onnx_extended.plotting#
onnx_extended.plotting.benchmark.hhistograms#
- onnx_extended.plotting.benchmark.hhistograms(df: pandas.DataFrame, keys: str | Tuple[str, ...] = 'name', metric: str = 'average', baseline: str = 'baseline', title: str = 'Benchmark', limit: int = 50, ax=None)[source]#
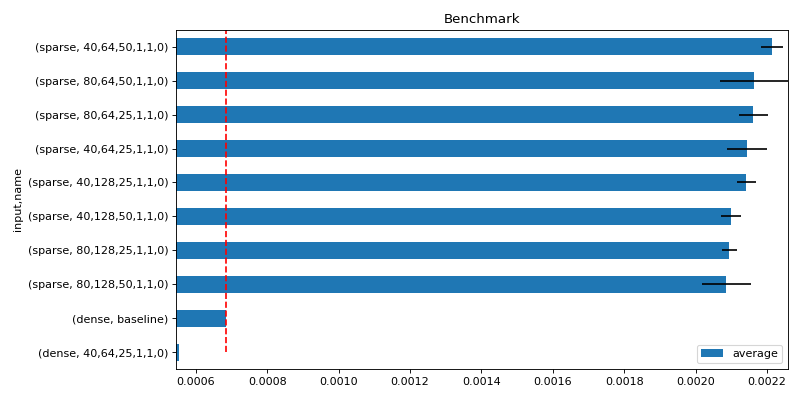
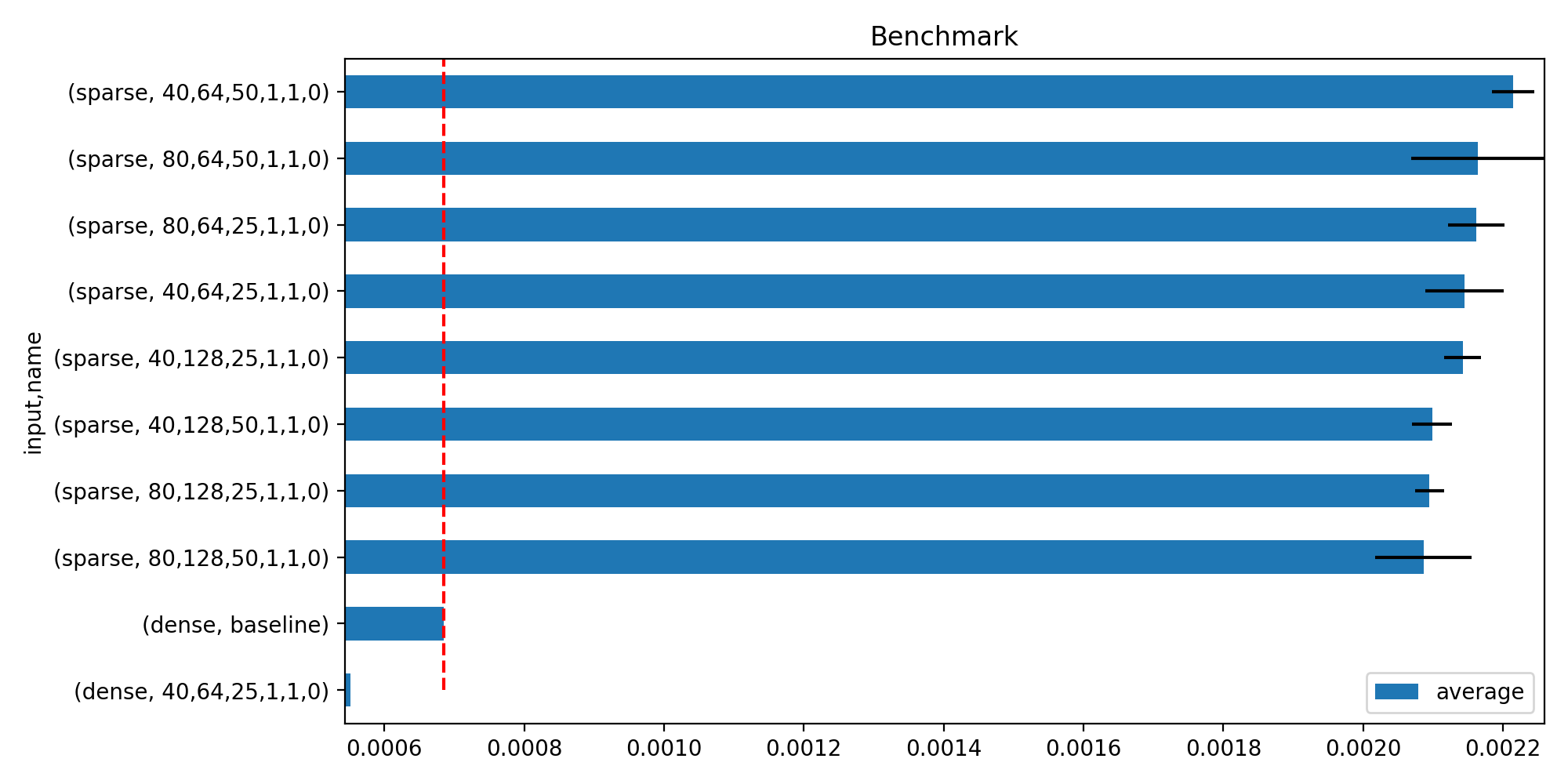
Histograms with error bars. Shows the first best performances.
- Parameters:
df – data
keys – columns to graph by
metric – metric to display
baseline – column keys[-1], no matter what it should be displayed
title – graph title
limit – number of performances to display
ax – existing axes
- Returns:
axes
average deviation min_exec ... batch_size_rows use_node3 input 0 0.002017 0.000149 0.001711 ... 1.0 0.0 sparse 1 0.002074 0.000065 0.001987 ... 1.0 0.0 sparse 2 0.002259 0.000426 0.001774 ... 1.0 0.0 sparse 3 0.002122 0.000065 0.002043 ... 1.0 0.0 sparse 4 0.002127 0.000083 0.001977 ... 1.0 0.0 sparse [5 rows x 21 columns]
(
Source code,png,hires.png,pdf)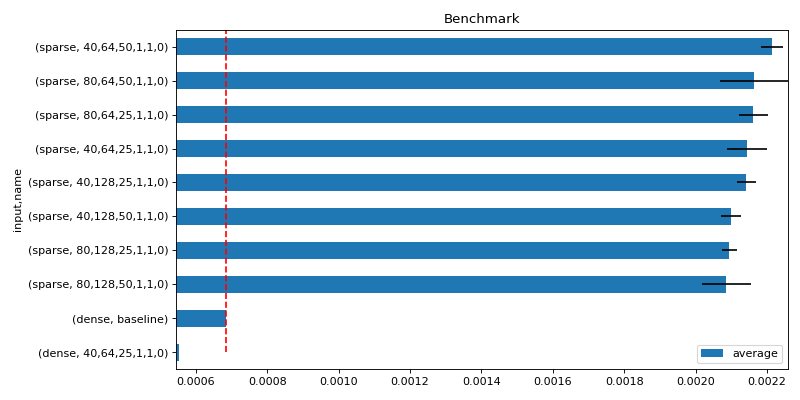
{kind=link}
{kind=link}
onnx_extended.plotting.benchmark.vhistograms#
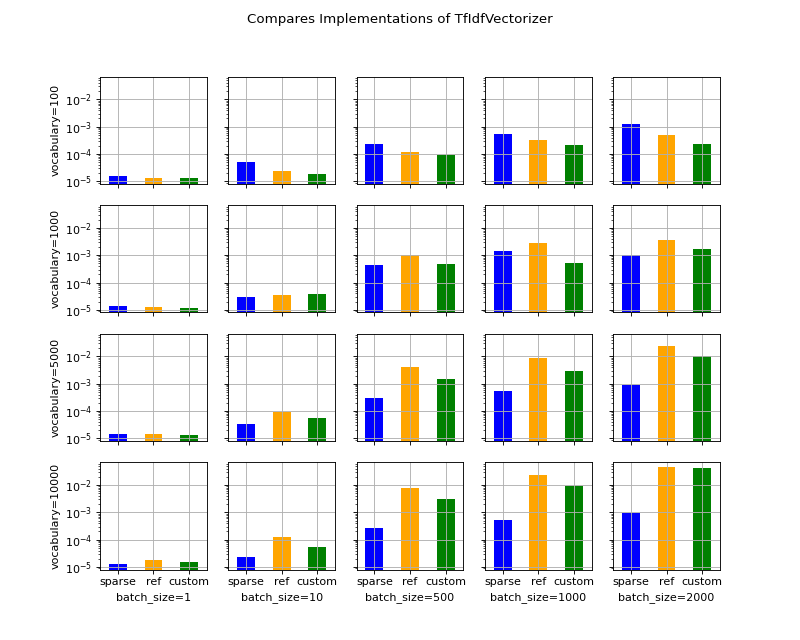
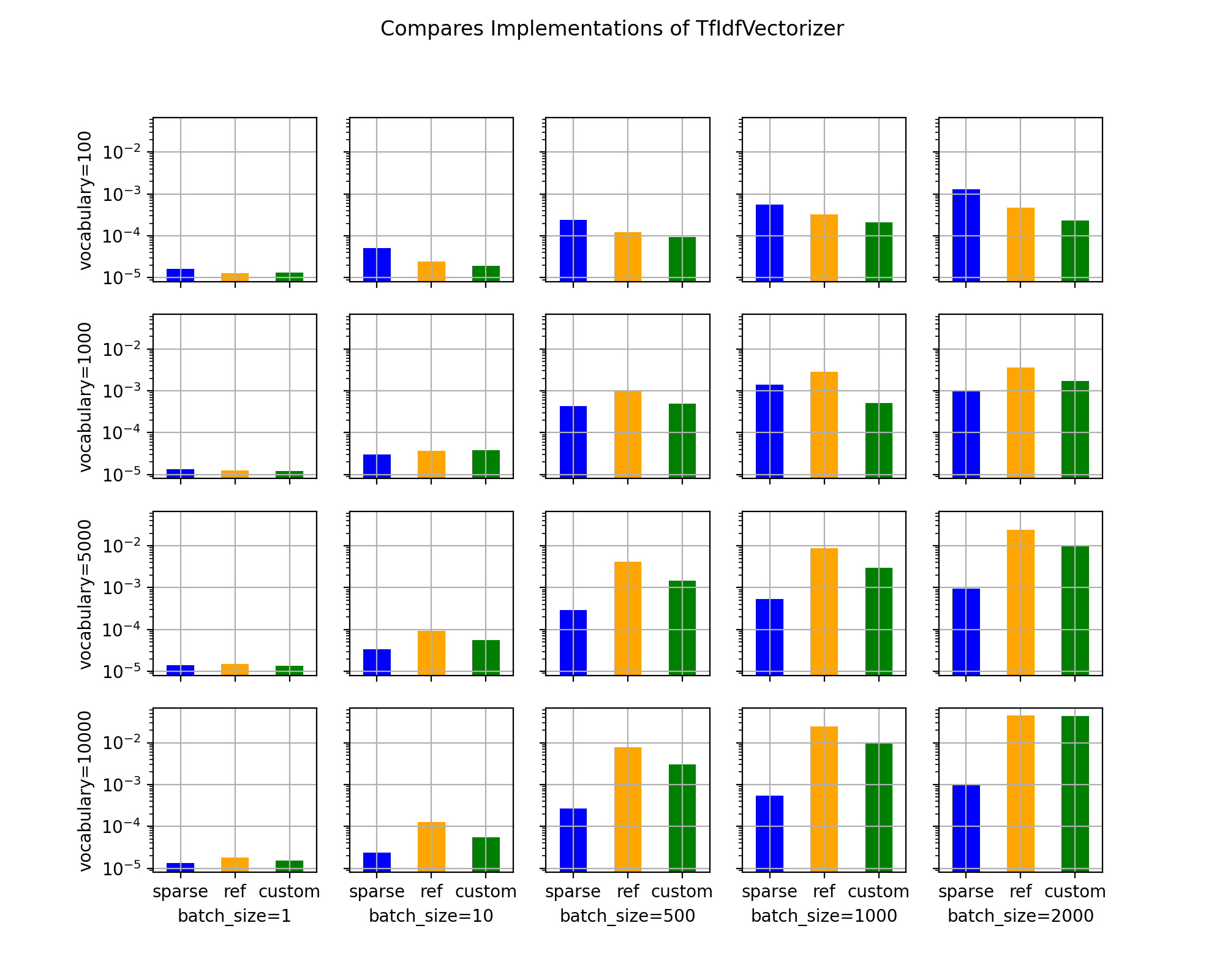
- onnx_extended.plotting.benchmark.vhistograms(df: pandas.DataFrame, metric: str = 'time', name: str = 'name', batch_size: str = 'batch_size', voc_size: str = 'voc_size', sup_title: str = 'Compares Implementations of TfIdfVectorizer')[source]#
Histograms with error bars.
- Parameters:
df – data
metric – metric to show
name – experiment name
batch_size – first column for the variations
voc_size – second column for the variations
sup_title – figure title
- Returns:
axes
average deviation min_exec ... voc_size batch_size time 0 0.000016 1.739738e-06 0.000015 ... 100 1 0.000016 1 0.000013 8.758799e-07 0.000012 ... 100 1 0.000013 2 0.000013 3.734642e-07 0.000013 ... 100 1 0.000013 3 0.000051 1.242146e-05 0.000033 ... 100 10 0.000051 4 0.000024 2.685157e-06 0.000021 ... 100 10 0.000024 [5 rows x 14 columns]
(
Source code,png,hires.png,pdf)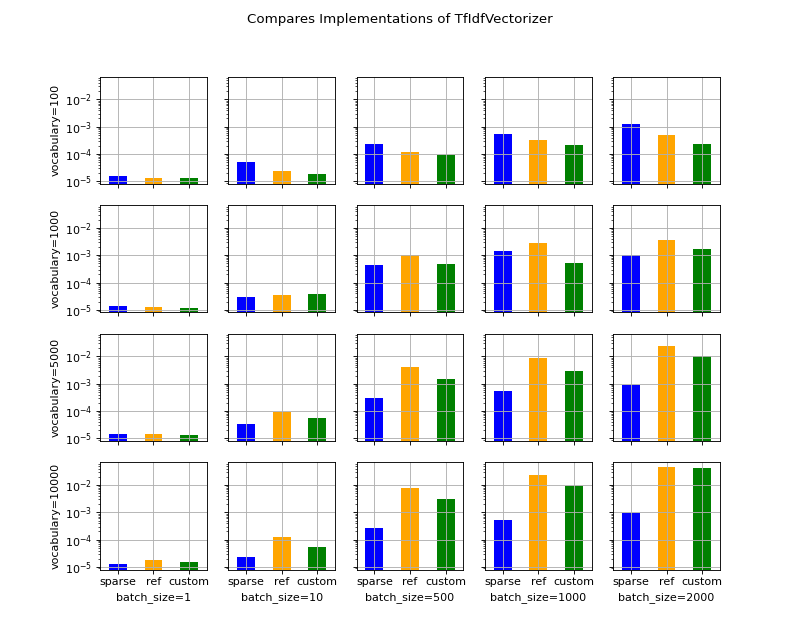
{kind=link}
{kind=link}