Note
Go to the end to download the full example code.
Evaluating random access for sparse¶
Whenever computing the prediction of a tree with a sparse tensor, is it faster to density first and then to compute the prediction or to keep the tensor in its sparse representation and do look up? The parameter nrnd can be seen as the depth of a tree.
import itertools
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from pandas import DataFrame
from onnx_extended.ext_test_case import unit_test_going
from onnx_extended.args import get_parsed_args
from onnx_extended.validation.cpu._validation import evaluate_sparse
expose = "repeat,warmup,nrows,ncols,sparsity,nrnd,ntimes"
script_args = get_parsed_args(
"plot_bench_sparse_access",
description=__doc__,
nrows=(10 if unit_test_going() else 100, "number of rows"),
ncols=(10 if unit_test_going() else 100000, "number of columns"),
ntimes=(
"1" if unit_test_going() else "2,4,8",
"number of times to do nrnd random accesses per row",
),
sparsity=(
"0.1,0.2" if unit_test_going() else "0.75,0.8,0.9,0.95,0.99,0.999,0.9999",
"sparsities to try",
),
repeat=2 if unit_test_going() else 5,
warmup=1 if unit_test_going() else 3,
nrnd=(10, "number of random features to access"),
expose=expose,
)
for att in sorted(expose.split(",")):
print(f"{att}={getattr(script_args, att)}")
ncols=100000
nrnd=10
nrows=100
ntimes=2,4,8
repeat=5
sparsity=0.75,0.8,0.9,0.95,0.99,0.999,0.9999
warmup=3
Sparse tensor¶
def make_sparse_random_tensor(n_rows: int, n_cols: int, sparsity: float):
t = np.random.rand(n_rows, n_cols).astype(np.float32)
m = np.random.rand(n_rows, n_cols).astype(np.float32)
t[m <= sparsity] = 0
return t
sparsity = list(map(float, script_args.sparsity.split(",")))
ntimes = list(map(int, script_args.ntimes.split(",")))
t = make_sparse_random_tensor(script_args.nrows, script_args.ncols, sparsity[0])
ev = evaluate_sparse(t, script_args.nrnd, ntimes[0], script_args.repeat, 3)
print(f"dense: initialization:{ev[0][0]:1.3g}")
print(f" access:{ev[0][1]:1.3g}")
print(f"sparse: initialization:{ev[1][0]:1.3g}")
print(f" access:{ev[1][1]:1.3g}")
print(f"Ratio sparse/dense: {ev[1][1] / ev[0][1]}")
dense: initialization:0.0106
access:3.19e-05
sparse: initialization:0.00603
access:0.000464
Ratio sparse/dense: 14.577338942609567
If > 1, sparse is slower.
Try sparsity¶
tries = list(itertools.product(ntimes, sparsity))
data = []
for nt, sp in tqdm(tries):
t = make_sparse_random_tensor(script_args.nrows, script_args.ncols, sp)
ev = evaluate_sparse(t, script_args.nrnd, nt, script_args.repeat, 3)
obs = dict(
dense0=ev[0][0],
dense1=ev[0][1],
dense=ev[0][0] + ev[0][1],
sparse0=ev[1][0],
sparse1=ev[1][1],
sparse=ev[1][0] + ev[1][1],
sparsity=sp,
rows=t.shape[0],
cols=t.shape[1],
repeat=script_args.repeat,
random=script_args.nrnd,
ntimes=nt,
)
data.append(obs)
df = DataFrame(data)
print(df)
0%| | 0/21 [00:00<?, ?it/s]
5%|▍ | 1/21 [00:00<00:07, 2.76it/s]
10%|▉ | 2/21 [00:00<00:06, 2.99it/s]
14%|█▍ | 3/21 [00:00<00:05, 3.32it/s]
19%|█▉ | 4/21 [00:01<00:04, 3.65it/s]
24%|██▍ | 5/21 [00:01<00:04, 3.89it/s]
29%|██▊ | 6/21 [00:01<00:03, 4.20it/s]
33%|███▎ | 7/21 [00:01<00:03, 4.47it/s]
38%|███▊ | 8/21 [00:02<00:03, 3.58it/s]
43%|████▎ | 9/21 [00:02<00:03, 3.32it/s]
48%|████▊ | 10/21 [00:02<00:03, 3.44it/s]
52%|█████▏ | 11/21 [00:03<00:02, 3.62it/s]
57%|█████▋ | 12/21 [00:03<00:02, 3.83it/s]
62%|██████▏ | 13/21 [00:03<00:01, 4.13it/s]
67%|██████▋ | 14/21 [00:03<00:01, 4.11it/s]
71%|███████▏ | 15/21 [00:04<00:01, 3.57it/s]
76%|███████▌ | 16/21 [00:04<00:01, 3.30it/s]
81%|████████ | 17/21 [00:04<00:01, 3.32it/s]
86%|████████▌ | 18/21 [00:04<00:00, 3.47it/s]
90%|█████████ | 19/21 [00:05<00:00, 3.76it/s]
95%|█████████▌| 20/21 [00:05<00:00, 3.99it/s]
100%|██████████| 21/21 [00:05<00:00, 4.21it/s]
100%|██████████| 21/21 [00:05<00:00, 3.73it/s]
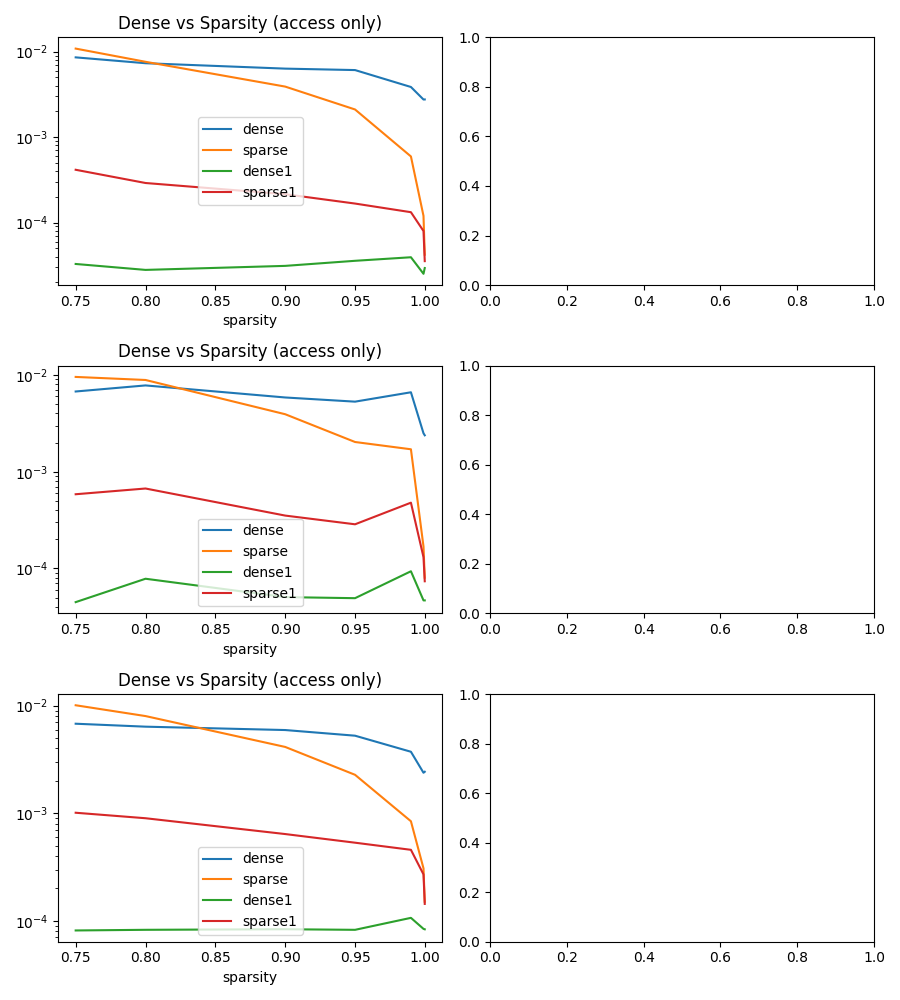
dense0 dense1 dense sparse0 sparse1 sparse sparsity rows cols repeat random ntimes
0 0.010098 0.000030 0.010128 0.005731 0.000393 0.006124 0.7500 100 100000 5 10 2
1 0.011091 0.000031 0.011123 0.004255 0.000320 0.004575 0.8000 100 100000 5 10 2
2 0.009296 0.000032 0.009327 0.002002 0.000219 0.002221 0.9000 100 100000 5 10 2
3 0.008728 0.000027 0.008755 0.000890 0.000164 0.001053 0.9500 100 100000 5 10 2
4 0.007255 0.000031 0.007286 0.000201 0.000129 0.000330 0.9900 100 100000 5 10 2
5 0.005834 0.000017 0.005850 0.000033 0.000074 0.000107 0.9990 100 100000 5 10 2
6 0.006017 0.000018 0.006035 0.000004 0.000042 0.000046 0.9999 100 100000 5 10 2
7 0.016828 0.000064 0.016892 0.006667 0.000901 0.007568 0.7500 100 100000 5 10 4
8 0.010308 0.000089 0.010397 0.005080 0.000709 0.005789 0.8000 100 100000 5 10 4
9 0.009168 0.000042 0.009210 0.002148 0.000498 0.002646 0.9000 100 100000 5 10 4
10 0.009281 0.000053 0.009335 0.001016 0.000336 0.001353 0.9500 100 100000 5 10 4
11 0.007513 0.000071 0.007585 0.000227 0.000308 0.000535 0.9900 100 100000 5 10 4
12 0.006701 0.000040 0.006741 0.000023 0.000165 0.000187 0.9990 100 100000 5 10 4
13 0.007248 0.000046 0.007294 0.000006 0.000111 0.000117 0.9999 100 100000 5 10 4
14 0.014905 0.000095 0.015000 0.005350 0.001326 0.006677 0.7500 100 100000 5 10 8
15 0.010594 0.000110 0.010704 0.003999 0.001050 0.005049 0.8000 100 100000 5 10 8
16 0.010837 0.000184 0.011021 0.002067 0.000817 0.002884 0.9000 100 100000 5 10 8
17 0.009065 0.000079 0.009144 0.001006 0.000725 0.001731 0.9500 100 100000 5 10 8
18 0.007229 0.000074 0.007304 0.000205 0.000491 0.000697 0.9900 100 100000 5 10 8
19 0.006437 0.000079 0.006516 0.000023 0.000322 0.000345 0.9990 100 100000 5 10 8
20 0.006487 0.000066 0.006554 0.000004 0.000170 0.000174 0.9999 100 100000 5 10 8
Plots
nts = list(sorted(set(df.ntimes)))
fig, ax = plt.subplots(len(nts), 2, figsize=(3 * len(nts), 10))
for i, nt in enumerate(nts):
sub = df[df.ntimes == nt]
sub[["sparsity", "dense", "sparse"]].set_index("sparsity").plot(
title=f"Dense vs Sparsity, ntimes={nt}",
logy=True,
ax=ax[0] if len(ax.shape) == 1 else ax[i, 0],
)
sub[["sparsity", "dense1", "sparse1"]].set_index("sparsity").plot(
title="Dense vs Sparsity (access only)",
logy=True,
ax=ax[1] if len(ax.shape) == 1 else ax[i, 0],
)
fig.tight_layout()
fig.savefig("plot_bench_sparse_access.png")
Total running time of the script: (0 minutes 7.214 seconds)