Trees#
Parallelization implementation#
There is no optimal way to parallelize on every machine and for every tree. It depends on the tree size, the number of features, the cache size, the number of cores. The optimal parameters may be twice faster or twice slower, sometimes more, than the fixed values currently uses in onnxruntime.
Six parameters#
The latency of a tree ensemble depends on the tree size and the machine it runs on. The following example takes a model using a TreeEnsembleRegressor and replaces it with a custom node and additional parameters to tune the parallelization. The kernel is a custom operator for onnxruntime. There are six parameters.
The implementation in onnxruntime only uses the first three. It takes place in method compute in file onnxruntime/core/providers/cpu/ml/tree_ensemble_common.h.
This package uses the six parameters in an experimental implementation to investigate new optimizations which could be brought to onnxruntime if they prove to be significantly better. The code is in onnx_extended/cpp/include/cpu/c_op_tree_ensemble_common_.hpp.
The implementation distinguishes between batch inference and one-off inference. The second one is usually uses in web services as the prediction always happens one at a time. We denote T as the number of trees and N the number of predictions to do. N is the batch size.
name |
default |
range |
|
|---|---|---|---|
0 |
parallel_tree |
40 |
[0, |
1 |
parallel_tree_N |
128 |
[0, |
2 |
parallel_N |
50 |
[0, |
3 |
batch_size_tree |
1 |
[1, |
4 |
batch_size_rows |
1 |
[1, |
5 |
use_node3 |
0 |
{0, 1} |
 [
[If N==1 (one off prediction), the inference is parallelized by tree if T > parallel_tree. Every chunk of batch_size_tree consecutive trees is processed in parallel.
If N > 1, no parallelization is done if N <= parallel_N_ && T <= parallel_tree_.
If T >= parallel_tree_, the batch is split into chunks of parallel_tree_N rows. In every chunk, the parallelization is done by tree: every chunk of batch_size_tree consecutive trees is processed in parallel.
Otherwise, the parallelisation is done by rows. The dataset is split into chunks of batch_size_rows rows. Every of them is processed in parallel.
The last parameter is independant from the other. If enabled, the implementation changes the structure to get bigger nodes equivalent to three node from the original tree. This was originally intended to use AVX instructions to speed up the implementation.
Change the parallelization settings#
Should we let the users define the parameters or let the inference session take some time during the initalization to find suitable parameters for the tree and the machine the model is running on. The following example shows how to uses a custom kernel to change the settings. It replaces the onnx nodes by another one with the same parameters plus the parallelization settings. The custom operator will be able to used them.
<<<
import os
import numpy as np
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from skl2onnx import to_onnx
from onnxruntime import InferenceSession, SessionOptions
from onnx_array_api.plotting.text_plot import onnx_simple_text_plot
from onnx_extended.ortops.optim.cpu import get_ort_ext_libs
from onnx_extended.ortops.optim.optimize import (
change_onnx_operator_domain,
get_node_attribute,
)
# The dimension of the problem.
batch_size = 20
n_features = 4
n_trees = 2
max_depth = 3
# Let's create model.
X, y = make_regression(batch_size * 2, n_features=n_features, n_targets=1)
X, y = X.astype(np.float32), y.astype(np.float32)
model = RandomForestRegressor(n_trees, max_depth=max_depth, n_jobs=-1)
model.fit(X[:batch_size], y[:batch_size])
onx = to_onnx(model, X[:1], target_opset=17)
# onnx-extended implements custom kernels
# to tune the parallelization parameters.
# It requires to replace the onnx node by another
# one including the optimization parameters.
optim_params = {
"parallel_tree": 80,
"parallel_tree_N": 80,
"parallel_N": 80,
"batch_size_tree": 2,
"batch_size_rows": 2,
"use_node3": 0,
}
# Let's replace the node TreeEnsembleRegressor with a new one
# and additional parameters.
def transform_model(onx, op_name, **kwargs):
att = get_node_attribute(onx.graph.node[0], "nodes_modes")
modes = ",".join(map(lambda s: s.decode("ascii"), att.strings))
return change_onnx_operator_domain(
onx,
op_type=op_name,
op_domain="ai.onnx.ml",
new_op_domain="onnx_extented.ortops.optim.cpu",
nodes_modes=modes,
**kwargs,
)
modified_onx = transform_model(onx, "TreeEnsembleRegressor", **optim_params)
# The new attributes are added into the onnx file and defines
# how the parallelisation must be done.
print(onnx_simple_text_plot(modified_onx))
# Let's check it is working.
opts = SessionOptions()
r = get_ort_ext_libs()
opts.register_custom_ops_library(r[0])
sess = InferenceSession(
modified_onx.SerializeToString(),
opts,
providers=["CPUExecutionProvider"],
)
feeds = {"X": X}
print(sess.run(None, feeds))
>>>
opset: domain='ai.onnx.ml' version=1
opset: domain='' version=17
opset: domain='onnx_extented.ortops.optim.cpu' version=1
input: name='X' type=dtype('float32') shape=['', 4]
TreeEnsembleRegressor[onnx_extented.ortops.optim.cpu](X, batch_size_rows=2, batch_size_tree=2, nodes_modes=b'BRANCH_LEQ,BRANCH_LEQ,BRANCH_LEQ,LEAF,...LEAF,LEAF', parallel_N=80, parallel_tree=80, parallel_tree_N=80, use_node3=0, n_targets=1, nodes_falsenodeids=28:[8,5,4...0,0,0], nodes_featureids=28:[1,3,2...0,0,0], nodes_hitrates=28:[1.0,1.0...1.0,1.0], nodes_missing_value_tracks_true=28:[0,0,0...0,0,0], nodes_nodeids=28:[0,1,2...10,11,12], nodes_treeids=28:[0,0,0...1,1,1], nodes_truenodeids=28:[1,2,3...0,0,0], nodes_values=28:[0.15102006494998932,-0.5046523809432983...0.0,0.0], post_transform=b'NONE', target_ids=15:[0,0,0...0,0,0], target_nodeids=15:[3,4,6...10,11,12], target_treeids=15:[0,0,0...1,1,1], target_weights=15:[-51.169532775878906,-29.89283561706543...53.451934814453125,113.51219177246094]) -> variable
output: name='variable' type=dtype('float32') shape=['', 1]
[array([[ -24.975],
[ 24.747],
[ -24.384],
[-102.339],
[ -24.384],
[ -8.917],
[ -24.975],
[ -24.384],
[ 25.444],
[ -52.555],
[ -73.832],
[ 106.904],
[ -52.555],
[ 149.875],
[ -24.384],
[ -52.555],
[ 10.267],
[ -24.384],
[ -63.939],
[ -63.316],
[ -24.384],
[ -24.384],
[ -48.471],
[ 41.837],
[ -63.939],
[ -24.384],
[ 89.814],
[-101.716],
[ -24.975],
[ -73.832],
[ 41.837],
[ -24.384],
[ 149.875],
[ 135.395],
[ -8.917],
[ 25.444],
[ -63.939],
[ -35.431],
[ 24.747],
[ 135.395]], dtype=float32)]
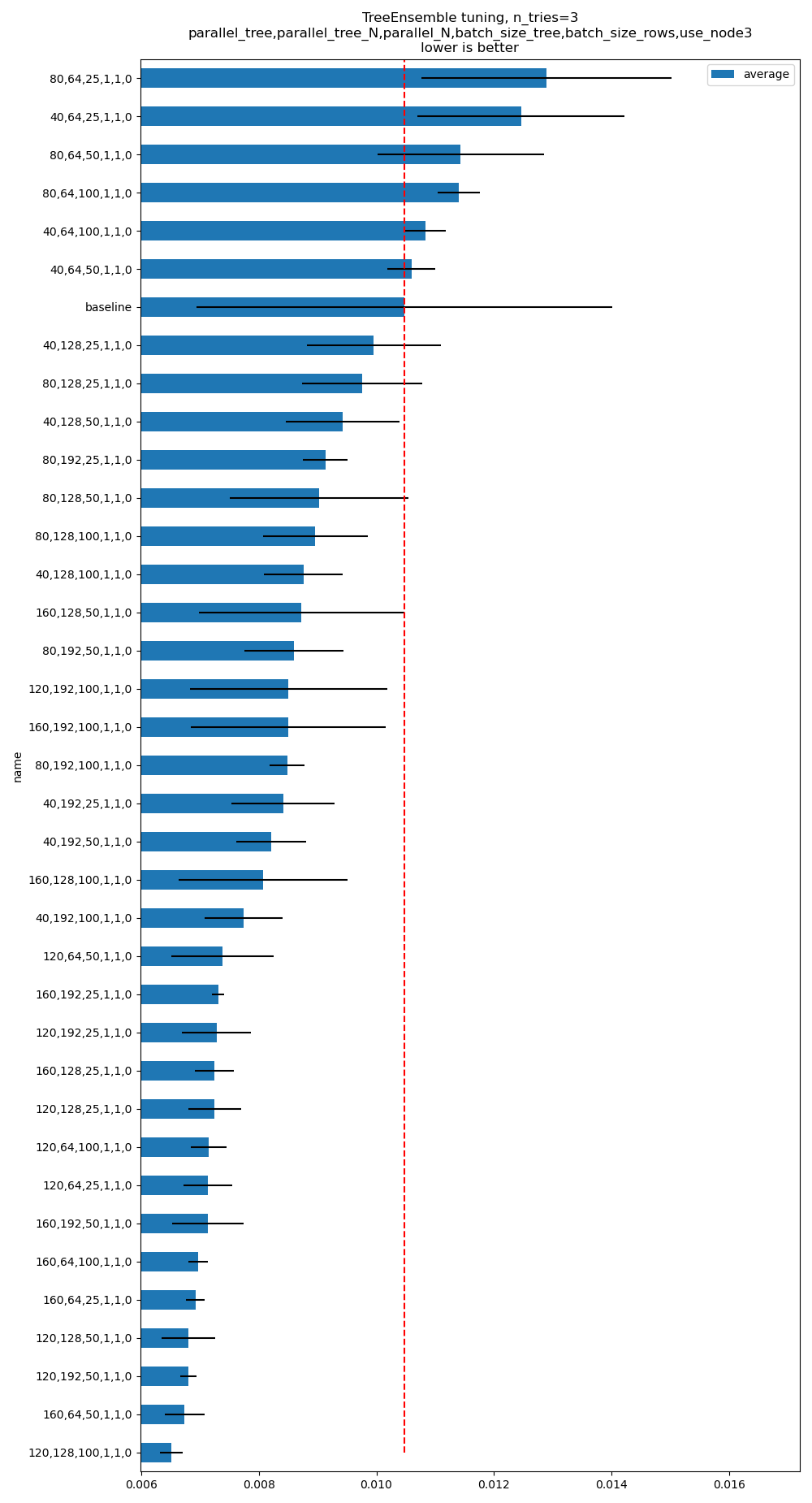
Optimizes the parallelisation settings#
See example TreeEnsemble optimization. It produces the following graph. The baseline means onnxruntime==1.16.0. The command line is:
python plot_optim_tree_ensemble.py --n_features=50 --n_trees=100 --max_depth=10 --scenario=CUSTOM
--parallel_tree=160,120,80,40 --parallel_tree_N=192,128,64 --parallel_N=100,50,25
--batch_size_tree=1 --batch_size_rows=1 --use_node3=0