mlinsights.timeseries¶
Datasets¶
- mlinsights.timeseries.datasets.artificial_data(dt1, dt2, minutes=1)[source]¶
Generates articial data every minutes.
- Parameters:
dt1 – first date
dt2 – second date
minutes – interval between two observations
- Returns:
dataframe
<<<
import datetime from mlinsights.timeseries.datasets import artificial_data now = datetime.datetime.now() data = artificial_data(now - datetime.timedelta(40), now) print(data.head())
>>>
time y 0 2025-10-25 10:30:59.424746 2.303976 1 2025-10-25 10:31:59.424746 2.480810 2 2025-10-25 10:32:59.424746 2.398172 3 2025-10-25 10:33:59.424746 2.350040 4 2025-10-25 10:34:59.424746 2.391244
Experimentation¶
- mlinsights.timeseries.patterns.find_ts_group_pattern(ttime, values, names, name_subset=None, per='week', unit='half-hour', agg='sum', estimator=None, verbose=0)[source]¶
Clusters times series to find similar patterns.
- Parameters:
ttime – time column
values – features to use to cluster
names – column which holds group name
name_subset – subset of groups to study, None for all
per – aggragation per week
unit – unit
agg – aggregation function
estimator – estimator used to find pattern,
sklearn.cluster.KMeansand 10 groupsverbose – verbosity
- Returns:
found clusters, distances
Manipulation¶
- mlinsights.timeseries.agg.aggregate_timeseries(df, index='time', values='y', unit='half-hour', agg='sum', per=None)[source]¶
Aggregates timeseries assuming the data is in a dataframe.
@param df dataframe @param index time column @param values value or values column @param unit aggregate over a specific period @param sum kind of aggregation @param per second aggregation, per week… @return aggregated values
Plotting¶
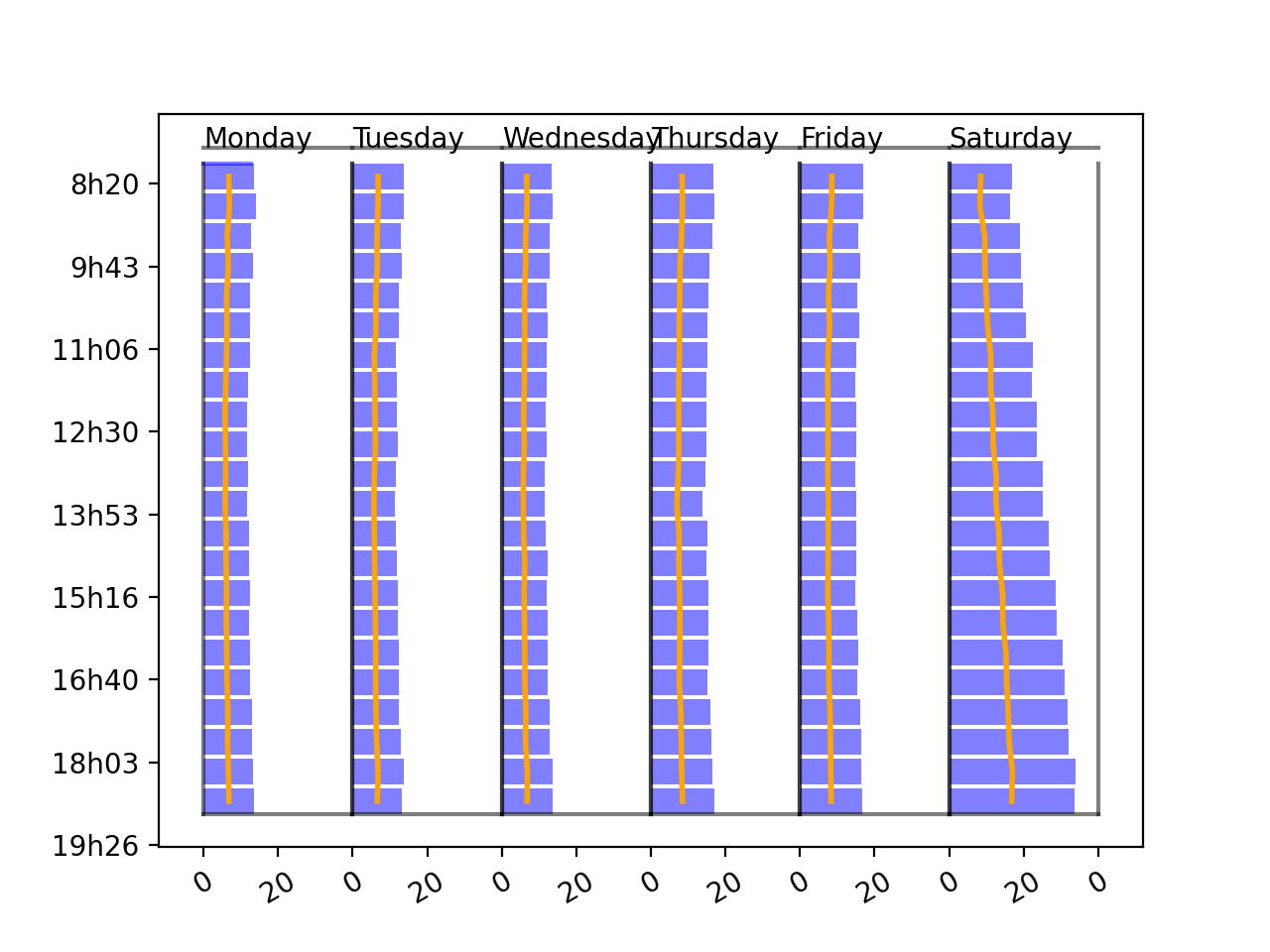
- mlinsights.timeseries.plotting.plot_week_timeseries(time, value, normalise=True, label=None, h=0.85, value2=None, label2=None, daynames=None, xfmt='%1.0f', ax=None)[source]¶
Shows a timeseries dispatched by days as bars.
- Parameters:
time – dates
value – values to display as bars.
normalise – normalise data before showing it
label – label of the series
h – scale factor
value2 – second series to show as a line
label2 – label of the second series
daynames – names to use for week day names (default is English)
xfmt – format number of the X axis
ax – existing axis
- Returns:
axis
(
Source code,png,hires.png,pdf)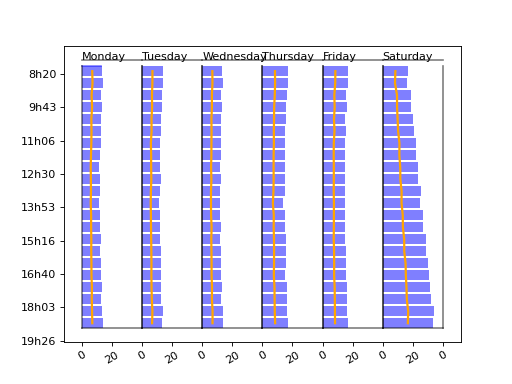
{kind=link}
{kind=link}
Prediction¶
BaseReciprocalTimeSeriesTransformer¶
The following function builds a regular dataset from a timeseries so that it can be used by machine learning models.
- class mlinsights.timeseries.base.BaseReciprocalTimeSeriesTransformer(context_length=0)[source]¶
Base for all timeseries preprocessing automatically applied within a predictor.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BaseReciprocalTimeSeriesTransformer¶
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
Returns¶
- selfobject
The updated object.
- set_transform_request(*, context: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') BaseReciprocalTimeSeriesTransformer¶
Configure whether metadata should be requested to be passed to the
transformmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- contextstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
contextparameter intransform.- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter intransform.
Returns¶
- selfobject
The updated object.
build_ts_X_y¶
- mlinsights.timeseries.utils.build_ts_X_y(model, X, y, weights=None, same_rows=False)[source]¶
Builds standard X, y based in the given one.
- Parameters:
model – a timeseries model (
BaseTimeSeries)X – times series, used as features, [n_obs, n_features], X may be empty (None)
y – timeseries (one single vector), [n_obs]
weights – weights None or array [n_obs]
same_rows – keeps the same number of rows as the original datasets, use nan when no value is available
- Returns:
(X, y, weights): X is array of features [nrows, n_features + past] where nrows = n_obs + model.delay2 - model.past + 2, y is an array of targets [nrows], weights is None or array [nrows]
<<<
import numpy from mlinsights.timeseries import build_ts_X_y from mlinsights.timeseries.base import BaseTimeSeries X = numpy.arange(10).reshape(5, 2) y = numpy.arange(5) * 100 weights = numpy.arange(5) * 1000 bs = BaseTimeSeries(past=2) nx, ny, nw = build_ts_X_y(bs, X, y, weights) print("X=", X) print("y=", y) print("nx=", nx) print("ny=", ny)
>>>
X= [[0 1] [2 3] [4 5] [6 7] [8 9]] y= [ 0 100 200 300 400] nx= [[ 2 3 0 100] [ 4 5 100 200] [ 6 7 200 300]] ny= [[200] [300] [400]]
With
use_all_past=True:<<<
import numpy from mlinsights.timeseries.base import BaseTimeSeries from mlinsights.timeseries import build_ts_X_y X = numpy.arange(10).reshape(5, 2) y = numpy.arange(5) * 100 weights = numpy.arange(5) * 1000 bs = BaseTimeSeries(past=2, use_all_past=True) nx, ny, nw = build_ts_X_y(bs, X, y, weights) print("X=", X) print("y=", y) print("nx=", nx) print("ny=", ny)
>>>
X= [[0 1] [2 3] [4 5] [6 7] [8 9]] y= [ 0 100 200 300 400] nx= [[ 0 1 2 3 0 100] [ 2 3 4 5 100 200] [ 4 5 6 7 200 300]] ny= [[200] [300] [400]]
BaseTimeSeries¶
The first class defined the template for all timeseries estimators. It deals with a timeseries ine one dimension and additional features.
- class mlinsights.timeseries.base.BaseTimeSeries(past=1, delay1=1, delay2=2, use_all_past=False, preprocessing=None)[source]¶
Base class to build a predictor on timeseries. The class computes one or several predictions at each time, between delay1 and delay2. It computes:
 with d in [delay1, delay2[ and
with d in [delay1, delay2[ and
 .
.- Parameters:
past – values to use to predict
delay1 – the model computes the first prediction for time=t + delay1
delay2 – the model computes the last prediction for time=t + delay2 excluded
use_all_past – use all past features, not only the timeseries
preprocessing – preprocessing to apply before predicting, only the timeseries itselves, it can be a difference, it must be of type
BaseReciprocalTimeSeriesTransformer
DummyTimeSeriesRegressor¶
The first predictor is a dummy one: it uses the current value to predict the future.
- class mlinsights.timeseries.dummies.DummyTimeSeriesRegressor(estimator='dummy', past=1, delay1=1, delay2=2, use_all_past=False, preprocessing=None)[source]¶
Dummy regressor for time series. Use past values as prediction.
- Parameters:
estimator – estimator to use for regression,
sklearn.linear_model.LinearRegressionimplements a linear auto-regressor,'dummy'use past value as predictionspast – values to use to predict
delay1 – the model computes the first prediction for time=t + delay1
delay2 – the model computes the last prediction for time=t + delay2 excluded
use_all_past – use all past features, not only the timeseries
preprocessing – preprocessing to apply before predicting, only the timeseries itselves, it can be a difference, it must be of type
BaseReciprocalTimeSeriesTransformer
- fit(X, y, sample_weight=None)[source]¶
Trains the model.
- Parameters:
X – output of X may be empty (None)
y – timeseries (one single vector), array [n_obs]
sample_weight – weights None or array [n_obs]
- Returns:
self
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DummyTimeSeriesRegressor¶
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
Returns¶
- selfobject
The updated object.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DummyTimeSeriesRegressor¶
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
Returns¶
- selfobject
The updated object.
ARTimeSeriesRegressor¶
The first regressor is an auto-regressor. It can be estimated with any regressor implemented in scikit-learn.
- class mlinsights.timeseries.ar.ARTimeSeriesRegressor(estimator='dummy', past=1, delay1=1, delay2=2, use_all_past=False, preprocessing=None)[source]¶
Base class to build a regressor on timeseries. The class computes one or several predictions at each time, between delay1 and delay2. It computes:
with d in [delay1, delay2[ and
.- Parameters:
estimator – estimator to use for regression,
sklearn.linear_model.LinearRegressionimplements a linear auto-regressor,'dummy'use past value as predictionspast – values to use to predict
delay1 – the model computes the first prediction for time=t + delay1
delay2 – the model computes the last prediction for time=t + delay2 excluded
use_all_past – use all past features, not only the timeseries
preprocessing – preprocessing to apply before predicting, only the timeseries itselves, it can be a difference, it must be of type
BaseReciprocalTimeSeriesTransformer
- fit(X, y, sample_weight=None)[source]¶
Trains the model.
- Parameters:
X – output of X may be empty (None)
y – timeseries (one single vector), array [n_obs]
sample_weight – weights None or array [n_obs]
- Returns:
self
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ARTimeSeriesRegressor¶
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
Returns¶
- selfobject
The updated object.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ARTimeSeriesRegressor¶
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Parameters¶
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
Returns¶
- selfobject
The updated object.
ts_mape¶
The library implements one scoring function which compares the prediction to what a dummy predictor would do by using the previous day as a prediction.
- mlinsights.timeseries.metrics.ts_mape(expected_y, predicted_y, sample_weight=None)[source]¶
Computes
 .
It compares the prediction to what a dummy
predictor would do by using the previous day
as a prediction.
.
It compares the prediction to what a dummy
predictor would do by using the previous day
as a prediction.- Parameters:
expected_y – expected values
predicted_y – predictions
sample_weight – sample weight
- Returns:
metrics