Heap#
La structure heap ou tas en français est utilisée pour trier. Elle peut également servir à obtenir les k premiers éléments d’une liste.
Un tas est peut être considéré comme un tableau  qui vérifie une condition assez simple, pour tout indice
qui vérifie une condition assez simple, pour tout indice  , alors
, alors ![T[i] \geqslant \max(T[2i+1], T[2i+2])](../../_images/math/2923849735ef66b9365d17e5418ec28fd8a1f6c4.svg) . On en déduit nécessairement que le premier élément du tableau est le plus grand. Maintenant comment transformer un tableau en un autre qui respecte cette contrainte ?
. On en déduit nécessairement que le premier élément du tableau est le plus grand. Maintenant comment transformer un tableau en un autre qui respecte cette contrainte ?
[2]:
%matplotlib inline
Transformer en tas#
[3]:
def swap(tab, i, j):
"Echange deux éléments."
tab[i], tab[j] = tab[j], tab[i]
def entas(heap):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(heap) - 1
while i > 0:
root = (i - 1) // 2
if heap[root] < heap[i]:
swap(heap, root, i)
modif += 1
i -= 1
return heap
ens = [1, 2, 3, 4, 7, 10, 5, 6, 11, 12, 3]
entas(ens)
[3]:
[12, 11, 5, 10, 7, 3, 1, 6, 4, 3, 2]
Comme ce n’est pas facile de vérifer que c’est un tas, on le dessine.
Dessiner un tas#
[4]:
from teachpyx.tools import draw_diagram
def dessine_tas(heap):
rows = ["blockdiag {"]
for i, v in enumerate(heap):
if i * 2 + 1 < len(heap):
rows.append(
'"[{}]={}" -> "[{}]={}";'.format(i, heap[i], i * 2 + 1, heap[i * 2 + 1])
)
if i * 2 + 2 < len(heap):
rows.append(
'"[{}]={}" -> "[{}]={}";'.format(
i, heap[i], i * 2 + 2, heap[i * 2 + 2]
)
)
rows.append("}")
return draw_diagram("\n".join(rows))
ens = [1, 2, 3, 4, 7, 10, 5, 6, 11, 12, 3]
dessine_tas(entas(ens))
[4]:
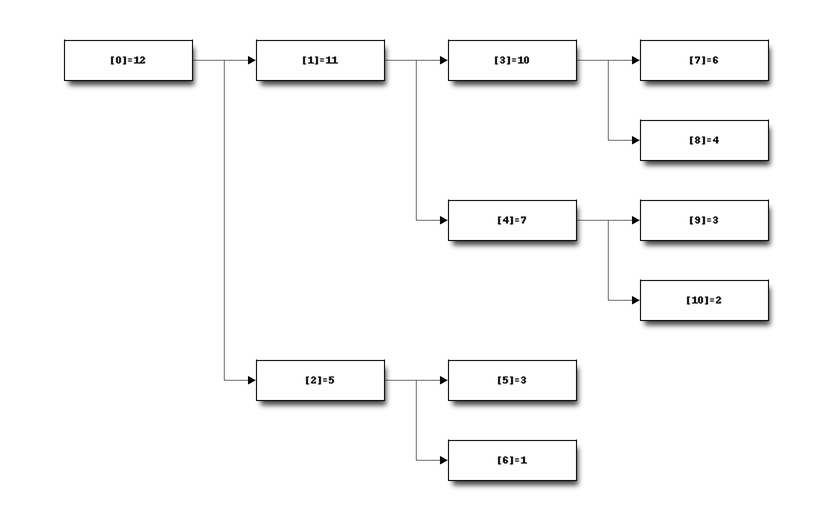
Le nombre entre crochets est la position, l’autre nombre est la valeur à cette position. Cette représentation fait apparaître une structure d’arbre binaire.
Première version#
[5]:
def swap(tab, i, j):
"Echange deux éléments."
tab[i], tab[j] = tab[j], tab[i]
def _heapify_max_bottom(heap):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(heap) - 1
while i > 0:
root = (i - 1) // 2
if heap[root] < heap[i]:
swap(heap, root, i)
modif += 1
i -= 1
def _heapify_max_up(heap):
"Organise un ensemble selon un tas."
i = 0
while True:
left = 2 * i + 1
right = left + 1
if right < len(heap):
if heap[left] > heap[i] >= heap[right]:
swap(heap, i, left)
i = left
elif heap[right] > heap[i]:
swap(heap, i, right)
i = right
else:
break
elif left < len(heap) and heap[left] > heap[i]:
swap(heap, i, left)
i = left
else:
break
def topk_min(ens, k):
"Retourne les k plus petits éléments d'un ensemble."
heap = ens[:k]
_heapify_max_bottom(heap)
for el in ens[k:]:
if el < heap[0]:
heap[0] = el
_heapify_max_up(heap)
return heap
ens = [1, 2, 3, 4, 7, 10, 5, 6, 11, 12, 3]
for k in range(1, len(ens) - 1):
print(k, topk_min(ens, k))
1 [1]
2 [2, 1]
3 [3, 2, 1]
4 [3, 3, 1, 2]
5 [4, 3, 1, 3, 2]
6 [5, 4, 3, 3, 2, 1]
7 [5, 6, 3, 4, 2, 3, 1]
8 [5, 7, 3, 6, 2, 3, 1, 4]
9 [5, 10, 3, 7, 2, 3, 1, 6, 4]
Même chose avec les indices au lieu des valeurs#
[6]:
def _heapify_max_bottom_position(ens, pos):
"Organise un ensemble selon un tas."
modif = 1
while modif > 0:
modif = 0
i = len(pos) - 1
while i > 0:
root = (i - 1) // 2
if ens[pos[root]] < ens[pos[i]]:
swap(pos, root, i)
modif += 1
i -= 1
def _heapify_max_up_position(ens, pos):
"Organise un ensemble selon un tas."
i = 0
while True:
left = 2 * i + 1
right = left + 1
if right < len(pos):
if ens[pos[left]] > ens[pos[i]] >= ens[pos[right]]:
swap(pos, i, left)
i = left
elif ens[pos[right]] > ens[pos[i]]:
swap(pos, i, right)
i = right
else:
break
elif left < len(pos) and ens[pos[left]] > ens[pos[i]]:
swap(pos, i, left)
i = left
else:
break
def topk_min_position(ens, k):
"Retourne les positions des k plus petits éléments d'un ensemble."
pos = list(range(k))
_heapify_max_bottom_position(ens, pos)
for i, el in enumerate(ens[k:]):
if el < ens[pos[0]]:
pos[0] = k + i
_heapify_max_up_position(ens, pos)
return pos
ens = [1, 2, 3, 7, 10, 4, 5, 6, 11, 12, 3]
for k in range(1, len(ens) - 1):
pos = topk_min_position(ens, k)
print(k, pos, [ens[i] for i in pos])
1 [0] [1]
2 [1, 0] [2, 1]
3 [2, 1, 0] [3, 2, 1]
4 [10, 2, 0, 1] [3, 3, 1, 2]
5 [5, 10, 0, 2, 1] [4, 3, 1, 3, 2]
6 [6, 5, 2, 10, 1, 0] [5, 4, 3, 3, 2, 1]
7 [5, 7, 10, 6, 1, 2, 0] [4, 6, 3, 5, 2, 3, 1]
8 [5, 3, 10, 7, 1, 2, 0, 6] [4, 7, 3, 6, 2, 3, 1, 5]
9 [5, 4, 10, 3, 1, 2, 0, 7, 6] [4, 10, 3, 7, 2, 3, 1, 6, 5]
[7]:
import numpy.random as rnd
X = rnd.randn(10000)
%timeit topk_min(X, 20)
3.87 ms ± 553 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
[8]:
%timeit topk_min_position(X, 20)
3.4 ms ± 372 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Coût de l’algorithme#
[9]:
from tqdm import tqdm
from pandas import DataFrame
from teachpyx.ext_test_case import measure_time
rows = []
for n in tqdm(list(range(1000, 20001, 1000))):
X = rnd.randn(n)
res = measure_time(
"topk_min_position(X, 100)",
{"X": X, "topk_min_position": topk_min_position},
div_by_number=True,
number=10,
)
res["size"] = n
rows.append(res)
df = DataFrame(rows)
df.head()
100%|██████████| 20/20 [00:09<00:00, 2.01it/s]
[9]:
| average | deviation | min_exec | max_exec | repeat | number | ttime | context_size | warmup_time | size | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.001400 | 0.000271 | 0.001090 | 0.001892 | 10 | 10 | 0.014000 | 232 | 0.001138 | 1000 |
| 1 | 0.002110 | 0.000517 | 0.001622 | 0.003214 | 10 | 10 | 0.021104 | 232 | 0.001633 | 2000 |
| 2 | 0.001967 | 0.000299 | 0.001747 | 0.002545 | 10 | 10 | 0.019669 | 232 | 0.002969 | 3000 |
| 3 | 0.002692 | 0.000611 | 0.002081 | 0.003779 | 10 | 10 | 0.026925 | 232 | 0.003983 | 4000 |
| 4 | 0.003096 | 0.000276 | 0.002660 | 0.003578 | 10 | 10 | 0.030960 | 232 | 0.003305 | 5000 |
[10]:
import matplotlib.pyplot as plt
df[["size", "average"]].set_index("size").plot()
plt.title("Coût topk en fonction de la taille du tableau");
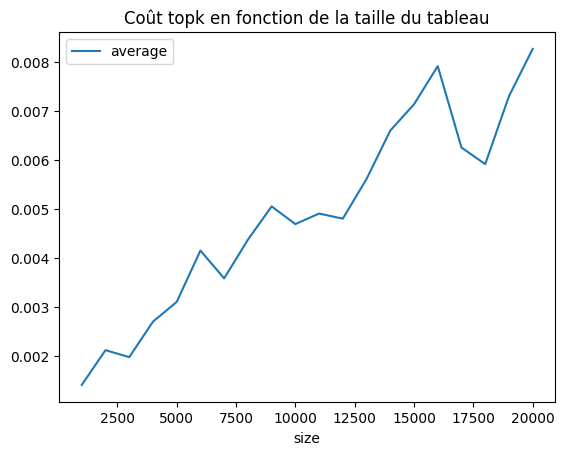
A peu près linéaire comme attendu.
[11]:
from tqdm import tqdm
from teachpyx.ext_test_case import measure_time
rows = []
X = rnd.randn(10000)
for k in tqdm(list(range(500, 2001, 150))):
res = measure_time(
"topk_min_position(X, k)",
{"X": X, "topk_min_position": topk_min_position, "k": k},
div_by_number=True,
number=5,
)
res["k"] = k
rows.append(res)
df = DataFrame(rows)
df.head()
100%|██████████| 11/11 [00:08<00:00, 1.33it/s]
[11]:
| average | deviation | min_exec | max_exec | repeat | number | ttime | context_size | warmup_time | k | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.008493 | 0.001842 | 0.006837 | 0.013038 | 10 | 5 | 0.084926 | 232 | 0.014053 | 500 |
| 1 | 0.009114 | 0.002111 | 0.007600 | 0.013480 | 10 | 5 | 0.091137 | 232 | 0.022466 | 650 |
| 2 | 0.011651 | 0.003198 | 0.008757 | 0.017215 | 10 | 5 | 0.116511 | 232 | 0.010779 | 800 |
| 3 | 0.011374 | 0.001973 | 0.009725 | 0.016044 | 10 | 5 | 0.113739 | 232 | 0.012545 | 950 |
| 4 | 0.016104 | 0.003647 | 0.011865 | 0.022728 | 10 | 5 | 0.161042 | 232 | 0.018794 | 1100 |
[12]:
df[["k", "average"]].set_index("k").plot()
plt.title("Coût topk en fonction de k");
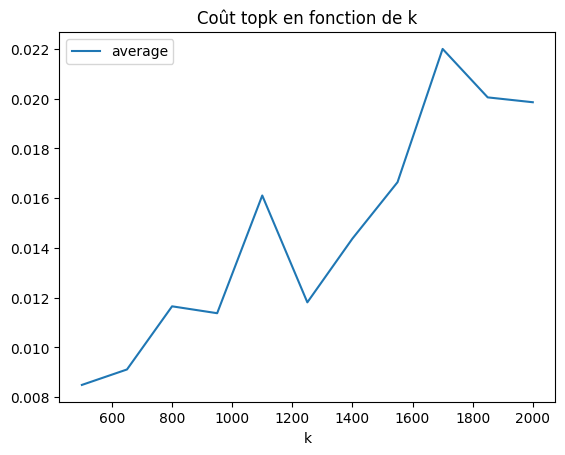
Pas évident, au pire en  , au mieux en
, au mieux en  .
.
Version simplifiée#
A-t-on vraiment besoin de _heapify_max_bottom_position ?
[13]:
def _heapify_max_up_position_simple(ens, pos, first):
"Organise un ensemble selon un tas."
i = first
while True:
left = 2 * i + 1
right = left + 1
if right < len(pos):
if ens[pos[left]] > ens[pos[i]] >= ens[pos[right]]:
swap(pos, i, left)
i = left
elif ens[pos[right]] > ens[pos[i]]:
swap(pos, i, right)
i = right
else:
break
elif left < len(pos) and ens[pos[left]] > ens[pos[i]]:
swap(pos, i, left)
i = left
else:
break
def topk_min_position_simple(ens, k):
"Retourne les positions des k plus petits éléments d'un ensemble."
pos = list(range(k))
pos[k - 1] = 0
for i in range(1, k):
pos[k - i - 1] = i
_heapify_max_up_position_simple(ens, pos, k - i - 1)
for i, el in enumerate(ens[k:]):
if el < ens[pos[0]]:
pos[0] = k + i
_heapify_max_up_position_simple(ens, pos, 0)
return pos
ens = [1, 2, 3, 7, 10, 4, 5, 6, 11, 12, 3]
for k in range(1, len(ens) - 1):
pos = topk_min_position_simple(ens, k)
print(k, pos, [ens[i] for i in pos])
1 [0] [1]
2 [1, 0] [2, 1]
3 [2, 1, 0] [3, 2, 1]
4 [10, 2, 1, 0] [3, 3, 2, 1]
5 [5, 10, 2, 1, 0] [4, 3, 3, 2, 1]
6 [5, 6, 10, 2, 1, 0] [4, 5, 3, 3, 2, 1]
7 [6, 7, 10, 5, 2, 1, 0] [5, 6, 3, 4, 3, 2, 1]
8 [5, 4, 10, 7, 6, 2, 1, 0] [4, 10, 3, 6, 5, 3, 2, 1]
9 [3, 4, 6, 5, 7, 10, 2, 1, 0] [7, 10, 5, 4, 6, 3, 3, 2, 1]
[14]:
X = rnd.randn(10000)
%timeit topk_min_position_simple(X, 20)
3.79 ms ± 1.13 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
[ ]:
[ ]: