
[oh.make_tensor_value_info("Y", itype, ["b", "a"])],
),
opset_imports=[
oh.make_opsetid("", 18),
oh.make_opsetid("onnx_extended.ortops.optim.cuda", 1),
],
ir_version=9,
)
return model
model = get_model(itype=itype)
print(onnx_simple_text_plot(model))
config=small
itype=10, dtype=<class 'numpy.float16'>
opset: domain='' version=18
opset: domain='onnx_extended.ortops.optim.cuda' version=1
input: name='X' type=dtype('float32') shape=['a', 'b']
Transpose(X, perm=[1,0]) -> xt
Cast(xt, to=10) -> Y
output: name='Y' type=dtype('float16') shape=['b', 'a']
Models¶
def get_session(model):
import onnxruntime
from onnx_extended.ortops.optim.cuda import get_ort_ext_libs
if "CUDAExecutionProvider" not in onnxruntime.get_available_providers():
return None
opts = onnxruntime.SessionOptions()
opts.register_custom_ops_library(get_ort_ext_libs()[0])
sess = onnxruntime.InferenceSession(
model.SerializeToString(),
opts,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"],
)
return sess
X = np.random.randn(64, 32).astype(
np.float16 if itype == TensorProto.FLOAT else np.float32
)
feeds = dict(X=X)
sess1 = get_session(model)
if sess1 is not None:
for k, v in feeds.items():
print(k, v.dtype, v.shape)
expected = sess1.run(None, feeds)[0]
print(expected[:4, :4])
X float32 (64, 32)
[[ 1.144 1.531 -0.2537 0.364 ]
[-0.9155 -1.075 -1.664 0.686 ]
[-0.569 0.313 -1.226 -0.1168]
[-0.6147 -0.2583 -0.7163 -0.132 ]]
Same model but using the fused op.
opset: domain='' version=18
opset: domain='onnx_extended.ortops.optim.cuda' version=1
input: name='X' type=dtype('float32') shape=['a', 'b']
Transpose2DCastFP16[onnx_extended.ortops.optim.cuda](X) -> Y
output: name='Y' type=dtype('float16') shape=['b', 'a']
[[ 1.144 1.531 -0.2537 0.364 ]
[-0.9155 -1.075 -1.664 0.686 ]
[-0.569 0.313 -1.226 -0.1168]
[-0.6147 -0.2583 -0.7163 -0.132 ]]
Benchmark¶
def move_inputs(sess, feeds):
from onnxruntime.capi._pybind_state import (
SessionIOBinding,
OrtDevice as C_OrtDevice,
OrtValue as C_OrtValue,
)
input_names = [i.name for i in sess.get_inputs()]
ort_device = C_OrtDevice(C_OrtDevice.cuda(), C_OrtDevice.default_memory(), 0)
feed_ort_value = [
(name, C_OrtValue.ortvalue_from_numpy(feeds[name], ort_device))
for name in input_names
]
bind = SessionIOBinding(sess._sess)
for name, value in feed_ort_value:
bind.bind_input(
name, ort_device, feeds[name].dtype, value.shape(), value.data_ptr()
)
for o in sess.get_outputs():
bind.bind_output(o.name, ort_device)
return bind, feed_ort_value
def benchmark(
sess, sizes, config, label, itype, times_col: int = 1, times_indices: int = 1
):
data = []
for size in tqdm(sizes):
X = np.random.randn(size, size).astype(
np.float16 if itype == TensorProto.FLOAT else np.float32
)
feeds = dict(X=X)
bind, _cuda_feeds = move_inputs(sess, feeds)
begin = time.perf_counter()
for _i in range(script_args.warmup):
# sess.run(None, feeds)
sess._sess.run_with_iobinding(bind, None)
warmup = time.perf_counter() - begin
times = []
for _i in range(script_args.repeat):
begin = time.perf_counter()
# sess.run(None, feeds)
sess._sess.run_with_iobinding(bind, None)
times.append(time.perf_counter() - begin)
npt = np.array(times)
obs = dict(
warmup=warmup,
time=npt.mean(),
std=npt.std(),
min=npt.min(),
max=npt.max(),
repeat=script_args.repeat,
size=size,
label=label,
)
data.append(obs)
return data
Not Fused.
sizes=(256, 512, 1024)
0%| | 0/3 [00:00<?, ?it/s]
100%|██████████| 3/3 [00:00<00:00, 28.09it/s]
100%|██████████| 3/3 [00:00<00:00, 27.99it/s]
Fused.
if sess2 is not None:
data_nd2 = benchmark(sess2, sizes, script_args.config, "Fused", itype=itype)
0%| | 0/3 [00:00<?, ?it/s]
100%|██████████| 3/3 [00:00<00:00, 46.49it/s]
Data¶
warmup time std min max repeat size label
0 0.006178 0.000388 0.000362 0.000127 0.001068 5 256 Not Fused
1 0.005847 0.000167 0.000056 0.000125 0.000268 5 512 Not Fused
2 0.003798 0.001154 0.001521 0.000172 0.004123 5 1024 Not Fused
3 0.001275 0.000074 0.000002 0.000072 0.000077 5 256 Fused
4 0.001737 0.000122 0.000002 0.000119 0.000125 5 512 Fused
Pivot.
if sess2 is not None:
pivot = df.pivot(index="size", columns="label", values="time")
pivot["ratio"] = pivot["Not Fused"] / pivot["Fused"]
print(pivot)
ax = pivot[["Not Fused", "Fused"]].plot(
logx=True,
logy=True,
title=(
f"Not Fused/Fused implementation for Transpose + "
f"Cast on CUDA\nitype={itype}"
),
)
ax.get_figure().savefig("plot_op_transpose_2d_cast_cuda.png")
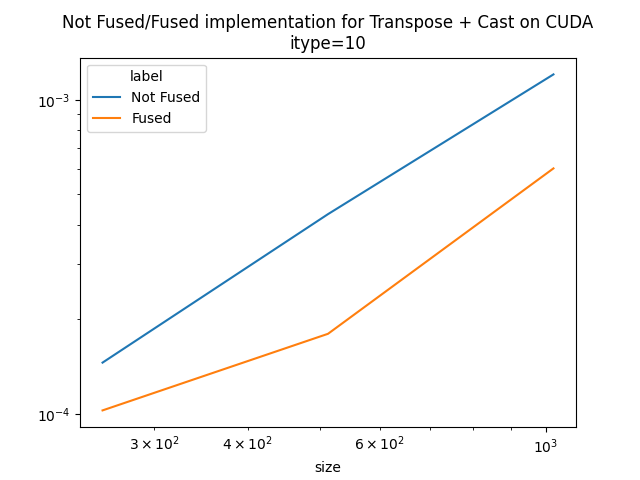
label Fused Not Fused ratio
size
256 0.000074 0.000388 5.255936
512 0.000122 0.000167 1.368403
1024 0.000160 0.001154 7.231917
It seems worth it to combine both operators.
Total running time of the script: (0 minutes 0.552 seconds)