Données antipathiques (skewed), Appariement - énoncé#
Un problème où le map/reduce n’est pas la meilleure solution dans l’absolu. Comment faire quand on n’a que ça et un problème de détection de doublons dans un jeu de données ?
[2]:
%matplotlib inline
import matplotlib.pyplot as plt
Description du problème#
On se place ici dans le cadre d’un problème classique désigné par le terme anglais de conflation (voir aussi Conflation Optimized by Least Squares to Maintain Geographic Shapes. Il s’agit de fusionner deux bases de données qui décrivent chacune les mêmes entités (deux annuaires par exemple) mais de manière légèrement différentes.
Par exemple, on dispose de deux bases  et
et  . Chacune d’elles donne les positions géographiques de
. Chacune d’elles donne les positions géographiques de  et
et  bâtiments. La mesure des coordonnées est faite à dix ans d’intervalles et on souhaite connaître les bâtiments qui ont été détruits ou créés. Il faut donc apparier les entités de la première base avec les de la seconde.
bâtiments. La mesure des coordonnées est faite à dix ans d’intervalles et on souhaite connaître les bâtiments qui ont été détruits ou créés. Il faut donc apparier les entités de la première base avec les de la seconde.
Une première option consiste à calculer toutes les distances entre les deux bases soit  distances puis à apparier les deux points les plus proches, puis les deux suivantes les plus proches jusqu’à ce qu’on décide qu’à partir d’un certain seuil, deux bâtiments sont probablement trop éloignés pour être appariés.
distances puis à apparier les deux points les plus proches, puis les deux suivantes les plus proches jusqu’à ce qu’on décide qu’à partir d’un certain seuil, deux bâtiments sont probablement trop éloignés pour être appariés.
Lorsqu’on dispose de grandes bases, 10 millions d’entités par exemple, ce calcul devient impossible à réaliser en un temps raisonnable. Il faut ruser.
[3]:
import random
x1 = [random.gauss(0, 1) for i in range(0, 150)] + [
random.gauss(0, 1) * 2 + 4 for i in range(0, 500)
]
y1 = [random.gauss(0, 1) for i in range(0, 150)] + [
random.gauss(0, 1) - 1 for i in range(0, 500)
]
x2 = [x + random.gauss(0, 0.2) for x in x1]
y2 = [y + random.gauss(0, 0.2) for y in y1]
plt.figure(figsize=(16, 6))
plt.plot(x1, y1, "o")
plt.plot(x2, y2, "o");
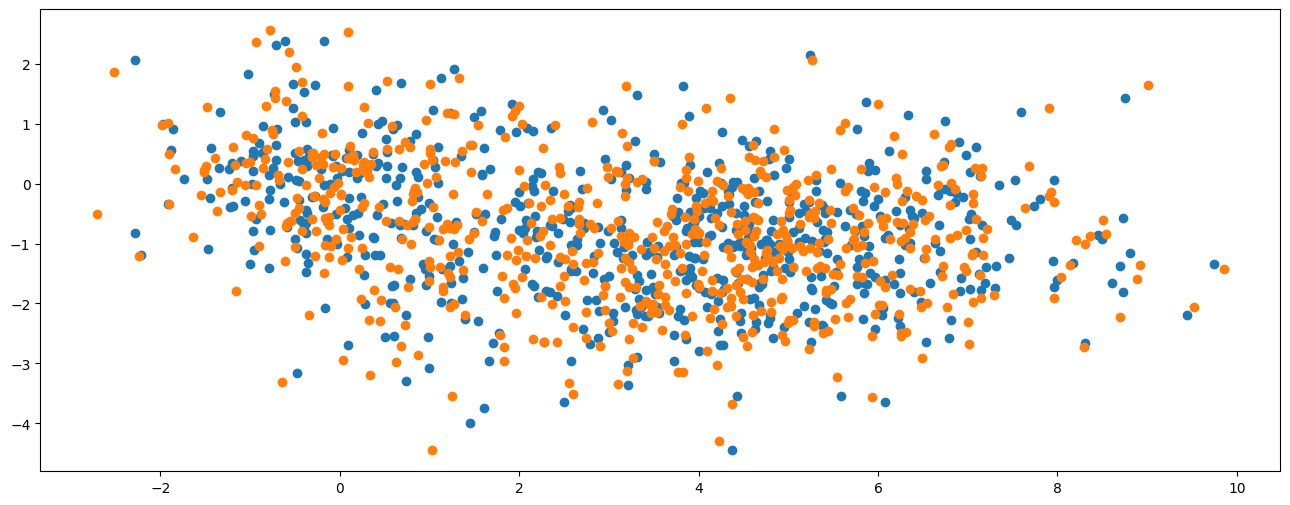
On veut apparier les points bleus et rouges. Si on dessine une grille sur les données, deux points ont plus de chance d’être appariés s’ils font partie de la même case. Mais cela ne suffit pas. Il faut aussi considérer les voisins.
Exercice 1 : combien de voisins faut-il considérer ?#
On veut être sûr de ne manquer aucun appariement. On suppose que les cases sont de tailles  . On suppose que deux points
. On suppose que deux points  (rouge) et
(rouge) et  (bleu) ne peuvent jamais être appariés si la distance
(bleu) ne peuvent jamais être appariés si la distance  . Le point
. Le point  est dans la case
est dans la case  . Où peut être ? Comment utiliser cette information pour réduire le nombre de distances à calculer ?
. Où peut être ? Comment utiliser cette information pour réduire le nombre de distances à calculer ?
[4]:
Exercice 2 : nombre de distances ?#
Ecrire un programme python qui calcule ce nombre de distances.
[5]:
Exercice 3 : distribuer les calculs#
Ecrire le même programme en PIG.
[6]:
Exercice 4 : données antipathiques#
Y a-t-il des cas où cette distribution sera difficilement réalisable ? (indice : skewed)
[7]:
Exercice 5 : comment distribuer malgré tout ?#
Oublions le problème initial. On a deux datasets qu’on doit fusionner (JOIN). Une des clés est partagée par plus de 10% des deux bases. Comment distribuer ce JOIN sur plusieurs machines ?
[8]: