Note
Go to the end to download the full example code
Measuring Gemm performance with different input and output tests#
This benchmark looks into various combinations allowed by functions cublasLtMatmul. The tested configurations are available at cuda_gemm.cu.
import pprint
import warnings
from itertools import product
from tqdm import tqdm
import matplotlib.pyplot as plt
from pandas import DataFrame
from onnx_extended.args import get_parsed_args
from onnx_extended.ext_test_case import unit_test_going
try:
from onnx_extended.validation.cuda.cuda_example_py import (
gemm_benchmark_test,
get_device_prop,
)
has_cuda = True
except ImportError:
# CUDA not available.
has_cuda = False
gemm_benchmark_test = None
if has_cuda:
prop = get_device_prop()
if prop["major"] <= 0:
# No CUDA.
dtests, ddims = "", ""
elif prop["major"] < 7:
# No float 8.
dtests, ddims = "0,1,2,3,4,15", "16,32,64,64x128x92"
elif prop["major"] < 9: # T100, A100
# No float 8.
dtests, ddims = (
"0,1,2,3,4,15",
"16,32,64,128,256,512,1024,2048,4096,8192,"
"128x768x768,128x3072x768,128x768x3072",
)
else:
dtests, ddims = (
"0,1,2,3,4,5,6,7,11,14,15",
"16,32,64,128,256,512,1024,2048,4096,8192,16384,"
"128x768x768,128x3072x768,128x768x3072",
)
else:
dtests, ddims = "", ""
script_args = get_parsed_args(
"plot_bench_gemm_f8",
description=__doc__,
dims=(
"16,32" if unit_test_going() else ddims,
"square matrix dimensions to try, comma separated values",
),
tests=(
"0,1,2" if unit_test_going() else dtests,
"configuration to check, see cuda_gemm.cu",
),
warmup=2 if unit_test_going() else 5,
repeat=2 if unit_test_going() else 10,
expose="repeat,warmup",
)
Device#
if has_cuda:
prop = get_device_prop()
pprint.pprint(prop)
else:
print("CUDA is not available")
prop = dict(major=0)
{'clockRate': 1569000,
'computeMode': 0,
'concurrentKernels': 1,
'isMultiGpuBoard': 0,
'major': 6,
'maxThreadsPerBlock': 1024,
'minor': 1,
'multiProcessorCount': 10,
'name': 'NVIDIA GeForce GTX 1060',
'sharedMemPerBlock': 49152,
'totalConstMem': 65536,
'totalGlobalMem': 6442319872}
Benchmark#
def type2string(dt):
dtests = {
0: "F32",
2: "F16",
14: "BF16",
28: "E4M3",
29: "E5M2",
3: "I8",
10: "I32",
}
return dtests[int(dt)]
dims = []
tests = []
if gemm_benchmark_test is not None:
for d in script_args.dims.split(","):
if "x" in d:
spl = d.split("x")
m, n, k = tuple(int(i) for i in spl)
dims.append((m, n, k))
else:
dims.append(int(d))
tests = list(int(i) for i in script_args.tests.split(","))
pbar = tqdm(list(product(tests, dims)))
obs = []
for test, dim in pbar:
pbar.set_description(f"type={test} dim={dim}")
if test in {8, 9, 10, 12, 13}:
warnings.warn(f"unsupported configuration {test}.")
continue
mdim = dim if isinstance(dim, int) else max(dim)
if mdim < 128:
n, N = script_args.warmup * 8, script_args.repeat * 8
elif mdim < 512:
n, N = script_args.warmup * 4, script_args.repeat * 4
elif mdim < 8192:
n, N = script_args.warmup * 2, script_args.repeat * 2
else:
n, N = script_args.warmup, script_args.repeat
if isinstance(dim, int):
gemm_args = [dim] * 6
else:
m, n, k = dim
lda, ldb, ldd = k, k, k
gemm_args = [m, n, k, lda, ldb, ldd]
# warmup
gemm_benchmark_test(test, N, *gemm_args)
# benchmark
res = gemm_benchmark_test(test, N, *gemm_args)
# better rendering
res["test"] = test
update = {}
for k, v in res.items():
if "type_" in k:
update[k] = type2string(v)
if k.startswith("t-"):
update[k] = res[k] / res["N"]
update["compute_type"] = f"C{int(res['compute_type'])}"
for c in ["N", "m", "n", "k", "lda", "ldb", "ldd"]:
update[c] = int(res[c])
update["~dim"] = (update["k"] * max(update["m"], update["n"])) ** 0.5
update["mnk"] = f"{update['m']}x{update['n']}x{update['k']}"
update["name"] = (
f"{update['type_a']}x{update['type_b']}->"
f"{update['type_d']}{update['compute_type']}"
)
res.update(update)
obs.append(res)
if unit_test_going() and len(obs) > 2:
break
df = DataFrame(obs)
df.to_csv("plot_bench_gemm_f8.csv", index=False)
df.to_excel("plot_bench_gemm_f8.xlsx", index=False)
print(df.head().T)
df.head().T
0%| | 0/24 [00:00<?, ?it/s]
type=0 dim=16: 0%| | 0/24 [00:00<?, ?it/s]
type=0 dim=16: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=0 dim=32: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=0 dim=64: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=0 dim=(64, 128, 92): 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=1 dim=16: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=1 dim=32: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=1 dim=64: 4%|▍ | 1/24 [00:01<00:36, 1.60s/it]
type=1 dim=64: 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=1 dim=(64, 128, 92): 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=2 dim=16: 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=2 dim=32: 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=2 dim=64: 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=2 dim=(64, 128, 92): 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=3 dim=16: 29%|██▉ | 7/24 [00:01<00:03, 5.46it/s]
type=3 dim=16: 54%|█████▍ | 13/24 [00:01<00:00, 11.04it/s]
type=3 dim=32: 54%|█████▍ | 13/24 [00:01<00:00, 11.04it/s]
type=3 dim=64: 54%|█████▍ | 13/24 [00:01<00:00, 11.04it/s]
type=3 dim=(64, 128, 92): 54%|█████▍ | 13/24 [00:01<00:00, 11.04it/s]
type=4 dim=16: 54%|█████▍ | 13/24 [00:02<00:00, 11.04it/s]
type=4 dim=32: 54%|█████▍ | 13/24 [00:02<00:00, 11.04it/s]
type=4 dim=32: 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=4 dim=64: 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=4 dim=(64, 128, 92): 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=15 dim=16: 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=15 dim=32: 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=15 dim=64: 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=15 dim=(64, 128, 92): 75%|███████▌ | 18/24 [00:02<00:00, 13.71it/s]
type=15 dim=(64, 128, 92): 100%|██████████| 24/24 [00:02<00:00, 11.19it/s]
0 1 2 3 4
t-total 0.000058 0.000062 0.000069 0.000064 0.000062
t-clean 0.000001 0.000001 0.000001 0.000001 0.000001
t-gemm_in 0.00001 0.00001 0.000011 0.000011 0.000011
t-setup 0.000006 0.00001 0.00001 0.00001 0.000006
t-stream_create 0.0 0.0 0.0 0.0 0.0
N 80 80 80 40 80
epiloque 1.0 1.0 1.0 1.0 1.0
ldd 16 32 64 92 16
t-workspace_free 0.000003 0.000003 0.000003 0.000003 0.000003
algo 11.0 0.0 0.0 0.0 11.0
t-gemm_sync 0.000048 0.000053 0.000059 0.000054 0.000052
t-stream_destroy 0.000001 0.000002 0.000001 0.000001 0.000002
workspace_size 1048576.0 1048576.0 1048576.0 1048576.0 1048576.0
m 16 32 64 64 16
k 16 32 64 92 16
n 16 32 64 128 16
compute_type C68 C68 C68 C68 C77
lda 16 32 64 92 16
type_a F32 F32 F32 F32 F32
ldb 16 32 64 92 16
t-gemm 0.000017 0.000022 0.000023 0.000022 0.000019
type_b F32 F32 F32 F32 F32
t-workspace_new 0.000003 0.000003 0.000003 0.000003 0.000003
type_d F32 F32 F32 F32 F32
test 0 0 0 0 1
~dim 16.0 32.0 64.0 108.51728 16.0
mnk 16x16x16 32x32x32 64x64x64 64x128x92 16x16x16
name F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C77
Test definition#
name test type_a type_b type_d compute_type
0 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68
1 F16xF16->F16C64 3 F16 F16 F16 C64
2 F32xF32->F32C68 0 F32 F32 F32 C68
3 F32xF32->F32C75 2 F32 F32 F32 C75
4 F32xF32->F32C77 1 F32 F32 F32 C77
5 I8xI8->I32C72 15 I8 I8 I32 C72
Total time and only gemm#
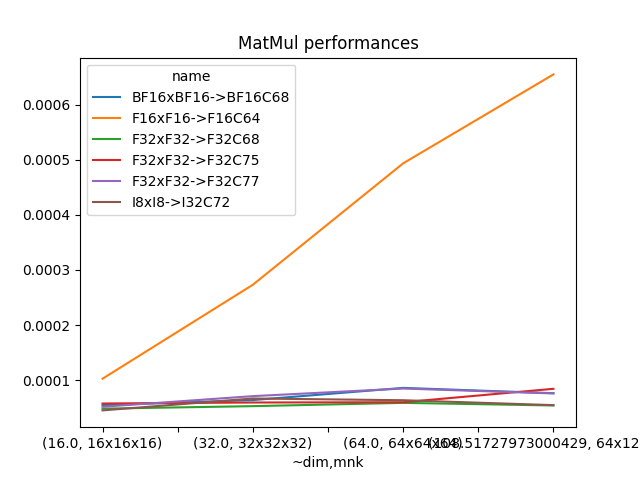
name test type_a type_b type_d compute_type ~dim mnk t-total t-gemm_sync
0 F32xF32->F32C68 0 F32 F32 F32 C68 16.00000 16x16x16 0.000058 0.000048
1 F32xF32->F32C68 0 F32 F32 F32 C68 32.00000 32x32x32 0.000062 0.000053
2 F32xF32->F32C68 0 F32 F32 F32 C68 64.00000 64x64x64 0.000069 0.000059
3 F32xF32->F32C68 0 F32 F32 F32 C68 108.51728 64x128x92 0.000064 0.000054
4 F32xF32->F32C77 1 F32 F32 F32 C77 16.00000 16x16x16 0.000062 0.000052
5 F32xF32->F32C77 1 F32 F32 F32 C77 32.00000 32x32x32 0.000124 0.000071
6 F32xF32->F32C77 1 F32 F32 F32 C77 64.00000 64x64x64 0.000115 0.000085
7 F32xF32->F32C77 1 F32 F32 F32 C77 108.51728 64x128x92 0.000131 0.000076
8 F32xF32->F32C75 2 F32 F32 F32 C75 16.00000 16x16x16 0.000115 0.000058
9 F32xF32->F32C75 2 F32 F32 F32 C75 32.00000 32x32x32 0.000072 0.000059
10 F32xF32->F32C75 2 F32 F32 F32 C75 64.00000 64x64x64 0.000071 0.000060
11 F32xF32->F32C75 2 F32 F32 F32 C75 108.51728 64x128x92 0.000096 0.000084
12 F16xF16->F16C64 3 F16 F16 F16 C64 16.00000 16x16x16 0.000114 0.000103
13 F16xF16->F16C64 3 F16 F16 F16 C64 32.00000 32x32x32 0.000328 0.000273
14 F16xF16->F16C64 3 F16 F16 F16 C64 64.00000 64x64x64 0.000506 0.000494
15 F16xF16->F16C64 3 F16 F16 F16 C64 108.51728 64x128x92 0.000669 0.000655
16 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 16.00000 16x16x16 0.000108 0.000055
17 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 32.00000 32x32x32 0.000075 0.000064
18 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 64.00000 64x64x64 0.000140 0.000086
19 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 108.51728 64x128x92 0.000088 0.000076
20 I8xI8->I32C72 15 I8 I8 I32 C72 16.00000 16x16x16 0.000055 0.000045
21 I8xI8->I32C72 15 I8 I8 I32 C72 32.00000 32x32x32 0.000120 0.000067
22 I8xI8->I32C72 15 I8 I8 I32 C72 64.00000 64x64x64 0.000074 0.000064
23 I8xI8->I32C72 15 I8 I8 I32 C72 108.51728 64x128x92 0.000065 0.000055
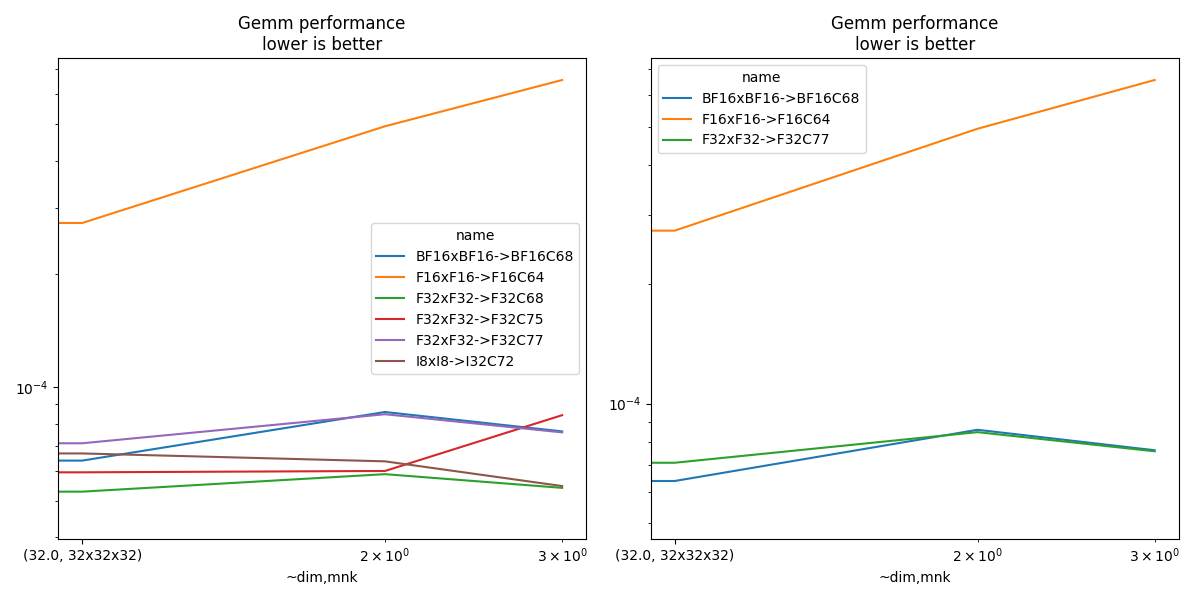
Smaller sets#
if df.shape[0] > 0:
subset = {1, 3, 4, 5, 7}
dfis = dfi[dfi.test.isin(subset)]
print()
print("t-gemm_sync")
pivi = dfis.pivot_table(index=["~dim", "mnk"], columns="name", values="t-gemm_sync")
print(pivi)
print()
print("t-total")
pivi = dfis.pivot_table(index=["~dim", "mnk"], columns="name", values="t-total")
print(pivi)
t-gemm_sync
name BF16xBF16->BF16C68 F16xF16->F16C64 F32xF32->F32C77
~dim mnk
16.00000 16x16x16 0.000055 0.000103 0.000052
32.00000 32x32x32 0.000064 0.000273 0.000071
64.00000 64x64x64 0.000086 0.000494 0.000085
108.51728 64x128x92 0.000076 0.000655 0.000076
t-total
name BF16xBF16->BF16C68 F16xF16->F16C64 F32xF32->F32C77
~dim mnk
16.00000 16x16x16 0.000108 0.000114 0.000062
32.00000 32x32x32 0.000075 0.000328 0.000124
64.00000 64x64x64 0.000140 0.000506 0.000115
108.51728 64x128x92 0.000088 0.000669 0.000131
Plots#
if df.shape[0] > 0:
piv = df.pivot_table(index=["~dim", "mnk"], columns="name", values="t-gemm_sync")
piv.plot(title="MatMul performances")
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
piv.plot(ax=ax[0], title="Gemm performance\nlower is better", logx=True, logy=True)
piv = df[df.test.isin(subset)].pivot_table(
index=["~dim", "mnk"], columns="name", values="t-gemm_sync"
)
if piv.shape[0] > 0:
piv.plot(
ax=ax[1], title="Gemm performance\nlower is better", logx=True, logy=True
)
fig.tight_layout()
fig.savefig("plot_bench_gemm_f8.png")
Total running time of the script: (0 minutes 3.986 seconds)