Classification multi-classe et stacking¶
On cherche à prédire la note d’un vin avec un classifieur multi-classe puis à améliorer le score obtenu avec une méthode dite de stacking.
Le problème¶
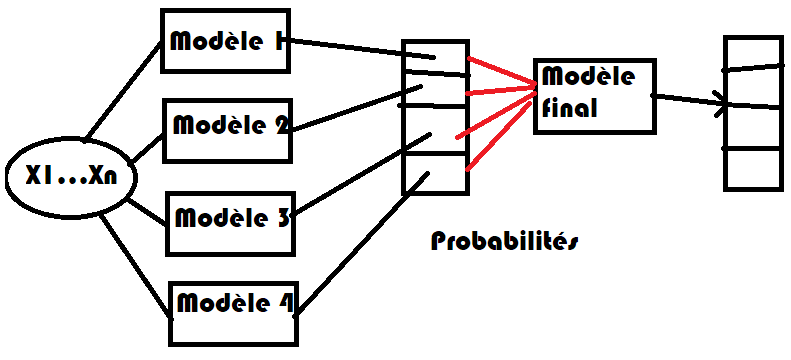
Il n’est pas évident que les scores des différents modèles qu’on apprend sur chacun des classes soient comparables. Si le modèle n’est pas assez performant, on peut songer à ajouter un dernier modèle qui prend la décision finale en fonction du résultat de chaque modèle.
[7]:
from IPython.display import Image
Image("images/stackmulti.png", width=400)
[7]:
[8]:
%matplotlib inline
[9]:
from teachpyx.datasets import load_wines_dataset
df = load_wines_dataset()
X = df.drop(["quality", "color"], axis=1)
y = df["quality"]
[10]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
[11]:
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
clr = OneVsRestClassifier(LogisticRegression(max_iter=1500))
clr.fit(X_train, y_train)
[11]:
OneVsRestClassifier(estimator=LogisticRegression(max_iter=1500))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
LogisticRegression(max_iter=1500)
Parameters
[12]:
import numpy
numpy.mean(clr.predict(X_test).ravel() == y_test.values.ravel()) * 100
[12]:
np.float64(54.09230769230769)
On regarde la matrice de confusion.
[13]:
from sklearn.metrics import confusion_matrix
import pandas
df = pandas.DataFrame(confusion_matrix(y_test, clr.predict(X_test)))
try:
df.columns = [str(_) for _ in clr.classes_][: df.shape[1]]
df.index = [str(_) for _ in clr.classes_][: df.shape[0]]
except ValueError:
# Il peut arriver qu'une classe ne soit pas représenter
# lors de l'apprentissage
print("erreur", df.shape, clr.classes_)
df
[13]:
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|
| 3 | 0 | 0 | 4 | 2 | 0 | 0 | 0 |
| 4 | 0 | 0 | 28 | 26 | 1 | 0 | 0 |
| 5 | 0 | 0 | 325 | 210 | 2 | 0 | 0 |
| 6 | 0 | 0 | 166 | 531 | 16 | 0 | 0 |
| 7 | 0 | 0 | 15 | 230 | 23 | 0 | 0 |
| 8 | 0 | 0 | 6 | 34 | 4 | 0 | 0 |
| 9 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
On cale d’abord une random forest sur les données brutes.
[14]:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
numpy.mean(rfc.predict(X_test).ravel() == y_test.values.ravel()) * 100
[14]:
np.float64(67.6923076923077)
On cale une random forest avec les sorties de la régression logistique.
[15]:
rf_train = clr.decision_function(X_train)
rfc_y = RandomForestClassifier()
rfc_y.fit(rf_train, y_train)
[15]:
RandomForestClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
On calcule le taux d’erreur.
[16]:
rf_test = clr.decision_function(X_test)
numpy.mean(rfc_y.predict(rf_test).ravel() == y_test.values.ravel()) * 100
[16]:
np.float64(65.72307692307693)
C’est presque équivalent à une random forest calée sur les données brutes. On trace les courbes ROC pour la classe 4.
[17]:
from sklearn.metrics import roc_curve, roc_auc_score
fpr_lr, tpr_lr, th_lr = roc_curve(y_test == 4, clr.decision_function(X_test)[:, 2])
fpr_rfc, tpr_rfc, th_rfc = roc_curve(y_test == 4, rfc.predict_proba(X_test)[:, 2])
fpr_rfc_y, tpr_rfc_y, th_rfc_y = roc_curve(
y_test == 4, rfc_y.predict_proba(rf_test)[:, 2]
)
auc_lr = roc_auc_score(y_test == 4, clr.decision_function(X_test)[:, 2])
auc_rfc = roc_auc_score(y_test == 4, rfc.predict_proba(X_test)[:, 2])
auc_rfc_y = roc_auc_score(y_test == 4, rfc_y.predict_proba(rf_test)[:, 2])
auc_lr, auc_rfc, auc_rfc_y
[17]:
(0.610804863925883, 0.6194730746960047, 0.585865662999421)
[18]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
ax.plot([0, 1], [0, 1], "k--")
ax.plot(fpr_lr, tpr_lr, label="OneVsRest + LR")
ax.plot(fpr_rfc, tpr_rfc, label="RF")
ax.plot(fpr_rfc_y, tpr_rfc_y, label="OneVsRest + LR + RF")
ax.set_title("Courbe ROC - comparaison de deux\nmodèles pour la classe 4")
ax.legend();
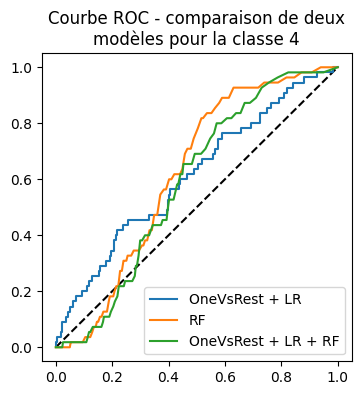
La courbe ROC ne montre rien de probant. Il faudrait vérifier avec une cross-validation qu’il serait pratique de faire avec un pipeline mais ceux-ci n’acceptent qu’un seul prédicteur final.
[19]:
from sklearn.pipeline import make_pipeline
try:
pipe = make_pipeline(
OneVsRestClassifier(LogisticRegression(max_iter=1500)), RandomForestClassifier()
)
except Exception as e:
print("ERREUR :")
print(e)
On construit une ROC sur toutes les classes.
[20]:
fpr_lr, tpr_lr, th_lr = roc_curve(
y_test == clr.predict(X_test),
clr.predict_proba(X_test).max(axis=1),
drop_intermediate=False,
)
fpr_rfc, tpr_rfc, th_rfc = roc_curve(
y_test == rfc.predict(X_test),
rfc.predict_proba(X_test).max(axis=1),
drop_intermediate=False,
)
fpr_rfc_y, tpr_rfc_y, th_rfc_y = roc_curve(
y_test == rfc_y.predict(rf_test),
rfc_y.predict_proba(rf_test).max(axis=1),
drop_intermediate=False,
)
auc_lr = roc_auc_score(
y_test == clr.predict(X_test), clr.decision_function(X_test).max(axis=1)
)
auc_rfc = roc_auc_score(
y_test == rfc.predict(X_test), rfc.predict_proba(X_test).max(axis=1)
)
auc_rfc_y = roc_auc_score(
y_test == rfc_y.predict(rf_test), rfc_y.predict_proba(rf_test).max(axis=1)
)
auc_lr, auc_rfc, auc_rfc_y
[20]:
(0.5566906703022872, 0.7535939393939393, 0.7387052091528319)
[21]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
ax.plot([0, 1], [0, 1], "k--")
ax.plot(fpr_lr, tpr_lr, label="OneVsRest + LR")
ax.plot(fpr_rfc, tpr_rfc, label="RF")
ax.plot(fpr_rfc_y, tpr_rfc_y, label="OneVsRest + LR + RF")
ax.set_title("Courbe ROC - comparaison de deux\nmodèles pour toutes les classes")
ax.legend();
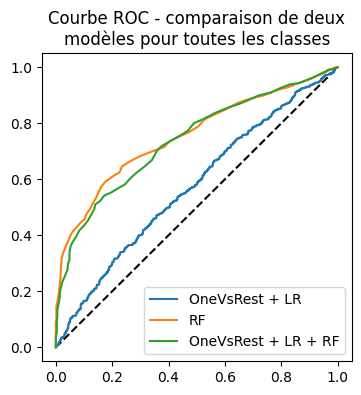
Sur ce modèle, le score produit par le classifieur final paraît plus partinent que le score obtenu en prenant le score maximum sur toutes les classes. On tente une dernière approche où le modèle final doit valider ou non la réponse : c’est un classifieur binaire. Avec celui-ci, tous les classifieurs estimés sont binaires.
[22]:
rf_train_bin = clr.decision_function(X_train)
y_train_bin = clr.predict(X_train) == y_train
rfc = RandomForestClassifier()
rfc.fit(rf_train_bin, y_train_bin)
[22]:
RandomForestClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
On regarde les premières réponses.
[23]:
rf_test_bin = clr.decision_function(X_test)
rfc.predict_proba(rf_test_bin)[:3]
[23]:
array([[0.26, 0.74],
[0.76, 0.24],
[0.66, 0.34]])
[24]:
y_test_bin = clr.predict(X_test) == y_test
[25]:
fpr_rfc_bin, tpr_rfc_bin, th_rfc_bin = roc_curve(
y_test_bin, rfc.predict_proba(rf_test_bin)[:, 1]
)
auc_rfc_bin = roc_auc_score(y_test_bin, rfc.predict_proba(rf_test_bin)[:, 1])
auc_lr, auc_rfc_bin
[25]:
(0.5566906703022872, 0.7760471471663816)
[26]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
ax.plot([0, 1], [0, 1], "k--")
ax.plot(fpr_lr, tpr_lr, label="OneVsRest + LR")
ax.plot(fpr_rfc, tpr_rfc, label="OneVsRest + LR + RF")
ax.plot(fpr_rfc_bin, tpr_rfc_bin, label="OneVsRest + LR + RF binaire")
ax.set_title("Courbe ROC - comparaison de deux\nmodèles pour toutes les classes")
ax.legend();
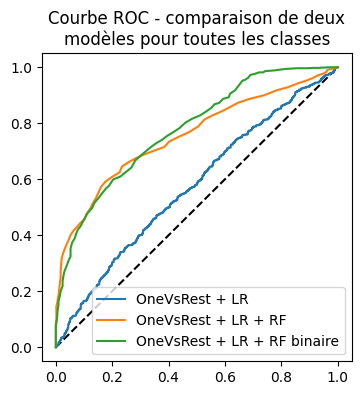
Un peu mieux mais il faudrait encore valider avec une validation croisée et plusieurs jeux de données, y compris artificiels. Il reste néanmoins l’idée.
Automatisation avec une implémentation¶
Comme c’est fastidieux de faire tout cela, on crée un pipeline. scikit-learn a introduit le modèle StackingClassifier.
[27]:
from sklearn.ensemble import StackingClassifier
model = StackingClassifier(
[
("ovrlr", LogisticRegression()),
("rf", RandomForestClassifier()),
]
)
model.fit(X_train, y_train)
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/model_selection/_split.py:813: UserWarning: The least populated class in y has only 3 members, which is less than n_splits=5.
warnings.warn(
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:406: ConvergenceWarning: lbfgs failed to converge after 100 iteration(s) (status=1):
STOP: TOTAL NO. OF ITERATIONS REACHED LIMIT
Increase the number of iterations to improve the convergence (max_iter=100).
You might also want to scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
~/vv/this312/lib/python3.12/site-packages/sklearn/model_selection/_split.py:813: UserWarning: The least populated class in y has only 3 members, which is less than n_splits=5.
warnings.warn(
[27]:
StackingClassifier(estimators=[('ovrlr', LogisticRegression()),
('rf', RandomForestClassifier())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Parameters
Parameters
[28]:
fpr_pipe, tpr_pipe, th_pipe = roc_curve(
y_test == model.predict(X_test),
model.predict_proba(X_test).max(axis=1),
drop_intermediate=False,
)
auc_pipe = roc_auc_score(
y_test == model.predict(X_test), model.predict_proba(X_test).max(axis=1)
)
auc_pipe
[28]:
0.7486097777777779
La validation croisée a été escamotée par gain de temps mais faire l’impasse est risquée dans le cas général.