Note
Go to the end to download the full example code.
Measuring Gemm performance with different input and output tests¶
This benchmark looks into various combinations allowed by functions cublasLtMatmul. The tested configurations are available at cuda_gemm.cu.
import pprint
import warnings
from itertools import product
from tqdm import tqdm
import matplotlib.pyplot as plt
from pandas import DataFrame
from onnx_extended.args import get_parsed_args
from onnx_extended.ext_test_case import unit_test_going
try:
from onnx_extended.validation.cuda.cuda_example_py import (
gemm_benchmark_test,
get_device_prop,
)
has_cuda = True
except ImportError:
# CUDA not available.
has_cuda = False
gemm_benchmark_test = None
if has_cuda:
prop = get_device_prop()
if prop["major"] <= 0:
# No CUDA.
dtests, ddims = "", ""
elif prop["major"] < 7:
# No float 8.
dtests, ddims = "0,1,2,3,4,15", "16,32,64,64x128x92"
elif prop["major"] < 9: # T100, A100
# No float 8.
dtests, ddims = (
"0,1,2,3,4,15",
"16,32,64,128,128x128x128,128x512x128,128x512x512",
)
else:
dtests, ddims = (
"0,1,2,3,4,5,6,7,11,14,15",
"16,32,64,128,256,512,1024,2048,4096,8192,16384,"
"128x768x768,128x3072x768,128x768x3072",
)
else:
dtests, ddims = "", ""
script_args = get_parsed_args(
"plot_bench_gemm_f8",
description=__doc__,
dims=(
"16,32" if unit_test_going() else ddims,
"square matrix dimensions to try, comma separated values",
),
tests=(
"0,1,2" if unit_test_going() else dtests,
"configuration to check, see cuda_gemm.cu",
),
warmup=2 if unit_test_going() else 5,
repeat=2 if unit_test_going() else 10,
expose="repeat,warmup",
)
Device¶
if has_cuda:
prop = get_device_prop()
pprint.pprint(prop)
else:
print("CUDA is not available")
prop = dict(major=0)
{'clockRate': 0,
'computeMode': 0,
'concurrentKernels': 1,
'isMultiGpuBoard': 0,
'major': 8,
'maxThreadsPerBlock': 1024,
'minor': 9,
'multiProcessorCount': 24,
'name': 'NVIDIA GeForce RTX 4060 Laptop GPU',
'sharedMemPerBlock': 49152,
'totalConstMem': 65536,
'totalGlobalMem': 8585281536}
Benchmark¶
def type2string(dt):
dtests = {
0: "F32",
2: "F16",
14: "BF16",
28: "E4M3",
29: "E5M2",
3: "I8",
10: "I32",
}
return dtests[int(dt)]
dims = []
tests = []
if gemm_benchmark_test is not None:
for d in script_args.dims.split(","):
if "x" in d:
spl = d.split("x")
m, n, k = tuple(int(i) for i in spl)
dims.append((m, n, k))
else:
dims.append(int(d))
tests = [int(i) for i in script_args.tests.split(",")]
pbar = tqdm(list(product(tests, dims)))
obs = []
for test, dim in pbar:
pbar.set_description(f"type={test} dim={dim}")
if test in {8, 9, 10, 12, 13}:
warnings.warn(f"unsupported configuration {test}.", stacklevel=0)
continue
mdim = dim if isinstance(dim, int) else max(dim)
if mdim < 128:
n, N = script_args.warmup * 8, script_args.repeat * 8
elif mdim < 512:
n, N = script_args.warmup * 4, script_args.repeat * 4
elif mdim < 8192:
n, N = script_args.warmup * 2, script_args.repeat * 2
else:
n, N = script_args.warmup, script_args.repeat
if isinstance(dim, int):
gemm_args = [dim] * 6
else:
m, n, k = dim
lda, ldb, ldd = k, k, k
gemm_args = [m, n, k, lda, ldb, ldd]
# warmup
try:
gemm_benchmark_test(test, N, *gemm_args)
except RuntimeError:
# Not working.
continue
# benchmark
res = gemm_benchmark_test(test, N, *gemm_args)
# better rendering
res["test"] = test
update = {}
for k, v in res.items():
if "type_" in k:
update[k] = type2string(v)
if k.startswith("t-"):
update[k] = res[k] / res["N"]
update["compute_type"] = f"C{int(res['compute_type'])}"
for c in ["N", "m", "n", "k", "lda", "ldb", "ldd"]:
update[c] = int(res[c])
update["~dim"] = (update["k"] * max(update["m"], update["n"])) ** 0.5
update["mnk"] = f"{update['m']}x{update['n']}x{update['k']}"
update["name"] = (
f"{update['type_a']}x{update['type_b']}->"
f"{update['type_d']}{update['compute_type']}"
)
res.update(update)
obs.append(res)
if unit_test_going() and len(obs) > 2:
break
df = DataFrame(obs)
df.to_csv("plot_bench_gemm_f8.csv", index=False)
df.to_excel("plot_bench_gemm_f8.xlsx", index=False)
print(df.head().T)
df.head().T
0%| | 0/42 [00:00<?, ?it/s]
type=0 dim=16: 0%| | 0/42 [00:00<?, ?it/s]
type=0 dim=16: 2%|▏ | 1/42 [00:00<00:07, 5.54it/s]
type=0 dim=32: 2%|▏ | 1/42 [00:00<00:07, 5.54it/s]
type=0 dim=64: 2%|▏ | 1/42 [00:00<00:07, 5.54it/s]
type=0 dim=64: 7%|▋ | 3/42 [00:00<00:03, 11.89it/s]
type=0 dim=128: 7%|▋ | 3/42 [00:00<00:03, 11.89it/s]
type=0 dim=(128, 128, 128): 7%|▋ | 3/42 [00:00<00:03, 11.89it/s]
type=0 dim=(128, 512, 128): 7%|▋ | 3/42 [00:00<00:03, 11.89it/s]
type=0 dim=(128, 512, 512): 7%|▋ | 3/42 [00:00<00:03, 11.89it/s]
type=0 dim=(128, 512, 512): 17%|█▋ | 7/42 [00:00<00:01, 20.15it/s]
type=1 dim=16: 17%|█▋ | 7/42 [00:00<00:01, 20.15it/s]
type=1 dim=32: 17%|█▋ | 7/42 [00:00<00:01, 20.15it/s]
type=1 dim=64: 17%|█▋ | 7/42 [00:00<00:01, 20.15it/s]
type=1 dim=128: 17%|█▋ | 7/42 [00:00<00:01, 20.15it/s]
type=1 dim=128: 26%|██▌ | 11/42 [00:00<00:01, 25.96it/s]
type=1 dim=(128, 128, 128): 26%|██▌ | 11/42 [00:00<00:01, 25.96it/s]
type=1 dim=(128, 512, 128): 26%|██▌ | 11/42 [00:00<00:01, 25.96it/s]
type=1 dim=(128, 512, 512): 26%|██▌ | 11/42 [00:00<00:01, 25.96it/s]
type=2 dim=16: 26%|██▌ | 11/42 [00:00<00:01, 25.96it/s]
type=2 dim=16: 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=32: 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=64: 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=128: 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=(128, 128, 128): 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=(128, 512, 128): 36%|███▌ | 15/42 [00:00<00:00, 28.34it/s]
type=2 dim=(128, 512, 128): 48%|████▊ | 20/42 [00:00<00:00, 34.44it/s]
type=2 dim=(128, 512, 512): 48%|████▊ | 20/42 [00:00<00:00, 34.44it/s]
type=3 dim=16: 48%|████▊ | 20/42 [00:00<00:00, 34.44it/s]
type=3 dim=32: 48%|████▊ | 20/42 [00:00<00:00, 34.44it/s]
type=3 dim=64: 48%|████▊ | 20/42 [00:00<00:00, 34.44it/s]
type=3 dim=64: 57%|█████▋ | 24/42 [00:00<00:00, 25.90it/s]
type=3 dim=128: 57%|█████▋ | 24/42 [00:00<00:00, 25.90it/s]
type=3 dim=(128, 128, 128): 57%|█████▋ | 24/42 [00:01<00:00, 25.90it/s]
type=3 dim=(128, 512, 128): 57%|█████▋ | 24/42 [00:01<00:00, 25.90it/s]
type=3 dim=(128, 512, 512): 57%|█████▋ | 24/42 [00:01<00:00, 25.90it/s]
type=3 dim=(128, 512, 512): 67%|██████▋ | 28/42 [00:01<00:00, 24.44it/s]
type=4 dim=16: 67%|██████▋ | 28/42 [00:01<00:00, 24.44it/s]
type=4 dim=32: 67%|██████▋ | 28/42 [00:01<00:00, 24.44it/s]
type=4 dim=64: 67%|██████▋ | 28/42 [00:01<00:00, 24.44it/s]
type=4 dim=64: 74%|███████▍ | 31/42 [00:01<00:00, 19.72it/s]
type=4 dim=128: 74%|███████▍ | 31/42 [00:01<00:00, 19.72it/s]
type=4 dim=(128, 128, 128): 74%|███████▍ | 31/42 [00:01<00:00, 19.72it/s]
type=4 dim=(128, 512, 128): 74%|███████▍ | 31/42 [00:01<00:00, 19.72it/s]
type=4 dim=(128, 512, 512): 74%|███████▍ | 31/42 [00:01<00:00, 19.72it/s]
type=4 dim=(128, 512, 512): 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=16: 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=32: 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=64: 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=128: 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=(128, 128, 128): 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=(128, 512, 128): 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=(128, 512, 512): 83%|████████▎ | 35/42 [00:01<00:00, 21.84it/s]
type=15 dim=(128, 512, 512): 100%|██████████| 42/42 [00:01<00:00, 26.48it/s]
0 1 2 3 4
t-total 0.000094 0.000217 0.000112 0.0002 0.000103
t-clean 0.0 0.000001 0.0 0.000001 0.0
t-gemm_in 0.000012 0.000038 0.000015 0.000022 0.00001
t-setup 0.000003 0.000005 0.000002 0.000005 0.000002
t-stream_create 0.0 0.0 0.0 0.0 0.0
N 80 80 80 40 40
epiloque 1.0 1.0 1.0 1.0 1.0
ldd 16 32 64 128 128
t-workspace_free 0.000002 0.000004 0.000002 0.000005 0.000002
algo 11.0 1.0 1.0 1.0 1.0
t-gemm_sync 0.00008 0.0002 0.000105 0.000129 0.000096
t-stream_destroy 0.000007 0.000002 0.000001 0.000054 0.000002
workspace_size 1048576.0 1048576.0 1048576.0 1048576.0 1048576.0
m 16 32 64 128 128
k 16 32 64 128 128
n 16 32 64 128 128
compute_type C68 C68 C68 C68 C68
lda 16 32 64 128 128
type_a F32 F32 F32 F32 F32
ldb 16 32 64 128 128
t-gemm 0.000015 0.000044 0.000018 0.000028 0.000013
type_b F32 F32 F32 F32 F32
t-workspace_new 0.000003 0.000008 0.000002 0.000004 0.000002
type_d F32 F32 F32 F32 F32
test 0 0 0 0 0
~dim 16.0 32.0 64.0 128.0 128.0
mnk 16x16x16 32x32x32 64x64x64 128x128x128 128x128x128
name F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C68 F32xF32->F32C68
Test definition¶
name test type_a type_b type_d compute_type
0 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68
1 F16xF16->F32C68 3 F16 F16 F32 C68
2 F32xF32->F32C68 0 F32 F32 F32 C68
3 F32xF32->F32C75 2 F32 F32 F32 C75
4 F32xF32->F32C77 1 F32 F32 F32 C77
Total time and only gemm¶
name test type_a type_b type_d compute_type ~dim mnk t-total t-gemm_sync
0 F32xF32->F32C68 0 F32 F32 F32 C68 16.0 16x16x16 0.000094 0.000080
1 F32xF32->F32C68 0 F32 F32 F32 C68 32.0 32x32x32 0.000217 0.000200
2 F32xF32->F32C68 0 F32 F32 F32 C68 64.0 64x64x64 0.000112 0.000105
3 F32xF32->F32C68 0 F32 F32 F32 C68 128.0 128x128x128 0.000200 0.000129
4 F32xF32->F32C68 0 F32 F32 F32 C68 128.0 128x128x128 0.000103 0.000096
5 F32xF32->F32C68 0 F32 F32 F32 C68 256.0 128x512x128 0.000175 0.000122
6 F32xF32->F32C68 0 F32 F32 F32 C68 512.0 128x512x512 0.002146 0.000689
7 F32xF32->F32C77 1 F32 F32 F32 C77 16.0 16x16x16 0.000110 0.000100
8 F32xF32->F32C77 1 F32 F32 F32 C77 32.0 32x32x32 0.000121 0.000111
9 F32xF32->F32C77 1 F32 F32 F32 C77 64.0 64x64x64 0.000137 0.000127
10 F32xF32->F32C77 1 F32 F32 F32 C77 128.0 128x128x128 0.000099 0.000093
11 F32xF32->F32C77 1 F32 F32 F32 C77 128.0 128x128x128 0.000099 0.000092
12 F32xF32->F32C77 1 F32 F32 F32 C77 256.0 128x512x128 0.000090 0.000085
13 F32xF32->F32C77 1 F32 F32 F32 C77 512.0 128x512x512 0.001371 0.000530
14 F32xF32->F32C75 2 F32 F32 F32 C75 16.0 16x16x16 0.000073 0.000067
15 F32xF32->F32C75 2 F32 F32 F32 C75 32.0 32x32x32 0.000096 0.000089
16 F32xF32->F32C75 2 F32 F32 F32 C75 64.0 64x64x64 0.000090 0.000083
17 F32xF32->F32C75 2 F32 F32 F32 C75 128.0 128x128x128 0.000108 0.000099
18 F32xF32->F32C75 2 F32 F32 F32 C75 128.0 128x128x128 0.000132 0.000103
19 F32xF32->F32C75 2 F32 F32 F32 C75 256.0 128x512x128 0.000138 0.000119
20 F32xF32->F32C75 2 F32 F32 F32 C75 512.0 128x512x512 0.001008 0.000288
21 F16xF16->F32C68 3 F16 F16 F32 C68 16.0 16x16x16 0.000067 0.000062
22 F16xF16->F32C68 3 F16 F16 F32 C68 32.0 32x32x32 0.000084 0.000066
23 F16xF16->F32C68 3 F16 F16 F32 C68 64.0 64x64x64 0.000068 0.000060
24 F16xF16->F32C68 3 F16 F16 F32 C68 128.0 128x128x128 0.000061 0.000056
25 F16xF16->F32C68 3 F16 F16 F32 C68 128.0 128x128x128 0.000068 0.000062
26 F16xF16->F32C68 3 F16 F16 F32 C68 256.0 128x512x128 0.000091 0.000084
27 F16xF16->F32C68 3 F16 F16 F32 C68 512.0 128x512x512 0.000110 0.000103
28 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 16.0 16x16x16 0.000111 0.000074
29 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 32.0 32x32x32 0.000056 0.000051
30 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 64.0 64x64x64 0.000064 0.000051
31 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 128.0 128x128x128 0.000064 0.000058
32 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 128.0 128x128x128 0.000060 0.000054
33 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 256.0 128x512x128 0.000069 0.000063
34 BF16xBF16->BF16C68 4 BF16 BF16 BF16 C68 512.0 128x512x512 0.000177 0.000129
Smaller sets¶
if df.shape[0] > 0:
subset = {1, 3, 4, 5, 7}
dfis = dfi[dfi.test.isin(subset)]
print()
print("t-gemm_sync")
pivi = dfis.pivot_table(index=["~dim", "mnk"], columns="name", values="t-gemm_sync")
print(pivi)
print()
print("t-total")
pivi = dfis.pivot_table(index=["~dim", "mnk"], columns="name", values="t-total")
print(pivi)
t-gemm_sync
name BF16xBF16->BF16C68 F16xF16->F32C68 F32xF32->F32C77
~dim mnk
16.0 16x16x16 0.000074 0.000062 0.000100
32.0 32x32x32 0.000051 0.000066 0.000111
64.0 64x64x64 0.000051 0.000060 0.000127
128.0 128x128x128 0.000056 0.000059 0.000092
256.0 128x512x128 0.000063 0.000084 0.000085
512.0 128x512x512 0.000129 0.000103 0.000530
t-total
name BF16xBF16->BF16C68 F16xF16->F32C68 F32xF32->F32C77
~dim mnk
16.0 16x16x16 0.000111 0.000067 0.000110
32.0 32x32x32 0.000056 0.000084 0.000121
64.0 64x64x64 0.000064 0.000068 0.000137
128.0 128x128x128 0.000062 0.000065 0.000099
256.0 128x512x128 0.000069 0.000091 0.000090
512.0 128x512x512 0.000177 0.000110 0.001371
Plots¶
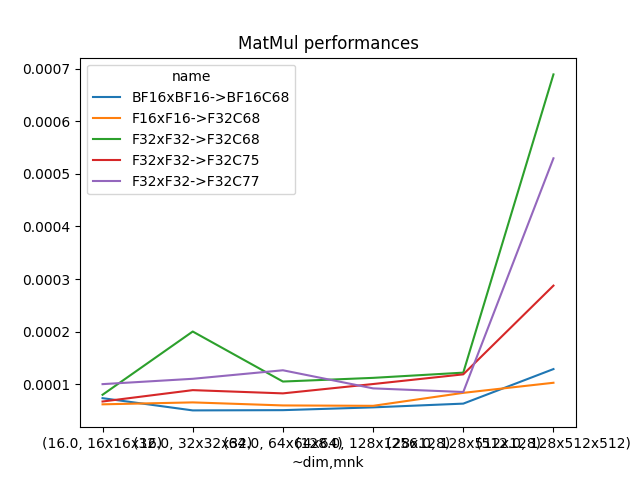
if df.shape[0] > 0:
piv = df.pivot_table(index=["~dim", "mnk"], columns="name", values="t-gemm_sync")
piv.plot(title="MatMul performances")
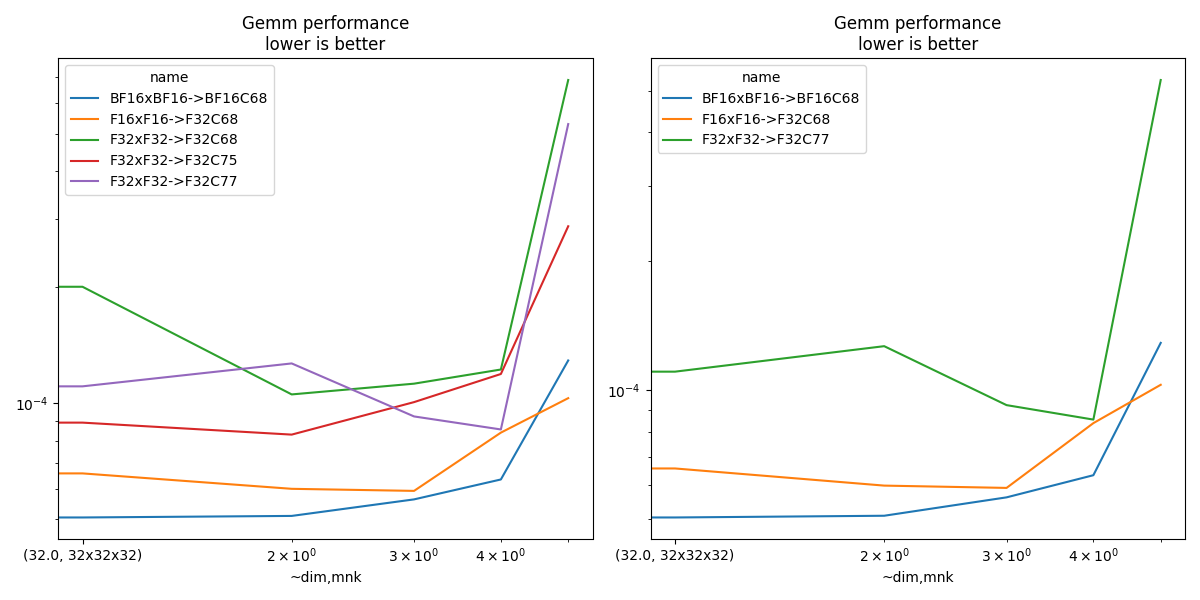
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
piv.plot(ax=ax[0], title="Gemm performance\nlower is better", logx=True, logy=True)
piv = df[df.test.isin(subset)].pivot_table(
index=["~dim", "mnk"], columns="name", values="t-gemm_sync"
)
if piv.shape[0] > 0:
piv.plot(
ax=ax[1], title="Gemm performance\nlower is better", logx=True, logy=True
)
fig.tight_layout()
fig.savefig("plot_bench_gemm_f8.png")
Total running time of the script: (0 minutes 2.203 seconds)