Note
Go to the end to download the full example code
Compares implementations of Einsum#
This example compares different equations for function numpy.einsum().
It compares numpy implementation to a custom implementation,
onnxruntime implementation and opt-einsum optimisation.
If available, tensorflow and pytorch are included as well.
The custom implementation does not do any transpose.
It uses parallelisation and SIMD optimization when the summation
happens on the last axis of both matrices. It only implements
matrix multiplication. We also measure the improvment made with
function einsum.
Available optimisation#
The code shows which optimisation is used for the custom implementation, AVX or SSE and the number of available processors, equal to the default number of used threads to parallelize.
import logging
import numpy
import pandas
import matplotlib.pyplot as plt
from onnx import TensorProto
from onnx.helper import (
make_model,
make_graph,
make_node,
make_tensor_value_info,
make_opsetid,
)
from onnxruntime import InferenceSession
from onnx_extended.ext_test_case import measure_time, unit_test_going
from tqdm import tqdm
from opt_einsum import contract
from onnx_extended.tools.einsum.einsum_fct import _einsum
logging.getLogger("matplotlib.font_manager").setLevel(logging.ERROR)
logging.getLogger("matplotlib.ticker").setLevel(logging.ERROR)
logging.getLogger("PIL.PngImagePlugin").setLevel(logging.ERROR)
logging.getLogger("onnx-extended").setLevel(logging.ERROR)
Einsum: common code#
try:
from tensorflow import einsum as tf_einsum, convert_to_tensor
except ImportError:
tf_einsum = None
try:
from torch import einsum as torch_einsum, from_numpy
except ImportError:
torch_einsum = None
def build_ort_einsum(equation, op_version=18): # opset=13, 14, ...
onx = make_model(
make_graph(
[make_node("Einsum", ["x", "y"], ["z"], equation=equation)],
equation,
[
make_tensor_value_info("x", TensorProto.FLOAT, None),
make_tensor_value_info("y", TensorProto.FLOAT, None),
],
[make_tensor_value_info("z", TensorProto.FLOAT, None)],
),
opset_imports=[make_opsetid("", op_version)],
)
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
return lambda x, y: sess.run(None, {"x": x, "y": y})
def build_ort_decomposed(equation, op_version=18): # opset=13, 14, ...
cache = _einsum(
equation,
numpy.float32,
opset=op_version,
optimize=True,
verbose=True,
runtime="python",
)
if not hasattr(cache, "onnx_"):
cache.build()
sess = InferenceSession(
cache.onnx_.SerializeToString(), providers=["CPUExecutionProvider"]
)
return lambda x, y: sess.run(None, {"X0": x, "X1": y})
def loop_einsum_eq(fct, equation, xs, ys):
for x, y in zip(xs, ys):
fct(equation, x, y)
def loop_einsum_eq_th(fct, equation, xs, ys):
for x, y in zip(xs, ys):
fct(equation, x, y, nthread=-1)
def loop_einsum(fct, xs, ys):
for x, y in zip(xs, ys):
fct(x, y)
def timeit(stmt, ctx, dim, name):
obs = measure_time(stmt, div_by_number=True, context=ctx, repeat=5, number=1)
obs["dim"] = dim
obs["fct"] = name
return obs
def benchmark_equation(equation):
# equations
ort_einsum = build_ort_einsum(equation)
ort_einsum_decomposed = build_ort_decomposed(equation)
res = []
for dim in tqdm([8, 16, 32, 64, 100, 128, 200, 256]): # , 500, 512]):
if unit_test_going() and dim > 64:
break
xs = [numpy.random.rand(2, dim, 12, 64).astype(numpy.float32) for _ in range(5)]
ys = [numpy.random.rand(2, dim, 12, 64).astype(numpy.float32) for _ in range(5)]
# numpy
ctx = dict(
equation=equation,
xs=xs,
ys=ys,
einsum=numpy.einsum,
loop_einsum=loop_einsum,
loop_einsum_eq=loop_einsum_eq,
loop_einsum_eq_th=loop_einsum_eq_th,
)
obs = timeit(
"loop_einsum_eq(einsum, equation, xs, ys)", ctx, dim, "numpy.einsum"
)
res.append(obs)
# opt-einsum
ctx["einsum"] = contract
obs = timeit("loop_einsum_eq(einsum, equation, xs, ys)", ctx, dim, "opt-einsum")
res.append(obs)
# onnxruntime
ctx["einsum"] = ort_einsum
obs = timeit("loop_einsum(einsum, xs, ys)", ctx, dim, "ort-einsum")
res.append(obs)
# onnxruntime decomposed
ctx["einsum"] = ort_einsum_decomposed
obs = timeit("loop_einsum(einsum, xs, ys)", ctx, dim, "ort-dec")
res.append(obs)
if tf_einsum is not None:
# tensorflow
ctx["einsum"] = tf_einsum
ctx["xs"] = [convert_to_tensor(x) for x in xs]
ctx["ys"] = [convert_to_tensor(y) for y in ys]
obs = timeit(
"loop_einsum_eq(einsum, equation, xs, ys)", ctx, dim, "tf-einsum"
)
res.append(obs)
if torch_einsum is not None:
# torch
ctx["einsum"] = torch_einsum
ctx["xs"] = [from_numpy(x) for x in xs]
ctx["ys"] = [from_numpy(y) for y in ys]
obs = timeit(
"loop_einsum_eq(einsum, equation, xs, ys)", ctx, dim, "torch-einsum"
)
res.append(obs)
# Dataframes
df = pandas.DataFrame(res)
piv = df.pivot(index="dim", columns="fct", values="average")
rs = piv.copy()
for c in ["ort-einsum", "ort-dec", "tf-einsum", "torch-einsum", "opt-einsum"]:
if c not in rs.columns:
continue
rs[c] = rs["numpy.einsum"] / rs[c]
rs["numpy.einsum"] = 1.0
# Graphs.
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
piv.plot(
logx=True,
logy=True,
ax=ax[0],
title=f"Einsum benchmark\n{equation} -- (2, N, 12, 64) lower better",
)
ax[0].legend(prop={"size": 9})
rs.plot(
logx=True,
logy=True,
ax=ax[1],
title="Einsum Speedup, baseline=numpy\n%s -- (2, N, 12, 64)"
" higher better" % equation,
)
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], "g--")
ax[1].plot([min(rs.index), max(rs.index)], [2.0, 2.0], "g--")
ax[1].legend(prop={"size": 9})
return df, rs, ax
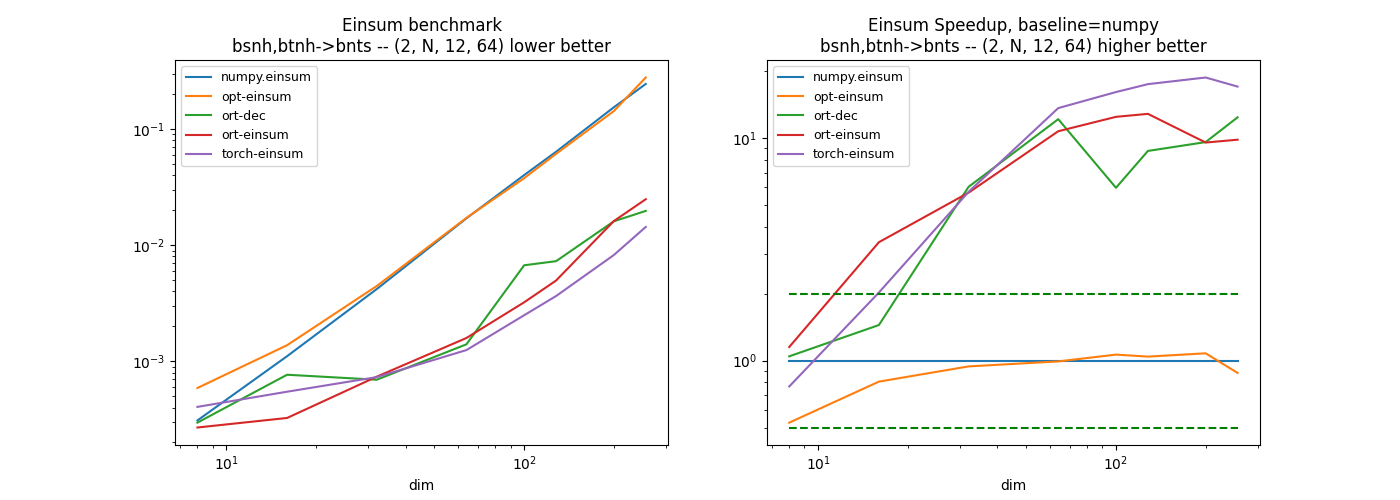
First equation: bsnh,btnh->bnts#
The decomposition of this equation without einsum function gives the following.
![digraph{
orientation=portrait;
ranksep=0.25;
nodesep=0.05;
width=0.5;
height=0.1;
size=5;
node [shape=record];
0 [label="input 0\\nbsnh\\n[ 0 3 2 1 -1]"];
140569353101536 [label="id\\nNone"];
0 -> 140569353101536;
140569353101104 [label="expand_dims\\naxes=((4, 4),)None"];
140569353101536 -> 140569353101104;
1 [label="input 1\\nbtnh\\n[ 0 3 2 -1 1]"];
140569353095008 [label="id\\nNone"];
1 -> 140569353095008;
140569353107056 [label="expand_dims\\naxes=((3, 3),)None"];
140569353095008 -> 140569353107056;
140569353101152 [label="batch_dot\\nbatch_axes=(0, 1) keep_axes=None left=(0, 1, 2) ndim=5 right=(0, 1, 3) sum_axes=(4,)None"];
140569353096880 -> 140569353101152;
140569353108928 -> 140569353101152;
140569353106816 [label="squeeze\\naxes=(1,)None"];
140569353100432 -> 140569353106816;
140569353100192 [label="id - I-1\\nNone" style=filled fillcolor=red];
140569353106816 -> 140569353100192;
140569353096880 [label="transpose - I0\\nperm=(0, 2, 1, 4, 3)None" style=filled fillcolor=red];
140569353101104 -> 140569353096880;
140569353108928 [label="transpose\\nperm=(0, 2, 3, 1, 4)None"];
140569353107056 -> 140569353108928;
140569353100432 [label="transpose - I1\\nperm=(0, 4, 1, 3, 2)None" style=filled fillcolor=red];
140569353101152 -> 140569353100432;
}](../_images/graphviz-f843f49780a3b0710731811e1bdda1c7b750b384.png)
0%| | 0/121 [00:00<?, ?it/s]
0.012 rtbest='bsnh,btnh->bnts': 0%| | 0/121 [00:00<?, ?it/s]
0.012 rtbest='bsnh,btnh->bnts': 2%|▏ | 3/121 [00:00<00:04, 29.41it/s]
0.011 rtbest='bsth,bnth->btns': 2%|▏ | 3/121 [00:00<00:04, 29.41it/s]
0.011 rtbest='bsth,bnth->btns': 7%|▋ | 8/121 [00:00<00:02, 39.19it/s]
0.011 rtbest='bsth,bnth->btns': 12%|█▏ | 15/121 [00:00<00:02, 49.94it/s]
0.011 rtbest='bsth,bnth->btns': 17%|█▋ | 21/121 [00:00<00:01, 51.93it/s]
0.011 rtbest='htnb,hsnb->hnst': 17%|█▋ | 21/121 [00:00<00:01, 51.93it/s]
0.011 rtbest='htnb,hsnb->hnst': 23%|██▎ | 28/121 [00:00<00:01, 57.22it/s]
0.011 rtbest='hntb,hstb->htsn': 23%|██▎ | 28/121 [00:00<00:01, 57.22it/s]
0.011 rtbest='hstb,hntb->htns': 23%|██▎ | 28/121 [00:00<00:01, 57.22it/s]
0.011 rtbest='nshb,nthb->nhts': 23%|██▎ | 28/121 [00:00<00:01, 57.22it/s]
0.011 rtbest='nthb,nshb->nhst': 23%|██▎ | 28/121 [00:00<00:01, 57.22it/s]
0.011 rtbest='nthb,nshb->nhst': 29%|██▉ | 35/121 [00:00<00:01, 61.00it/s]
0.011 rtbest='thsb,tnsb->tsnh': 29%|██▉ | 35/121 [00:00<00:01, 61.00it/s]
0.011 rtbest='thsb,tnsb->tsnh': 36%|███▌ | 43/121 [00:00<00:01, 64.19it/s]
0.011 rtbest='sntb,shtb->sthn': 36%|███▌ | 43/121 [00:00<00:01, 64.19it/s]
0.011 rtbest='tnsb,thsb->tshn': 36%|███▌ | 43/121 [00:00<00:01, 64.19it/s]
0.011 rtbest='tnsb,thsb->tshn': 41%|████▏ | 50/121 [00:00<00:01, 65.57it/s]
0.01 rtbest='htbn,hsbn->hbst': 41%|████▏ | 50/121 [00:00<00:01, 65.57it/s]
0.01 rtbest='htbn,hsbn->hbst': 47%|████▋ | 57/121 [00:00<00:00, 66.84it/s]
0.01 rtbest='htbn,hsbn->hbst': 53%|█████▎ | 64/121 [00:01<00:00, 67.07it/s]
0.01 rtbest='htbn,hsbn->hbst': 59%|█████▊ | 71/121 [00:01<00:00, 67.79it/s]
0.01 rtbest='htbn,hsbn->hbst': 64%|██████▍ | 78/121 [00:01<00:00, 67.14it/s]
0.01 rtbest='sbnh,stnh->sntb': 64%|██████▍ | 78/121 [00:01<00:00, 67.14it/s]
0.01 rtbest='nbhs,nths->nhtb': 64%|██████▍ | 78/121 [00:01<00:00, 67.14it/s]
0.01 rtbest='nbhs,nths->nhtb': 71%|███████ | 86/121 [00:01<00:00, 68.86it/s]
0.01 rtbest='nbht,nsht->nhsb': 71%|███████ | 86/121 [00:01<00:00, 68.86it/s]
0.0097 rtbest='tbhn,tshn->thsb': 71%|███████ | 86/121 [00:01<00:00, 68.86it/s]
0.0095 rtbest='nbts,nhts->nthb': 71%|███████ | 86/121 [00:01<00:00, 68.86it/s]
0.0095 rtbest='nbts,nhts->nthb': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.0095 rtbest='sbnt,shnt->snhb': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.0093 rtbest='tbns,thns->tnhb': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.0093 rtbest='htsn,hbsn->hsbt': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.009 rtbest='hnts,hbts->htbn': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.0088 rtbest='hnst,hbst->hsbn': 78%|███████▊ | 94/121 [00:01<00:00, 71.08it/s]
0.0088 rtbest='hnst,hbst->hsbn': 85%|████████▌ | 103/121 [00:01<00:00, 74.30it/s]
0.0087 rtbest='stnh,sbnh->snbt': 85%|████████▌ | 103/121 [00:01<00:00, 74.30it/s]
0.0087 rtbest='tnsh,tbsh->tsbn': 85%|████████▌ | 103/121 [00:01<00:00, 74.30it/s]
0.0087 rtbest='tnsh,tbsh->tsbn': 93%|█████████▎| 112/121 [00:01<00:00, 78.24it/s]
0.0086 rtbest='tshn,tbhn->thbs': 93%|█████████▎| 112/121 [00:01<00:00, 78.24it/s]
0.0085 rtbest='shtn,sbtn->stbh': 93%|█████████▎| 112/121 [00:01<00:00, 78.24it/s]
0.0085 rtbest='shtn,sbtn->stbh': 100%|██████████| 121/121 [00:01<00:00, 80.53it/s]
0.0085 rtbest='shtn,sbtn->stbh': 100%|██████████| 121/121 [00:01<00:00, 67.22it/s]
0%| | 0/8 [00:00<?, ?it/s]
38%|███▊ | 3/8 [00:00<00:00, 18.99it/s]
62%|██████▎ | 5/8 [00:00<00:00, 4.35it/s]
75%|███████▌ | 6/8 [00:01<00:00, 2.52it/s]
88%|████████▊ | 7/8 [00:03<00:00, 1.18it/s]
100%|██████████| 8/8 [00:07<00:00, 1.59s/it]
100%|██████████| 8/8 [00:07<00:00, 1.07it/s]
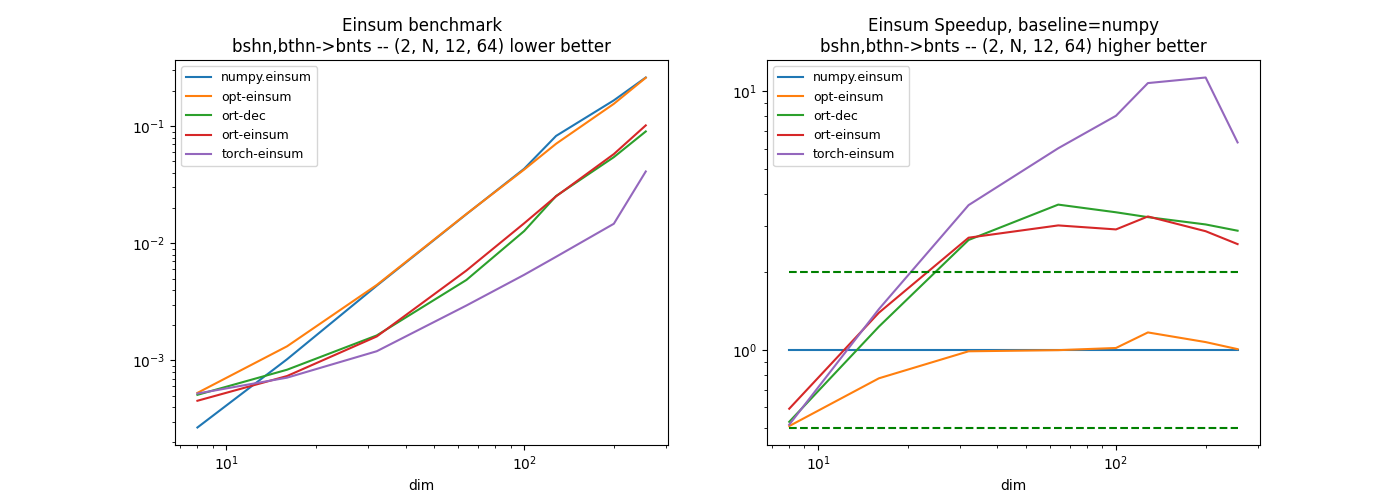
Second equation: bshn,bthn->bnts#
The summation does not happen on the last axis but on the previous one. Is it worth transposing before doing the summation… The decomposition of this equation without einsum function gives the following.
![digraph{
orientation=portrait;
ranksep=0.25;
nodesep=0.05;
width=0.5;
height=0.1;
size=5;
node [shape=record];
0 [label="input 0\\nbshn\\n[ 0 2 3 1 -1]"];
140569353096208 [label="id\\nNone"];
0 -> 140569353096208;
140569353107584 [label="expand_dims\\naxes=((4, 4),)None"];
140569353096208 -> 140569353107584;
1 [label="input 1\\nbthn\\n[ 0 2 3 -1 1]"];
140569353105568 [label="id\\nNone"];
1 -> 140569353105568;
140569353099760 [label="expand_dims\\naxes=((3, 3),)None"];
140569353105568 -> 140569353099760;
140569353101440 [label="batch_dot\\nbatch_axes=(0, 1) keep_axes=None left=(0, 1, 2) ndim=5 right=(0, 1, 3) sum_axes=(4,)None"];
140569353100528 -> 140569353101440;
140569353105280 -> 140569353101440;
140569353108256 [label="squeeze\\naxes=(1,)None"];
140569353105760 -> 140569353108256;
140569353107632 [label="id - I-1\\nNone" style=filled fillcolor=red];
140569353108256 -> 140569353107632;
140569353100528 [label="transpose - I0\\nperm=(0, 3, 1, 4, 2)None" style=filled fillcolor=red];
140569353107584 -> 140569353100528;
140569353105280 [label="transpose\\nperm=(0, 4, 3, 1, 2)None"];
140569353099760 -> 140569353105280;
140569353105760 [label="transpose - I1\\nperm=(0, 4, 1, 3, 2)None" style=filled fillcolor=red];
140569353101440 -> 140569353105760;
}](../_images/graphviz-1e4ddfc60741b6fadb3d268152db683d6325d1ad.png)
0%| | 0/121 [00:00<?, ?it/s]
0.013 rtbest='bshn,bthn->bnts': 0%| | 0/121 [00:00<?, ?it/s]
0.009 rtbest='bshn,bthn->bnts': 0%| | 0/121 [00:00<?, ?it/s]
0.009 rtbest='bshn,bthn->bnts': 6%|▌ | 7/121 [00:00<00:01, 67.10it/s]
0.009 rtbest='bshn,bthn->bnts': 12%|█▏ | 15/121 [00:00<00:01, 73.31it/s]
0.009 rtbest='bshn,bthn->bnts': 19%|█▉ | 23/121 [00:00<00:01, 73.47it/s]
0.009 rtbest='bshn,bthn->bnts': 26%|██▌ | 31/121 [00:00<00:01, 70.19it/s]
0.009 rtbest='bshn,bthn->bnts': 32%|███▏ | 39/121 [00:00<00:01, 70.54it/s]
0.009 rtbest='bshn,bthn->bnts': 39%|███▉ | 47/121 [00:00<00:01, 70.38it/s]
0.009 rtbest='bshn,bthn->bnts': 45%|████▌ | 55/121 [00:00<00:00, 70.71it/s]
0.009 rtbest='bshn,bthn->bnts': 52%|█████▏ | 63/121 [00:00<00:00, 71.71it/s]
0.009 rtbest='bshn,bthn->bnts': 59%|█████▊ | 71/121 [00:00<00:00, 73.68it/s]
0.009 rtbest='hbnt,hsnt->htsb': 59%|█████▊ | 71/121 [00:01<00:00, 73.68it/s]
0.009 rtbest='hbsn,htsn->hntb': 59%|█████▊ | 71/121 [00:01<00:00, 73.68it/s]
0.0089 rtbest='hbts,hnts->hsnb': 59%|█████▊ | 71/121 [00:01<00:00, 73.68it/s]
0.0089 rtbest='nbhs,nths->nstb': 59%|█████▊ | 71/121 [00:01<00:00, 73.68it/s]
0.0089 rtbest='nbhs,nths->nstb': 66%|██████▌ | 80/121 [00:01<00:00, 77.04it/s]
0.0088 rtbest='sbht,snht->stnb': 66%|██████▌ | 80/121 [00:01<00:00, 77.04it/s]
0.0088 rtbest='sbht,snht->stnb': 74%|███████▎ | 89/121 [00:01<00:00, 78.47it/s]
0.0087 rtbest='nbst,nhst->nthb': 74%|███████▎ | 89/121 [00:01<00:00, 78.47it/s]
0.0086 rtbest='nbts,nhts->nshb': 74%|███████▎ | 89/121 [00:01<00:00, 78.47it/s]
0.0086 rtbest='nbts,nhts->nshb': 81%|████████ | 98/121 [00:01<00:00, 80.15it/s]
0.0086 rtbest='htsn,hbsn->hnbt': 81%|████████ | 98/121 [00:01<00:00, 80.15it/s]
0.0086 rtbest='htsn,hbsn->hnbt': 88%|████████▊ | 107/121 [00:01<00:00, 82.41it/s]
0.0086 rtbest='htsn,hbsn->hnbt': 96%|█████████▌| 116/121 [00:01<00:00, 83.26it/s]
0.0086 rtbest='nhts,nbts->nsbh': 96%|█████████▌| 116/121 [00:01<00:00, 83.26it/s]
0.0085 rtbest='shnt,sbnt->stbh': 96%|█████████▌| 116/121 [00:01<00:00, 83.26it/s]
0.0085 rtbest='shnt,sbnt->stbh': 100%|██████████| 121/121 [00:01<00:00, 76.84it/s]
0%| | 0/8 [00:00<?, ?it/s]
38%|███▊ | 3/8 [00:00<00:00, 21.83it/s]
75%|███████▌ | 6/8 [00:02<00:00, 2.10it/s]
88%|████████▊ | 7/8 [00:05<00:00, 1.01it/s]
100%|██████████| 8/8 [00:09<00:00, 1.85s/it]
100%|██████████| 8/8 [00:09<00:00, 1.24s/it]
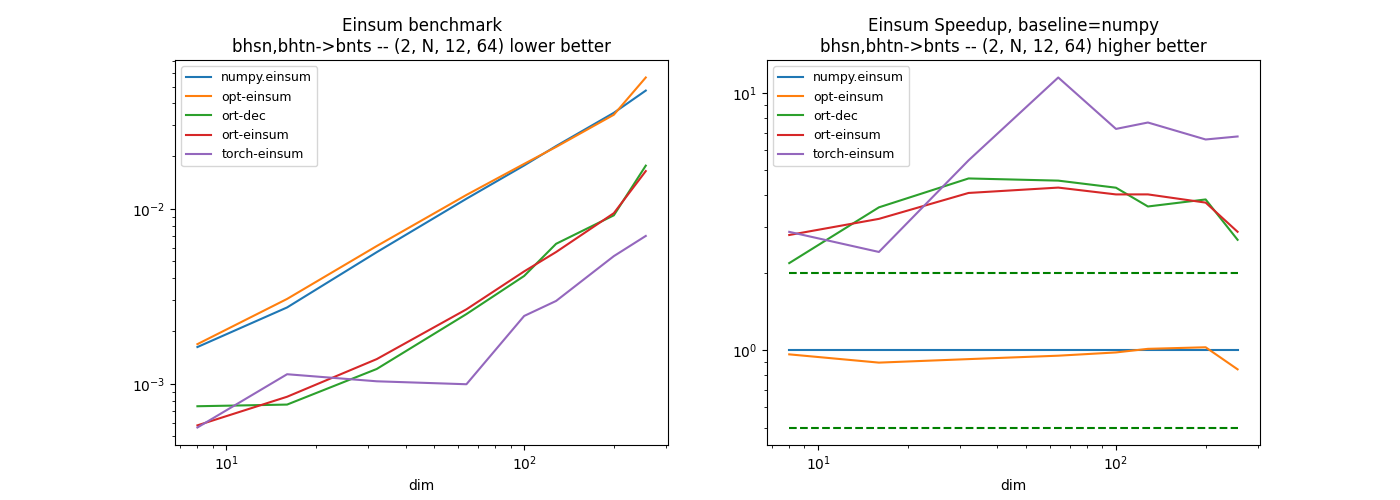
Third equation: bhsn,bhtn->bnts#
The summation does not happen on the last axis but on the second one. It is worth transposing before multiplying. The decomposition of this equation without einsum function gives the following.
![digraph{
orientation=portrait;
ranksep=0.25;
nodesep=0.05;
width=0.5;
height=0.1;
size=5;
node [shape=record];
0 [label="input 0\\nbhsn\\n[ 0 1 3 2 -1]"];
140569353101728 [label="id\\nNone"];
0 -> 140569353101728;
140569353105328 [label="expand_dims\\naxes=((4, 4),)None"];
140569353101728 -> 140569353105328;
1 [label="input 1\\nbhtn\\n[ 0 1 3 -1 2]"];
140569353106000 [label="id\\nNone"];
1 -> 140569353106000;
140569353106384 [label="expand_dims\\naxes=((3, 3),)None"];
140569353106000 -> 140569353106384;
140569353097264 [label="batch_dot\\nbatch_axes=(0, 1) keep_axes=None left=(0, 1, 2) ndim=5 right=(0, 1, 3) sum_axes=(4,)None"];
140569353104224 -> 140569353097264;
140569353102688 -> 140569353097264;
140569353109456 [label="squeeze\\naxes=(1,)None"];
140569353101824 -> 140569353109456;
140569353100288 [label="id - I-1\\nNone" style=filled fillcolor=red];
140569353109456 -> 140569353100288;
140569353104224 [label="transpose - I0\\nperm=(0, 3, 2, 4, 1)None" style=filled fillcolor=red];
140569353105328 -> 140569353104224;
140569353102688 [label="transpose\\nperm=(0, 4, 3, 2, 1)None"];
140569353106384 -> 140569353102688;
140569353101824 [label="transpose - I1\\nperm=(0, 4, 1, 3, 2)None" style=filled fillcolor=red];
140569353097264 -> 140569353101824;
}](../_images/graphviz-cf5502accad81e821f64ba656ea7679d7cb434a4.png)
0%| | 0/121 [00:00<?, ?it/s]
0.013 rtbest='bhsn,bhtn->bnts': 0%| | 0/121 [00:00<?, ?it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 0%| | 0/121 [00:00<?, ?it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 6%|▌ | 7/121 [00:00<00:01, 69.41it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 12%|█▏ | 14/121 [00:00<00:01, 60.02it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 17%|█▋ | 21/121 [00:00<00:01, 63.64it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 23%|██▎ | 28/121 [00:00<00:01, 63.41it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 30%|██▉ | 36/121 [00:00<00:01, 66.50it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 36%|███▋ | 44/121 [00:00<00:01, 68.30it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 42%|████▏ | 51/121 [00:00<00:01, 65.99it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 48%|████▊ | 58/121 [00:00<00:01, 57.52it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 53%|█████▎ | 64/121 [00:01<00:00, 57.49it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 60%|██████ | 73/121 [00:01<00:00, 64.47it/s]
0.0091 rtbest='bhsn,bhtn->bnts': 68%|██████▊ | 82/121 [00:01<00:00, 69.32it/s]
0.009 rtbest='tnbh,tnsh->thsb': 68%|██████▊ | 82/121 [00:01<00:00, 69.32it/s]
0.009 rtbest='tnbh,tnsh->thsb': 75%|███████▌ | 91/121 [00:01<00:00, 73.65it/s]
0.0088 rtbest='nsbt,nsht->nthb': 75%|███████▌ | 91/121 [00:01<00:00, 73.65it/s]
0.0088 rtbest='nsbt,nsht->nthb': 83%|████████▎ | 100/121 [00:01<00:00, 76.34it/s]
0.0087 rtbest='hsnt,hsbt->htbn': 83%|████████▎ | 100/121 [00:01<00:00, 76.34it/s]
0.0084 rtbest='nhst,nhbt->ntbs': 83%|████████▎ | 100/121 [00:01<00:00, 76.34it/s]
0.0084 rtbest='nhst,nhbt->ntbs': 90%|█████████ | 109/121 [00:01<00:00, 79.82it/s]
0.0084 rtbest='nths,ntbs->nsbh': 90%|█████████ | 109/121 [00:01<00:00, 79.82it/s]
0.0084 rtbest='nths,ntbs->nsbh': 98%|█████████▊| 119/121 [00:01<00:00, 83.26it/s]
0.0084 rtbest='nths,ntbs->nsbh': 100%|██████████| 121/121 [00:01<00:00, 70.72it/s]
0%| | 0/8 [00:00<?, ?it/s]
38%|███▊ | 3/8 [00:00<00:00, 15.65it/s]
62%|██████▎ | 5/8 [00:00<00:00, 6.59it/s]
75%|███████▌ | 6/8 [00:01<00:00, 4.74it/s]
88%|████████▊ | 7/8 [00:01<00:00, 3.19it/s]
100%|██████████| 8/8 [00:02<00:00, 2.10it/s]
100%|██████████| 8/8 [00:02<00:00, 3.14it/s]
Conclusion#
pytorch seems quite efficient on these examples. The custom implementation was a way to investigate the implementation of einsum and find some ways to optimize it.
merged = pandas.concat(dfs)
name = "einsum"
merged.to_csv(f"plot_{name}.csv", index=False)
merged.to_excel(f"plot_{name}.xlsx", index=False)
plt.savefig(f"plot_{name}.png")
# plt.show()

Total running time of the script: (0 minutes 26.804 seconds)