Note
Go to the end to download the full example code.
LayerNormalization implementation cannot be exchanged¶
This example applies what was illustrated Reproducible Parallelized Reduction is difficult, reduction operations are sensitive to parallelization.
We consider a small model including a layer normalization followed by a matrix multiplication and we show that replacing a kernel by another one may significantly impact the output.
The model¶
import itertools
import pandas
import onnx
import onnx.helper as oh
import onnxruntime
import torch
from onnx_array_api.plotting.graphviz_helper import plot_dot
from onnx_diagnostic.ext_test_case import unit_test_going
from onnx_diagnostic.helpers import max_diff, string_diff, string_type
from onnx_diagnostic.helpers.onnx_helper import onnx_dtype_name, onnx_dtype_to_np_dtype
from onnx_diagnostic.helpers.torch_helper import onnx_dtype_to_torch_dtype
from onnx_diagnostic.helpers.doc_helper import LayerNormalizationOrt, MatMulOrt
from onnx_diagnostic.reference import TorchOnnxEvaluator
TFLOAT = onnx.TensorProto.FLOAT
TFLOAT16 = onnx.TensorProto.FLOAT16
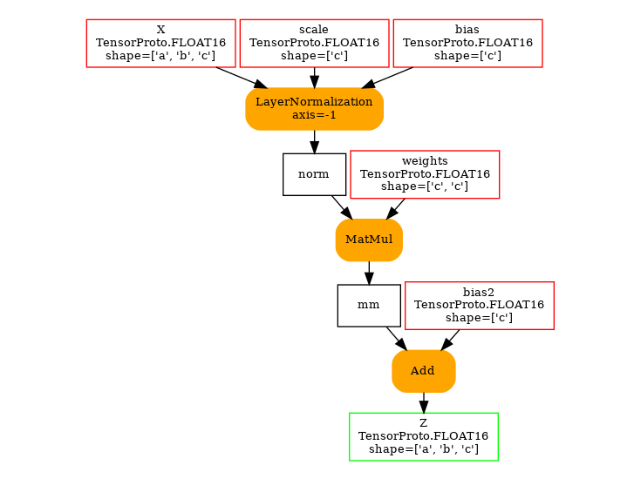
def get_model(itype: int = TFLOAT16):
return oh.make_model(
oh.make_graph(
[
oh.make_node("LayerNormalization", ["X", "scale", "bias"], ["norm"], axis=-1),
oh.make_node("MatMul", ["norm", "weights"], ["mm"]),
oh.make_node("Add", ["mm", "bias2"], ["Z"]),
],
"layer_norm_matmul_add",
[
oh.make_tensor_value_info("X", itype, ["a", "b", "c"]),
oh.make_tensor_value_info("scale", itype, ["c"]),
oh.make_tensor_value_info("bias", itype, ["c"]),
oh.make_tensor_value_info("weights", itype, ["c", "c"]),
oh.make_tensor_value_info("bias2", itype, ["c"]),
],
[oh.make_tensor_value_info("Z", itype, ["a", "b", "c"])],
),
ir_version=9,
opset_imports=[oh.make_opsetid("", 18)],
)
model = get_model()
plot_dot(model)
Let’s compare two runtimes¶
That will be onnxruntime and
onnx_diagnostic.reference.TorchOnnxEvaluator.
last_dim = 64 if unit_test_going() else 1152
def make_feeds(last_dim: int):
return {
"X": (torch.rand((32, 1024, last_dim), dtype=torch.float16) - 0.5) * 120,
"scale": torch.rand((last_dim,), dtype=torch.float16),
"bias": torch.rand((last_dim,), dtype=torch.float16),
"weights": torch.rand((last_dim, last_dim), dtype=torch.float16),
"bias2": torch.rand((last_dim,), dtype=torch.float16),
}
def cast_feeds(itype, provider, feeds):
np_feeds = {k: v.detach().numpy() for k, v in feeds.items()}
if provider == "CUDA":
if not torch.cuda.is_available():
return None, None
tch_feeds = {k: v.to("cuda") for k, v in feeds.items()}
ort_feeds = np_feeds
else:
tch_feeds = feeds.copy()
tch_feeds["X"] = tch_feeds["X"][:2] # too long otherwise
ort_feeds = np_feeds.copy()
ort_feeds["X"] = ort_feeds["X"][:2]
tch_feeds = {k: v.to(ttype) for k, v in tch_feeds.items()}
ort_feeds = {k: v.astype(np_dtype) for k, v in ort_feeds.items()}
return tch_feeds, ort_feeds
feeds = make_feeds(last_dim)
kws = dict(with_shape=True, with_min_max=True, with_device=True)
data = []
baseline = {}
for provider, itype in itertools.product(["CPU", "CUDA"], [TFLOAT, TFLOAT16]):
ttype = onnx_dtype_to_torch_dtype(itype)
np_dtype = onnx_dtype_to_np_dtype(itype)
tch_feeds, ort_feeds = cast_feeds(itype, provider, feeds)
if tch_feeds is None:
continue
model = get_model(itype)
print()
print(f"-- running on {provider} with {onnx_dtype_name(itype)}")
print("-- running with torch")
torch_sess = TorchOnnxEvaluator(model, providers=[f"{provider}ExecutionProvider"])
expected = torch_sess.run(None, tch_feeds)
baseline[itype, provider, "torch"] = expected
print(f"-- torch: {string_type(expected, **kws)}")
print("-- running with ort")
ort_sess = onnxruntime.InferenceSession(
model.SerializeToString(), providers=[f"{provider}ExecutionProvider"]
)
got = ort_sess.run(None, ort_feeds)
baseline[itype, provider, "ort"] = got
print(f"-- ort: {string_type(got, **kws)}")
diff = max_diff(expected, got, hist=True)
print(f"-- diff {string_diff(diff)}")
# memorize the data
diff["dtype"] = onnx_dtype_name(itype)
diff["provider"] = provider
diff.update(diff["rep"])
del diff["rep"]
del diff["dnan"]
del diff[">100.0"]
del diff[">10.0"]
data.append(diff)
-- running on CPU with FLOAT
-- running with torch
-- torch: #1[CT1s2x1024x1152[240.0281982421875,333.2430725097656:A285.0493383403518]]
-- running with ort
-- ort: #1[A1s2x1024x1152[240.02822875976562,333.2430419921875:A285.0493383583897]]
-- diff abs=0.000152587890625, rel=5.568541537966721e-07, n=2359296.0/#1484455>0.0-#2032>0.0001
-- running on CPU with FLOAT16
-- running with torch
-- torch: #1[CT10s2x1024x1152[240.0,333.25:A285.05135504404706]]
-- running with ort
-- ort: #1[A10s2x1024x1152[240.0,333.25:A285.0493660502964]]
-- diff abs=0.25, rel=0.0009765586853176355, n=2359296.0/#585826>0.0-#585826>0.0001-#585826>0.001-#585826>0.01-#585826>0.1
-- running on CUDA with FLOAT
-- running with torch
-- torch: #1[GT1s32x1024x1152[234.32650756835938,335.265869140625:A285.04125916001027]]
-- running with ort
-- ort: #1[A1s32x1024x1152[234.3227996826172,335.26470947265625:A285.03857064794204]]
-- diff abs=0.019561767578125, rel=6.741366235333735e-05, n=37748736.0/#37648559>0.0-#37048890>0.0001-#31279193>0.001-#522757>0.01
-- running on CUDA with FLOAT16
-- running with torch
-- torch: #1[GT10s32x1024x1152[234.375,335.25:A285.04108573993045]]
-- running with ort
-- ort: #1[A10s32x1024x1152[234.375,335.25:A285.0410857167509]]
-- diff abs=0.5, rel=0.00187969218160834, n=37748736.0/#1601>0.0-#1601>0.0001-#1601>0.001-#1601>0.01-#1601>0.1
df = pandas.DataFrame(data).set_index(["provider", "dtype"])
print(df)
abs rel sum ... >0.01 >0.1 >1.0
provider dtype ...
CPU FLOAT 0.000153 5.568542e-07 57.637527 ... 0 0 0
FLOAT16 0.250000 9.765587e-04 146385.375000 ... 585826 585826 0
CUDA FLOAT 0.019562 6.741366e-05 130786.453049 ... 522757 0 0
FLOAT16 0.500000 1.879692e-03 400.375000 ... 1601 1601 0
[4 rows x 10 columns]
Visually.
df["abs"].plot.bar(title="Discrepancies ORT / torch for LayerNorm(X) @ W + B")
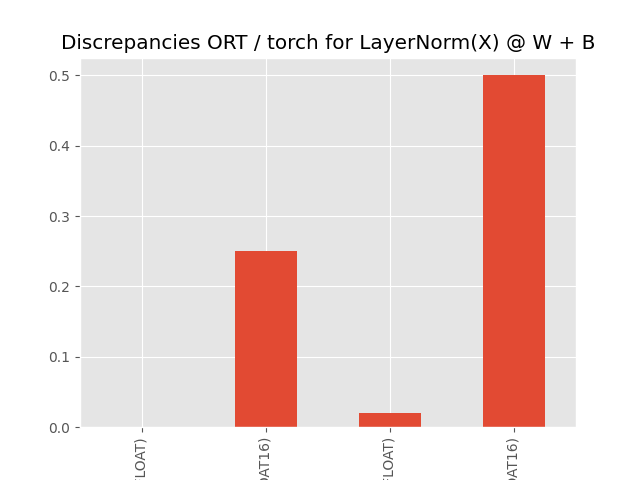
The discrepancies are significant on CUDA, higher for float16. Let’s see which operator is responsible for them, LayerNormalization or MatMul.
The discrepancies come from?¶
We mix torch and onnxruntime to execute the kernels.
data = []
for mod, provider, itype in itertools.product(
["ORT-TORCH", "TORCH-ORT"], ["CPU", "CUDA"], [TFLOAT, TFLOAT16]
):
ttype = onnx_dtype_to_torch_dtype(itype)
np_dtype = onnx_dtype_to_np_dtype(itype)
tch_feeds, _ = cast_feeds(itype, provider, feeds)
if tch_feeds is None:
continue
custom_kernels = (
{("", "LayerNormalization"): LayerNormalizationOrt}
if mod == "ORT-TORCH"
else {("", "MatMul"): MatMulOrt}
)
model = get_model(itype)
print()
print(f"-- {mod} running on {provider} with {onnx_dtype_name(itype)}")
sess = TorchOnnxEvaluator(
model,
custom_kernels=custom_kernels,
providers=[f"{provider}ExecutionProvider"],
)
got = sess.run(None, tch_feeds)
print(f"-- {mod}: {string_type(got, **kws)}")
difft = max_diff(baseline[itype, provider, "torch"], got)
print(f"-- diff with torch {string_diff(difft)}")
diffo = max_diff(baseline[itype, provider, "ort"], got)
print(f"-- diff with ort {string_diff(diffo)}")
data.append(
dict(
model=mod,
dtype=onnx_dtype_name(itype),
provider=provider,
diff_ort=diffo["abs"],
diff_torch=difft["abs"],
)
)
-- ORT-TORCH running on CPU with FLOAT
-- ORT-TORCH: #1[CT1s2x1024x1152[240.02818298339844,333.2430725097656:A285.04933834518954]]
-- diff with torch abs=9.1552734375e-05, rel=3.225682013818846e-07, n=2359296.0
-- diff with ort abs=0.000152587890625, rel=5.813544669095066e-07, n=2359296.0
-- ORT-TORCH running on CPU with FLOAT16
-- ORT-TORCH: #1[CT10s2x1024x1152[240.0,333.25:A285.0513520770603]]
-- diff with torch abs=0.5, rel=0.001848422002136776, n=2359296.0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0
-- ORT-TORCH running on CUDA with FLOAT
-- ORT-TORCH: #1[GT1s32x1024x1152[234.32652282714844,335.2658386230469:A285.04125915866217]]
-- diff with torch abs=0.0001220703125, rel=4.5536574584636475e-07, n=37748736.0
-- diff with ort abs=0.019561767578125, rel=6.741820726159815e-05, n=37748736.0
-- ORT-TORCH running on CUDA with FLOAT16
-- ORT-TORCH: #1[GT10s32x1024x1152[234.375,335.25:A285.04108571675084]]
-- diff with torch abs=0.5, rel=0.00187969218160834, n=37748736.0
-- diff with ort abs=0, rel=0
-- TORCH-ORT running on CPU with FLOAT
-- TORCH-ORT: #1[CT1s2x1024x1152[240.0251007080078,333.2402648925781:A285.04672243771427]]
-- diff with torch abs=0.018798828125, rel=6.496689800285014e-05, n=2359296.0
-- diff with ort abs=0.018798828125, rel=6.496689800285014e-05, n=2359296.0
-- TORCH-ORT running on CPU with FLOAT16
-- TORCH-ORT: #1[CT10s2x1024x1152[240.0,333.25:A285.04913934071857]]
-- diff with torch abs=0.5, rel=0.0018867853328855364, n=2359296.0
-- diff with ort abs=0.25, rel=0.0009765586853176355, n=2359296.0
-- TORCH-ORT running on CUDA with FLOAT
-- TORCH-ORT: #1[GT1s32x1024x1152[234.32289123535156,335.26470947265625:A285.03857107711394]]
-- diff with torch abs=0.019561767578125, rel=6.741366235333735e-05, n=37748736.0
-- diff with ort abs=0.002410888671875, rel=8.311597291643774e-06, n=37748736.0
-- TORCH-ORT running on CUDA with FLOAT16
-- TORCH-ORT: #1[GT10s32x1024x1152[234.375,335.25:A285.04108573993045]]
-- diff with torch abs=0, rel=0
-- diff with ort abs=0.5, rel=0.0018832320782219277, n=37748736.0
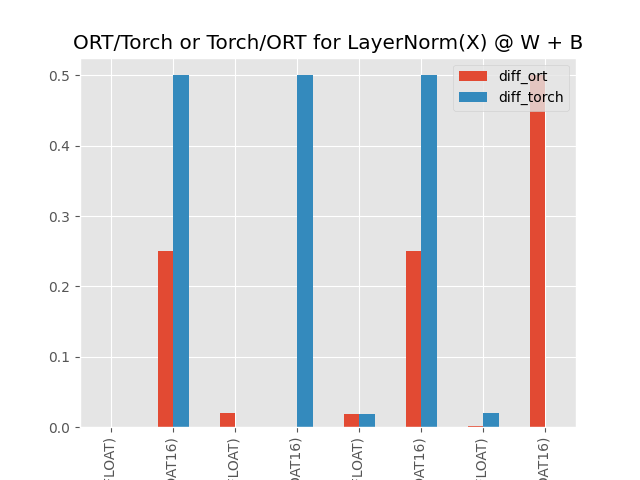
df = pandas.DataFrame(data).set_index(["model", "provider", "dtype"])
df = df.sort_index()
print(df)
diff_ort diff_torch
model provider dtype
ORT-TORCH CPU FLOAT 0.000153 0.000092
FLOAT16 0.250000 0.500000
CUDA FLOAT 0.019562 0.000122
FLOAT16 0.000000 0.500000
TORCH-ORT CPU FLOAT 0.018799 0.018799
FLOAT16 0.250000 0.500000
CUDA FLOAT 0.002411 0.019562
FLOAT16 0.500000 0.000000
Visually.
df[["diff_ort", "diff_torch"]].plot.bar(
title="ORT/Torch or Torch/ORT for LayerNorm(X) @ W + B"
)
Total running time of the script: (1 minutes 8.626 seconds)
Related examples