Profiling onnxruntime#
After the profiling comes the analyze. Here are two kinds. Both profiling are made on the following model.
<<<
import numpy as np
from onnx import TensorProto
from onnx.checker import check_model
from onnx.helper import (
make_model,
make_graph,
make_node,
make_opsetid,
make_tensor_value_info,
)
from onnx.numpy_helper import from_array
from onnx_array_api.plotting.text_plot import onnx_simple_text_plot
def get_model():
model_def0 = make_model(
make_graph(
[
make_node("Add", ["X", "init1"], ["X1"]),
make_node("Abs", ["X"], ["X2"]),
make_node("Add", ["X", "init3"], ["inter"]),
make_node("Mul", ["X1", "inter"], ["Xm"]),
make_node("Sub", ["X2", "Xm"], ["final"]),
],
"test",
[make_tensor_value_info("X", TensorProto.FLOAT, [None])],
[make_tensor_value_info("final", TensorProto.FLOAT, [None])],
[
from_array(np.array([1], dtype=np.float32), name="init1"),
from_array(np.array([3], dtype=np.float32), name="init3"),
],
),
opset_imports=[make_opsetid("", 18)],
)
check_model(model_def0)
return model_def0
print(onnx_simple_text_plot(get_model()))
>>>
opset: domain='' version=18
input: name='X' type=dtype('float32') shape=['']
init: name='init1' type=dtype('float32') shape=(1,) -- array([1.], dtype=float32)
init: name='init3' type=dtype('float32') shape=(1,) -- array([3.], dtype=float32)
Abs(X) -> X2
Add(X, init1) -> X1
Add(X, init3) -> inter
Mul(X1, inter) -> Xm
Sub(X2, Xm) -> final
output: name='final' type=dtype('float32') shape=['']
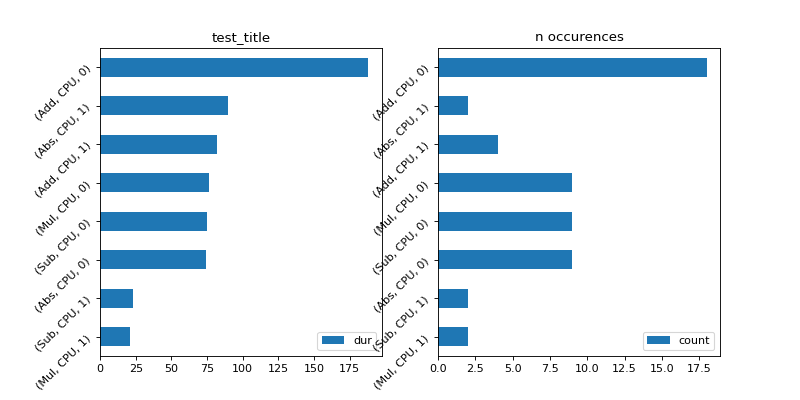
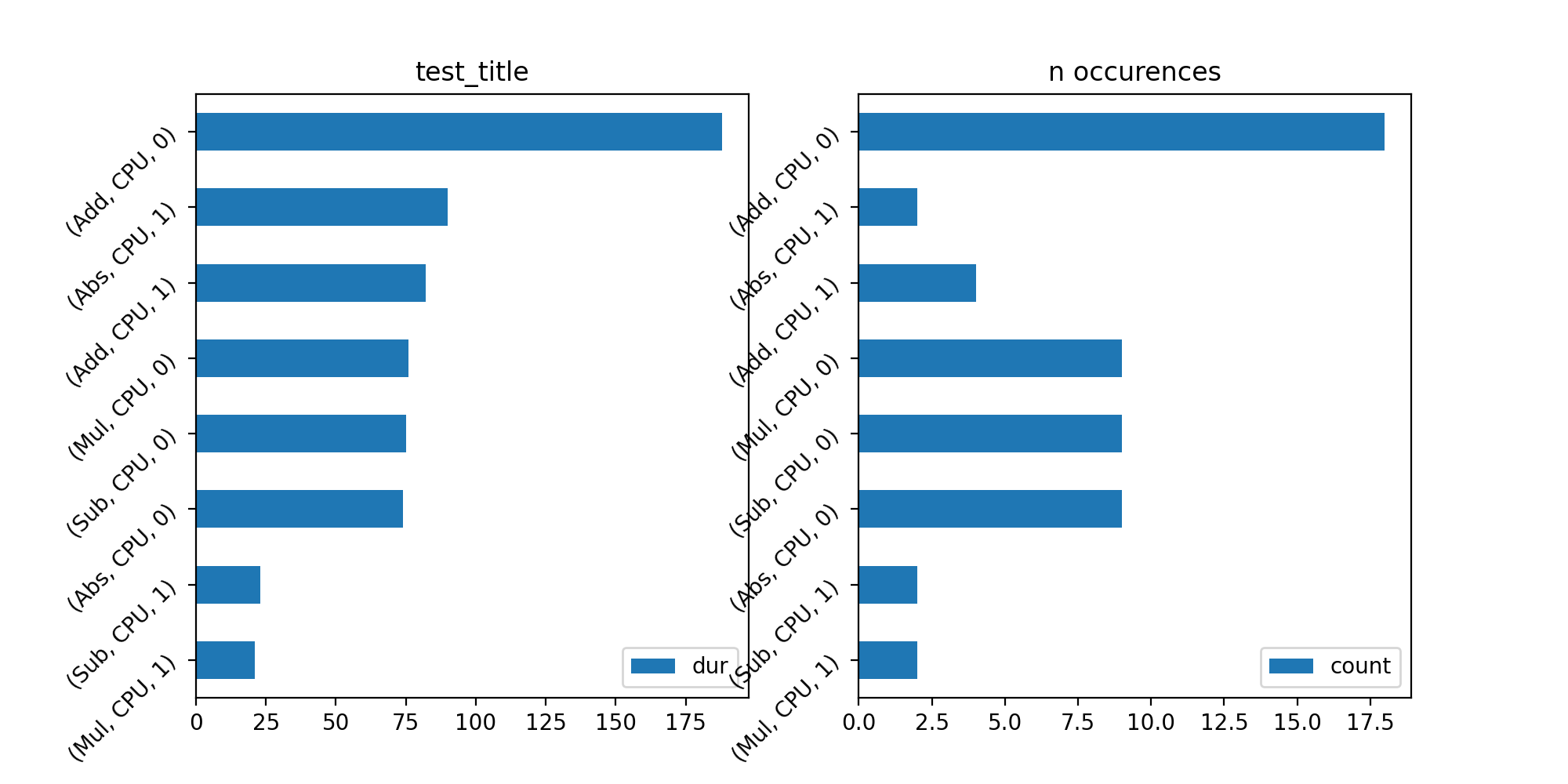
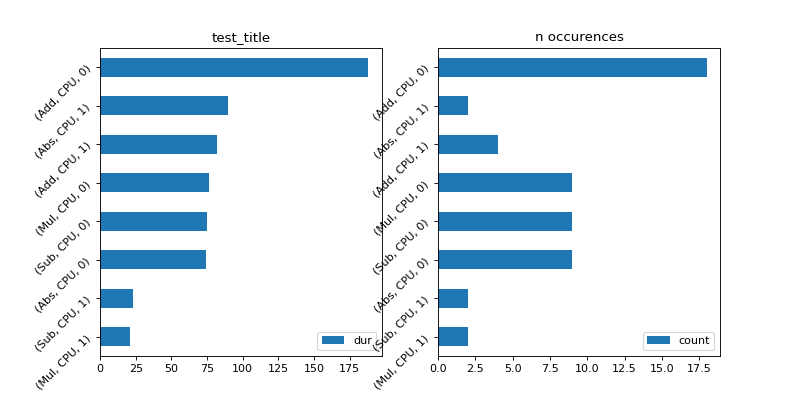
Time per type of node#
Two graphs to show the time aggregated per kind of operator. The domain is not logged so two different operator sharing the same type name gut different domains are aggregated together. (Add, CPU, 1) means all operators Add running on CPU for the first run. (Add, CPU, 0) means the same for any other runs. The first run is usually longer as it completes some of the optimization based on the inputs a ndoe receives.
import numpy as np
from onnx import TensorProto
from onnx.checker import check_model
from onnx.helper import (
make_model,
make_graph,
make_node,
make_opsetid,
make_tensor_value_info,
)
from onnx.numpy_helper import from_array
from onnxruntime import InferenceSession, SessionOptions
import matplotlib.pyplot as plt
from onnx_extended.tools.js_profile import (
js_profile_to_dataframe,
plot_ort_profile,
_process_shape,
)
def get_model():
model_def0 = make_model(
make_graph(
[
make_node("Add", ["X", "init1"], ["X1"]),
make_node("Abs", ["X"], ["X2"]),
make_node("Add", ["X", "init3"], ["inter"]),
make_node("Mul", ["X1", "inter"], ["Xm"]),
make_node("Sub", ["X2", "Xm"], ["final"]),
],
"test",
[make_tensor_value_info("X", TensorProto.FLOAT, [None])],
[make_tensor_value_info("final", TensorProto.FLOAT, [None])],
[
from_array(np.array([1], dtype=np.float32), name="init1"),
from_array(np.array([3], dtype=np.float32), name="init3"),
],
),
opset_imports=[make_opsetid("", 18)],
)
check_model(model_def0)
return model_def0
sess_options = SessionOptions()
sess_options.enable_profiling = True
sess = InferenceSession(
get_model().SerializeToString(),
sess_options,
providers=["CPUExecutionProvider"],
)
for _ in range(11):
sess.run(None, dict(X=np.arange(10).astype(np.float32)))
prof = sess.end_profiling()
df = js_profile_to_dataframe(prof, first_it_out=True)
print(df.head())
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
plot_ort_profile(df, ax[0], ax[1], "test_title")
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
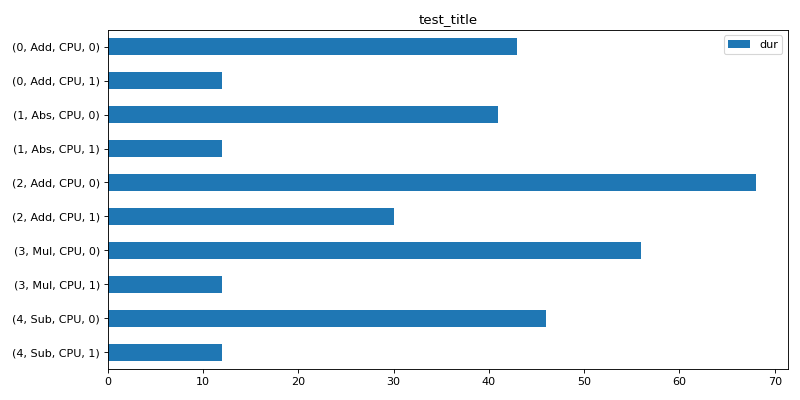
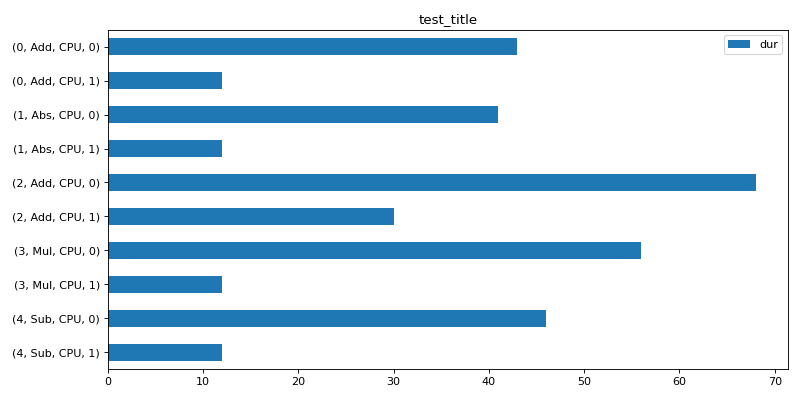
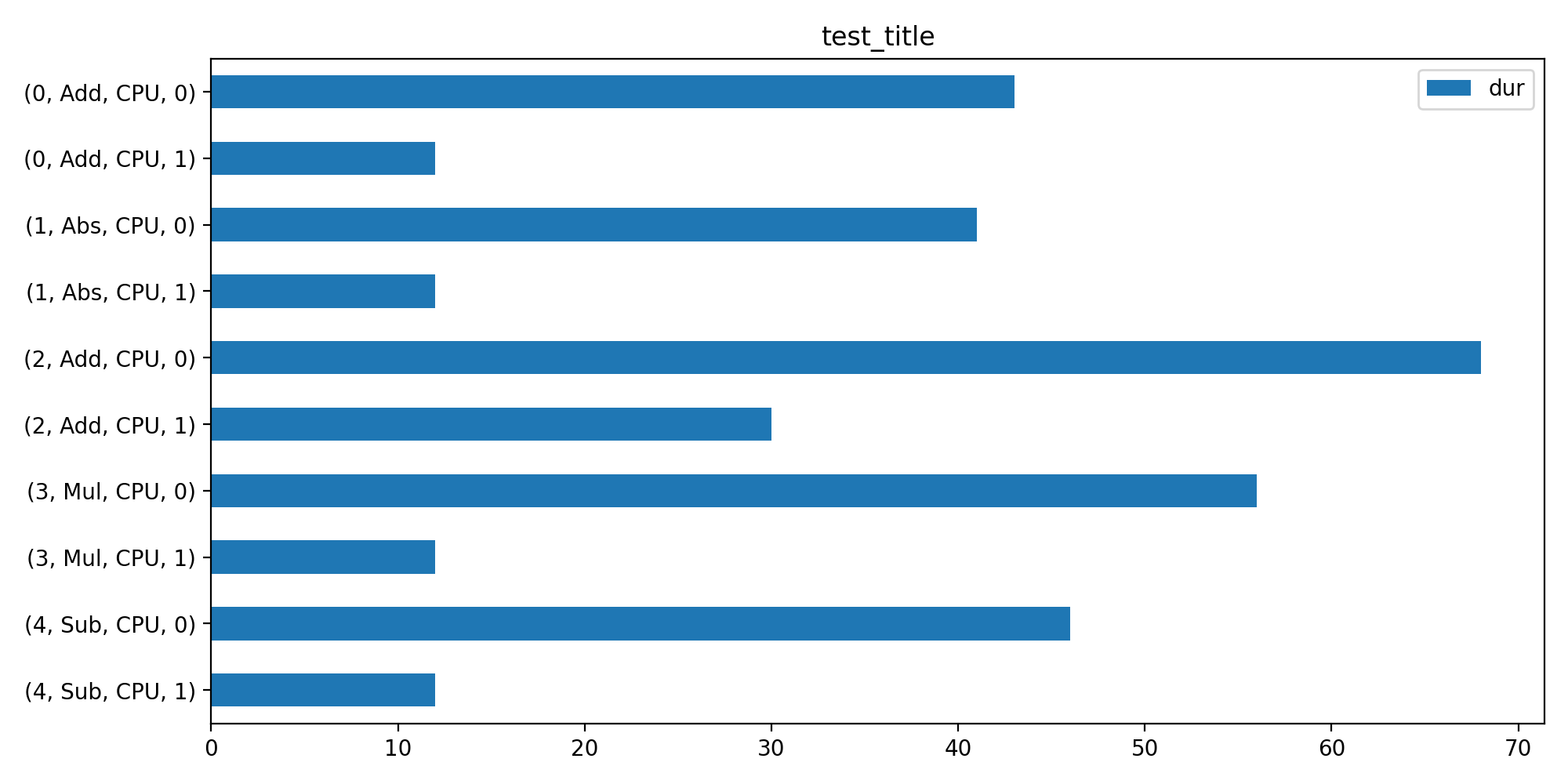
Time per instance#
The time for every node of a graph. (0, Add, CPU, 1) means operator Add at position 0 in the graph running on CPU for the first run. (0, Add, CPU, 0) means the same for any other runs.
import numpy as np
from onnx import TensorProto
from onnx.checker import check_model
from onnx.helper import (
make_model,
make_graph,
make_node,
make_opsetid,
make_tensor_value_info,
)
from onnx.numpy_helper import from_array
from onnxruntime import InferenceSession, SessionOptions
import matplotlib.pyplot as plt
from onnx_extended.tools.js_profile import (
js_profile_to_dataframe,
plot_ort_profile,
_process_shape,
)
def get_model():
model_def0 = make_model(
make_graph(
[
make_node("Add", ["X", "init1"], ["X1"]),
make_node("Abs", ["X"], ["X2"]),
make_node("Add", ["X", "init3"], ["inter"]),
make_node("Mul", ["X1", "inter"], ["Xm"]),
make_node("Sub", ["X2", "Xm"], ["final"]),
],
"test",
[make_tensor_value_info("X", TensorProto.FLOAT, [None])],
[make_tensor_value_info("final", TensorProto.FLOAT, [None])],
[
from_array(np.array([1], dtype=np.float32), name="init1"),
from_array(np.array([3], dtype=np.float32), name="init3"),
],
),
opset_imports=[make_opsetid("", 18)],
)
check_model(model_def0)
return model_def0
sess_options = SessionOptions()
sess_options.enable_profiling = True
sess = InferenceSession(
get_model().SerializeToString(),
sess_options,
providers=["CPUExecutionProvider"],
)
for _ in range(11):
sess.run(None, dict(X=np.arange(10).astype(np.float32)))
prof = sess.end_profiling()
df = js_profile_to_dataframe(prof, first_it_out=True, agg=True)
print(df.head())
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
plot_ort_profile(df, ax, title="test_title")
fig.tight_layout()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}