Note
Go to the end to download the full example code
Measuring CPU/GPU performance with a vector sum#
The examples compares multiple versions of a vector sum, CPU, GPU.
Vector Sum#
from tqdm import tqdm
import numpy
import matplotlib.pyplot as plt
from pandas import DataFrame
from onnx_extended.ext_test_case import measure_time, unit_test_going
from onnx_extended.validation.cpu._validation import (
vector_sum_array_avx as vector_sum_avx,
vector_sum_array_avx_parallel as vector_sum_avx_parallel,
)
try:
from onnx_extended.validation.cuda.cuda_example_py import (
vector_sum0,
vector_sum6,
vector_sum_atomic,
)
except ImportError:
# CUDA is not available
vector_sum0 = None
obs = []
dims = [500, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 2000]
if unit_test_going():
dims = dims[:3]
for dim in tqdm(dims):
values = numpy.ones((dim, dim), dtype=numpy.float32).ravel()
diff = abs(vector_sum_avx(dim, values) - dim**2)
res = measure_time(lambda: vector_sum_avx(dim, values), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="avx",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
diff = abs(vector_sum_avx_parallel(dim, values) - dim**2)
res = measure_time(lambda: vector_sum_avx_parallel(dim, values), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="avx//",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
if vector_sum0 is None:
# CUDA is not available
continue
diff = abs(vector_sum0(values, 32) - dim**2)
res = measure_time(lambda: vector_sum0(values, 32), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="0cuda32",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
diff = abs(vector_sum_atomic(values, 32) - dim**2)
res = measure_time(lambda: vector_sum_atomic(values, 32), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="Acuda32",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
diff = abs(vector_sum6(values, 32) - dim**2)
res = measure_time(lambda: vector_sum6(values, 32), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="6cuda32",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
diff = abs(vector_sum6(values, 256) - dim**2)
res = measure_time(lambda: vector_sum6(values, 256), max_time=0.5)
obs.append(
dict(
dim=dim,
size=values.size,
time=res["average"],
direction="6cuda256",
time_per_element=res["average"] / dim**2,
diff=diff,
)
)
df = DataFrame(obs)
piv = df.pivot(index="dim", columns="direction", values="time_per_element")
print(piv)
0%| | 0/14 [00:00<?, ?it/s]
7%|7 | 1/14 [00:03<00:50, 3.87s/it]
14%|#4 | 2/14 [00:13<01:26, 7.17s/it]
21%|##1 | 3/14 [00:17<01:02, 5.67s/it]
29%|##8 | 4/14 [00:36<01:49, 10.91s/it]
36%|###5 | 5/14 [00:41<01:19, 8.79s/it]
43%|####2 | 6/14 [00:54<01:23, 10.44s/it]
50%|##### | 7/14 [01:05<01:14, 10.57s/it]
57%|#####7 | 8/14 [01:24<01:19, 13.24s/it]
64%|######4 | 9/14 [01:42<01:13, 14.63s/it]
71%|#######1 | 10/14 [01:46<00:46, 11.52s/it]
79%|#######8 | 11/14 [01:51<00:28, 9.55s/it]
86%|########5 | 12/14 [01:56<00:16, 8.00s/it]
93%|#########2| 13/14 [02:04<00:08, 8.05s/it]
100%|##########| 14/14 [02:11<00:00, 7.63s/it]
100%|##########| 14/14 [02:11<00:00, 9.38s/it]
direction 0cuda32 6cuda256 6cuda32 Acuda32 avx avx//
dim
500 1.181641e-08 1.345400e-08 1.410174e-08 9.197381e-08 5.356410e-10 9.517533e-10
700 8.027340e-09 8.687643e-09 9.185914e-09 6.432641e-08 9.622454e-10 1.894896e-09
800 1.322138e-08 8.278698e-09 9.314792e-09 7.457594e-08 7.508841e-10 1.150001e-08
900 8.297663e-09 8.669644e-09 8.719653e-09 7.039077e-08 1.412792e-09 3.496707e-09
1000 7.746498e-09 6.723199e-09 7.186971e-09 6.473864e-08 1.316828e-09 3.257170e-09
1100 9.454735e-09 6.034921e-09 6.974243e-09 6.529125e-08 1.416969e-09 4.857414e-09
1200 7.214382e-09 5.636405e-09 6.285408e-09 6.241749e-08 8.808762e-10 3.975563e-09
1300 7.810209e-09 6.051327e-09 6.062795e-09 7.308626e-08 1.237137e-09 5.696840e-09
1400 1.701166e-08 5.082336e-09 5.524672e-09 6.865366e-08 1.597392e-09 7.970353e-09
1500 6.411862e-09 5.295806e-09 5.659262e-09 5.933988e-08 1.666052e-09 5.514271e-09
1600 6.132204e-09 4.616231e-09 5.769171e-09 5.958209e-08 1.562252e-09 4.656670e-09
1700 4.357651e-09 5.286932e-09 5.599310e-09 6.009173e-08 1.344157e-09 2.825355e-09
1800 5.477418e-09 4.636300e-09 4.220067e-09 5.965470e-08 1.330121e-09 3.942129e-09
2000 4.434196e-09 5.291751e-09 3.988259e-09 5.825104e-08 1.083512e-09 2.771634e-09
Plots#
piv_diff = df.pivot(index="dim", columns="direction", values="diff")
piv_time = df.pivot(index="dim", columns="direction", values="time")
fig, ax = plt.subplots(1, 3, figsize=(12, 6))
piv.plot(ax=ax[0], logx=True, title="Comparison between two summation")
piv_diff.plot(ax=ax[1], logx=True, logy=True, title="Summation errors")
piv_time.plot(ax=ax[2], logx=True, logy=True, title="Total time")
fig.savefig("plot_bench_gpu_vector_sum_gpu.png")

The results should look like the following.
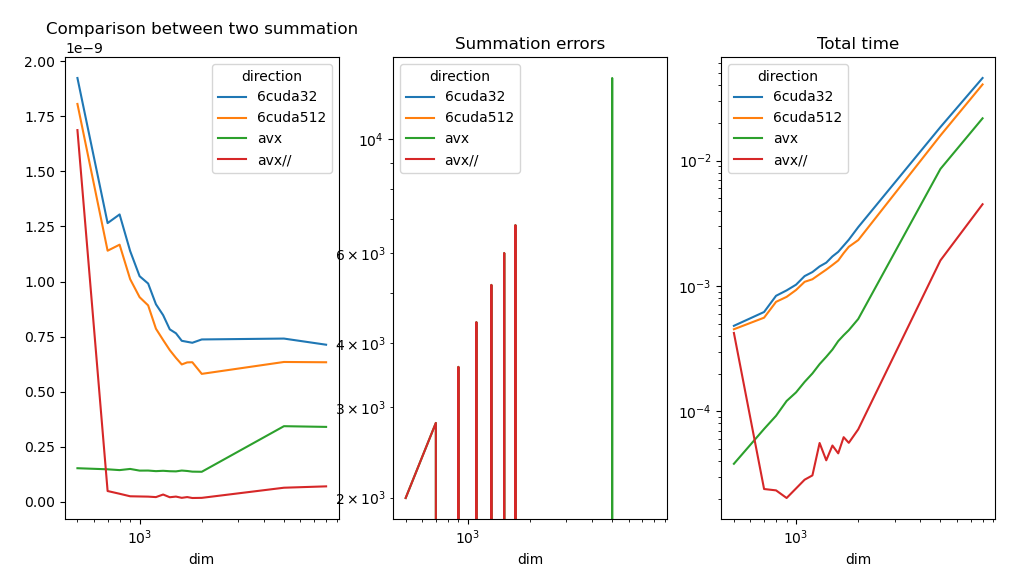
AVX is still faster. Let’s try to understand why.
Profiling#
The profiling indicates where the program is most of the time. It shows when the GPU is waiting and when the memory is copied from from host (CPU) to device (GPU) and the other way around. There are the two steps we need to reduce or avoid to make use of the GPU.
Profiling with nsight-compute:
nsys profile --trace=cuda,cudnn,cublas,osrt,nvtx,openmp python <file>
If nsys fails to find python, the command which python should locate it. <file> can be `plot_bench_gpu_vector_sum_gpu.py for example.
Then command nsys-ui starts the Visual Interface interface of the profiling. A screen shot shows the following after loading the profiling.
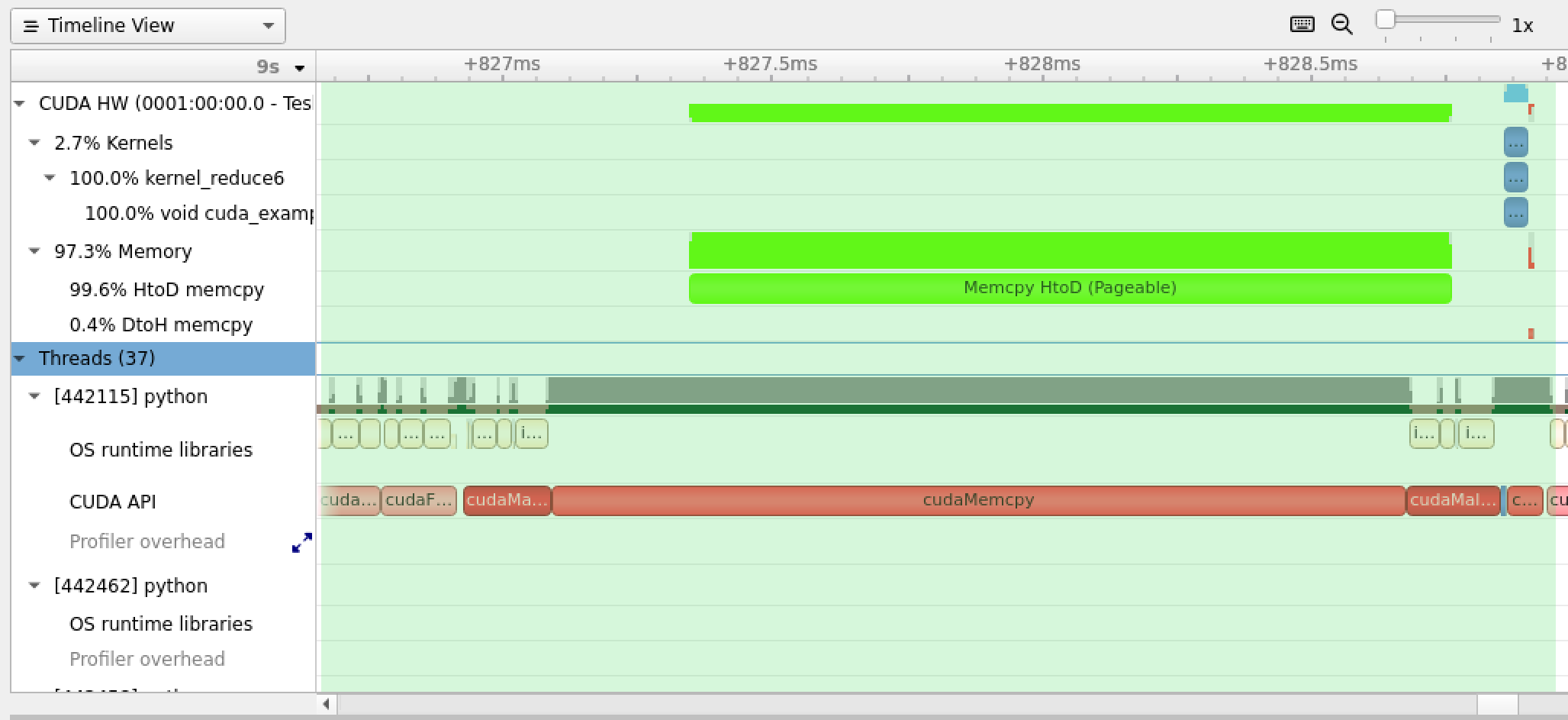
Most of time is spent in copy the data from CPU memory to GPU memory. In our case, GPU is not really useful because just copying the data from CPU to GPU takes more time than processing it with CPU and AVX instructions.
GPU is useful for deep learning because many operations can be chained and the data stays on GPU memory until the very end. When multiple tools are involved, torch, numpy, onnxruntime, the DLPack avoids copying the data when switching.
The copy of a big tensor can happens by block. The computation may start before the data is fully copied.
Total running time of the script: ( 2 minutes 18.607 seconds)