Note
Go to the end to download the full example code
Measuring CPU performance#
Processor caches must be taken into account when writing an algorithm, see Memory part 2: CPU caches from Ulrich Drepper.
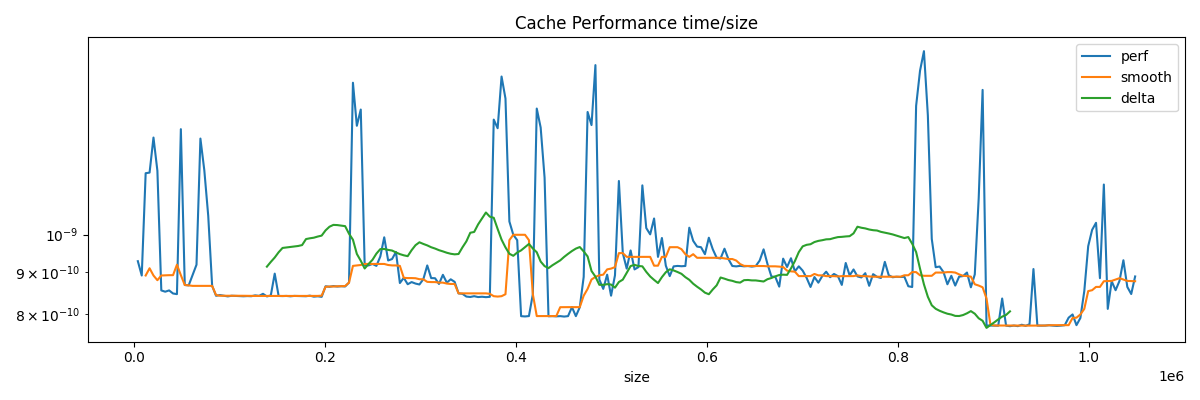
Cache Performance#
Code of benchmark_cache.
obs = []
step = 2**12
for i in tqdm(range(step, 2**20 + step, step)):
res = min(
[
benchmark_cache(i, False),
benchmark_cache(i, False),
benchmark_cache(i, False),
]
)
if res < 0:
# overflow
continue
obs.append(dict(size=i, perf=res))
df = DataFrame(obs)
mean = df.perf.mean()
lag = 32
for i in range(2, df.shape[0]):
df.loc[i, "smooth"] = df.loc[i - 8 : i + 8, "perf"].median()
if i > lag and i < df.shape[0] - lag:
df.loc[i, "delta"] = (
mean
+ df.loc[i : i + lag, "perf"].mean()
- df.loc[i - lag + 1 : i + 1, "perf"]
).mean()
0%| | 0/256 [00:00<?, ?it/s]
48%|████▊ | 123/256 [00:00<00:00, 1220.72it/s]
96%|█████████▌| 246/256 [00:00<00:00, 595.68it/s]
100%|██████████| 256/256 [00:00<00:00, 620.11it/s]
Cache size estimator#
cache_size_index = int(df.delta.argmax())
cache_size = df.loc[cache_size_index, "size"] * 2
print(f"L2 cache size estimation is {cache_size / 2 ** 20:1.3f} Mb.")
L2 cache size estimation is 0.703 Mb.
Verification#
try:
out, err = run_cmd("lscpu", wait=True)
print("\n".join(_ for _ in out.split("\n") if "cache:" in _))
except Exception as e:
print(f"failed due to {e}")
df = df.set_index("size")
fig, ax = plt.subplots(1, 1, figsize=(12, 4))
df.plot(ax=ax, title="Cache Performance time/size", logy=True)
fig.tight_layout()
fig.savefig("plot_benchmark_cpu_array.png")
L1d cache: 128 KiB (4 instances)
L1i cache: 128 KiB (4 instances)
L2 cache: 1 MiB (4 instances)
L3 cache: 8 MiB (1 instance)
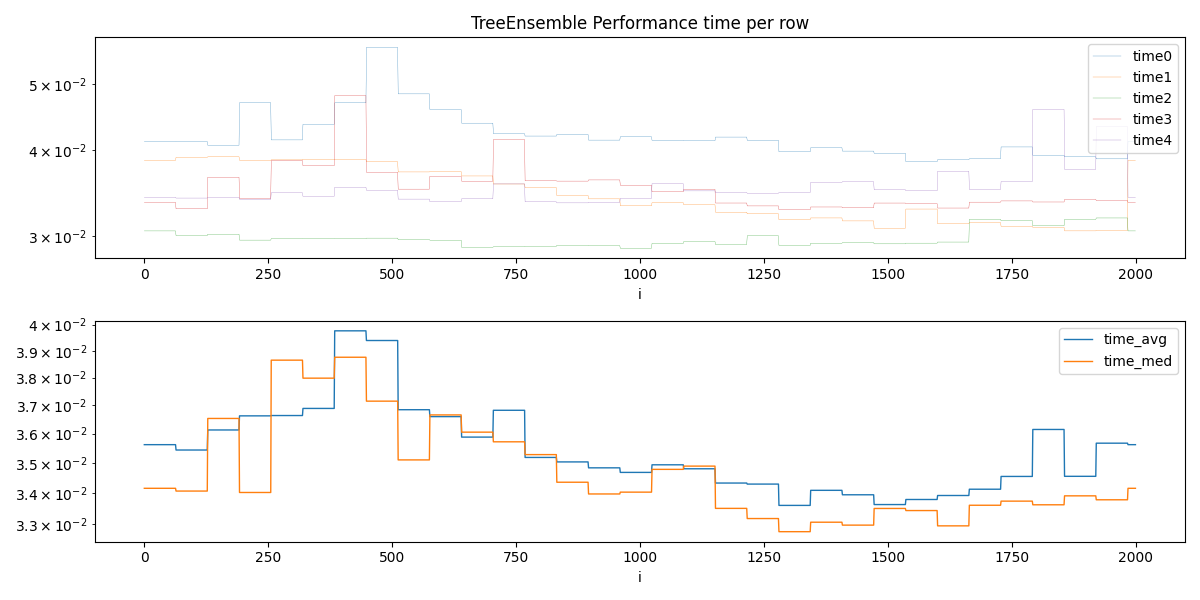
TreeEnsemble Performance#
We simulate the computation of a TreeEnsemble
of 50 features, 100 trees and depth of 10
(so  nodes.)
The code of benchmark_cache_tree
nodes.)
The code of benchmark_cache_tree
dfs = []
cols = []
drop = []
for n in tqdm(range(2 if unit_test_going() else 5)):
res = benchmark_cache_tree(
n_rows=2000,
n_features=50,
n_trees=100,
tree_size=1024,
max_depth=10,
search_step=64,
)
res = [[max(r.row, i), r.time] for i, r in enumerate(res)]
df = DataFrame(res)
df.columns = [f"i{n}", f"time{n}"]
dfs.append(df)
cols.append(df.columns[-1])
drop.append(df.columns[0])
df = concat(dfs, axis=1).reset_index(drop=True)
df["i"] = df["i0"]
df = df.drop(drop, axis=1)
df["time_avg"] = df[cols].mean(axis=1)
df["time_med"] = df[cols].median(axis=1)
df.head()
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:01<00:05, 1.31s/it]
40%|████ | 2/5 [00:02<00:03, 1.17s/it]
60%|██████ | 3/5 [00:03<00:02, 1.06s/it]
80%|████████ | 4/5 [00:04<00:01, 1.08s/it]
100%|██████████| 5/5 [00:05<00:00, 1.09s/it]
100%|██████████| 5/5 [00:05<00:00, 1.10s/it]
Estimation#
Optimal batch size is among:
i time_med time_avg
0 1280 0.032751 0.033592
1 1600 0.032936 0.033915
2 1408 0.032959 0.033938
3 1344 0.033052 0.034085
4 1216 0.033169 0.034291
5 1536 0.033426 0.033785
6 1472 0.033493 0.033620
7 1152 0.033496 0.034325
8 1664 0.033597 0.034121
9 1792 0.033612 0.036147
One possible estimation
Estimation: 1202.786800709671
Plots.
cols_time = ["time_avg", "time_med"]
fig, ax = plt.subplots(2, 1, figsize=(12, 6))
df.set_index("i").drop(cols_time, axis=1).plot(
ax=ax[0], title="TreeEnsemble Performance time per row", logy=True, linewidth=0.2
)
df.set_index("i")[cols_time].plot(ax=ax[1], linewidth=1.0, logy=True)
fig.tight_layout()
fig.savefig("plot_bench_cpu.png")
Total running time of the script: (0 minutes 7.694 seconds)